There are currently several billion Web pages and files on the Internet and continues to grow every day. The ability to search in the vast information space of the Internet, provide search engines.
Search engines can be divided into directories, classifiers, search engines (index robots), metasearch systems. The basis for such a classification may be a search implementation method and database replenishment methods.
Different principles of search engines
Information retrieval machines are services that include huge databases that are automatically replenished using a search robot ( special programscanning Internet content).
The robot accesses Web pages, examines the contents of these pages and, depending on the program laid down, can save the entire page in its database, or generate and write keywords from the pages into the database. Such actions are called indexing.
If the site’s pages are not linked via hyperlinks to other sites, the probability of finding this page is very small. There is also a manual indexing mechanism in the search engine database: site owners can put their pages in the queue for indexing themselves.
Directories are a huge database of URLs for sites of various subjects. Catalogs can be arranged in different ways, i.e. having either a linear or hierarchical structure.
Initially, a search is carried out on a general topic, then the request is more specific. A distinctive feature of the catalog is that all information is entered by a person. Therefore, the characteristic features of the catalog are the low replenishment speed and the small volume compared to the search system, although this characteristic helps to increase the accuracy of the search.
Organization of work with the catalog is quite simple. A Web site page usually contains a list of certain categories, each of which is linked by a hyperlink to other links, where either a list of sub-categories or a list of documents corresponding to a given section are located.
The most popular Russian catalogs include:
· One of the largest Russian-language catalogs List.ru ( http://www.list.ru);
Russian version of Yahoo ( http://www.yahoo.ru).
Classifiers. Perform similar functions as directories. They are a collection of URLs that are only systematized on a separate topic, or on a specific heading. Often classifiers simply refer to directories.
Metasearch systems. The system that sends a request to the main search engines and returns their reports, it does not have its own search tools and does not create its own database. The main advantage of meta search engines is the ability to provide the user with the resources of several search engines at once, without any effort on his part.
Internet Information Search Technology
You can organize a search in different ways, and one of the problems is to reduce the level of unnecessary information. It should be noted that the search and selection of information does not apply to ordinary human skills, this must be specially trained. It requires mastering the fundamentals of mathematical logic, understanding that the more accurately the request is formulated, the higher the correspondence of the information presented in the response to the request.
Search Rules by keywords
To start the search you need to enter keywords. These words should accurately reflect the essence of the request. You cannot specify any one keyword that has a general meaning, for example, “computer science” or “history”. Better narrow your search using additional keywords.
The main task of the user: to correctly set the combination of keywords so that the search is not extremely wide and leads to the desired result. In this case, you must adhere to certain rules established by the search engine.
Also, when searching, you must adhere to the following requirements:
1. Take into account the features of natural language:
· Polysemy - semantic variety of words or combinations of words;
· Homonymy - different in meaning, but equally spelled words;
· Synonyms - words that differ in spelling and pronunciation, but are identical in meaning;
2. Avoid spelling mistakes.
3. Avoid a single word search, use the necessary and sufficient set of words.
4. Do not write in capital letters.
5. Exclude unnecessary words from the search.
6. Use advanced search capabilities.
After setting the keywords, click on the Search button located next to the text box.
Types of Search Engines
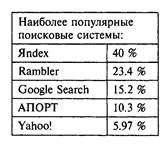
There are several thousand search engines on the World Wide Web, among which there are both well-established and less well-known. Of the most famous can be called among foreign: AltaVista, Google, HotBot, InfoSeek, Lycos, WebCrawler, Yahoo! and etc.; among Russian Yandex, Rambler, Aport! and etc.
Each search engine has both advantages and disadvantages. The selection criteria, which search engine to use, can serve such characteristics as:
· principle of operation search engine;
· the convenience of use;
· External design;
· The complexity of the query language;
· The presence of various advanced functions (control of the format and order of information displayed, translation of input words into another language, etc.)
· Speed \u200b\u200bof work;
· The level of workload at specific points in time, reliability, etc.
There are 2 main types of Internet search engines: index and classification (catalog).
Index search engines working in auto mode updating their information, browsing the contents of servers on the Internet, indexing all the information contained in them and entering information about the location of words on the pages of sites into their databases.
Search catalog systems contain a thematically structured directory of servers, and are often replenished manually. In the catalog search system, you can, starting with a larger thematic topic, gradually descending further under the headings, come to a link to desired server. In some cases, it is more convenient to use the first type of search engine, in others - the second type.
There are search engines that combine both principles of work. In particular, most index search engines have a catalog search system. Many search engines have transformed into Internet portals, combining a large number of resources and services. On the pages of such portals you can read the news, TV program, learn about the weather, exchange rates and much more.
There are also specialized search engines that allow you to search for information in other information "layers" of the Internet: file archive servers, mail servers and others. To search for files on file archive servers, there is specialized systems two types: database-based search engines and file directories. To search for a file in the system using the database, just enter the file name in the search field and the search engine will display the URL of the storage locations this file. If the file name is unknown, but its purpose is known (for example, a music file), then you can use the thematic catalog of music files.
To obtain a high-quality search result, it is necessary to use the capabilities of various search engines.
Conclusion
Local and global networks are widely used in the activities of a lawyer. As for global networks, it should be noted that the Internet is a global storehouse of information, including one closely related to jurisprudence. So the Internet has its own pages and websites of legal agencies, communities and, finally, government agencies that directly implement rulemaking. With the help of the Internet, you can organize conferences, communicate in real mode, correspond, and visit sites containing legal reference information. For example, there is the agency www.lexaudit.ru, which, among other things, is engaged in free daily newsletters on near-legal topics, which certainly facilitates the work of a lawyer and saves his time.
Often, the presence of a page on the Internet can affect the prestige of the company (lawyer). It is very convenient to maintain a page on the Internet both for advertising and for disseminating information and engaging in cooperation.
On the Internet there are many sites of legal subjects, which reflects the importance of law in the life of an individual, society and state. To legal information resources The Internet can apply various classification criteria.
1. On a national-territorial basis.
2. By type of site owners - government organizations, commercial organizations, public associations, educational institutions, private individuals, etc.
3. By branches of law - the theory of state and law, civil law, intellectual property law, information law, etc.
4. By the nature of the content (content) - catalogs of legal links, scientific publications, legal databases, collections of regulatory documents, the offer of legal services, etc.
5. In terms of coverage of the intended audience - international, federal, regional and local resources.
6. By the popularity of the resource, the number of site visitors (rating).
Many sites are difficult to categorize in content because they contain a combination of different options. So, for example, a site can contain a selection of regulatory documents, articles by various authors, a selection of links, and a forum, in a word, everything that the site’s author wants and can collect. It is clear that the same site can fall into several classification categories simultaneously.
Using search engines, you can get lists of links to legal resources. In numerous search directories usually there are relevant sections of legal topics.
