Most users of the Internet community begin their day with search engines, where they try to find the information they need and solve their problems. Unfortunately, search engines are often unable to accurately and fairly interpret resources. As a result, sites that are far from the issue to be resolved are often in the first positions of the search. At the same time, resources representing real benefits are "overboard" the search.
The reason for this situation is simple and lies in the technology for obtaining and presenting results by search engines. It should be understood that the main problem is the lack of clear rules that are accessible and open to all comers. The greater the uncertainty in the algorithms for generating search indexes (a black box), the less search engines reflect the process of generating real information. And accordingly, the lower will be the level of confidence in the search results of search engines.
It is not paradoxical, but this is not the fault of search engines, since they are obliged to hide the rules for constructing search indexes. This is the fault of the technology itself in organizing the search. At its core, search engine technology is aimed at a passive user. It is only necessary to register a site, then the search robot will do everything. He will scan the resource page by page, trying to analyze the content of each of them. The complexity of the user is minimal, which allows you to use different techniques for the "deception" of search robots at low cost of effort and money. In this scheme of work, search engines need to change the algorithms and rules for indexing resources and building a search index.
Of course, most users have used, are using, and will use classic search engines. It is simple, convenient and common. It’s a habit to use search engines.
General Information About Search Engines
Search system - This software provides access to a collection of poorly structured information. Focus on poorly structured data, i.e. data that cannot be represented in the form of a relational table distinguishes the search system from the DBMS.
In this definition of a search engine, information of various kinds is meant, i.e. text, audio, video, images, etc. However, it should be noted that it is the text data that is ideal for describing the full functionality of the search engine, because multimedia information search algorithms are primarily based on text search algorithms.
The main task of the search engine - minimize the time taken by the user to search for relevant information request. Relevance is one of the most subjective and confusing concepts in science. information retrieval. Most often they speak of relevance from the point of view of the user, and then the `` information relevant to the request "" and `` the information necessary for the user "" are one and the same. This is the relevance we are talking about in this section. The question is, what information does the user consider necessary? In some circumstances, relevant information can be defined as all information from the database related to the request. So, for example, if the user needs to know everything about a particular company, then he is interested in finding all the documents that mention this company. In other circumstances, relevant information is only that information that is sufficient to carry out a specific task of the user, for example, finding an answer to a specific question. If in the latter case there will be a lot of redundant data in the search results, i.e. data that are relevant to the request, but are not needed to perform this task, then the selection of the necessary / relevant information will take the user additional time.
Thus, traditionally two main characteristics are applied to a search engine: accuracy and completeness or rather, their dependence. Each time the user asks the system a request, thereby initiating a search, all documents in the collection of the search engine are divided into four parts. Accuracy determines one aspect of the search, namely how well the search engine is able to minimize the time it takes the user to search for relevant this request information. While completeness determines another aspect - how well the system is able to find information relevant to a given query. You can select the optimal query (s) when each document found is relevant and each relevant document is found.
Search engines when using the Internet play a very important role. So much information is concentrated on the Internet that its search is already turning into a separate task and is very time-consuming. Search engines provide thousands of links to a request instead of a few pages where the information you really need is available. The users of the World Wide Web, realizing the advantages offered by the possibility of analyzing spatial data, need a tool that allows quick and convenient search and access to digital images of the area and other spatial information, concentrated in many government, commercial and academic organizations.
A bit of history ...
Search engine (search server, search engine) - A special web site on which the user, for a given request, can get links to sites matching this request.
The search engine, as a rule, consists of two stages. The first - special program (search robot) or a person collects information from web pages and indexes them. When the user makes a request, the search proceeds by the pre-built index. The result of the search is the so-called search results - a list of links to documents (web pages) matching the query.
Most search engines look for information on Internet sites, but there are also search engines that can search for files on ftp servers, documents, and information in internal networks and other. AT recent times A new type of search engine based on RSS technology has appeared.
The work of the search system is based on the work of the “search engine”. The main criteria for the quality of the search engine are relevance, completeness of the database, and accounting for the morphology of the language.
Most popular search engines in Russia today are considered Google, Yandex, and Rambler.
The first search engine was Wandex, a defunct web site created by Matthew Graham of the Massachusetts Institute of Technology in 1993. A little later, the Aliweb search engine, which still exists, appears. First full-text search engine became "WebCrawler", launched in 1994. Unlike its predecessors, it allowed users to search for any keywords on any web page, since then it has become the standard in all major search engines. In addition, it was the first search engine that was widely known. In 1994, Lycos, developed at Carnegie Melon University, was launched.
Russian development search engines It began in 1996 with the advent of a morphological extension to the Altavista search engine, and the launch of the original Russian search engines Rambler and Aport. Soon, in 1997, the Yandex search engine was opened.
Today in the world there are several hundred diverse search engines that differ in their specialization, capabilities and search methods.
news
- 20/ 12/ 2005
TOKYO, Dec 20 - RIA Novosti, Andrey Fesyun. Japan will develop its own search engine for the Internet, as opposed to the growing popularity of the American system Google.
According to a department employee information policy Ministry of Economy, Trade and Industry Fumihiro Kajikawa, for this purpose a research group will be created with the participation of representatives of twenty universities and electronics companies.
"We do not intend to compete with Google or Yahoo, but we are thinking about creating a unique system exclusively for Japan," said Kazikawa. According to him, the system will be designed primarily for image search, in particular photographs.
The representative of the ministry said that the group will hold its first meeting next Friday, will submit an interim report on its activities to the ministry in March, and the final one in July next year.
- 09.2005
G.I. Ruzaykin
PC World :: News FeedOn the way to an inclusive information space, the problems of searching for information on the Web are becoming especially acute. This becomes apparent against the backdrop of technological advances in the development of the Internet, in particular regarding the delivery of information to the user (referring to the speed of data transfer, its volume and quality). That is why reports on the development of technologies and software products for information retrieval are so important in the IT market.
DVYGUN (www.dvygun.com) announced the release of a new version of the free personal search engine DVYGUN Smart Search 2.5.2.5 Beta, which allows full-text search in arrays of documents, messages email, multimedia files, on visit web pages and among contact information stored on the user's PC.
At the same time, the DVYGUN Smart Search program searches for the following types of information (files):
- email messages and Outlook / Outlook Express attachments
- files pDF formats, MS Word, MS Excel, RTF, HTML and text;
- data zIP archives, RAR, GZIP, CAB, etc .;
- images, music, and video files
- visited web pages, selected Internet addresses internet browser Explorer
- address book contacts in Windows and Outlook.
