\u003e Travailler avec l'information et les moteurs de recherche ( général, ordre de travail, sauvegarde et édition d'informations trouvées)
Informations- système de recherche - Un ensemble de règles de recherche d'informations d'une langue naturelle sur la recherche d'informations et une traduction inverse, ainsi qu'un critère de correspondance destiné à la recherche d'informations. Les composants du système d'information et de recherche spécifiques (IPS), à l'exception de la langue d'information et de recherche, les règles de traduction et le critère de conformité, incluent également les moyens de sa mise en œuvre technique, une gamme de textes (documents) dans lesquels la recherche d'informations est réalisée et les gens participent directement à cette recherche.
La recherche d'informations est le processus de recherche dans un certain ensemble de textes (documents) de tous ceux qui sont consacrés à la rubrique spécifiée dans la requête (sujet) ou contiennent les faits dont vous avez besoin, des informations. La propriété intellectuelle est effectuée au moyen d'un système de promotion et est effectuée manuellement soit à l'aide d'outils de mécanisation ou d'automatisation. Un membre indispensable de la propriété intellectuelle est une personne. En fonction de la nature des informations contenues dans le moteur d'information et du moteur de recherche émis (IPS) des textes, la propriété intellectuelle peut être documentaire, y compris bibliographique et factographique. La propriété intellectuelle doit être distinguée du traitement logique des informations, sans laquelle la délivrance directe de la personne répond aux questions qui leur sont posées n'est pas possible. Les IP sont trouvés - et peuvent être trouvés - seulement des faits ou des informations introduites dans l'IPS. Avant d'entrer dans le texte du texte (document), son principal contenu sémantique (thème ou sujet) est déterminé, qui est ensuite traduit et enregistré sur l'une des informations d'information et de recherche. Cette entrée s'appelle la manière de la recherche du texte. Venez également et lorsque les faits enregistrés sont introduits dans l'IPS, des informations. La demande reçue est également traduite dans une langue description, formant une commande de recherche. Étant donné que la recherche d'images de textes et de prescriptions de recherche est enregistrée dans la même langue, les expressions sur lesquelles une seule interprétation est autorisée, il est possible de les comparer officiellement, pas de plaisir au sens. Pour ce faire, les règles définies (critères de conformité) sont définies, établissement comme une coïncidence formelle de la commande de recherche de prescription de la part de la recherche devrait être considérée comme responsable de la demande d'informations et de l'extradition.
L'efficacité technique de l'IP est caractérisée par deux indicateurs relatifs - le ratio de précision (le rapport du nombre de textes responsables de la demande d'informations, au nombre total de textes dans cette question) et du ratio complet (le rapport du nombre des textes qui répondent à la demande d'informations, au nombre total de textes contenus dans la présente IPS). Les valeurs nécessaires de ces indicateurs dépendent des spécificités des besoins en informations. Par exemple, lors de la recherche de descriptions de brevets afin de procéder à un examen d'une demande de brevet de nouveauté, une complétude de 100% de la délivrance est nécessaire; Lorsque la recherche s'est concentrée sur un chercheur ou un ingénieur régulier, la précision de la délivrance d'environ 80% est considérée comme très bonne et l'exhaustivité est d'environ 50%.
Figure 1 - Processus de recherche
IP peut être deux types - Diffusion sélective (ou adresse) de la diffusion de l'information et de la recherche rétrospective. Avec la répartition électorale de l'information, la propriété intellectuelle est effectuée sur les demandes permanentes d'un certain nombre de consommateurs (abonnés), réalisée périodiquement (généralement une fois par semaine ou en deux semaines) et n'est effectuée que dans la gamme de textes reçus dans le IPA pour cette période de temps.
Entre les IP et les consommateurs (abonnés), les commentaires actuels sont établis (l'abonné rapporte dans quelle mesure ce texte répond à la demande et s'il faut une copie du texte intégral au degré de conformité de ce texte de ses besoins en matière d'information), Ce qui vous permet de clarifier les besoins des abonnés à réagir en temps voulu pour répondre aux modifications apportées à ces besoins et optimiser l'opération du système.
Avec une recherche rétrospective de l'IPP, les textes contenant les informations requises dans l'ensemble de la matrice accumulée de textes dans des demandes ponctuelles sont recherchées.
Architecture des systèmes d'information et de recherche modernes www.
Considérez un schéma typique d'un tel système. Dans diverses publications sur des systèmes spécifiques, des régimes sont donnés, qui diffèrent uniquement des uns des autres en appliquant des solutions logiciellesMais pas le principe d'organisation de divers composants du système. Par conséquent, considérons ce système sur l'exemple présenté:
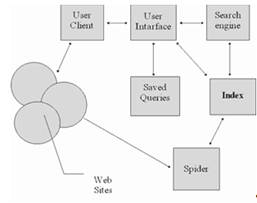
Figure 2 - Structure IPS pour Internet
Ce schéma indique:
le client est un programme qui visionne une ressource d'information spécifique. Actuellement, les programmes MultiProtocol Netscape Navigator sont les plus populaires. Un tel programme fournit une vue des documents Worl Toile large., Gopher, WAIS, Archives FTP, Listes de diffusion mailing et groupes de nouvelles Usenet. À son tour, tous ces ressources d'information sont un objet de recherche d'un système de récupération d'informations.
