Benefits
Allows, in most cases, the distribution of functions computing system between several independent computers on the network. This simplifies the maintenance of the computing system. In particular, the replacement, repair, upgrade, or relocation of a server does not affect customers.
· All data is stored on a server, which, as a rule, is much better protected than most clients. It is easier to enforce authorization on the server so that only clients with appropriate access rights can access the data.
· Allows you to combine different clients. Clients with different hardware platforms, operating systems, etc. can often use the resources of one server.
disadvantages
· Server failure can render the entire computer network inoperative.
· Support of this system requires a separate specialist - a system administrator.
· High cost of equipment.
Layered client-server architecture
A multi-tier client-server architecture is a type of client-server architecture in which the data processing function is transferred to one or more separate servers. This allows you to separate the functions of storing, processing and presenting data for more efficient use of the capabilities of servers and clients.
Special cases of a layered architecture:
IN computer technology three-tier architecture, a synonym for three-tier architecture (English three-tier or Multitier architecture) assumes the presence of the following application components: client application (usually they say “ thin client»Or terminal) connected to the application server, which in turn is connected to the database server.
Architecture overview
Customer is an interface (usually graphical) component that represents the first level, the actual application for the end user. The first level should not have direct connections to the database (for security requirements), be loaded with the main business logic (for scalability requirements) and store the application state (for reliability requirements). The simplest business logic can be and usually is taken to the first level: the authorization interface, encryption algorithms, checking the entered values \u200b\u200bfor validity and compliance with the format, simple operations (sorting, grouping, counting values) with data already loaded on the terminal.
The application server is located at the second level. The second level contains most of the business logic. Outside of it are fragments exported to terminals (see above), as well as stored procedures and triggers immersed in the third level.
The database server provides data storage and is taken out to the third level. This is usually a standard relational or object-oriented database management system. If the third level is a database along with stored procedures, triggers and a schema describing the application in terms of relational model, then the second level is built as a programming interface that connects client components with the application logic of the database.
In the simplest configuration, the physical application server can be combined with the database server on one computer, to which one or several terminals are connected via the network.
In the “correct” (in terms of security, reliability, scalability) configuration, the database server is located on a dedicated computer (or cluster), to which one or more application servers are connected via the network, to which, in turn, terminals are connected via the network.
Advantages
Compared with the client-server or file-server architecture, the following advantages of the three-tier architecture can be distinguished:
Scalability
Configurability - the isolation of levels from each other allows (with the correct deployment of the architecture) quickly and by simple means reconfigure the system in case of failures or during scheduled maintenance at one of the levels
High security
High reliability
Low requirements for the speed of the channel (network) between terminals and the application server
Low performance requirements and technical specifications terminals, as a result of a decrease in their cost. The terminal can be not only a computer, but also, for example, a mobile phone.
disadvantages
Disadvantages stem from merits. Compared to the client-server or file-server architecture, the following disadvantages of the three-tier architecture can be distinguished:
· Higher complexity of creating applications;
· More difficult to deploy and administer;
· High requirements for the performance of application servers and the database server, and, hence, the high cost of server hardware;
· High requirements for the speed of the channel (network) between the database server and application servers.
Classic client-server architecture
The term "client-server" means a software package architecture in which its functional parts interact according to a "request-response" scheme. If we consider two interacting parts of this complex, then one of them (the client) performs an active function, that is, initiates requests, and the other (the server) responds passively to them. As the system evolves, the roles may change, for example, some program unit will simultaneously perform the functions of a server in relation to one unit and a client in relation to another.
Note that any information system should have at least three main functional parts - modules for storing data, processing and interface with the user. Each of these parts can be implemented independently of the other two. For example, without changing the programs used to store and process data, you can change the user interface so that the same data will be displayed in the form of tables, graphs or histograms. Without changing the data presentation and storage programs, you can change the processing programs, for example, by changing the full-text search algorithm. Finally, without changing the data presentation and processing programs, you can change the data storage software by switching, for example, to a different file system.