Data can be searched for both all types and favorites. Further narrowing of the search area is performed when specifying the search parameters. For example, for files they can be “File Name”, “Folder”, “Size” and “Date Modified”. The ranking of the documents found is carried out according to the level of compliance with the search query. For verbose queries, the contextual proximity of words is taken into account, so each document found is displayed in the search results along with a contextual quote, which in most cases accelerates understanding of its content.
To organize an instant search, DVYGUN Smart Search performs initial data processing in order to build a special database (index), on which this search is performed. Here are a few features of the implementation of this function in this program: search and indexing can go simultaneously; you do not need to wait until indexing is complete to start the search; the index is updated in the background, the program constantly monitors the user's actions, so that the changed and new data is immediately included in the index, i.e. updating search results; in case of insufficient system resources, the indexing process is stopped to avoid slowing down the user's computer.
According to the developers of DVYGUN Smart Search, checking their program for the presence and quality of search attributes (updating the index on the fly, calculating the relevance of results, tuning, indexing speed and supporting the morphology of the Russian language) puts it ahead of such well-known search engines as Google, Yahoo, Microsoft, Copernic and Blinkx. No competitor fully satisfies the requirements for the presence and quality of these attributes. The DVYGUN Smart Search program performs indexing at a speed of 5 GB / h and morphological processing of Russian and ukrainian languages. Unfortunately, not one of the well-known domestic and Ukrainian search engines is able to index so quickly. At the same time, developers attribute the small number of file formats processed by DVYGUN Smart Search to the disadvantages of this version: you can fix the problem either by purchasing the appropriate filters, or by developing them yourself.
The development of existing search engines is evidenced by a message from Yandex (http://company.yandex.ru/news/2005/0628) that the new version of Yandex.Server is running all popular versions of Windows and Unix , began to function faster. This expanded the group of products for full-text information retrieval and increased the speed of processing documents by one and a half times. The number of types of processed documents has been increased: now, in addition to the formats .txt, .doc, .rtf, .html, .xml and .pdf ,.xls, .ppt and.swf are supported. Also, the indexing speed of files has increased from 25 to 40 MB / s.
For users who need to manage the design of search results, they are offered a package for delivering a new version of this program at a price almost 2 times lower than before, for only $ 170. In addition, editions of this program for owners of Standard + and Professional + websites have appeared advanced features.
According to the Russian representative office of CONVERA (www.convera.su), next year its efforts in Russia will be aimed at promoting the new search engine Excalibur and developing a localized version of RetriewalWare 8.2. It will implement such standard functions as extracting entities from the text (in the first release they include geographical names, proper names, times, currencies, dates, numbers - telephone, credit cards and automobile, as well as the connections between them), adapters to Websphere, Sharepoint portal, Documentum, new Lotus, Windchill and Teamlink software packages.
This fall, Excalibur will appear in Russia. The most significant difference between this product and other similar global search engines is to clarify the amount of relevant information offered as a result of the search. Such efficiency is possible thanks to 12 million taxonomies built into the program, with the help of which information is processed upon request. In the process of processing the request, its taxonomic concept ( subject area), as a result of which all information is divided into two groups - relevant and irrelevant to the request. Moreover, the query results can be presented in the form of tables, graphic images, texts and information links, i.e. the answer becomes a reflection of the essence of the request and its relationships in the aggregate of documents proposed as a result of the search.
- March 23, 1998
New Internet Search EngineThe new search engine directory Newman Search for Information Technologies has been launched. Newman Search combines the virtues of crawlers and directories at the same time. All sources that are searched are grouped by topics "Computer Press", "News", " Computer firms"etc. Users can limit the search area to relevant sections, significantly reducing the" information noise "and the time it takes to find the right document.
The subject matter of Newman Search Web sites is limited exclusively to computers, the Internet and information technology. Preference is given to primary sources and sites containing systematic information (documentation, descriptions, tests, prices, opinions, news, press releases).
Newman Search is distinguished by daily operational indexing of servers - from 1 day (for the "News" section) to 7 days (for company websites) computer business) Whereas in the usual search engines, information updates have to wait for months.
The search is carried out taking into account the morphology of the Russian language and computer terminology. For example, if you look for “HDD”, the words “HDD”, “WINCHESTER”, “HARD DISK”, “HDD”, etc. will be searched.
Open conversion statistics form a kind of rating of computer websites for information content. Moreover, the rating is supported separately for each section of the type "News", "Computer companies", etc.
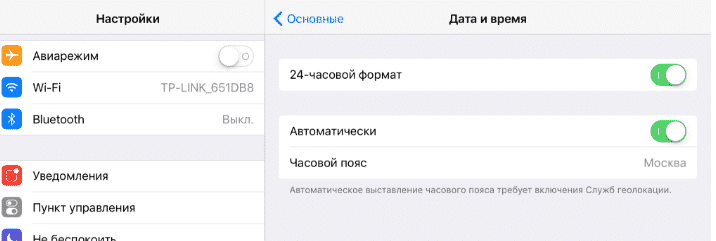
Yandex search engine
Yandex Search Engine History
The history of Yandex began in 1990 with the development of search software at Arcadia.
In 1993, Arcadia became a division of CompTek. In 1993-1994 software technology were significantly improved due to cooperation with the laboratory of Yu. D. Apresyan (Institute for Information Transmission Problems of the Russian Academy of Sciences).
In the summer of 1996, CompTek management and search engine developers came to the conclusion that the development of the technology itself is more important and interesting than the creation of search-based application products. Market research has shown the timeliness and great prospects of search technologies.
The word "Yandex" was invented a few years before by one of the main and oldest developers of the search engine. "Yandex" means "Language index", or, if in English, "Yandex" - "Yet Another indexer".
Officially, Yandex.Ru search engine was announced on September 23, 1997 at the Softool exhibition. The main distinguishing features of Yandex.Ru at that time were verification of the uniqueness of documents (exclusion of copies in different encodings), as well as key properties of the Yandex search core, namely: taking into account the morphology of the Russian language (including search by exact word form), search by distance (including within the paragraph, exact phrase), and a carefully developed relevance assessment algorithm (match the response to the query), taking into account not only the number of query words found in the text, but also the "contrast" of the word (its relative frequency for this document), the distance between the words, and the position of the word in the document.
In November 1997, a natural language query was implemented. From now on, Yandex.Ru can be accessed simply "in Russian", ask long queries, for example: "where to buy a computer", "genetically modified products" or "international codes telephone connection"and receive accurate answers. The average length of a request at Yandex.Ru is now 2.7 words. In 1997, it was 1.2 words, then users of search engines were accustomed to the telegraph style.
In 1998, Yandex.Ru got the opportunity to "find a similar document", a list of found servers, search in a given date range and sort the search results by the time of the last change.