In order to “establish communication” with all of the above information systems, a lawyer, must possess the necessary tools, as well as the necessary skills necessary for the effective handling and handling of the information received.
Federal Agency for Education
Smolensk State University
Information retrieval technology on the Internet.
Smolensk
Introduction …………………………………………………………………………… .. 1. Classification of search engines ………………………………………… ... 2. Search methods ………………………………………………………………… .... 2.1. A simple search .............................................. 2.2. Advanced Search ………………………………………………………………. 3. Theme catalog Yahoo. ……………………………………………………… 4. Alta Vista Auto Index ........................................... 5. Searching for information in conferences (Usenet) ………………………………… .. 6. Domestic search services …………………………………………… .. 6.1.Rambler ……………………………………………………………………………. 7.File search …………………………………………………………… .. 8. Sources of specialized information ……………………………… 9. The search for individuals on the Internet ...................................... 10.Metapoisk ………………………………………………………………………… .. 11.Effective search information ………………………………………… ... Conclusion ………………………………………………………………………………….Literature……………………………………………………………………….. |
Introduction
Anyone who ever tried to find necessary information on the Internet, I’ll probably agree that this process is similar to finding a needle in a haystack. The global Internet contains a huge amount of information, which is growing rapidly every day. Because of this, it often turns out that the problem of finding necessary information in this information ocean is extremely difficult and you need to be able to effectively use various search engines (information retrieval programs on the network). It should be noted that "search is an art."
1. Search Engine Classification
 There are many different search engines owned by different companies. First of all, the so-called thematic directories (for example, Yahoo) and automatic indexes (for example, AltaVista) are distinguished, although it must be borne in mind that a number of search engines occupies some intermediate position between these two "poles", that is, they contain elements both of these classes. Each of the search engines has its own extensive database of addresses (location) of various Web documents, and the search for links to the information we need occurs, not in the Web documents themselves, but in this database.
There are many different search engines owned by different companies. First of all, the so-called thematic directories (for example, Yahoo) and automatic indexes (for example, AltaVista) are distinguished, although it must be borne in mind that a number of search engines occupies some intermediate position between these two "poles", that is, they contain elements both of these classes. Each of the search engines has its own extensive database of addresses (location) of various Web documents, and the search for links to the information we need occurs, not in the Web documents themselves, but in this database. Thematic catalogs and automatic indexes differ, first of all, by how their databases are formed and updated: whether people take part in this process, or everything happens completely automatically.
The databases of thematic catalogs are compiled and systematically updated by experts in relevant fields on the basis of new Web documents discovered on the Internet by special search programs. The thematic catalog presents to the Internet user some tree-like structure of categories (sections and subsections), at the top level of which the most general concepts, such as Science, Art, Business, etc., are collected, and elements of the lowest level are links to individual Web pages and servers along with brief description their contents. You can travel through this hierarchical catalog, starting from more general categories (concepts) to narrower, specialized ones.
For example, to find information about the state of scientific research on the theory of superstrings, you can go down the following “ladder” of concepts:
Science
Physics
Theoretical Physics
Theories
String Theories (Theory String)
As a result, a list of sites will be obtained, among which the site of greatest interest is Superstrings. By clicking on the Superstrings hyperlink, we get to the home page of the site, with the corresponding heading, on which you can find an on-line textbook on the theory of superstrings, various links for further reading, a glossary on superstrings, etc.
The main advantage of thematic catalogs is the great value of the information received by the user, which is ensured by the presence of the “human factor” in the analysis and sorting of new Web pages. On the other hand, subject catalogs have a significant drawback, again related to the human factor, because due to the limited human capabilities their databases cover only a small part of the entire information Web space (less than 1%). Thus, despite the usefulness of subject directories, the use of only search engines of this kind is often clearly inadequate.
Summary table of selected subject catalogs
| List.Ru | Aport | Yandex | Rambler | Yahoo! | About | |
| general characteristics | 19 top-level sections | 14 top-level sections | 10 main sections, 7 combined, additional classification | 56 sections | 14 main sections | 36 sections |
| Sorting resources within a section | Alphabet, guide rating, popularity (attendance), date | Alphabet, attendance, league, estimation of the number of links to this resource, user opinion | Alphabet, Date Added, Citation Index | by attendance | alphabetically | link paid |
| Boolean operators | The language of the search engine Aport is used | Used language search engine Yandex | Used Rambler search engine language | No | No | |
| Phrase search | " " | " " | ||||
| Prefixes | +, - | +, - | ||||
| Iterative search (in results) | There is a search inside the category | After logging in, click More ... | ||||
| word replacement | * | * (not always correct) |
Unlike thematic catalogs, databases for automatic indexes are created and updated automatically by some special, internal search programs-robots that browse the Internet sites (sites) around the clock in search of newly appeared Web-documents. From each such document, the robot extracts all the new links contained in it and adds them to its address database, as a result of which the robot program has the opportunity to view a certain number of new Web documents for it. In each new Web-document, the robot analyzes all the words included in it and in the database section corresponding to each given word, the address (URL) of the document where this word occurs is remembered. Thus, the database created by the automatic index actually stores information about which Web documents contain certain words. Unlike subject directories, automatic indexes cover up to 25% of the total Web space.
The automatic index has a separate search engine to provide a user interface. This system can, browsing the database, find and display on the user computer screen addresses and brief information about all Web pages that contain this set of keywords using a given set of keywords. Thus, an automatic index consists of three parts: a robot program, a database collected by this robot, and an interface for searching in this database. It is with the latter component that the user works. By virtue of such an organization, an automatic index does not make any classification or rating of information.
The automatic indexes interface allows the user to specify a certain set of keywords that, from his point of view, are characteristic of the documents he is looking for, and thus allow finding a fairly limited number of potentially relevant Web pages. As such words, some specific terms and their combinations, rather rare surnames, etc. can be used.
The success of the search for the necessary information is largely determined by the right choice of keywords, because otherwise the search system can produce many thousands and millions of links to irrelevant Web-documents.
It should be borne in mind that a novice user has many different surprises, sometimes reaching anecdotal situations.
If for automatic indexes the search by keywords is the only means of finding the necessary information, then in thematic catalogs (for example, Yahoo!) this means alternative way search along with a journey through the system (tree) of categories nested in each other.
Some kind search services are rating services. They provide the customer ready list some links that are most frequently accessed by other Internet users. When it comes to topics of public interest, such as news, music, etc., such recommendations obtained by the statistical method are very convenient and useful. Such services, in particular, are provided by the domestic Rambler service.
2. Search Techniques
2.1. Simple search
Each search engine (PS) provides its own search methods and has its own characteristics in the rules for recording combinations of keywords. However, there are common elements equally true for most search engines. Typically, all PS allow the search for Web-documents for keywords that are specific to the desired document. Choosing such words is often a non-trivial task.