interface utilisateur - Interface utilisateur n'est pas simplement un programme de visualisation. Dans le cas d'un moteur d'information et de moteur de recherche, cette phrase comprend la façon de communiquer l'utilisateur avec l'appareil de recherche du système, c'est-à-dire Avec formation de requête et visualisation des résultats. Affichage des résultats de la recherche et des ressources de réseau Les ressources sont complètement différentes sur lesquelles nous allons nous arrêter un peu plus tard.
moteur de recherche - Le moteur de recherche est utilisé pour diffuser la demande de l'utilisateur, qui est préparé sur la langue d'information et de recherche (IPA), à la demande de système formelle, à la recherche de liens vers des ressources d'informations réseau et à la délivrance des résultats de cette recherche à l'utilisateur. .
index Base de données - Index est la principale gamme de systèmes de recherche d'informations et d'informations. Il sert à rechercher l'adresse de la ressource d'information. L'architecture de l'index est conçue de manière à ce que la recherche ait lieu le plus rapidement possible et qu'il soit possible d'estimer la valeur de chacune des ressources d'information trouvées du réseau.
queries - Les demandes des utilisateurs sont enregistrées dans sa base de données personnelle. Le débogage de chaque demande est assez long et il est donc extrêmement important de stocker des demandes auxquelles le système donne de bonnes réponses.
index Robot - L'indexeur de robot est utilisé pour analyser Internet et prendre en charge la base de données d'index dans l'état actuel. Ce programme est la principale source d'informations sur l'état des ressources d'information du réseau.
les sites www sont l'ensemble de l'Internet. Et si nous parlons plus précisément, ce sont les ressources d'information apportées en consultant des programmes.
Les systèmes de recherche sont généralement composés de trois composants:
1. Agent (araignée ou pelle), qui se déplace sur le réseau et recueille des informations;
2. Base de données, qui contient toutes les informations collectées par des araignées;
3. Moteur de recherche que les personnes utilisent comme une interface pour interagir avec la base de données.
Ministère de l'éducation de la Fédération de Russie.
Adygei State University
Cours.
Sur le sujet "Informations automatisées et moteurs de recherche".
Effectué
Étudiant de groupe
Vérifié
Introduction ................................................. ................................. 3.
1. Systèmes d'information .............................................. .4
Concept systèmes d'information………………………………………4
La structure des systèmes d'information .............................................. 4
Classification des systèmes d'information ................................... 6
2. Moteurs de recherche d'information .................................. 7
Contexte historique de développement des moteurs de recherche ............... 7
Le concept de moteurs de recherche ................................................. ...... ..... 9
Caractéristiques des moteurs de recherche .................................................. .. dix
· la structure du réseau ................................................. ............ .... 11
· structure des moteurs de recherche ........................... ..... 13
3. Caractéristiques des moteurs de recherche ................................... 17
4. problèmes et opportunités pour les moteurs de recherche ..................... 24
Conclusion ................................................. ............................................. 25
Les références ................................................. .............. ... 26
introduction
La phase moderne du développement de la civilisation se caractérise par la transition de la partie la plus développée de l'humanité de société industrielle À l'information. L'émergence et le développement du réseau informatique mondial de l'information sont l'un des phénomènes les plus vivants de ce processus.
Dans ce papier à terme sont considérés base théorique Recherche d'informations, classification et variétés de moteurs de recherche d'informations. Présenté le matériau en fonction des informations actuellement utilisées - catalogue de recherche Moteurs de recherche en texte intégral et hypertexte.
Lorsque le réseau apparaît, le problème de recherche est devenu plus pertinent. Internet - monde réseau informatique, représentant un environnement d'information unique et vous permet d'obtenir des informations à tout moment. Mais d'autre part, il y a beaucoup d'informations utiles sur Internet, mais il faut beaucoup de temps pour rechercher. Ce problème a servi de raison pour l'apparence. moteur de recherche. Dans ce cours, les travaux seront considérés comme des moteurs de recherche sur Internet.
Systèmes d'information
Le concept de systèmes d'information
Le système d'information est compris comme un ensemble organisé de logiciels et d'auxiliaires techniques et autres, processus technologiques et fonctionnellement - certains groupes de travailleurs fournissant la collecte, la présentation et l'accumulation de ressources d'information dans une certaine zone, la recherche et la délivrance des informations nécessaires pour répondre aux besoins de l'information des utilisateurs. Les systèmes d'information sont les moyens principaux, les outils de résolution de tâches support d'information Différentes activités et la plus grande technologie de l'information de l'industrie de l'industrie de la Rabbar.
Structure du système d'information
La composition du système d'information peut distinguer trois sous-systèmes:
1. Le sous-système technologique de la collection d'informations organisationnelle fournit le système d'information et comprend un ensemble de sources d'information, de la chaîne organisationnelle et technologique de la sélection des informations pour l'accumulation dans le système. Sans le bon sous-système organisé de la collecte d'informations, une organisation efficace de l'opération est impossible pour l'ensemble du système d'information dans son ensemble.
2. Le sous-système de la fourniture et du traitement des informations est le noyau du système d'information et reflète la soumission des développeurs et des abonnés de la structure et de la situation de la zone, qui devrait refléter le système d'information. Le sous-système de soumission et de traitement est l'un des composants les plus complexes de l'élaboration du système d'information.
3. réglementation - sous-système fonctionnel La délivrance de l'information définit les utilisateurs ou autrement des abonnés du système, implémente l'aspect cible de la nomination et l'exécution des tâches du système d'information.
La base de tous les moteurs de recherche constituent des bases de données - un ensemble de données organisées par les règles limites prévoyant des principes généraux pour décrire, stocker et manipuler des données, quels que soient les programmes d'application.