In the classic client-server architecture, you have to distribute the three main parts of the application into two physical modules. Typically, data storage software is located on a server (for example, a database server), the user interface is on the client side, but data processing has to be distributed between the client and server parts. This is the main drawback of the two-tier architecture, from which several unpleasant features follow, which greatly complicate the development of client-server systems.
When splitting data processing algorithms, it is necessary to synchronize the behavior of both parts of the system. All developers should be fully aware of the latest changes made to the system and understand these changes. This creates great difficulties in the development of client-server systems, their installation and maintenance, since it is necessary to spend significant efforts on coordinating the actions of different groups of specialists. In the actions of developers, contradictions often arise, and this slows down the development of the system and forces you to change already ready-made and proven elements.
To avoid the inconsistency of the various elements of the architecture, attempts are made to perform data processing on one of two physical parts - either on the client side (thick client) or on the server (thin client, or an architecture called 2.5-tier client). server"). Each approach has its drawbacks. In the first case, the network is unjustifiably overloaded, since raw, and therefore, redundant data is transmitted over it. In addition, the system support and its modification becomes more complicated, since the replacement of the calculation algorithm or the correction of an error requires the simultaneous complete replacement of all interface programs, otherwise errors or data inconsistencies may occur. If all information processing is performed on the server (when this is possible at all), then the problem arises of describing the built-in procedures and their debugging. The fact is that the language for describing built-in procedures is usually declarative and, therefore, in principle, does not allow step-by-step debugging. In addition, the system with processing information on the server is absolutely impossible to transfer to another platform, which is a serious drawback.
Most modern Rapid Application Development (RAD) tools that work with different databases implement the first strategy, that is, the fat client provides an interface to the database server through embedded SQL. This version of the implementation of a system with a "thick" client, in addition to the above disadvantages, usually provides an unacceptably low level of security. For example, in banking systems, all tellers have to give the rights to write to the main table accounting system... Besides, this system it is almost impossible to translate to Web technology, since specialized client software is used to access the database server.
So, the models discussed above have the following disadvantages.
1. "Thick" client:
# complexity of administration;
# the software update becomes more complicated, since it must be replaced simultaneously throughout the system;
# distribution of powers becomes more complicated, since access is differentiated not by actions, but by tables;
# the network is overloaded due to the transfer of raw data over it;
# weak data protection, as it is difficult to properly allocate authority.
2. "Thick" server:
# the implementation becomes more complicated, since languages \u200b\u200bsuch as PL / SQL are not suitable for developing such software and are not good means debugging;
# the performance of programs written in languages \u200b\u200blike PL / SQL is much lower than programs written in other languages, which is important for complex systems;
# programs written in DBMS languages \u200b\u200busually do not work reliably enough; an error in them can lead to the failure of the entire database server;
# the resulting programs are completely non-portable to other systems and platforms.
To solve the above problems, a multi-level (three or more levels) client-server architecture is used.
Layered client-server architectures
Such architectures more intelligently distribute data processing modules, which in this case run on one or more separate servers. These software modules act as a server for user interfaces and a client for database servers. In addition, different application servers can interact with each other to more accurately divide the system into functional blocks that perform specific roles. For example, you can select a personnel management server that will perform all the functions necessary for personnel management. By associating a separate database with it, you can hide all the implementation details of this server from users, allowing them to access only its public functions. In addition, such a system is very easy to adapt to the Web, since it is easier to develop html forms for users to access certain database functions than to all data.
In a three-tier architecture, the "thin" client is not overloaded with data processing functions, but plays its main role as a system for presenting information from the application server. Such an interface can be implemented using standard tools Web technologies - browser, CGI and Java. This reduces the amount of data transferred between the client and the application server, which allows client computers to be connected even over slow lines such as telephone lines. In addition, the client side can be so simple that in most cases it is implemented using a generic browser. But if you still have to change it, then this procedure can be carried out quickly and painlessly. The three-tier client-server architecture allows you to more accurately assign user permissions, since they do not receive access rights to the database itself, but to certain functions of the application server. This increases the security of the system (in comparison with the usual architecture) not only against deliberate attacks, but also against erroneous actions of personnel.