As a rule, the indication of one keyword is insufficient, and then the question arises of how to ask their respective combinations. Suppose, for example, we want to get information about the Russian Nobel Prize winner in 2000, Zhores Alferov. Specify only the last name in the search field
will lead to the discovery of a huge number of documents, most of which have nothing to do with the physicist of interest to us. By asking two keywords in the search field
separated by a space character, we must keep in mind that different search engines react to this character differently. Most PS consider the space as a sign of the logical operation "or" (OR) (these include Yahoo, AltaVista, etc.). Therefore, a search for a combination of words Zhorez Alferov will not reduce, but, on the contrary, will increase the number of documents found by the search system: all documents will be found where either the word Zhorez, or the word Alferov, or both of these words are found together.
In such cases, for a more adequate search, you can use quotation marks around the keywords that define the exact combination of characters enclosed in them:
"Zhorez Alferov".
However, at the same time, documents that contain a combination of these words in a different order (Alferov Zhorez) will not be found, because everything enclosed in quotation marks is a single phrase, and the search system will look for documents with an exact match of all the symbols of this phrase.
In order to find only those Web pages on which all our keywords are present at the same time, you need to put a plus sign in front of each of them. For example,
Zhorez + Alferov
will lead to finding Web documents where the word Zhorez and the word Alferov are necessarily present, not only in any order, but at any distance from each other (in the latter case, there may not be any logical connection between these words in the found document) .
The minus sign before the word excludes all documents that contain it, which in some cases can be very useful. For example, if we need to find different works on geometric, but not wave optics, then we can specify such a combination of keywords
Light + wave optics
It must be borne in mind that many words can have the same basis, but different endings (for example, indicating the plural in english language, case ending in Russian, etc.). In this regard, many search engines, having received a query in the form of a sequence of keywords, normalize it: discard all words consisting of less than four characters from this query (for example, the English preposition of), and also discard various endings and suffixes.
For example, in order not to miss a document that includes the phrase "In light optics in geometrical optics ...", the search engine may reduce the above query to normalize to
Light + optic * -wave * (1)
Here, an asterisk (*) denotes any combination of characters after the root of the corresponding words.
Since not all PSs carry out such initial processing of a client’s request, it is advisable to set the request in the form (1), that is, use the asterisk symbol to indicate possible variations of the endings of keywords.
You need to keep in mind some difference when using capital (lowercase) and lowercase (lowercase) letters in keywords. Usually, a search in small letters takes into account matches when both the capital letter is in the text and when it is small. Spelling keywords in capital letters means searching for documents containing the word in this form.
It can be very useful to search for keywords only in the headers of Web pages, since the importance of the title of a document is usually more than the importance of its text. In different substations, the search for keywords only in the headers of Web pages is specified using different service words: in AltaVista this word is title :, in Yahoo! - t: in Rambler - $ title :, etc.
2.2. Advanced Search
Simple search methods do not always allow us to efficiently find the Web documents we need, and therefore search engines provide the client with the ability to use the so-called advanced search tools. Queries for advanced search are built from keywords associated with signs of logical operations, and look like Boolean expressions used in programming languages.
In addition to the standard logical operations OR ("or"), AND ("and") and NOT (negation), the (and is very effective!) NEAR operation is used, which determines the degree of proximity of keywords to each other in a Web document.
When performing complex queries, it is important to understand in which order the above operations are performed, that is, what is their priority. In the sequence OR, AND, NOT, NEAR, the priority of operations increases from left to right. The execution order of individual elements of a complex query can be changed using parentheses, as is customary when writing Boolean expressions in programming.
Unlike simple search tools, advanced search tools are much more standardized for different search engines. The great advantage of the advanced search is also the flexibility of the possibilities of constructing the request offered to the client, and a significant drawback is its much slower operation compared to a simple search.
OR (operation "or") performs the same function as the space character in simple search queries in most PSs. For example, request
leads to a search for documents that contain either the word bush, or the word modes, or both of these words at the same time.
AND (operation "and") leads to finding documents in which both words associated with this operation are necessarily found, but at the same time they can be at any distance from each other. As a result, it may turn out that the document does not have any logical connection between the two given keywords. For example, in response to a request
search engine AltaVista gives links not only to relevant scientific works on nonlinear dynamics, but also to individual chapters of the famous science fiction novel by G. Wales, “The Struggle of the Worlds,” which, of course, have nothing to do with the subject of the search.
NOT is a negation operation that excludes those Web documents that contain an unnecessary phrase (thus, this operation in a complex search plays the same role as the minus sign in a simple search).
NEAR (a logical operation indicating the degree of proximity of keywords to each other) is one of the most convenient advanced search commands. In different search engines, the concept of word proximity is different. For example, AltaVista considers close words that are separated by no more than ten other words. Some other substations allow explicitly indicating the degree of proximity when recording a NEAR operation, that is, they allow you to determine the maximum allowable number of extraneous words that can stand between two keywords associated with this operation.
Type request
will lead to a search for documents in which the two specified keywords are close enough to each other, and therefore, most likely related in meaning. For example, in the text of a Web page there may be a phrase: "Bushes of normal modes ..".
Zhores NEAR Alferov
will lead to a search for documents that contain the phrases Zhores Ivanovich Alferov, Alferov Zhores Ivanovich, etc. Note that when using the NEAR operation, the order of the keywords in the document cannot be specified, which, however, is rather not a disadvantage, but an advantage, and this is clearly seen from the query just quoted.
As already mentioned, using the above logical operations, you can specify a search query in the form of a complex logical expression.
Despite the existence of some general principles for organizing the search for Web documents, various PSs can differ very much from each other according to the capabilities provided to the client, according to appearance of their home pages, etc., which is why it is advisable to get to know them when working directly on the Internet.
As an example, below is a very short, schematic description of the two currently most popular substations Yahoo (thematic catalog) and AltaVista (automatic index).
3. Yahoo Theme Directory
This system was one of the first to appear on the Web, and today Yahoo is working with many manufacturers of funds information retrieval, and its various servers use different software. Search call yahoo systems can be done using the address http://www.yahoo.com.
Note that browsers usually allow the possibility of a not complete set of addresses. For example, in order to call Yahoo, you can type only the word Yahoo in the address field, and the rest of the address is automatically added by the browser.
The Yahoo homepage provides the customer with the opportunity to access two main methods of working with this search engine - to search for Web documents by keywords, the set box of which is located to the left of the "Search" button, and to search using a hierarchical tree of various sections (categories) below.
Note that in both cases, the search for a link to the desired Web-document occurs in the same database, but in different ways.
Having opened the section of the thematic catalog of interest by clicking on its name, we will see new page Yahoo, which has exactly the same structure as the main page: it contains a search field for keywords and a list of subsections of the section we selected, etc.
You can also see on the Yahoo homepage advertisements, various additional categories, such as news, which contain, in particular, weather information, etc.