Les éléments suivants du fonctionnement des systèmes d'information peuvent être distingués:
* Collection d'informations - organisée dans un processus spécial de collecte et d'affichage des informations:
recevoir les informations
Évaluer les informations pertinentes
l'ordre de sélection et de fixation d'informations.
* Emballage - Procédé d'ajout d'informations provenant d'une pluralité de pièces en un seul tout et apportez-la à l'utilisateur.
* Recherche et délivrance de l'information - établissement d'une ordonnance technologique spéciale pour répondre aux besoins d'information des abonnés du système d'information dans les activités de gestion et les processus technologiques.
* Maintenir l'intégrité et la conservation de l'information - révision, révision et copier invalide La pertinence des informations font partie intégrante. unités d'information. La sécurité des informations est effectuée à l'aide d'instructions réglementaires.
Classification des systèmes d'information
Par la nature de la disposition organisation logique Les informations stockées sont divisées en usine, documentaire et géographique.
Accumule et stockez des données sur la forme d'une pluralité d'instances d'un ou de plusieurs types Éléments structurels. Chacune de ces cas d'éléments structurels ou une partie de leur combinaison reflète des informations, par tout fait, événement. La structure de chaque type d'objet d'information consiste en un ensemble fini de détails reflétant les principaux aspects et caractéristiques des informations pour les objets de ce domaine.
Dans l'élément d'unité documentaire des informations, le document et les informations sont involontés pour des éléments plus petits, en règle générale, ne sont pas structurés ni structurés sous forme limitée. Pour le document d'entrée, certaines positions formalisées peuvent être installées - la date de fabrication, l'artiste, le thème. Certains types de systèmes d'information documentaire garantissent l'établissement de l'interconnexion logique des documents d'entrée - le Coenplex dans la teneur sémantique.
Dans les données d'information géographique, il est organisé sous la forme d'objets d'information distincts liés à une base topographique électronique commune. Systèmes de géoinformation Demander un soutien d'information dans ces domaines, la structure des objets d'information et des processus dans lesquels il existe un composant géographique.
Un autre critère de classification des moteurs de recherche est des fonctions ou des tâches résolues.
Les références sont les fonctions types de systèmes d'information les plus courantes et permettent de fournir aux abonnés un système d'obtention de données d'installation à certaines classes d'objets.
La recherche est la classe la plus courante des systèmes d'information. En général, le formulaire peut être considéré comme une sorte d'espace d'information tel que défini en termes d'informations et de description logique de la zone.
Le calcul est calculé pour traiter des informations dans le système, selon certains algorithmes calculés à diverses fins.
Les fonctions technologiques des systèmes d'information sont d'automatiser l'ensemble du cycle technologique ou de ses composants individuels, de la production ou de la structure organisationnelle.
Systèmes de recherche d'informations
Contexte historique de développer des moteurs de recherche.
Passons à l'historique du réseau Internet, créé en relation avec la nécessité de partager les ressources d'informations distribuées entre divers systèmes informatiques. La plupart des premières applications, y compris FTP et e-mail, ont été conçues exclusivement pour l'échange de données entre les ordinateurs hôtes Internet.
D'autres applications telles que Telnet ont été créées pour s'assurer que l'utilisateur a la capacité d'accéder non seulement aux informations, mais également aux ressources de travail du système distant. En tant que développement Internet (augmentation des utilisateurs et des ordinateurs hôtes), les anciennes méthodes d'échange de données ont cessé de répondre aux besoins accrus des utilisateurs. Il était nécessaire de développer de nouvelles façons de rechercher des ressources réseau et d'y accéder, ce qui permettrait d'utiliser des informations quel que soit son format et son emplacement.
Pour répondre à ces besoins, le moteur de recherche d'Archie a été créé pour la première fois, tâche décisive Localisation des ressources sur le serveur FTP et système gopherSimplifier l'accès à différents ressources réseau. Les informations sur le réseau ont ensuite été développées systèmes www et WAIS proposant des méthodes absolument nouvelles pour obtenir des informations. Les principes de fonctionnement de ces systèmes facilitent la navigation dans un grand nombre de ressources d'information sans la nécessité de fournir des mécanismes d'exploitation d'Internet. Cette approche vous permet de ne parler aucun simple sur les ressources d'interdre systèmes informatiques, mais sur des espaces d'information spéciaux du réseau.
Système Archie. Représente le complexe logicielTravailler avec des bases de données spéciales. Ces bases de données contiennent constamment reconstituer des informations de fichier auxquelles vous pouvez accéder via le service FTP. En utilisant les services du système Archie, vous pouvez rechercher un fichier par le modèle de son nom. Dans le même temps, l'utilisateur recevra une liste de fichiers avec une indication précise de leur stockage de lieu sur le réseau, ainsi que des informations sur le type, la durée de création et la taille des fichiers. L'accès au système de récupération d'informations sur l'archie peut être effectué de différentes manières, à partir de demandes de messagerie et à l'aide du service Telnet et se terminant par des clients d'Archie graphique.
Système Gopher. Il a été conçu pour simplifier le processus de localisation des ressources IPTP et une vue plus pratique du contenu des fichiers stockés sur des serveurs FTP. Le système de gopher permet de fournir aux utilisateurs des fichiers disponibles et de leur contenu disponible sur la forme (sous la forme d'un menu). Le menu Gopher Server peut contenir des liens vers d'autres serveurs Gopher et FTP. Ainsi, l'utilisateur obtient la capacité de "voyager" sur Internet, sans faire attention à l'emplacement de ses ressources et accédez à ces ressources.