In 1999, Yandex released a new search robot, which allowed to optimize and speed up crawling of Runet sites. The new robot made it possible to provide users with new opportunities - search in different areas of the text (headings, links, annotations, addresses, captions for pictures), restriction of search to a group of sites, search by links and images, as well as highlight documents in Russian. A search appeared in the catalog categories and for the first time in Runet the concept of "citation index" was introduced.
In 2000, the company Yandex was formed. Yandex was founded by the shareholders of CompTek, a company that created and has long developed the Yandex project. Ru-Net Holdings invested $ 5,280,000 and received a 35.72% stake in the new company. Shareholders also include management and leading search engine developers. The general director was Arkady Volozh.
All rights to the Yandex brand and the www.yandex.ru website, as well as to search technology Yandex and the family of software products of the same name. In addition, the recently launched project www.narod.ru was transferred to Yandex.
Yandex Indexing Management
Permissions and prohibitions on indexing are taken from the robots.txt file. Yandex supports the META tag robots, the NOINDEX tag, and the custom robots.txt extension, the Host directive. Permissions and prohibitions on indexing are taken by all search engines from the robots.txt file located in the root directory of the server. A ban on indexing a number of pages may appear, for example, out of a desire not to index identical documents in different encodings. The smaller the server, the faster the robot will bypass it. Therefore, it is advisable to prohibit all documents in the robots.txt file that do not make sense to index.
The Yandex search engine supports the robots.txt custom extension, the Host directive. The argument of the Host directive is a domain name (one valid host name that is not an IP address) with a port number (80 by default), separated by a colon. If any site is not specified as an argument for Host, it implies the presence of the Disallow directive: /, i.e. a complete ban on indexing (if there is at least one valid Host directive in the group).
This custom extension helps the search engine choose the right mirror for indexing. In fact, the Host directive specifies the main mirror for the site, while indexing all other mirrors is prohibited.
For compatibility with robots that do not fully comply with the robots.txt standard, the Host directive must be added to the group starting with the User-Agent entry immediately after the Disallow entries.
The Yandex search engine analyzes and follows the instructions of the META tag robots. To prevent indexing of certain parts of the text, they can be tagged.
Adding pages in the Yandex search engine
Yandex browses hundreds of thousands of Web pages daily for changes or new links. Resource owners can add their own site by filling out the AddURL form. Yandex browses hundreds of thousands of Web pages daily for changes or new links. Resource owners can add their own site by filling out the AddURL form.
Yandex indexes russian network, therefore, servers in the su, ru, am, az, by, ge, kg, kz, md, ua, uz domains are entered into the search engine. The remaining servers are entered only if the text in Russian is found on them, or if the resource owners convince the search engine administration that their server is interesting to users of the Russian-speaking Internet (this is usually done by writing to [email protected]).
Usually pages appear in the search database within a week after they appear or change. New pages entered into the database using AddURL will appear faster (if they are in the Russian-language part of the network and do not require manual verification).
The Yandex search engine is full-text, that is, only those words that are written on the pages of sites fall into its index (and become available for search).
In the list of search results, after the page address, text is displayed that consists of a title (title tag), description (meta name \u003d "Description" content \u003d "" tag) or the beginning of the document (if there is no such tag) and contexts - fragments of the old page text containing query words.
Indexing in the Yandex search engine
When Yandex discovers a new or changed page, it indexes it. In the process, the page is divided into elements whose contents are entered in the index. When Yandex discovers a new or changed page, it indexes it. In the process, the page is divided into elements (text, headings, image captions, links, and so on), the contents of which are entered in the index. This takes into account the position of the words, that is, their position in the document or its element. The document itself is not stored in the database.
Yandex indexes pages by their true addresses. This means that if redirect is on the page, the robot will perceive it as a link to the new address and put it in the indexing queue.
As standard required hTTP protocol, Yandex, having received information in the response header that this URL is a redirect (3xx codes), will add the URL to which the redirect leads to the list of addresses to bypass. If the redirect was permanent (code 301), or meta-refresh was found on the page, then the old URL will be excluded from the crawl list.
The Yandex robot stores the date of the last crawl of each page, the date of its change (sent by the Web server) and the date the last change was made to the search database (index date). It optimizes Web crawling so that it often visits the most modified servers. Yandex robot works automatically and usually reindexing occurs every two to three weeks.
Yandex robot monitors changes to already indexed pages on its next visit to the site. The robot has its own work schedule and it is impossible to change it.
Yandex indexes a document in its entirety: text, title, image captions, description, keywords and some other information.
Yandex robot bypasses the "dynamic" pages and treats them in exactly the same way as the "static" ones. In addition to standard HTML, the Yandex search robot indexes: PDF, DOC, RTF and Flash file formats.
Duplicate - This is the same text, under a dozen different addresses, depending, for example, on the way you navigate the site. Sites with a large number of duplicates are ruthlessly cleaned from time to time.
Site Mirrors
Mirror - partial or full copy of the site. The presence of duplicate resources is sometimes necessary for owners of highly visited sites to increase the reliability and accessibility of their service.
A large number of mirrors clogs search engine databases and leads to duplicates in search results. Therefore, when the Yandex robot detects several site mirrors, it selects one of them as the main one, the rest are deleted from the index. By default, the robot selects in the main mirror based on its own considerations. And usually not what the owner of the resource would like to see.
You can take a number of measures to select the desired site as the main mirror.
Firstly, you can remove non-essential site mirrors.
Secondly, on all mirrors, except for the one you need to choose as the main one, place the robots.txt file, which completely prohibits indexing the site. Or put robots.txt on the mirrors with the Host directive.
Thirdly, place a tag on the main pages of minor mirrors that prohibits their indexing and crawling by links.
Fourth, change the code of the main pages on non-primary mirrors so that all (or almost all) links from them deep into the site are absolute and lead to the main mirror.
In the case of the implementation of one of the above tips, the main mirror will be automatically changed as you bypass the Yandex search robot.
Yandex search engine working methods
The Yandex search engine contains in its index about each word of the text the number of the document, sentence, word in the sentence and the weight of each word. The Yandex search robot indexes pages and, based on the information on them, forms a search index.
All this information is used in the search. For each query, phrases are searched for (and get a higher rank) that exactly match the query, then sentences containing all the words in the query, etc. An important role is played by the relative position of the words. So, for example, if a four-word query does not have an exact answer in the database, sentences containing three words from the query in which the words are in exactly the same sequence as in the query will be ranked above. This makes it possible to solve a typical search problem - to search for a document by "inaccurate quoting."
Rambler Search Engine
Rambler Search Engine History
The history of the search engine "Rambler" begins in 1991 in the town of Pushchino, Moscow Region. It was there that the Stack company was created by a group of like-minded people. Headed the company "Stack" Sergey Lysakov. The company was engaged local networks and internet connection.