For example, consider a system, different parts of which operate on several remote friend from other servers. Suppose that a new version of the system has been received from the developer, for the installation of which in a two-tier architecture it is necessary to simultaneously change all system modules. If this is not done, the interaction of old clients with new servers can lead to unpredictable consequences, since developers usually do not count on such use of the system. In a three-tier architecture, the situation is simplified. The fact is that by changing the application server and data storage server (this is easy to do at the same time, since both of them are usually located next to each other), we immediately change the set of available services. Thus, the likelihood of an error due to a mismatch between the versions of the server and client parts is sharply reduced. If in new version any service has disappeared, then the interface elements that served it in old systemwill simply not work. If the algorithm of the service has changed, then it will work correctly even with the old interface.
Multi-tier client-server systems can be easily translated to Web-technology - for this it is enough to replace the client part with a universal or specialized browser, and supplement the application server with a Web-server and small programs that call server procedures. To develop these programs, you can use both the Common Gateway Interface (CGI) and more modern technology Java.
It should also be noted that in a three-tier system, a lot of information is transmitted over the communication channel between the application server and the database. However, this does not slow down the calculations, since faster lines can be used to connect the indicated elements. This will require minimal cost, since both servers are usually located in the same room. Thus, the overall performance of the system increases - two different servers are now working on the same task, and communication between them can be carried out via the fastest lines with minimal cost funds. True, there is a problem of consistency of joint computing, which transaction managers are called upon to solve - new elements of multi-tier systems.
]. This allows you to separate the functions of storing, processing and presenting data for more efficient use of the capabilities of servers and clients.
Among the multi-tier client-server architecture, the most common three-tier architecture ( three-tier architecture, three-tier), which assumes the presence of the following application components: a client application (usually they say "thin client" or terminal) connected to application serverwhich in turn is connected to database server [ , ].
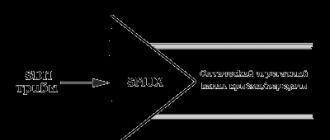
fig. 5.4.
Figure: 5.4.Representing a layered client-server architecture
- Terminal is an interface (usually graphical) component that represents the first level, the actual application for the end user. The first level should not have direct connections to the database (for security requirements), be loaded with the main business logic (for scalability requirements) and store the application state (for reliability requirements). The simplest business logic can be and usually is taken to the first level: the authorization interface, encryption algorithms, checking the entered values \u200b\u200bfor validity and compliance with the format, simple operations (sorting, grouping, counting values) with data already loaded on the terminal.
- Applications server located on the second level. At the second level, most of the business logic is concentrated. Outside of it are fragments exported to terminals, as well as stored procedures and triggers immersed in the third level.
- Database server provides data storage and is brought to the third level. This is usually a standard relational or object-oriented database management system. While the third level is a database along with stored procedures, triggers, and a schema that describes the application in terms of the relational model, the second level is built as a programming interface that connects client components with the application logic of the database.
In the simplest configuration, physically applications server can be combined with database server on one computer to which one or more terminals are connected over the network.
In the "correct" (in terms of security, reliability, scalability) configuration database server located on a dedicated computer (or cluster) to which one or more application servers, to which, in turn, terminals are connected via the network.