Système Véronique. Utilisé pour rechercher des informations dans l'espace Gopher sur les éléments d'éléments de menu. Après avoir entré un mot clé, le système Veronica découvre s'il est trouvé dans le menu de n'importe quel serveur Gopher et, en tant que résultats de recherche, il donne une liste des éléments de menu, contenant le mot-clé. Puisque le système Veronica n'est pas autonome moteur de rechercheet étroitement liés au système gopher, il est identique à celui du système gopher, désavantage: pas toujours par l'en-tête peut être dit qu'il représente une ou une autre ressource d'information. Les avantages du système sont qu'il n'est pas nécessaire de déterminer où se trouve les informations trouvées, il suffit de sélectionner l'entrée souhaitée dans la liste.
Le concept de moteurs de recherche d'informations.
Moteur de recherche automatisé - un système composé de personnel et un ensemble de moyens d'automatisation de ses activités qui mettent en œuvre la technologie de l'information pour effectuer des fonctions établies.
L'expérience et la pratique de la création de systèmes dans divers domaines d'activité vous permettent de donner une définition plus large et universelle, qui reflète pleinement tous les aspects de leur essence.
Le système d'information est en outre comprise - un ensemble organisé de logiciels et d'aides techniques et autres, processus technologiques et fonctionnellement - certains groupes de travailleurs qui fournissent une collecte, une soumission et une accumulation de ressources d'information dans une certaine zone, la recherche et la délivrance des informations nécessaires pour se rencontrer Les besoins en informations des utilisateurs contingents établis - abonnés du système.
Caractéristiques des moteurs de recherche.
Dans le travail, le processus de recherche est représenté par quatre étapes: le libellé (se produit avant le début de la recherche); action (recherche de démarrage); Examen des résultats (le résultat que l'utilisateur voit après la recherche); et amélioration (après l'examen des résultats et avant de retourner à la recherche avec une autre formulation du même besoin). Un système de recherche d'informations non linéaires plus pratique comprend les étapes suivantes:
1. Fixer le besoin d'informations pour une langue naturelle;
2. Choix services de recherche réseaux et formalisation du compte rendu des informations nécessaires à des informations spécifiques et à des langues de recherche (IPA);
3. Effectuer les demandes créées;
4. Traitement préliminaire des listes obtenues des références aux documents;
5. faire appel à des adresses sélectionnées pour les documents requis;
6. Aperçu du contenu des documents trouvés;
7. Installation de documents pertinents pour une étude ultérieure;
8. Extrait des documents de référence pertinents pour élargir la demande;
9. Apprendre l'ensemble des documents enregistrés;
10. Si le besoin d'informations n'est pas entièrement satisfait, revenez à la première étape.
Le processus de recherche a un aspect didactique extrêmement profond - il est donc établi que l'application de systèmes d'information de dialogue conduit à la formation d'un tel style d'informations et d'activités de recherche dans les utilisateurs ordinaires, qui est généralement caractéristique des scientifiques les plus remarquables.
Dans la plupart des cas, le besoin d'informations survient après l'étude de tout nouvelle informationreçu par l'utilisateur. La situation se pose souvent lorsque l'utilisateur dispose déjà d'un certain nombre de documents sur le sujet du sujet. Il est proposé d'utiliser ces documents pour la compilation automatisée requête de recherche passant par système spécialisé Gestion de documents (Cour) (le système est en cours de développement).
Le système doit indexer tous les documents d'utilisateur. Dans le processus d'indexation, tous les mots contenus dans les documents sont divisés en classes sémantiques suivantes: Mots d'arrêt; les mots les plus fréquents de la langue du ménage (conversationnel); Terminologie communicatrice; Terminologie scientifique générale; système célèbre Termes de la zone; Mots inconnus. La partition est effectuée sur la base des dictionnaires correspondants qui devraient être partie de Systèmes. Les mots inconnus seront principalement attribués par de nombreux mots spéciaux de la zone. Il y aura également des termes nouvellement formés et des mots contenant des erreurs.
Sur la base de l'indice, la présentation vectorielle des documents est basée sur laquelle la Cour produit un regroupement hiérarchique d'une pluralité de documents, ce qui entraîne la partition de cet ensemble sur des groupes thématiques. Au cours du dialogue avec l'utilisateur, il existe un choix d'une ou de plusieurs des clusters les plus pertinents de documents et de définir les caractéristiques du processus de recherche.
La requête de recherche doit être construite sur la base du centre du cluster sélectionné. La taille optimale de la requête varie de 8-12 à 25-30 termes. La dernière opération préparatoire, la Cour, conclut une demande de demande de l'IPA.
Structure du réseau.
Comme vous le savez, le moyen le plus simple d'agrandir la recherche d'informations sur Internet est appliqué dans les systèmes de métapoik et augmenter la quantité d'IPS primaire. Ce mécanisme doit être mis en œuvre dans tout système développé. La répartition de la répartition des ressources de moteur de recherche sur divers systèmes IP du réseau mondial devrait être résolue de manière appropriée, sur la base de la comptabilisation de la part des références reconnues par des sessions de recherche précédentes.
La deuxième unité de moteur de recherche automatisée envoie la requête créée et la tresse et sélectionnez les références reçues, après quoi elles s'adressent aux adresses sélectionnées et reçoivent quelques documents multiples du réseau contenant également des hyperliens.