Already in 1996, Sergey Lysakov and programmer Dmitry Kryukov decided to develop the first Russian search engine for the Internet. Dmitry Kryukov came up with the name of the project - Rambler. Translated by Rambler means "wanderer, wanderer, tramp", which is in tune with the principle of the search engine robot.
On September 26, 2006, the rambler.ru domain was registered and on October 8, the Stack company activated the system. In the spring of 1997, Rambler s Top100 appeared - a rating classifier that estimates the popularity of Russian resources on the basis of objective data.
In June 2003, the company launched new version search engine, which differs from the previous one in two main parameters: the search speed has increased significantly due to the new system architecture, the search index is updated several times a day.
For those who know exactly what they are looking for and don’t want to spend too much time, a special concise version of the Rambler search was opened at r0.ru, (or, as they say, Arnold).
Rambler Association Mechanism
When someone makes a series of consecutive queries in the Rambler search engine, these words and phrases become interconnected - Rambler associations. Rambler search engine users have access to the Rambler association engine. Rambler Associations - These are thematically (associatively) related queries with the user's original query. When someone makes a series of consecutive searches in the Rambler search engine, these words and phrases become interconnected. And this sequence creates Rambler associations. In fact, this is the concept of "They also look for us."
On the one hand, using the Rambler association mechanism, the user can quickly refine or expand his request. On the other hand, a chain of typical associations reveals the shortcomings of the original request, its ambiguity, and “blurring”. As a result, a visitor to the Rambler search engine learns to ask correctly, without wasting time, that is, in fact, resorting to the help of the “collective mind”.
The mechanism of associations “They also look for us” is interesting to anyone who wants to see what thousands and thousands of network visitors think about. This is a search tool, as well as a source of valuable information for linguists and webmasters.
Rambler Search Engine Indexing Management
You can restrict the indexing of resource pages to the Rambler search engine through robots.txt or the META tag "Robots". The search engine’s robot Rambler is called "StackRambler". It is he who downloads documents posted on the Internet, finds links to other documents in them, downloads them again, etc. The StackRambler robot analyzes the robots.txt file and limits the scanning of the resource according to its instructions. Through robots.txt, you can restrict access to certain directories and / or files.
You can also limit the scanning of resource pages to a search engine robot Rambler through the META tag "Robots". The tag controls the indexing of a particular web page. At the same time, robots can be prohibited not only from indexing the document itself, but also by clicking on the links in it.
Adding Pages to the Rambler Search Engine
Rambler’s robot bypasses the Web through links and thus finds new resources. You can fill out a registration form. Rambler’s robot independently visits only sites located in the national domains.ru, .su, .ua, .by, .kz, .kg, .uz, .ge. If the site is located in one of the other domain zones (for example, in.com, .net or.org, or in other national domains), by default, Rambler’s robots will not visit pages of such resources. To add such resources of interest to Russian-speaking users, the number of scanned users must be addressed to the administrator of the search engine Rambler.
Rambler’s robot crawls the Web using links and thus finds new resources for indexing. You can also fill out a registration form in the Rambler search engine. Fields of this questionnaire - "Site Name" and "Description" are not used for search. They are intended to be read by editors only and are used in Rambler internal databases.
The robot scans the pages of the site within a day from the moment of registration (or finding a resource). At the same time, it immediately bypasses the site to a certain depth (it scans pages linked to by a registered page). The pages downloaded by the robot appear in the search database with some delay. Re-indexing of received documents is carried out at intervals of approximately two weeks.
Search Engine Indexing
When indexing by the Rambler search engine, only the information that the user can see on the page is taken into account. It is advisable to include the basic concepts and keywords for the site in the following HTML tags (in order of importance): title h1 ... h4 b, strong, u The more often the word appears in these fields, the more likely it is that Rambler will give a link to this document is closer to the top of the list of search results.
The maximum document size for Rambler robots is 200 kilobytes. Larger documents are truncated to the specified size.
The indexing program processes redirects (redirects), but only if the redirection is performed to the domain.ru or to the domains of some CIS countries.
Rambler processes all "dynamic" pages with names of the form * .asp *, * .php *, * .pl *, * / cgi-bin / *, etc. for the sites visited (according to top100), as well as sites containing unique information useful to users search engine. For other sites, only part of such pages is processed.
HTML snippets tagged are not indexed by Rambler.
Search engine Rambler can extract links from flash objects and therefore can process sites built on flash technology. However, the texts of flash objects themselves are not yet indexed.
When indexing, only the information that the user can see on the page is taken into account.
Hidden fields and all other fields except when indexing sites are ignored. The same applies to comments in the site’s HTML code. You should also not use invisible text in which the font color matches the background color.
The search takes into account the data of Rambler's Top100 The Rambler’s special robot twice a day adds new pages to the search engine database from all sites that participate in the Rambler's rating and have placed a counter on their pages. After changing the information in the rating of Rambler's Top100 its update in the search engine occurs within one to two days. If the site is registered in Pinterest, it will be on some requests, even if the information has been deleted from the index database.
The search takes into account information obtained from the Rambler "s Top100 rating if the site is registered on it. The number shows when this information was received. The information on Rambler's Top100 is updated almost every day.
Aport Search Engine
Aport Search Engine History
The official presentation of Aport took place on November 11, 1997. By that time, the first million documents located on 10 thousand servers were indexed in its database. The creator of the Aport search engine is Agama, a software developer for Windows platforms. It should be noted that Aport was created and continues to run under Windows (unlike most search engines). The linguistic developments of "Agama" were used to create the Aport search engine, in which at the time of its creation, the word morphology was taken into account and, at the request of the client, the query spelling was checked.
The Aport search engine was first demonstrated in February 1996 at the Agama press conference regarding the opening of the Russian Club. Initially, the Aport search engine only searched russia.agama.com.
The official presentation of the Aport search engine took place only on November 11, 1997. By that time, the first million documents located on 10 thousand servers were indexed in the Aport database.
The most important features of the first version of Aport were the translation of the query and search results into English and vice versa, as well as the reconstruction of all indexed pages from its own database.
In November 1998, the Aport search engine was acquired by Israeli citizen Joseph Avchuk (with the retention of the Aport and Agama brands). The real amount of the transaction was 55 thousand dollars.
In October 1999, at the computer exhibitions on both sides of the ocean, a fundamentally new search engine, Aport 2000, was fully integrated with AtRus (now Catalog Aport).
Aport 2000 was the first Russian search engine built on the basis of the results for individual sites. To divide resources into sites, information is used that Aport provides to the AtRus catalog or information entered into Aport by the owners of the resources.