If the total number of links found by Yahoo is large enough, then the list of these links is divided into chunks. By default, such a portion contains 20 links, but this number can be changed by referring to the search options page, the launch button of which is located next to the search button "Search". There you can redefine the role of the space between keywords (whether to consider it a logical OR operation or a logical AND operation), etc.
On the options page there is also a switch that allows you to enable or disable the search mode for whole words. In Substrings mode, Yahoo will find all the links in which the word we have indicated is not only in itself, but also part of other words, for example, a search for the word "art" (art) will work on the word "department" (department, department, etc.) . d.). By default, the Substrings mode is set so that the user is not forced to enter each noun in a single and in plural (that is, with the end of "-s"), etc. On the contrary, in the Complete Words mode, the keywords we ordered are only found if they are limited on both sides by spaces or punctuation marks.
Yahoo search engine searches for links to documents matching your query in several various bases data, primarily category names and Web site headers. If the necessary links were not found in this way, Yahoo will automatically organize a search in the database of individual Web pages. The client can order a search in one of these databases by clicking on the buttons that are located below the keyword entry field. Yahoo organizes the search results according to several criteria that determine the rating of this link. A higher rating is assigned to documents in which keywords occur more times in which they appear in the heading or if the link corresponds to an older section in the hierarchical category tree.
At the end of the search results page, Yahoo offers to use the services of several other search engines if the client is not satisfied with the results of this search. Such links are convenient because the Yahoo system, when accessing them, will itself enter our keywords in the request form of another search engine called in this way. In conclusion, Yahoo provides about one million links to Web pages and this is just over 0.1% of the total web space.
4. Alta Vista Auto Index
You can call this search engine at: http://altavista.digital.com (for many browsers, just type altavista is enough).
Alta Vista has one of the largest databases in the class of automatic indexes, and the most powerful and flexible rules for building queries. At the same time, Alta Vista has both a simple search system and an advanced search system, the button of which is located below the keywords input field.
It is also possible to search for information using the category catalog, which is similar to the Yahoo system directory, and search by keywords can only be carried out within a certain category.
You can search for Web documents by keywords in the database for WWW pages or in the teleconferencing database (Usenet). To select one of these databases - WWW or Usenet content - use the drop-down list that can be called up using the button located under the title bar of this system on its main page.
When using the simple search of the Alta Vista system, it is necessary to take into account its differences from the corresponding means of Yahoo! Indeed, by default, Alta Vista, unlike Yahoo, is looking for occurrences of whole words: the ordered term should stand apart in the Web document, and not be part of other chains of characters. If you need to find all occurrences of this keyword, even when it is part of other words, you need to use the * symbol (this symbol can only be at the end of the keyword and replace no more than five letters). For example, a query like Ada * will lead to documents that contain the words “Ada”, “Adam”, “Adagio”, etc.
The search engine Alta Vista, like most other search engines, offers the client a number of additional featuresin particular, it allows you to find only those Web documents in which the specified keywords are found only in hypertext links, document headers, in their URLs (which makes it possible to find all Web pages located on the server with this address), and so on. etc. For this, special commands are used in Alta Vista: Anchor, title, etc. Such opportunities can be used both separately and together with each other.
The advanced search form differs from the simple request form in the presence of two fields. The second of them - Results Ranking Criteria - is completely analogous to the input field of the simple search form, and you can use the same special expressions, quotation marks and signs +, -, * in it. However, here this field plays only an auxiliary role, determining the sorting order of the results: documents containing keywords from the Ranking field will be the first in the list.
The keywords for the actual search should be entered in the first of the fields - Selection Criteria. Queries in this field are constructed according to the rules described above using the operations NEAR, NOT, AND, OR. In addition, at the bottom of the search form there is a field for entering dates that allow you to set the time interval in which documents of interest to us were created or changed.
We note about the peculiarities of searching for documents in Russian in Alta Vista in Russian that it makes no sense to search for documents by Russian keywords in the Yahoo catalog, since the employees of this service do not speak Russian.
5. Finding information in conferences (Usenet)
WWW pages are the largest and most valuable, but not the only source of information on the Internet. Of great interest is the Usenet newsgroup system, which publishes more than 100,000 messages from around the world every day.
If a client is interested in a particular topic, he can simply subscribe to the appropriate newsgroup. However, if he wants not to discuss his problem with living people, but simply to find out what is known on a particular issue, you can use the systems auto search in the Usenet content. Alta Vista maintains a separate index for more than 10 thousand newsgroups, to search in which you only need to switch the search switch from the "Web" value to the "Usenet" value (all the rules for compiling a request and setting options are the same in both of these cases). The search results are a sorted list of article headings, the full text of any of which can be obtained by clicking on its heading.
Worldwide considered the most best service to find information in Usenet conferences DejaNews server (http://www.dejanews.com). Among Russian-speaking, the RusNews server (http://news.corvis.ru) stands out, which is also a news server containing more than 2000 news groups. There is also a similar Russian server TELA-search (http://tela.dux.ru/news.html).
Documents with answers to frequently asked questions (Frequently Asked Questions, FAQs) are a completely unique source of information. Such a genre of questions and answers perfectly introduces a completely unprepared reader into the very essence of the matter. If initially lists of answers to questions existed only for teleconferencing groups, now documents with the heading "FAQ" are used for clients of a wide variety of servers and services. Articles and reviews are written in this genre, and firms and organizations promote their goals and aspirations. If the client needs to quickly become familiar with the new field of science, technology, culture or politics, it is advisable to start by reading the "FAQ" section of the appropriate Usenet newsgroup. And although one cannot acquire too fundamental knowledge in this way, one can quickly get used to terminology, learn about the most burning problems and often get an almost exhaustive list of references.
6. Domestic search services
The Russian Internet sector is currently booming, and although domestic search engines still lag behind the corresponding foreign systems in terms of the volume of their catalogs and indexes, they are not inferior to their foreign counterparts in some indicators (primarily the use of new technologies in processing search results), and in some cases surpass them.
First of all, we point to the automatic Aport 2000 index and the thematic catalog @Rus (Atrus) located at the following addresses: http://www.aport.ru/ and http://www.atrus.ru/, respectively. The two systems are in partnership. Indeed, when, as a result of a search, Aport 2000 displays the address of a Web page, it may be accompanied by a brief description of the corresponding Web site taken from the @Rus directory. On the other hand, when filling in the Atrus catalog, tools from the Aport search engine are actively used. From the client’s point of view, however, these search engines are still independent means of obtaining information. Note some of their advantages. Aport 2000 uses the currently most effective rating system by the number of links leading to this resource (by citation index). The Atrus search system provides the client with a convenient catalog-portal "My @Rus", which the user can configure to quickly receive the information he needs most. The configuration tools for this directory also allow you to disable all unnecessary on the main page of the search system, which makes working with it especially fast and convenient.