L'étude montre que l'opinion généralisée sur la teneur chaotique du remplissage des informations du réseau mondial et l'absence de toute structure de relations est l'illusion. La présence de "communautés" est révélée - des sites bien liés contenant des matériaux de gros sujets. Les pages "centrales" sont allouées - contenant de grandes listes de liens et de pages auxquelles de nombreuses références sont des pages "faisant autorité". Ainsi, le but de la 8ème étape de la recherche est la détection de tels groupes et identifie parmi leurs membres le plus "autoritaire". Comme indiqué dans, l'algorithme de résolution de cette tâche est assez simple.
Traitement des résultats de la recherche.
Après avoir reçu la recherche d'un réseau de certaines multitude de documents, il est nécessaire d'allouer le plus pertinent. La présence de «communautés» ne facilite pas cette tâche. Vous pouvez sélectionner plusieurs classes suivantes des situations les plus fréquentes.
1. L'absence d'informations de recherche sur le segment de réseau à l'étude. Une telle situation est décrite dans. Dans ce cas, allez à un autre segment, c'est-à-dire explorer généralement les ressources créées dans d'autres langues.
2. Les "communautés" trouvées contiennent des informations non conformes aux sujets requis, mais principalement sur les autres proches de la volonté souhaitée.
3. Des quantités trop importantes de ressources d'information ont été détectées.
Dans les deux derniers cas, vous devez énumérer automatiquement tous les documents trouvés et déterminer le degré de proximité de leur demande initiale. Plus de 20 mesures de proximité métrique adaptées à la comparaison des documents dans la représentation vectorielle sont considérées dans le travail. Solution optimale Les tâches de classement sont réalisées en appliquant un système basé sur une approche orientée de l'agence.
Dans de nombreux cas, recherchez dans nouvelle régionLorsque le niveau d'utilisateur global n'est pas suffisamment élevé, il est souhaitable de filtrer les informations émises sur le style du style de texte afin que la familiarisation initiale avec le matériau se produise en utilisant des textes populaires et populaires.
Pour réduire le volume des matériaux à l'étude, vous devez également filtrer les résultats de la recherche par type de sources. Il est tellement évident que les documents situés sur des sites scientifiques sur des serveurs commerciaux ou sur des serveurs de médias diffèrent de manière significative dans la nature.
Structure des moteurs de recherche.
La recherche du pointeur de recherche se produit en trois étapes, dont les deux sont préparatoires et invisibles pour l'utilisateur. Premièrement, le pointeur de recherche collecte des informations de Monde Large La toile. . Pour cette utilisation programmes spéciauxnavigateurs similaires. Ils sont capables de copier la page Web spécifiée sur le serveur de pointeur de recherche, de la voir, trouvez tous les hypothèques qui disposent des ressources qui sont trouvées là-bas pour trouver à nouveau les hyperliens disponibles en eux, etc. Ces programmes sont appelés. worms, araignées, chenilles, cragoleurs, araignées et d'autres noms similaires. "Chaque pointeur de recherche exploite son programme unique à cette fin, qui se développe souvent. De nombreux moteurs de recherche modernes sont nés de projets expérimentaux liés au développement et à la mise en œuvre de programmes de surveillance de réseau automatique. Théoriquement, avec une entrée réussie araignée Il est capable de jouer à tous les espaces Web d'une plongée, mais il faut beaucoup de temps, et il est toujours nécessaire de revenir périodiquement à des ressources visitées auparavant pour contrôler les changements qui se produisent là-bas et identifier les références "mortes", c'est-à-dire perdu la pertinence.
Après avoir copié les ressources Web en ligne sur le serveur de moteur de recherche, la deuxième étape du travail commence - indexation. Au cours de l'indexation, des bases de données spéciales sont créées, avec lesquelles vous pouvez installer, où et quand il a été trouvé sur Internet, un mot particulier. Considérez la base de données indexée est une sorte de dictionnaire. Il est nécessaire de veiller à ce que le moteur de recherche puisse répondre très rapidement aux demandes des utilisateurs. Les systèmes modernes sont capables d'émettre des réponses pour une fraction de seconde, mais si vous ne préparez pas d'index à l'avance, le traitement d'une demande continuera pendant des heures.
À la troisième étape, la demande du client traite et émettant des résultats de recherche sous la forme d'une liste des hyperliens. Supposons que le client souhaite savoir où il existe des pages Web sur Internet, sur lesquelles le célèbre mécanicien néerlandais, optique et chrétiens de mathématiciens, Guigens sont mentionnés. Il entre dans le mot Guigens dans le champ Set mots clés Et clique sur le bouton. Trouver (recherche). Selon ses bases de pointeur, le moteur de recherche de la fraction d'une seconde recherche des ressources Web appropriées et forme la page de résultats de recherche sur laquelle les recommandations sont présentées sous forme de liens hypertextes. Ensuite, le client peut utiliser ces liens pour la transition vers ses ressources.
Tout cela a l'air assez simple, mais il y a en fait des problèmes ici. Problème principal internet moderne Liée à l'abondance de pages Web. Il suffit d'entrer dans le champ de recherche si simple, comme par exemple le football, et le moteur de recherche russe donnera quelques milliers de liens, les regroupés de 10 à 20 morceaux sur la page affichée.