Aport 2000 became the first Russian search engine to implement two basic technologies of the American search engine Google. Accounting for the "page rank" (Page Rank), which characterizes its popularity. The rank value is calculated by the number of links to the resource from the external Internet. The weight of a link from a popular site is higher than the weight of a link from a less popular; links that include query words have more weight than, say, the word "here." Request processing with analysis HTML tags pages. For example, text between h2 tags takes precedence over text between h6 tags.
Aport 2000 also took into account the occurrence of query words in the URL. Among the undocumented features is a higher priority for sites that have received the highest and elite league in the AtRus catalog.
And, finally, another Aport championship is the use of a paid zero line in the search results (by the way, Aport was the first among our search engines to buy such a service from AltaVista, which for a small fee gave its link first when it asked for "Russian Search"). However, in "Aport" you can’t buy not a zero, but simply a higher place for your site in the search results.
The organization of scalability in the Aport 2000 architecture is such that it is possible to split the Aport search base into several separate bases, each small Aport works on its own computer. Aport 2000 believes that the entire Internet is divided into fragments. After conducting a search in these fragments, the user integrates and gives a general answer. You can add new small "aportiki" by a not-so-complicated procedure. In cases of accidents of individual machines, integral results that are somewhat different from the standard ones are issued, which can be observed from time to time.
On July 31, 2000 Golden Telecom bought the Agama family of Internet projects, including Aport and AtRus, for inclusion in Russia-on-line and near-content projects.
In May 2001, the deal to change the owner of Aport of Golden Telecom itself was finally completed, Alfa-Bank became the new owner. NASDAQ at that time was in a rapid recession and there was no chance of reselling Internet projects for an acceptable amount. This led to the decision of the new Golden Telecom owners to minimize the cost of supporting expensive Internet projects.
Indexing Search Engine Aport
When viewing the contents of the server for indexing, Aport checks the robots.txt file and supports Robots meta tags. When viewing the contents of the server for indexing, Aport checks the robots.txt file. Thus, it is possible to limit the "activity" of the Aport on the server. The search robot Aport has the name Aport. This name can be used to limit indexing through robots.txt.
Also, the Aport search system supports Robots meta tags, which allow you to set the rules for the behavior of the robot on the individual page of the site and if it is not possible to modify the robots.txt file on the server.
Adding pages in the Aport search engine
Registration of a site in Aport is done from the Add URL page. Only the site root should be added. Registration of a site in Aport is performed from the page http://catalog.aport.ru/eng/reg/add.ple. This page is accessible via the Add URL link from almost any Aport page. Only the root of the site should be added, the remaining pages will be found by Aport via links.
Aport is a search engine on the Russian Internet, so you can add Russian-language sites to it, as well as sites that are directly related to the Russian Internet. In case of refusal to automatically add the site (for example, if the search robot does not find Russian-language text on its root page), you can request to add the site by e-mail: [email protected]
Resource Indexing by Aport Search Engine
Aport is a full-text search engine. This means that it indexes all the words that a person would see on the screen while viewing a specific page of the server. Aport periodically checks the sites available in its database and brings its database in line with the changes that have occurred there. The verification period largely depends on the specific site (taking into account its popularity, the dynamism of updating according to the data collected by the aport during previous visits to the site and a number of other factors).
From the moment a site is added to the Aport search engine until it appears in the search database, it takes from two to three days to two weeks. In some cases, (for example, in the case of unstable communication with the added site), this time may be slightly longer.
Aport indexes all static documents (in the Url of which there is no "?" Symbol) found by his search robot via links on the site. This rule may not be observed for large sites, as well as for sites seen in the use of search spam.
Documents containing the "?" In Url are selectively indexed by the Aport search engine. In this case, quotas are used for the number of such documents for each site. The quota size is calculated automatically depending on a number of conditions, in particular on the citation index of the site, and may, in particular, be zero for some sites.
It should be borne in mind that full indexing of a site can occur gradually, as well as the fact that the content of the database is the prerogative of the search engine and there are no guarantees for indexing (as well as the preservation of already indexed documents in the index) Aport does not.
Aport is a full-text search engine. This means that it indexes all the words that a person would see on the screen while viewing a specific page of the server. As a result, any word from the text of documents can serve as a criterion for a subsequent search.
For HTML documents, in addition to the main text of the document, the following are also indexed: document title (TITLE), keywords (META KEYWORDS), page descriptions (META DESCRIPTION) and image captions (ALT). In addition, Aport indexes, as belonging to the document, the texts of hyperlinks to this document from other pages located both inside the site and outside it, as well as descriptions of sites from the Aport catalog compiled (or verified) by editors.
Google search engine
This search engine is becoming better and more popular over time, but it is inferior to the above search engines. According to surveys, google data provides about 10% of all Runet search queries. Google accepts sites of any domain for registration, that is, it is not limited only to the ru zone. This, of course, is a very big advantage over competitors (in Russia). But Google no longer has any advantages and can’t even display words in the search results that are synonymous with the query. That is, if we ask on Google search query "anecdote", then Google will look for exactly that word on sites, while Yandex, Rambler and Aport will also take into account synonyms on sites and synonyms, for example, "anecdotes", but Google cannot do this.
Foreign search engines
- AOL Search
- Achla
- Altavista
- AltaVista (Digital)
- Austria NetGuide
- Austronaut
- Alltheweb
- Antisearch
- Ask jeeves
- AskAlex
- Anzwers
- Ausindex
- AustriA-WWW
- Baku Pages
- Brit index
- Compnet
- Copernic
- Cyber411
- Direct hit
- Daypop.com
- Excite
- England online
- Freeality
- FTP Search
- GBP Great British Pages
- Hotbot
- Handilinks
- Infoseek
- InfoMarket
- Infomine
- InterSearch Austria
- Interview
- Inktomi
- Inforia
- Guide.at
- Looksmart
- Lycos
- Light search
- Libanis.com
- Magellan
- Maxisearch
- Msn search
- Mixcat.com
- Meta-ukraine.com
- Metacrawler
- Northern light
- Netscape search
- Open directory
- Open text
- Qango
- Raging Search
- Realnames
- Search.com
- Seachuk
- Search.lv
- Search.iwon.com
- Submitit.bcentral.com
- Superpromo.com
- Search.escapeartist.com
- Surfgopher.com
- Slider.com
- Uk index
- Ukdirectory
- Ukmax
- Whatuseek.com
- Webcrawler
- Web wombat
- Yahoo
- 2kcity.com
Meta-Search Engine Architecture
Introduction
This article examines the architecture of meta-search systems and the basic principles of their work and construction using the example of the meta-search system MetaPing.
What is a metasearch engine?