6.1. Rambler ( http://www.rambler.ru )
Rambler search engine has one of the largest indexes in Russia, but it gained its main popularity primarily as a rating system. It allows you to quickly identify the range of Web sites that provide information on a given topic, and evaluate their popularity by the number of visits by different Internet clients over the past 24 hours. Although the number of visits to this Web site does not always indicate the true value of the information available on it, in the case of topics of public interest, such a popularity rating can be trusted.
By default, only those documents are found in which all the keywords that we set are met, that is, the space between the words is perceived as a logical AND operation. However, this space value can be redefined to match the logical OR operation (as is the case with Yahoo or Alta Vista by default). To do this, select the option “Query words: any” in the advanced search form.
To exclude documents containing certain words, the latter must be indicated on the corresponding field of the advanced search form.
6.2. Yandex ( http :// www . yandex . ru )
The Yandex search engine is distinguished by its powerful advanced search tools, as well as a number of technological achievements, for example, the presence of an intelligent mechanism for morphological analysis of words, which is especially important for the Russian language. Regardless of the form in which the keyword was written in the request, Yandex will take into account all its forms. For example, if the key is the word go, there are links to Web documents containing the words go, go, and even walked. However, it is possible to search by the exact word form, for which it is necessary to put an exclamation mark “!” Before this word form.
A few words typed in the query, separated by spaces, means that all of them must be included in one sentence of the document to be searched (that is, the space acts as a sign of the logical AND operation).
It should be borne in mind that in Yandex Yandex, the AND operation can also be specified explicitly using the “&” symbol (but not using the word AND!). Doubling this character, that is, using the “&&” symbol, leads to the extension of the AND operation to the entire document (that is, words associated with && must be present within the entire document). The symbol of the OR operation in the search engine in question is the “|” sign (but not the word OR itself).
In Yandex Yandex, you can adjust the distance at which the specified keywords are located in the Web document. For example, request
physical / (- 2 4) education
means that the word physical can be located to the left of the word education (at a distance of a maximum of two words from it), and to the right (at a distance of a maximum of four words from it).
CompTek, the company that created Yandex Yandex, provides free of charge for corporate clients (organizations) a lightweight version of Yandex.Site, which indexes the contents of a Web site. This is convenient for owners of those Web sites who would like to organize a local system for searching information within their own site.
The Yandex search engine has a very good description in the “Help” section, which is highly recommended to look before using this system.
7. File Search
Among the special file search systems on the Internet, there are analogues of the previously discussed thematic directories (such as Yahoo) and automatic indexes (such as Alta Vista). Of course, these search engines do not provide the client with the files themselves, but only lists of links to them.
One of the most popular search services such as subject directories for searching files is shareware.com at http://www.shareware.com. This system classifies files according to only one criterion: for which operating system they are intended, but it stores descriptions of all files compiled by people. The shareware.com homepage is organized similarly to the pages of search engines that we have already reviewed. It offers the client various types of searches, and keywords can contain a * character that matches the sequence of any characters. The search is performed both in the names and in the file descriptions. You can specify a lower search threshold to get links to files created no earlier than a given date, and choose how to sort the results by date or alphabetical order of file names. By clicking on the file name in the list of results, we will get a number of links to Internet sites where copies of this file are stored, indicating the reliability of these servers and the time required to download the file, depending on the bandwidth of our channel.
Unlike the shareware.com catalog, the Archie search engine is an automatic index similar to Alta Vista. The list of anonymous nodes for Archie has to be kept by people (it can be found at http://hoohoo.ncsa.uiuc.edu/ftp/). A search in the Archie server database is done using keywords, which in this case are simply file names or name fragments.
The waiting time for communication with popular FTP sites (such as the rich collection of Windows programs (ftp://ftp.winsite.com)) can be very long, which is why the Internet usually has exact copies or "mirror images" "(mirrors), and search engines provide the addresses of all these mirrors.
A directory containing public files is almost always called pub. In most archives in each directory there is a special file with short ones — usually no longer than one line — a description of each file in this directory. Such a file can be called 0index, 00index, etc. (zeros are assigned to the file name so that it always falls in first place in the list of files sorted alphabetically).
8. Sources of specialized information
There are information companies providing electronic information services. For example, Knight-Ridder (KR) is the world's largest information company, providing online access to its services. It brings together such world-famous services as DialogInformationService from the USA and DataStar from Europe. Using the Internet as a medium to distribute its services, KR was able to automate key points their activities, improve customer service and, most importantly, expand the market for their services. All this ultimately led to the fact that KR became the world leader in the field of electronic document delivery and information service.
It has its own information retrieval system on the Internet from IBM - InfoMarket. It combines the means of obtaining information and managing payments with access rights.
However, at the initial stage of mastering the space of the Internet, one cannot do without an independent search for information. Web site addresses that are well-established sources of business information can be very useful here:
www.kentis.com is a KentInformationSystem server whose staff helps accounting and finance professionals use computer techologiesespecially the internet;
http: //www.promotion.aha.ru- on-line magazine for marketing on the Internet;
http: //www.inter.net.ru - the Internet magazine, regularly publishing material on marketing and advertising on the Internet;
http: //clickz.com is a magazine entirely dedicated to Internet marketing.
9. Search for individuals on the Internet
It is easiest to find information about a person if he has on the Internet his own personal page (personal home pages), which usually has his photo, e-mail and mailing address, phone, etc. Often, such a page contains a brief biography of the author , his hobby, etc. One of the largest systems for finding personal pages is called Who'sWho and is located at http://web.city.ac.uk/citylive/pages.html.
There are also extensive directories of email addresses of various people who use by email (e-mail). The leadership here seems to belong to the Four11 catalog at http://www.four11.com.
We also mention the WhoWhere catalog (http://www.whowhere.com), which even searches for similarities in sound or spelling of surnames (for example, “Kirsanov”, “Kirsanoff”, etc.).
The domestic catalog of electronic addresses is located at http://www.botik.ru/~intermap/form.html.
Absolutely unique is the All-American address directory at http://www.databaseamerica.com, which provides the coordinates of any of the 90 million US residents and any of 10 million American companies.
10. Metasearch
Databases of different search engines to a large extent do not overlap. Therefore, to search for sufficiently rare information, it is advisable to refer not to one, but to several substations. However, the rules for processing requests for different PSs, generally speaking, differ from each other. In order not to turn to different search engines in turn and not think about specific rules for making a request for each of them, the so-called meta-search systems were created.