- {!LANG-761313f1c09a94d35936694faf07924f!}
- {!LANG-9e3bd761376997b1a0f69f76b71337d3!}
- {!LANG-131826f16354eaa5cda5056dfb007a4e!}
- {!LANG-edb4133364654a5fbef64d3c1c3d8749!}
- {!LANG-6b556e748b34632af4cbc1683293e546!}
- {!LANG-4e7d42a8c97a46974b446b95cc9da00a!} {!LANG-525649d95372255f9a1c34600cfbe1dd!};
- {!LANG-00bae090155c66b962025b391a92654e!}
- {!LANG-7fecc985bd301e03fc13b202e5f7c3a1!}
- {!LANG-5cc3335b2cee3542dd6f9c20213a4c3a!}
- {!LANG-de23caa0076b7cfd6f01360178bdcf24!}
- {!LANG-3961ad5a883f69641a2c22bd2a5eec45!} application servers{!LANG-73365e38bf2b65234d77914e34d9fae0!} {!LANG-4c49c222544cb0277dbccecffd9ea7cd!}{!LANG-70fbfb5d7ebdfc3c611e522c9fd7b27f!}
- {!LANG-55434261324f89e6ef610bbed284dcc9!} database server{!LANG-73365e38bf2b65234d77914e34d9fae0!} {!LANG-40a9a991ee00e9329609d84e4e25b769!}.
- {!LANG-89da07510fb9c3b81c2c485e9b47e665!}
- {!LANG-aca14d047d4d93bc64c4fd015b301393!}
- {!LANG-df783e6bd37d07b2d0e7cfe8e89755d3!}
- {!LANG-650a9b7c1e9629a0364b03ab38c1fec3!}
- {!LANG-5dd7e921baeb05354548438c937e1202!}

{!LANG-70f608367a61d7dcad52499cebc92838!}{!LANG-ac244e7abfbe6ff7d82154a1efb1100b!}
{!LANG-7cef5e10342dd74f92d57a4c9c261995!}
{!LANG-66a48e61b066d58c8297ad401eeffb03!}
The logic level contains the main functions of the system, designed to achieve the goal set for it. These functions include computation based on input and stored data, validating all data items and processing commands from the presentation layer, and passing information to the data layer.
The data access layer is a subset of functions that provide interoperability with third-party systems that perform tasks on behalf of the application.
System data is usually stored in a database.
5.1.6. Distributed systems architecture
This type of system is more complex in terms of system organization. The essence distributed systems is to keep local copies of important data.
Such an architecture can be schematically represented as shown in Fig. 5.6.

Figure: 5.6.
More than 95% of the data used in enterprise management can be located on one personal computer, ensuring the possibility of his independent work. The stream of fixes and additions generated on this computer is negligible compared to the amount of data used. Therefore, if you store continuously used data on the computers themselves, and organize the exchange of corrections and additions to the stored data between them, then the total transmitted traffic will drop sharply. This allows you to reduce the requirements for communication channels between computers and more often use asynchronous communication, and thus create reliably functioning distributed information Systemsusing an unstable connection such as the Internet to connect individual elements, mobile communication, commercial satellite channels. And minimizing traffic between elements will make the cost of operating such a connection quite affordable. Of course, the implementation of such a system is not elementary, and requires solving a number of problems, one of which is the timely synchronization of data.
Each AWS is independent, contains only the information with which it must work, and the relevance of data in the entire system is ensured through the continuous exchange of messages with other AWPs. The exchange of messages between AWPs can be implemented different ways, from sending data to e-mail before transferring data over networks.
To solve the above problems, a multi-level (three or more levels) client-server architecture is used.
Such architectures more intelligently distribute data processing modules, which in this case run on one or more separate servers. These software modules act as a server for user interfaces and a client for database servers. In addition, different application servers can interact with each other to more accurately divide the system into functional blocks that perform specific roles.
For example, you can select a personnel management server that will perform all the functions necessary for personnel management. By associating a separate database with it, you can hide all the implementation details of this server from users, allowing them to access only its public functions. In addition, such a system is very easy to adapt to the Web, since it is easier to develop html forms for users to access certain database functions than to all data.
In a three-tier architecture, the client is not overloaded with data processing functions, but plays its main role as a system for presenting information from the application server. Such an interface can be implemented using standard Web technology tools — browser, CGI, and Java. This reduces the amount of data transferred between the client and the application server, which allows client computers to be connected even over slow lines such as telephone lines. In addition, the client side can be so simple that in most cases it is implemented using a generic browser.But if you still have to change it, then this procedure can be carried out quickly and painlessly. The three-tier client-server architecture allows you to more accurately assign user permissions, since they do not receive access rights to the database itself, but to certain functions of the application server. This increases the security of the system (in comparison with the usual architecture) not only against deliberate attacks, but also against erroneous actions of personnel.