It is no secret that the world wide Internet, containing an ever-growing huge volume of dynamically changing information, is developing at an unprecedentedly rapid pace. In order to somehow streamline this continuous flow of data, and most importantly, to enable Web users to find the information they need, special search engines have been created. Each such system has an index that carries service information about the contents of indexed documents, where each word of the text corresponds to the frequency of its use and the coordinates of the word in the text.
Each search engine has only its own, limited by its resources, many documents that are available for search. None of these systems can cover all the resources of the Internet, so at any time there may be a situation where the information needs of the user can not be satisfied. Typically, in this case, the user switches to another search engine and tries to search for what he needs there.
To solve this problem and expand the search capabilities, systems called metasearch were created. They do not have their own search bases data, do not contain any indexes and when searching use the resources of many search engines. Due to this, the completeness of the search in such systems is maximum and the probability of finding necessary information very high.
The principles of metasearch systems
When designing a metasearch system, a number of problems need to be solved.
First of all, from the set of documents received from search engines, it is necessary to select the most relevant, that is, relevant to the user's request. As a rule, creators of meta-search engines do not quite justifiably hope that the search engines they use return relevant search results and rely too much on the position that the document is in this search engine.
This standard approach is shown in Fig. 1. In such systems, the analysis of the received document descriptions is not performed, which can put the irrelevant documents that go first in one search engine higher than relevant in another than significantly lower the quality of the search itself. This principle turned out to be good when the author created the site’s position in search engines, but in general for meta-search systems it turned out to be unsatisfactory.
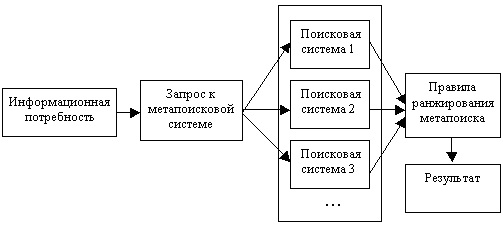
Fig. 1 Standard metasearch system
In developing the next generation of metasearch systems, the disadvantages inherent in standard metasearch systems were taken into account. Systems were created with the ability to select those search engines in which, according to the user, he is more likely to find what he needs (Fig. 2)
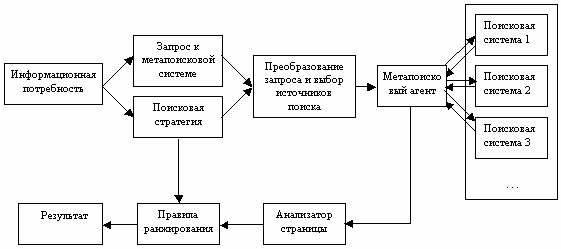
Fig. 2. The next generation of metasearch engines
In addition, this approach allows us to reduce the used computing resources of the metasearch server without overloading it with too much unnecessary information and seriously save traffic. It should be noted here that in any metasearch system, the most bottleneck is mainly the bandwidth of the data transfer channel, since the processing of pages with search results obtained from several dozen search servers It is not too time-consuming operation, because the time spent on processing information is orders of magnitude less than the time it takes for the pages requested from search engines to arrive.
As an example of systems with such an organization, we can name Profusion, Ixquick, SavvySearch, MetaPing.
How does all this work?
The principle of operation of the meta-search system MetaPing developed by the author of this article will be described below, however, the general principles will be true for the other systems of this class (see Fig. 2).
Let's start from the start page of this metasearch system. Usually the interface of such a system is extremely simplified and immediately allows you to understand what, where and how you can search here. In our case (MetaPing), search is possible in three areas of search: in Russia, Ukraine and around the world, while it is possible to search everything by noting the search on the Internet, or narrow the search area and look specifically for ads, news, files and abstracts ( fig. 3).
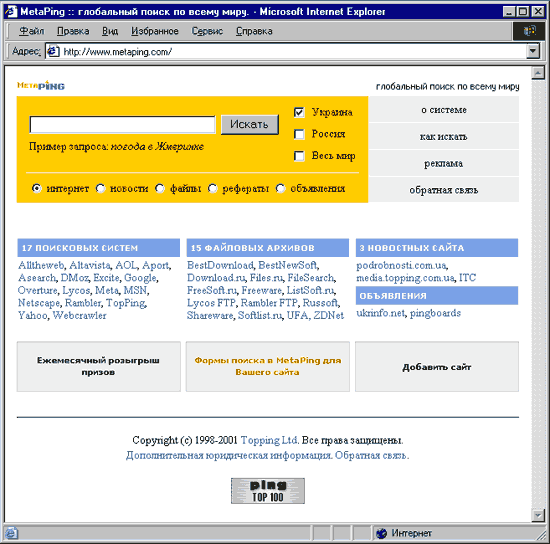
Fig.3 start page Metaping
The user selects, say, a search in Russia, and enters, for example, such a query: "best search engines" (Fig. 4).
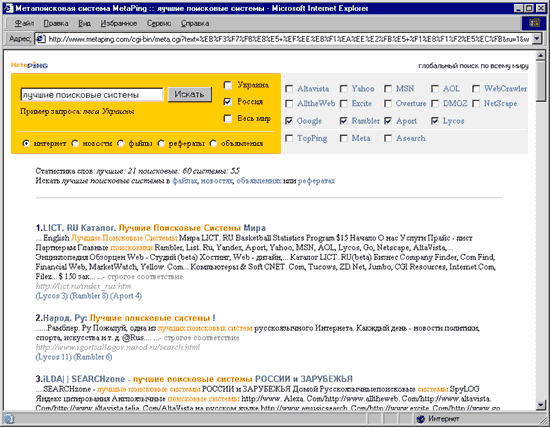
Fig. 4 MetaPing Search Results Page
After that, the request is relayed to the indicated Russian search engines (in our case, it is Rambler, Aport, Lycos and Google). It should be noted that Google, although it is not a Russian search engine, currently successfully competes with them both in the completeness of the databases and in the quality of the search, and that is why it ended up here. By the way, an attentive reader must have noted the absence of the largest Russian search engine Yandex. At the time of the launch of MetaPing, Yandex was also present here, but after the famous scandal, it had to be removed.
To send a request to the search engine, a special metasearch agent is used, which is responsible not only for the process of relaying the request and receiving pages, but also for sending the request in the correct encoding accepted in each of the selected search engines, otherwise a different set will be received descriptions of documents or will not be received at all, which will negatively affect the quality of the search.
After processing the received request, each system returns to the metasearch agent many descriptions and links to documents that it considers relevant to this request.
How among this set to choose exactly what the user needs?
At the beginning of this article, the standard approach that is used by most meta-search systems was already mentioned and consists in simply arranging the received links in the order of their sequence in the search results of each of the search engines. At the same time, if the same site was found in different search engines, then its value to the user, of course, increases significantly.