Having accepted the customer’s order, set using keywords in accordance with its own rules for its design, the meta-search system will write it in the forms of different search engines, send these forms and will wait for a response. When all search engines send the search results, the meta-search program will put them into one document and send it to the user. These meta-search engines include MetaCrawler located at (http://metacrawler.cs.washington.edu:8080), which sends a request to 9 different search engines (including: Yahoo, Alta Vista, Lycos, Excite and etc.). In case of different interpretations of the same options in different search engines, MetaCrawler even provides the ability to check the search results: before giving the link to the user, he will independently look at the document and check if it matches the query conditions - as MetaCrawler understands them. Of course, this check mode greatly delays the receipt of results, but it allows you to protect yourself from broken links as well as meaningless results. Note that you can set the waiting time on the MetaCrawler request form: the list will include only those results that have arrived from various search engines at this point.
11. Effective information retrieval
After a detailed study of the main features of the tools, we turn to the problem of search efficiency. The main parameters of search efficiency are:
Completeness of the search as a ratio of the number of documents found to the total number of relevant documents;
Search accuracy - the ratio of the number of relevant documents to the total number of documents received;
Relevance of links to documents - the existence of documents found on the network at the moment;
Search speed.
There are various search tools on the Internet with different functionalities. The quality of the search, therefore, depends primarily on the parameters of a particular search system, for example, on the size of the index, on the search method (refinement of topics or search by query), etc. Further, when working with a specific search system, you need to have an idea of \u200b\u200bthe methods for compiling queries, and know the necessary operators.
Thus, we can distinguish the following factors affecting the effectiveness of the search:
Properties and features of the search engine;
The quality of the wording of the request by the user.
Now consider how to better prepare the user for the compilation of the request. First of all, it is necessary to conduct a comprehensive lexical analysis of the information that needs to be found. Then it is advisable to compile a set of keywords (if necessary, in several languages) in the form of separate terms and phrases specific to your subject area.
Actions:
Selection of a search tool;
Accurate wording of queries using operators supported by this search tool;
Sending test requests;
Analysis of search results (by the number and relevance of links);
If necessary, adjustment of the request;
Repeated search;
Based on the foregoing, we can distinguish the following methods of effective search:
Search for general information in directory search engines. - Search for highly specialized information in search engines. For a more extensive search, it is clearly not sufficient to use only catalog systems with limited number described resources. In addition, highly specialized information in directories may simply be absent. Therefore, it is necessary to search for such information in search engines with large indexes.
Use operators or an advanced query form to narrow your search. To conduct a high-quality search, you need to familiarize yourself with the query language of a particular search engine. Effective and in a simple way The solution to the problem of making a high-quality query is to use the advanced search mode.
Using the search function among found resources. Most search engines support the ability to search within the results.
The use of metasearch engines. These search tools send your request to several search engines at once and from each system they receive several of the most relevant links.
Search for answers to questions in newsgroups. If you wish, you can contact the specialized news group with a specific question about assistance.
Subscription to specialized mailing lists, etc.
Conclusion
In conclusion, we can say that a single optimal Internet search technology does not exist. Depending on the specifics of the necessary information, appropriate search services should be used to find it. It must be remembered that the more competently the search services are selected and the request for information search is compiled, the better the search results will be.
Literature
1. Informatics and information technology / Ed. Romanova Yu.D. M .: Eksmo, 2008
2. Stepanov A.N. Computer science. St. Petersburg: Peter, 2002
3. Mayechak B. Information search on the network // Internet for children from 8 to 88. M .: Interekspert, 2002
4. Chechin G. M., Polozhentsev E. V., Nizhnikova S. V. Information search on the Internet. Rostov-on-Don: Russian State University, 2001
5. Dikansky E.Yu. Mastering the Internet: A Practical Course in Information and communication technology for novice users. M .: Ileksa, 2001
6.http: //www.dist-cons.ru/modules/searchinf/index.html
7.http: //www.seonews.ru/masterclasses/detail/29812.php
8.http: //www.gdenet.ru/bibl/technology/transmission/5.1.html
Lesson 73. Internet Information Search Technology Objectives: to master the basic principles of the organization of search activity in the global network; have an idea of \u200b\u200bthe search capabilities using a browser and the built-in capabilities of search engines. Lesson I. Organizational moment II. Actualization of knowledge - What opportunities does the Internet offer for searching information? (There are several ways to search for information on the network: by creating a query in one of the search engines; using directories and classifiers on one of the sites of the desired subject; using metasearch tools.) - List the names of Russian-language portals providing search tools? (Yandex is the most popular site, and Rambler is also popular.) - What are the differences between existing search engines? (Different search engines suggest different approaches to finding information. Some allow you to find information on keywords in the text, others offer systematized data and search for the desired data on the proposed annotations, etc.) - What are the criteria for the effectiveness of search engines. (The effectiveness of search engines is determined by the following characteristics: index volume; update period; presentation of the document during indexing; indexing depth and restriction on the number of pages of one domain; features of the organization of input of the request; ranking of documents; output of additional information; restrictions scopes of search robots.) III. Lesson Theoretical Material Search can be organized in different ways, and one of the problems is to reduce the level of so-called information noise. It should be noted that the search and selection of information in electronic media does not apply to ordinary human skills. This should be specially taught, to help not only the student, but also the teacher, especially those who are new to these skills, search technologies, and the ability to formulate a request. It requires mastering the fundamentals of mathematical logic, understanding that the more precisely the request is formulated, the higher the relevance, i.e., the correspondence of the answer to the request and the lower the level of information noise, which can be spent sifting out over several days of work on the Internet. In order to find the necessary document in the vast ocean of information on the Internet, you can use specialized service services that allow you to find a document using keywords. They are called search engines. The search engine of these systems regularly scans information on the network, navigating through the available links. If any page does not have external links using hyperlinks, then the search engine cannot detect such a page. In addition to search engines, there are metasearch engines. They do not have their own search engines, but use the capabilities of other search engines. The result of the search in the case of working with the metasearch system is a multitude of documents reflected on the pages of the used search engines. Search engines are presented to users in the form of web pages with convenient navigation. The bi860 ™ system address is enough and the necessary page will be provided to your services. Another possibility, built into the browser, is presented on the Toolbar in the form of the “SEARCH” button, which allows not only entering words for the search through the ready-made form, but also allows you to select the most popular search services. In order for the document relevance to be high, it is necessary to use the following nuances for all these search engines: 1. The keywords tag should not be longer than the BDO characters; 2. Up to 40 words (best phrases - for example: search engine). No more than 5 repetitions. 3. Focus on 2-3 key phrases. 4. They should be in the keywords tags with a small letter, in the description tag with a capital letter, and in the title (heading about\u003e large). Example:
<иЧ1е>Search Engines: Comparative Characteristics<ЛШе> <1ит1>Definition of search engines, the main characteristics of search engines Now relevance to search query "Search engine" will be very high, this document will be located on iB top Yu "until it is replaced by newer sites with the same keywords- Yes\u003e just remember that in the body of the page these words should be repeated in different places. IV. Implementation of the practical task 1. Enter the document that is the first in the list of search results for the keyword “Search Engine” and1 determine how many times the word search engine appears in the body of the program. 2. Select keywords to search for information on the topic “Opportunities for network technologies”. Determine the relevance of the documents found. V. Lesson summaryLesson 74. Types of search engines and their features
Objectives: to have an idea about search engines and their distinctive characteristics; learn how to use search engines to meet their own information needs.During the classes
I. Organizational moment II. Updating knowledge - What features does the Internet search engine provide? (The search system has powerful capabilities: a search engine and a database. A search engine scans the network and saves images of documents in its database. If a document has been deleted or moved, it can be viewed in a saved document mode.) - What reflects the relevance of the request? (Relevance is a characteristic that reflects the correspondence of the documents found to the request.) Щ. Theoretical material of the lesson The lack of a clear centralized structure on the Internet made it more chaotic in general. There are more and more new servers, where huge arrays of information are stored. It is not possible to search for information by entering only the finished address in the address bar. Therefore, the issues of information search are becoming very relevant, and over the years the problem will only increase. To carry out a search on the network, search engines are used, the main purpose of which is to facilitate the user the process of searching for information, not only on WWW servers, but also on FTP, Usenet and other Internet resources. There are several thousand search engines on the World Wide Web, among which there are both well-established and less well-known. Among the most famous search engines can be called among foreign ones: AltaVista, Google, HotBot, InfoSeek, Lycos, WebCrawler, Yahoo and others; among Russian: Rambler, APORT, Yandex, etc. Each search engine has both advantages and disadvantages. The criteria for choosing a search engine can serve such characteristics as: the principle of the search engine; the convenience of use; external design; complexity of the query language; the presence of various advanced functions (control the format and ranking of the displayed information, translation of the entered keywords into another language, etc.); speed of work; the level of workload at specific points in time and reliability, etc. The choice of a search system for a specific application is determined by the purpose of the search, the nature of the information sought, the desired format of the output data, and the coverage width of the tracked server addresses on the Internet. Most popular search engines in the Russian-speaking territory (in decreasing order of the number of results of the search) are Yandex, Rambler, Google, APORT, Yahoo, etc. There are 2 main types of Internet search engines: index and classification (catalog). Index search engines (for example, AltaVista, Google, HotPot, APORT, Yandex, etc.), working in the automatic mode of updating their information, browse the contents of servers on the Internet, index all the information contained in them, and enter information about the location of words on the pages of sites in their database. Search catalog systems (for example, Rambler, Yahoo!, etc.) contain a thematically structured directory of servers, and are often replenished manually. Typically, the WWW page of the classification search engine also contains a field for entering keywords for a lo-claim in your own database. In the catalog search system, starting with a larger thematic section, gradually going down the sections, come to the link to the desired server. In some cases, it may be more convenient to use the first type of search engines, in others - the second. There are search engines that combine both principles of work. In particular, most index search engines have a catalog search system. Also, search engines can use some other principles of search methods. Many search engines have transformed into Internet portals, combining a large number of resources and services. On the pages of such portals you can read the news, TV program, learn about the weather, exchange rates and much more. To search for information on Russian-language sites, it is recommended to use Russian search engines, due to the presence of the Russian-language interface, the ability to search in Russian words, taking into account the peculiarities (morphology) of the Russian language, the proximity of the location of servers, etc. To search simultaneously in several search engines, you can use the so-called search meta-machines, which do not have their own search systems, but use the capabilities of other search engines. As you know, there are a lot of search engines on the Internet and finding the right information is extremely difficult. The lack of a single standard for the specification of the search problem on the Web leads to the fact that each node offers its own way of solving the problem. As a result, a user who does not have the necessary skills in creating syntactic constructions of queries to the search system either does not fully use the capabilities of each portal, or, having studied the functions of a particular node, constantly addresses only one. The metasearch system has another advantage, such as the use of a single query language, in some systems even the ability to translate keywords into other languages \u200b\u200bis included. Such search engines, receiving query results from other search engines, filter the materials received, remove duplicate links, and sort them by relevance. To search for foreign resources, you can also use Russian search meta-machines that turn to other search tools (including foreign), because having in most cases access to the high-speed channel abroad, etc. There are also search engines that specialize in searching for specific topics (for example, information technology, for music, for resources devoted to nature, etc.). And the easiest way to search is to enter the name of the company in the address bar, because all large forms in the address name use their own name. As final words, we can say that in order to obtain a high-quality search result, it is necessary to use the capabilities of various search engines. Regular use of only one of the systems can adversely affect search results. IV. Implementation of the practical task. Evaluate the capabilities of the three search engines according to a specific request, according to any criteria chosen to your taste. V. Lesson summary
Lesson 75. Basic concepts and characteristics of search results
Lesson Objectives:
know the main characteristics of search results;
have an idea of \u200b\u200bhow to increase the relevance of search results.