Quelques milliers ne sont pas tellement, car un moteur de recherche étranger aurait donné des centaines de milliers de recharges dans une situation similaire. Essayez de trouver parmi eux dont vous avez besoin! Cependant, pour un consommateur ordinaire, absolument de toute façon, ils lui donneront un millier de résultats de recherche ou un million. En règle générale, les clients ne considèrent pas plus de 50 références debout en premier et ce qui se passe, peu de gens sont dérangés. Cependant, les clients sont très et très inquiets pour la qualité le tout premier Liens. Les clients n'aiment pas quand il y a des références dans le premier top dix, ils ont perdu la pertinence, ils sont agacés lorsque les liens allaient dans les fichiers voisins du même serveur. La très mauvaise option - lorsque dans une rangée, plusieurs liaisons menant à la même ressource, mais situées sur différents serveurs.
Le client a le droit de s'attendre à ce que les liens les plus utiles soient les premiers à se tenir debout. Ici et le problème se pose. Une personne se distingue facilement par une ressource utile de manière inutile, mais comment expliquer ce programme ?! Par conséquent, les meilleurs moteurs de recherche exposent des miracles d'intelligence artificielle pour tenter de trier les références trouvées pour la qualité de leurs ressources. Et ils devraient le faire rapidement - le client n'aime pas attendre.
À proprement parler, tous les moteurs de recherche dessinent les informations source du même espace Web. Les bases de données source peuvent donc être relativement similaires. Et uniquement dans la troisième étape, lors de la publication des résultats de la recherche, chaque moteur de recherche commence à montrer ses meilleurs (ou pires) traits individuels. Opération Tri des résultats appelé classement. Chaque page de page Web trouvée attribue une note qui devrait refléter la qualité du matériau. Mais la qualité est une notion de subjective, et le programme a besoin d'arbres objectifs, qui peuvent être exprimés par des chiffres adaptés à la comparaison.
Les notes élevées sont reçues par des pages Web disposant d'un mot-clé utilisé dans, requis, entre dans le titre. Le niveau de notation augmente si ce mot est trouvé sur la page Web plusieurs fois, mais pas trop souvent. Affecte favorablement l'entrée de classement mots nécessaires Dans les 5-6 premiers paragraphes de texte - ils sont considérés comme les plus importants lors de l'indexation. Pour cette raison, les maîtres Web expérimentés évitent de donner la table au début de leurs pages. Pour le moteur de recherche, chaque cellule de la table ressemble à un paragraphe et, par conséquent, le texte de base significatif semble être au dos (bien qu'il ne soit pas perceptible à l'écran) et cesse de jouer un rôle décisif pour le moteur de recherche.
Très bien si les mots-clés utilisés dans la requête sont inclus dans les illustrations d'accompagnement du texte alternatif. Pour le moteur de recherche, il s'agit d'un signe certain que cette page correspond exactement à la demande. Un autre signe de la qualité de la page Web est le fait qu'il a des liens vers des autres pages Web. Ce qu'ils sont plus, mieux c'est. Donc, cette page Web est populaire et a un haut citation. Les moteurs de recherche les plus avancés sont suivis du niveau de pages Web enregistrées de citation et de la prise en compte lors du classement.
Les créateurs des pages Web sont toujours intéressés à les afficher plus de personnes, ils préparent donc spécifiquement des pages afin que les moteurs de recherche leur donnent une note élevée. Un bon travail compétent du Web-Master est capable de soulever de manière significative la participation de la page Web, mais il existe de tels "Masters" qui tentent de tromper les moteurs de recherche et de donner à leurs pages Web à l'importance qui n'est pas vraiment pas dans eux. Ils ont répété répété des mots ou des groupes de mots sur la page Web et pour ceux qui ne tombent pas dans les yeux du lecteur, ni leur font une police extrêmement petite, ou appliquent la couleur du texte qui correspond à la couleur de la couleur de la couleur de la couleur. Contexte. Pour de telles "astuces", le moteur de recherche peut être puni avec une page Web en s'approchant d'une sanction d'une note négative.
Ces dernières années, la pratique de la notation commerciale a été développée. Techniquement, ils sont équipés du plus moyens modernesCorrespondant au niveau de 2000 et la taille totale du Runet (secteur Internet russe) est aujourd'hui approximativement du secteur de l'Ouest en 1994-1995. Par conséquent, il n'y a pas de problèmes particuliers à la recherche d'informations en Russie et dans un proche avenir qu'ils ne sont pas prévus. Et dans le secteur occidental, des problèmes de recherche sont très importants et différents moteurs de recherche essaient de les surmonter différemment. À propos de la façon dont cela se passe, nous allons dire.
Des points de recherche en Russie aujourd'hui, il existe trois "baleines" (il y a des systèmes plus petits, mais nous ne les arrêterons pas). C'est "Rambler" (www.rambler. RU), Yandex (www.yandex. Ru) et "APort2000" (www.aport. Ru).
Le moteur de recherche historiquement le plus populaire est Rambler. Elle a commencé à travailler avant l'autre et pendant une longue période a conduit à la taille du pointeur de recherche et à la qualité des services de recherche. Hélas, aujourd'hui ces réalisations dans le passé. Malgré le fait que la taille du pointeur de recherche "Rambler" est approximativement égale à 12 millions de pages Web, il n'a pas été mis à jour il y a longtemps et donne des résultats obsolètes. Aujourd'hui, Rambler est un portail populaire, le meilleur système de classification de la classification en Russie (sur ce qu'il est, nous dirons ci-dessous) plus une plate-forme publicitaire. Traditionnellement, ce système tient la première place en Russie par la participation et présente de bons revenus publicitaires. Mais dans le développement des moyens de trouver l'outil, comme nous l'exposons ci-dessous, n'investissez pas.