The approach is certainly correct, but what if one system, for example, indexes dynamically generated pages and the other does not? They have different sets of indexed documents, different completeness of databases, therefore, the information requested by the user can be found in one system and may not be found in another. In this case, the user can get several really relevant links from one system, which will be mixed with absolutely irrelevant from another (for example, in the case when the whole phrase is not found, the search is performed using one of the query keywords). As a result, the user has to manually select relevant links and it is very likely that after digging into such a “vinaigrette”, he simply leaves and never returns.
Is there any way to solve this problem? Of course have. It is necessary to do the same as they do with these documents with the set of document descriptions received from search engines, that is, determine the frequency of keywords in each title and description and try to independently determine the rating of each of them.
It is by this principle that the MetaPing meta-search system is built, where a mixed information processing algorithm is implemented. The author developed special programs to analyze the data obtained, due to which the first stage is the ranking of many descriptions of the received documents, the second rank is further adjusted according to the place where the document is and the total number of documents found on request (this allows you to evaluate the completeness of the search databases of a particular system).
Such processing allows not only to remove documents in the description of which there are no keywords at all as potentially irrelevant to the request, but also to find strict correspondence in the event that all the keywords are found in the description of the document completely, which immeasurably improves the quality and accuracy of the search.
Inforian Quest 98 and Copernic 98 Metasearch Systems
 Inforian Quest 98 (IQ is a good abbreviation, isn't it?). An Inforian product, the fruit of the collaborative efforts of Japanese, Chinese and American programmers.
Inforian Quest 98 (IQ is a good abbreviation, isn't it?). An Inforian product, the fruit of the collaborative efforts of Japanese, Chinese and American programmers.
Weight about 3.5Mb, requires up to 5Mb free disk space. Cost full version 25 US dollars, shareware - 1 month.
It uses two styles: Essence, for advanced users, and Wizard, for beginners. Both styles are distinguished by extreme simplicity. Inforian Quest 98 allows you to perform quick meta-searches on the seven most popular servers (Yahoo !, Altavista, InfoSeek, Excite, HotBot, OpenText, WebCrawler), access additionally almost 200 search engines in America, Europe, Japan and China, plus poll inside these databases data on seven thematic sections Arts and Entertainment (Arts & Entertainment), News and Business (News & Business), Computers and Internet (Computers & Internet), Software and files (Software & FTP), News groups (Usenet (Discussion Group) ), Scientific Technology (Technology), Addresses and Phones (Yellow Pages). There is hope for the inclusion of Israeli and Russian clients in the list of "searched" servers in the near future.
Depending on the degree of your patience, it is recommended to set the wait time (wait for ...) for the search results to be returned (minimum - 1 second, maximum - almost 4 months, recommended - 1-2 minutes) and indicate the maximum number of messages from each site found (links per site) (default, 10). If you want to receive exclusively up-to-date information and are ready to sacrifice a little search speed for this, refuse to use a proxy server. If you wish, you can easily change the interface language from English to German, French or Spanish, if your computer is not only assembled, but also started software Far Eastern craftsmen - you can try the Japanese or Chinese interface. Amazingly executed is a "tip" that can be accessed by pressing the F1 key on the keyboard or using the Help -\u003e Help Topics script.
 Copernic 98, a metasearch engine from ATC (Agents Technologies Corporation), is no less popular today. The main advantage of the program is the absence of the need to pay for the main version, the usage time is unlimited. This program surpasses its competitor in both lightness (about 2.5Mb) and the volume of the respondent when searching for information space. NetFind, LookSmart, Lycos, Magellan have been added to the cage of the main search engines, compared to the competitor, although the very promising OpenText has been forgotten. It is noteworthy that when using Copernic 98 to search for any of your friends on the Web, you use not only the resources of traditional Who Where ?, BigFoot, Four11, but also the database of the “hero of the current season”, Mirabilis. The thematic catalog, containing about 20 sections and accumulating information from over 100 search engines, can be used if you have chosen the plus version (30 days for free, you’ll like it, pay extra $ 30). To date, the so-called Channel Development Kit is under development, which will allow you to independently add any search engine to the list. If at the same time Copernic does not consider the search phrase in Russian or Hebrew erroneous, in our country this direction is provided with considerable popularity.
Copernic 98, a metasearch engine from ATC (Agents Technologies Corporation), is no less popular today. The main advantage of the program is the absence of the need to pay for the main version, the usage time is unlimited. This program surpasses its competitor in both lightness (about 2.5Mb) and the volume of the respondent when searching for information space. NetFind, LookSmart, Lycos, Magellan have been added to the cage of the main search engines, compared to the competitor, although the very promising OpenText has been forgotten. It is noteworthy that when using Copernic 98 to search for any of your friends on the Web, you use not only the resources of traditional Who Where ?, BigFoot, Four11, but also the database of the “hero of the current season”, Mirabilis. The thematic catalog, containing about 20 sections and accumulating information from over 100 search engines, can be used if you have chosen the plus version (30 days for free, you’ll like it, pay extra $ 30). To date, the so-called Channel Development Kit is under development, which will allow you to independently add any search engine to the list. If at the same time Copernic does not consider the search phrase in Russian or Hebrew erroneous, in our country this direction is provided with considerable popularity.
For each search operation, you can change the maximum values \u200b\u200bof the total number of search results and the number of messages in a separate search channel (Search -\u003e New -\u003e Parameters -\u003e Custom Search). You can connect a proxy server to work (View -\u003e Options -\u003e Connection -\u003e Proxies).
More than a thousand years ago, Saints Cyril and Methodius made a strategic mistake, taking Greek letters as the basis of the Russian alphabet. One of its most severe consequences - the need to waste time switching keyboard case - appeared only a few decades ago, when computers were invented. Another, much less significant, is the need to write a separate chapter on the search in Russian-language documents.
Let's try to learn more about the origin of Russian writing, this time using the Rambler search engine. In the "Ratings" section of Chapter 1, we have already talked about Rambler as a rating of Russian sites. In this section, it will be appropriate to say that Rambler is not only and not so much a rating as an automatic index, about the same as Aport. Indeed, on the main page of Rambler at the very top there is a Search field and a Find button! to send a request.
To find documents describing the creation of Russian writing, it is reasonable to enter the words “history”, “Russian”, “writing” in the search field, surround the entered words with quotation marks to specify a phrase search, and click the Find! Button. A snippet of search results.
As you can see, the first (out of 234 found) document, judging by its title, as well as the beginning shown by Rambler, the date of the last change (May 18, 2005) and size (150 KB), fully meets our expectations. Perhaps the remaining 233 pages say something about Russian writing. But is weight the documents? Is something important missing? To correctly answer these questions, you need to know the language of queries of Rambler.