As an example, consider a system, the various parts of which run on several servers remote from each other. Suppose that a new version of the system has been received from the developer, for the installation of which in a two-tier architecture it is necessary to simultaneously change all system modules. If this is not done, the interaction of old clients with new servers can lead to unpredictable consequences, since developers usually do not count on such use of the system. In a three-tier architecture, the situation is simplified. The fact is that by changing the application server and data storage server (this is easy to do at the same time, since both of them are usually located next to each other), we immediately change the set of available services. Thus, the likelihood of an error due to a mismatch between server and client versions is drastically reduced. If any service disappeared in the new version, then the interface elements that served it in the old system simply will not work. If the algorithm of the service has changed, then it will work correctly even with the old interface.
Multi-tier client-server systems can be easily translated to Web-technology - for this it is enough to replace the client part with a universal or specialized browser, and supplement the application server with a Web-server and small programs that call server procedures. Both the Common Gateway Interface (CGI) and the more modern Java technology can be used to develop these programs.
It should also be noted that in a three-tier system, a lot of information is transmitted over the communication channel between the application server and the database. However, this does not slow down the calculations, since faster lines can be used to connect the indicated elements. This will require minimal cost, since both servers are usually located in the same room. Thus, the overall performance of the system increases - two different servers are now working on the same task, and communication between them can be carried out via the fastest lines with minimal investment. True, there is a problem of consistency of joint computing, which transaction managers are called upon to solve - new elements of multi-level systems.
Translated from English: Chernobay Yu.A.
Development of client-server systems
Architecture computer system has evolved along with the ability of hardware to use startup applications. The simplest (and earliest) of all was the "Mainframe Architecture", in which all operations and functions are performed within the server (or "host") computer. Users interacted with the server through dumb terminals, which transmitted instructions, capturing the keystroke, to the server and showed the results of executing the instructions to the user. Such applications were typical and, despite the relatively large processing power of server computers, were generally relatively slow and inconvenient to use, due to the need to transmit every keystroke to the server.
The introduction and widespread adoption of the PC, with its own processing power and graphical user interface, allowed applications to become more complex, and the expansion network systems led to the second major type of system architecture, "File Partitioning". In this PC architecture (or " work station") downloads files from a specialized" file server "and then manages the application (including data) locally. This works well when there is little use of shared data, data updates, and the amount of data to be transferred. However, it soon became clear that file sharing was all more cluttered the network, and applications became more complex and required more and more data to be transferred in both directions.
The problems associated with the processing of data by applications through a file shared over a network led to the development of the client-server architecture in the early 1980s. In this approach, the file server is replaced by the database server, which, rather than simply transferring and saving files to the connected workstations (clients), receives and actually executes requests for data, returning only the result requested by the client. By transferring only the data requested by the client and not the entire file, this architecture significantly reduces the network load. This allowed the creation of a system in which multiple users could update data through GUI interfaces linked to a single, shared database.
Typically, either Structured Query Language (SQL) or Remote Procedure Call (RPCs) is used to communicate between client and server. Several basic options for organizing a client-server architecture are described below.
In a two-tier architecture, the load is distributed between the server (which contains the database) and the client (which contains user interface). They are usually located on different physical machines, but this is not a requirement. Provided that the levels are logically separated, they can be placed (for example, for development and testing) on \u200b\u200bthe same computer (Fig. 1).
Figure 1: Two-Tier Architecture
The distribution of application logic and data processing in this model was and remains problematic. If the client is "smart" and carries out the main data processing, then problems arise related to distribution, installation and maintenance of the application, since each client needs its own local copy software... If the client is "dumb" the application logic and processing must be implemented in the database, and therefore it becomes completely dependent on the particular DBMS used. In any case, each client must register and, depending on the access rights received by him, perform certain functions. However, the two-tier client-server architecture was good decisionwhen the number of users was relatively small (up to about 100 concurrent users), but with the growth of users, a number of restrictions appeared on the use of this architecture.