Le pointeur le plus important sous-tend le système YANDEX. Simpling 27 millions de pages Web, mais ce n'est pas seulement en taille. Ce n'est pas simplement un pointeur pour les ressources et le pointeur des ressources les plus pertinentes. En ce qui concerne la pertinence de Yandex aujourd'hui est un chef inconditionnel (Fig. 7.3).
Le système "APORT" gagne dans la troisième étape: au moment de la soumission d'informations au client. Elle ne cherche pas à créer le plus grand pointeur outils automatiquesEt au lieu de cela, les informations du répertoire @RUS passant le traitement manuel sont largement utilisées. Par conséquent, le système n'est pas autant de résultats que ses concurrents les plus proches, mais ces résultats sont généralement exacts et clairement représentés.
Caractéristiques des moteurs de recherche.
Commencer à chercher quoi que ce soit sur Internet et d'avoir un minimum d'informations, ainsi que d'essayer de limiter la perte de temps, de tirer le meilleur parti de informations générales Il est possible de faire appel à la base de données suivante.
Base de données: Le sujet conduit aux ressources de pare-feu construites par des bibliothécaires.
Recherche: Les recherches peuvent être limitées au nom de la ressource, en la décrivant ou avec les titres de sujet spécifiés.
Résultats: Les résultats sont affichés dans l'ordre alphabétique par les noms de la ressource.
Adresse: http://sunsite.berkeley.edu/interneTind EX /
Yahoo! - Le plus célèbre moteur de recherche. Ses sites sont divisés en catégories et mots-clés. Il contient informations utiles par eux-même page d'accueil. Peut se connecter à d'autres moteurs de recherche
Bases de données: Recherche d'emploi Ressources Internet, Actualités, Cartes, informations promotionnelles, Information sportive, entreprises, numéros de téléphone, pages www personnelles et adresses électroniques (base de données séparée).
Recherche: Toutes les pages Yahoo offrent non seulement une zone de recherche simple, mais également les options de cette recherche, ainsi que la recherche d'adresses de courrier ou d'adresse électronique. La recherche peut être limitée pour spécifier une certaine période de temps. Les opérateurs booléens (et ou) et la recherche série sont également pris en charge. Remarque: si la recherche dans Yahoo! N'a pas abouti à un résultat positif, le processus de recherche entre automatiquement dans l'Alta Vista, qui continue de rechercher et, dans le cas de résultats positifs, renvoie automatiquement les informations trouvées dans Yahoo !.
Si Yahoo! Ne peut pas établir de communication rapidement avec Alta Vista, puis dans cette affaire Yahoo! fournira une page de communication avec un ensemble d'outils de recherche. Une fois l'une de ces cravates est sélectionnée, les mots-clés sont transmis au moteur de recherche à votre discrétion.
L'outil facilitant la recherche est la présence de "Tip Search" (TS) - Recherche avec "UGEA": Yahoo! Est un répertoire subordonné, ce qui signifie que le système n'a pas autant de pages que des moteurs de recherche, mais la tâche du mot clé le plus courant vous permettra de trouver le sujet nécessaire sur la page. haut niveau (La première page qui survient devant l'utilisateur lors de la visite du site) pour l'organisation ou la société.
RÉSULTATS: Les communications sont affichées conformément à la désintelligence du mot ont demandé à la séquence de la recherche avec leur texte descriptif et la hiérarchie subordonnée.
Adresse: http://www.yahoo.com/
Fréquence de modernisation: quotidiennement

Alta Vista prend en charge un ensemble de mots clés et de définir une page spécifique utilise des méthodes de renseignement artificielles. Les utilisateurs peuvent configurer des options de recherche et choisir un type de recherche - complexe ou simplifié, et à profiter également différentes façons fournir des informations. Contrairement aux machines qui indiquent uniquement les mots-clés, il indexe tout le texte, qui permet recherche complète. Cependant, à cause de cela, l'utilisateur peut simplement se noyer d'informations.
Bases de données: WWW Page et Usenet News situées dans le monde entier.
Recherche: Offres simples (Simple (s))) Rechercher ou (beaucoup plus avancé (MMS)), c'est-à-dire Plus avancé, méthode. S - La recherche est principalement utilisée pour questions générales, MMS - La recherche utilise la syntaxe de recherche spécifique. Pour faciliter l'exécution de la procédure, il y a un indice (aide de recherche simple). MMS - Recherche en utilisant BULIN (BOOLEAN), c'est-à-dire À l'aide des syndicats clés utilisant (et, ou non - (et, ou, ou non)) et un contact simple (proche - (environ)) vous permet d'utiliser plusieurs mots, d'alternance de mots, d'une phrase en tant que clé pour rechercher.
TS - Recherche: Introduction du type de clé: "Votre phrase" Comme premier sens de recherche qui limitera le nombre de documents wwws trouvés avec des en-têtes de type "Votre phrase".
Résultats: offre trois choix de résultats (mais deux donnent le même résultat):
1) "Standard" ("standard") - Les résultats obtenus par la machine sous la forme d'une liste des paragraphes, résumés par celui-ci avec la présence de l'adresse URL, la taille du fichier et la dernière date des mises à niveau. Les résultats sont retournés comme dix points à l'écran,
2) "compact" ("compact") mettez chaque élément d'une ligne avec la dernière date de mise à niveau des fichiers de la carte,
3) "détaillé" ("détaillé"), qui est identique à "standard".
Adresse: http://altavista.digital.com.
Fréquence de modernisation: www-robot de manière constante.