So far, we know that Rambler is looking for a phrase when words in the search field are surrounded by quotation marks. It is important to understand that the words that make up the phrase, Rambler leaves unchanged. Rambler will find documents containing the phrase "history of Russian writing," but will not find the phrase "history of Russian writing." To search for all grammatical forms of words, it is necessary to free them from quotation marks by entering “Cyril”, “Methodius”, “Russian”, and “writing” in the search field.
At such a request, Rambler finds already 4229 sites and more than 34 thousand documents. A snippet of search results. As you can see, Rambler highlighted in bold the words “Russian”, “written”, that is, no difference is made between the words “Russian” and “Russian”, all grammatical forms are considered as one word. But it's worth putting the word in quotation marks, and Rambler will look for exactly what is indicated. By the following query, documents will be found where there are the words “Russian”, “writing” and any grammatical forms of the words “Cyril” (for example, “Cyril”) and “Methodius”:
Cyril Methodius "Russian" "writing"

By default, Rambler searches for documents that have all the words separated by spaces. But almost all modern search engines are trying to guess what the seeker had in mind, so it’s better to explicitly tell Rambler what he should do. If you need to find all the words, the logical operator AND is put between them. By the following query, documents will be found where there are both words (taking into account their variability):
Cyril AND Methodius
But if you need to find one of several words, use the OR operator, for example:
(writing OR alphabet OR alphabet) AND Russian AND “Cyril” AND “Methodius”
This query means that you are looking for pages where you must have the words "Cyril", "Methodius", one of the grammatical forms of the word "Russian" and one of the words: "writing", "alphabet", "alphabet" (taking into account their grammatical variability ) In the last example, the words "Cyril" and "Methodius" are written with lowercase letter, because Rambler anyway before turning to his index, turns uppercase letters in lowercase.
In addition to the AND and OR operators, in Rambler there is also the NOT operator, which allows you to find documents where there is no given word (phrase). By the next query, pages will be found where there are the words “history”, “Russian”, “writing” (taking into account their grammatical variability), but there is no word “Cyril”: the history AND of the Russian AND the written language NOT Kirill
Using the NOT operator, you can compose very complex queries, for example: the history of AND Russian AND writing NOT (Cyril OR Methodius)
This query instructs Rambler to search for pages where there are all three words connected by the AND operator, and there is neither the word Cyril nor the word Methodius. You can understand this using such a query to the search engine:
Cyril OR Methodius
In this case, documents could be found where there is either the word "Cyril", or the word "Methodius", or both of these words. Obviously, all documents indexed by the search engine can be divided into two parts: the first answers the query Cyril OR Methodius, the second does not. So, the NOT operator just instructs the search engine to show this second part. Obviously, in this part the pages are collected in which there is neither the word Cyril nor the word Methodius.
It remains for us to get acquainted with the advanced search mode, which can be configured by selecting the Advanced Search mouse link located under the Find! Button. Blank pacuiiipeHHoro request.
You can enter words associated with logical operators in the search field (in this case, in the Search for query words group, the switch should be selected), you can simply indicate whether at least one of the selected words is searched or exact ([phase. You can specify where it will go search - in the documents themselves, in the titles (title) or in the texts of links. You can limit the distance between words; this, of course, will not replace the search for phrases, but can sometimes help. You can search only on certain sites (Search for documents only on the following sites ). You can search for a dock copes of a certain type by setting the Document Language and Document Format created in the specified period of time (Document Date). Finally, you can sort pages not only by their relevance to the query (relevance), but also by date, and also search for documents that do not contain specified words (Exclude documents containing the following words).
Rambler (syn. Rambler, rambler, translated from English as a wanderer, tramp) — Search engine of internet holding Rambler Media Group.
The search engine takes into account the morphology of Russian, Ukrainian and english languages, as well as searching, it goes through all forms of queries and gives results according to the degree of compliance with the query.
Rambler, one of the very first search engines on the Internet market, played a huge role in the development of Runet. With a small number (no more than 5%), the search engine is in third place after Yandex and Google.
The Rambler audience is basically represented by people who have been using the system almost since its inception.
Among the advantages in Rambler, one can distinguish a thematic rating of sites, a news service, an Internet messenger, an online payment service, free mail and the Runner contextual advertising service, etc.
Chronicle of events
In 1991, a group of scientists, namely Sergey Lysakov, Yuri Ershov, Dmitry Kryukov, Victor Voronkov and Vladimir Samoilov, from the Institute of Biochemistry and Physiology of Microorganisms of the Russian Academy of Sciences, set about developing a local network for the exchange of scientific and technical information in Pushchino. Soon the network was connected to Moscow, and then to the Internet. The project quickly earned and began to actively develop.
The official year of birth of the search engine is 1996, when Dmitry Kryukov created a search service called Rambler. In 1996, other search engines were already created and worked, but they, unlike Rambler, were not popular.
In 1997, Dmitry Kryukov introduced a certain scale, the Rambler’s Top100 classifier, which is responsible for determining the authority of sites depending on the frequency of their visits.
In 1999, Igor Ashmanov, who left the company in 2001, took the post of director of development and research, and then the position of executive director. He described his work in Rambler in the book “Life Inside the Bubble”, where he described in detail the activities of the company for 1999-2001, as well as why Rambler lost his 1st place in the domestic Internet market.
In 2004 The Rambler’s Top 100 is ISO 9001 certified.
In 2007 CEO took Mark Opzumer. In 2009, vertical search was added based on eXtended AGgregator technology. On December 31, 2009, Rambler quit all top management together with CEO Mark Opumer and the same year the search engine received the Runet Prize in the nomination Culture and Mass Communications.
Since April 2009 Olga Turishcheva, who worked at Vympel as a venture business development director, leads Rambler.
At the end of June 2011, Rambler switched to Yandex search technology. Along with the advantages of the search engine, there are also disadvantages, especially compared to Yandex or Google. In Rambler, algorithms are rarely updated, there are practically no filters for controlling the quality of Internet sources for low-frequency or mid-frequency queries, which increases the number of spam sites, and the algorithm for determining the relevance of sites is also low-priced. In this regard, the share of Rambler among search engines decreased from 20 to 5%.
What can Rambler offer?
Rambler provides not only numerous projects of an entertaining nature, but also the following sections:
1) "Cards" - contains detailed maps large cities. Users can find out the addresses of interest to them, pave any routes and be aware of traffic jams.
2) In “Price.ru” you can find any product catalogs, information about discounts, product reviews, upcoming events, etc.
3) “Finance” will always provide the necessary information about currency quotes, the situation on the modern market, stock prices, etc.
4) In “Ferra.ru” you can find reviews of the latest digital technology: cameras, phones, computers, etc.