During the classes
I. Organizational moment II. Actualization of knowledge - What are the characteristics of search engines. (When choosing search engines, you need to pay attention to: the principle of the search engine, ease of use, external design, the complexity of the query language, the presence of various advanced functions (controlling the format and ranking of the displayed information, translating the entered keywords into another language etc.), speed of work, level of workload at specific points in time and reliability, etc.) - What are the types of search engines. (There are two types of search engines: index and classification. In the first case, the search-wik automatically scans the contents of the network and indexes all the information. In the second, a structured catalog is formed almost manually.) - What are the possibilities of the metasearch system? (The metasearch system provides the ability to use a single query language for several search engines.) III. Theoretical material of the lesson The totality of information and data needed by the user at a given time is called information need. If a person is able to understand someone else’s speech, proceeding from the context, then technical systems prefer to work with formalized data. There is a need to present information needs in the form of a set of certain concepts that should act as key concepts. When compiling this set, not only words are important, but also the relationship between them. This population is called a request. After entering the query, the search system selects documents, with the subsequent formation of the result according to certain criteria that are entered in the search parameters. The set of documents that corresponds to the request (issuance, response) is characterized by the property of relevance, i.e., an indicator of the level of conformity of the response to the request. A distinction is made between semantic and formal relevance when compliance is considered either with respect to the consumer’s information needs or with respect to the request. When scanning pages, the search engine determines: the number of words; frequency of occurrences of the request in the text; keywords; text at the beginning; page title the topic of the page The search engine is able to determine only the formal relevance of the document when the presence or absence of keywords in the document in the specified a) relation is the main search parameter. Other important characteristics The search result is complete and accurate. Completeness reflects the ratio of relevant responses to the number of all possible documents satisfying the consumer’s informational need. Accuracy expresses the ratio of a total of one hundred relevant responses to the number of all documents issued. Features of the search for information due to the features of the network itself. Network information space is a flexible, dynamic and constantly changing system. Search engines that analyze data in a given space (for example, on the Russian-speaking Internet) form their own database, which reflects the content of all documents. Moreover, the search engine on a site can only go if some other sites have links to this page . In the absence of cross-references, the machine is not able to detect a document on the network. Any search engine includes a special database that stores a description of documents at a particular point in time. It turns out that the search is actually carried out not in the entire network but in the existing database. The search results for one search are interesting, but using various search services. Each service you give your own data set. Which reveals negative trends that must be taken into account when performing a search. These are: a search engine database may not contain all the documents available on the network; saved documents may not be online. Search can be organized in different ways. The most naive way is to compose a query in the form of a simple set of words. For example, the pedagogical system is technology. The search engine will give out the addresses of documents containing three words; but do not prove that all three words will be found in all documents, that is, I can offer pages where the words “pedagogical system”, or “technology”, or simply “pedagogical” are found. That is, the author can be big, up to a thousand pages more. The golden rules for finding information on the network include the following requirements: 1. Take into account the features of the natural language 2. Avoid spelling errors. 3. Avoid a single word search, use the necessary and sufficient set of words. 4. Do not write in capital letters. 5. Exclude unnecessary words from the search. 6. Use advanced search capabilities. Two factors affect search results, such as: taking into account the possibilities of a natural language and the use of tools provided by search engines. The features of a natural language include: Polysemy (semantic variety of words or combinations of words); Homonymy (different in meaning, but equally spelling words; Synonyms (differing in spelling and pronunciation of words, but identical in meaning). IV. Conducting laboratory work Laboratory work “Searching for information on the Internet” Task: find information describing the possibilities of the Internet Step 1: Select the keyword for the search Step 2: Determine the best phrase with the keyword Step 3 Select the search system Step 4 Connect to the network Step 5 Launch the portal’s main page with the search system Step 6 Enter the phrase in the search string is step 7. Analyze the level of compliance of the pages with the task. 8 step. Open links to specified pages - step 9. Save the pages for detailed acquaintance in working folder. V. Accomplishment of the practical task 1. Create a folder “Search Results” in own folder, l ^ hl, gtp, n, t-SECOND FIELD 2. Determine the addresses of the boundaries, ^ ki ^ i, using the log. callers this computer have been working lately ”ment 3. List the last five addresses in text D U“ Notepad ”; 4. Search for documents with the keyword “Search Engine”. Determine the number of documents found - Download the first of the documents found. Describe the level of compliance of the document found to your requests. Lesson 76. The concept of query language Objectives: to master the methods of optimal Internet information retrieval; Be familiar with search capabilities using the query language. Lesson progress I. Organizational moment I. Knowledge updating / Panel- - For what the Search panel is intended, pdK ss \\ иск _ и иск включает includes the ability to search datHHblx using „1 M1LU’ p _ _ personal search engines built-in browser by wu entered in the search bar. By default, the browser pc of the built-in meta-search page of Microsoft is addressable - What is the address bar of the browser for? The browser line allows you to access the site by a ^ Ryo in URL format or IP address.)\u003e Internet services? - What search tools do the service w y ™ provide, etc. * ™ m (You can use the search engine\u003e structured directories and meta-search systems-) List the English and Russian search engines? Among the English-language search engines, one can note: Google, Yahoo, AltaVista, Lycos, etc. The most popular Russian-language systems are: Yandex, Rambler, Aport, etc.) - What properties should a query have to take into account the user's information needs? The main properties of search results are relevance, accuracy and completeness. They characterize the level of correspondence of the response to the request, the ratio of the totality of relevant responses to the number of all issued documents and the ratio of relevant responses to the number of all possible documents. III. Theoretical material of the lesson Search engine tools include the query language, it is different for different systemsbut has certain salient features. Consider the query language of one of the popular Yandex systems. The nature and feature of this search engine is to take into account the morphology of the language, i.e., the search is carried out by all forms of the word or words in the query. For example, if the word “pour” is given, then the search will result in documents with the words “pouring”. It is worth noting that not all search engines have this “ability”. Query Language Syntax
| Syntax | Value | Example |
| Prohibition of enumeration of all word forms | pedagogical system (the words pedagogical systems will be excluded from the search) | |
| - | Mandatory presence of words in found documents | Teaching Council on + Fridays (pages should be selected where the word is found not only ped-advice, but also the prerequisite for the presence of the word "Friday") |
| (It is written with sparkling | Exclude a word from a search result | Methodological system-technology (documents will be excluded where all three words meet together) |
| Mandatory inclusion of words in one sentence | Pedagogical & System | |
| Search for any of the given words | Methodology | technology | methodical technique | |
| The requirement of the presence of the first word in a sentence without a second | Pedagogical - system (search results will not include documents where both words appear within the sentence) | |
| &<~~ | Search within a document | Pedagogical - system (search results will not include pages where both words appear in the document) |
| Search for sustainable phrases | “Pedagogical system” (a strict sequence of words is taken into account, the word “pedagogical system” will be excluded) | |
| Spacing between words in a sentence | Subject / 1 of the lesson (the numbers after the icon indicate how far the second word should be in the sentence. The sentences “today's lesson theme” will be excluded from the search) |
| Language syntax | Value | Example |
| / (nm) | The restriction on the distance, where n is the minimum and t is the maximum distance | Methodology / (- 4 3) technology (the word “technology” should be in the interval from 4 words on the left to 3 words on the right) |
| 0 | Expression Search | (methodology, technology) / + 1 (training, study) (the search results will include documents that include the expressions “training methodology”, “study methodology”, “teaching technology”, “study technology”) |
| $ title | Search for title information | $ title pedagogical system (the result will be documents where these words are used as a title) |
| $ anchor | Search for information on the name of links | $ anchor pedagogical system (if the document uses this set as a hyperlink) |
| $ Address | Search for information on address names | $ Address edu (documents will be offered where site addresses include the word "edu") |
| ~ # UBL \u003d "url | Exclude from the search of certain pages specified by URL | Information ~ # URL \u003d "wwwлnfoгmika.гu" (the search will be carried out everywhere except for the given site) |
| Wink \u003d "URL | Search for sites that have links to a given site | # link \u003d "" (the result of the search will be sites that have links to a given URL) |
| # image \u003d "file name" | Search by document for graphic file names | # image \u003d “comp *” (the request will provide links to documents with computer images) |
| # abstract \u003d "annotation" | Search for sites where a given set is found in meta tags | # abstract \u003d "KOMnbK\u003e Tep" (sites will be defined where the given word occurs when using the meta tag) |
| # keywords \u003d "keyword" | Search for sites where a given word is allocated as a key concept | # keywords \u003d "KOMnbK\u003e Tep" (sites will be defined where the word is highlighted in any way) |
| # Yn1 \u003d "subscription of graphic file" | Search by image caption, which appears when you bring the mouse to the active part of the screen | # hint \u003d “computen\u003e (sites will be defined where not just computer images are found, but those with a given signature) |