Performance: As the number of users grows, performance begins to degrade. The degradation in performance is directly proportional to the number of users, each of whom has its own connection to the server, which means that the server must maintain all of these connections (using a "Keep-Alive" message) even when the database is not being accessed.
Security: Each user must have their own individual access to the database, and have the rights granted to operate the application. To do this, you need to store the access rights for each user in the database. When you need to add functionality to the application and you need to update user rights.
Functionality: Regardless of what type of client is used, most of the data processing must be in the database, which means that it depends entirely on the capabilities provided in the database by the manufacturer. This can severely limit the functionality of the application as various bases data support different functions, use different programming languages, and even implement basic tools such as triggers in different ways.
Mobility: The two-tier architecture is so dependent on specific implementation database that transfer existing applications for various DBMS becomes a serious problem. This is especially true in the case of applications in vertical markets, where the choice of DBMS is not determined by the vendor.
But despite this, the two-level architecture was found new life in the internet age. It can work well in disconnected environments where the UI is "dumb" (eg a browser). However, in many ways this implementation represents a return to the original mainframe architecture.
In an effort to overcome the limitations of the two-tier architecture outlined above, an additional layer has been introduced. This architecture is the standard client-server model with a three-tier architecture. The purpose of the extra layer (usually called the "middle" or "rules" layer) is to control application execution and database management. As with the two-level model, the levels can be located either on different computers (Figure 2), or on one computer in test mode.

Figure 2: Three-Tier Architecture
With the introduction of the middle row, the limitations of the two-tier architecture have largely been removed, resulting in a much more flexible, and scalable, system. Since clients now only connect to the application server, rather than directly to the data server, the burden of maintaining connections is removed, as is the need to implement application logic within the database. The database can now perform only the functions of storing and retrieving data, and the task of receiving and processing requests can be performed by the middle level of the three-tier architecture. Development operating systemsincorporating elements such as connection pooling, queuing, and distributed transaction processing has strengthened (and simplified) mid-tier development.
Note that in this model, the application server does not control the user interface, nor does the user actually make queries directly to the database. Instead, it allows multiple clients to share business logic, computation, and access to search engine data. The main advantage is that the client requires less software and no longer needs direct connection to the database, which improves security. Consequently, the application is more scalable, the support and installation costs on a single server are significantly lower than for maintaining applications directly on the client's computer or even on a two-tier architecture.
There are many variations on the basic three-tier models, designed to serve different functions. These include distributed transaction processing (where multiple DBMSs are updated in the same protocol), message-based applications (where applications do not communicate in real time), and cross-platform compatibility (Object Request Broker or “ORB” applications).
Layered architecture or N-tier architecture
With the development of Internet applications against the background of a general increase in the number of users, the basic three-tier client-server model has been expanded by introducing additional layers. These architectures are referred to as "layered" architectures, and they usually have four tiers (Figure 3) where on the network the server is responsible for handling the connection between the client browser and the application server The benefit is that multiple web servers can connect to the same application server thereby increasing the handling of more concurrently connected users.

Figure 3: N-Tier Architecture
Layers versus layers
These terms are (unfortunately) often confused. However, there is a big difference between them and have a certain meaning. The main difference is that the levels are physical leveland the layers are on logical. In other words, the level, theoretically, can be deployed independently on separate computer, and the layer is a logical division within the layer (Figure 4). The typical three-tier model described above typically contains at least seven layers, separated at all three layers.
The main thing to remember about layered architecture is that requests and responses from each flow in the same direction travel through all layers, and that layers can never be skipped. Thus, in the model shown in Figure 4, the only layer that can refer to layer "E" (data access layer) is layer "D" (rules layer). Likewise, layer "C" (application validation layer) can only respond to requests from layer "B" (error handling layer).

Figure 4: Rows Divided into Logical Layers