Excite utilise des informations pour analyser technologie de recherche IntelligentConceptXtraction, qui vous permet de faire des exemples de demandes. C'est le moteur de recherche le plus populaire en Amérique. Pour chaque page trouvée, il estime le degré de conformité à la demande.
Bases de données: www pages dans le monde, nouvelles, cartes, "Pages Jaunes" ("Pages Jaunes"), Logiciels libres, Citations principales, Télévision, Météo, E - adresses postalesVols de Airlines.
Recherche: offre uniquement S - recherche qui prend en charge certaines options MMS - Recherche.
TS - Recherche: Utiliser Plus (+) Pour déterminer que tous les documents ont ce mot ou utilisent moins (-) pour clarifier qu'aucun des documents n'a ce mot. Peut-être aussi soutenir dans les opérateurs de caredice.
Vous pouvez utiliser "et", "ou" et "et" et non "(et non) opérateurs et supports ronds pour le groupement. Par exemple: (numérique ou alors. Virtuel ou alors. Électronique) et bibliothèque.
(numérique ou alors virtuel ou alors électronique) ET bibliothèque.
Résultats: Les résultats sont affichés avec le nom du document, la décharge de pertinence en pourcentage, adresse URL - résumé logiciel Document et option pour restaurer «plus comme celui-ci» («plutôt»), ce qui vous permet d'utiliser le document comme votre question.
Adresse: http://www.excite.com/
Fréquence de la modernisation: constamment - www-robot.
![]()
Pour rechercher Internet utilise le traitement parallèle multiprocesseur 10. Million pages par jour. Restriction de bot à chaud latérale utile sur le type de bouton pour sélectionner des boutons.
Base de données: WWW Page située dans le monde entier.
Recherche: Offres S - Recherche et expert (expert) - Recherche, prend en charge les opérateurs booléens (et ou ou ou), la phrase de recherche et le choix de "homme" ou "URL". La recherche électronique prend également en charge les dates, l'emplacement (pays, etc.)
TS - Recherche: utilise la conclusion de la phrase en guillemets doubles (par exemple, "mots de phrase").
Résultats: Les résultats sont affichés avec le nom du document, la décharge de pertinence dans le pourcentage, l'URL, la taille du document.
Adresse: http://www.hotbot.com/
Fréquence de modernisation: constamment www-robot ("slurp").

Infoseeek est le moteur de recherche le plus populaire de l'industrie informatique. En mai 1996, il a été reconnu comme la machine d'information fournissant la plus fiabilité. L'attractivité de la machine est qu'après la lecture des informations, vous pouvez vérifier les informations trouvées à nouveau.
Bases de données: www Page située dans le monde entier, Nouvelles, stocks de citations, cartes, pages jaunes ("Pages Jaunes"), Adresses de messagerie, etc.
Recherche: offre uniquement une simple recherche s - recherche, mais les mots-clés de recherche peuvent être limités à des champs spécifiques (tels que dans les titres de document), la recherche en utilisant des opportunités ou à l'exception d'un mot donné (ce mot est précédé de moins "-") ou avec l'inclusion du mot requis (ce mot est précédé de "+"). Pour pour plus d'informations En ce qui concerne la recherche, utilisée. Aide Infoseek (aide Infoseek).
Résultats: Inclut le nom du document, la taille du fichier, l'URL, un bref résumé extrait du document et la décharge en pourcentage.
Adresse: http://www.infoseeek.com/
Fréquence de modernisation: www-robot de manière constante.
Informations supplémentaires: dans le cas d'un grand nombre d'informations, voir http://info.infoseeek.com/.

Lycos est l'un des premiers moteurs de recherche. La machine est pratique pour travailler avec la recherche et la visualisation simultanée des sites. Dans la sortie des informations d'information bref examenet les adresses trouvées.
Bases de données: World Www-pages, sons, images, "5% Top 5%"
Recherche: Offres S - Recherche et client (personnalisé (C)) Recherche. La C-Search prend en charge les opérateurs booléens et ou (et ou ou ou ou ou), ainsi que d'autres destinations.
Résultats: Les résultats sont faits à une liste ordonnée; Les informations incluent une adresse de document (URL), le nom, la taille du fichier et les vitesses d'obturation.
Adresse: http://www.lycos.com/
Fréquence de modernisation: www-robot de manière constante.
Problèmes et opportunités pour les moteurs de recherche.
Le travail de nombreux moteurs de recherche est considéré comme assez réussi. Cependant, tous les moteurs de recherche modernes souffrent de certains inconvénients sérieux:
1. La recherche par mots-clés donne trop de liens et beaucoup d'entre eux sont inutiles.
2. Un grand nombre de moteurs de recherche avec différents les interfaces des utilisateurs génère le problème de la surcharge cognitive.
3. Les méthodes d'indexation des bases de données ne sont généralement pas liées au contenu de l'information.
5. Les machines ne sont pas conçues pour comprendre la langue naturelle.
dans dernièrement Les besoins d'assistance intellectuelle augmentent rapidement. Cela a conduit à l'émergence d'agents intelligents.
Typiquement, les agents intelligents sont la partie principale du moteur de recherche pour la recherche intelligence artificielle. L'utilisateur enseigne à l'agent, puis il va en ligne à la recherche.
Les agents intelligents exécutent des instructions pour le compte de l'utilisateur, ont une certaine indépendance. Après la recherche, ils avertissent l'utilisateur sur les résultats. Les agents apprennent à la suite de leurs activités.
Intellectuelle - éducation basée sur rétroaction Par des exemples d'erreurs et par interaction avec d'autres agents.
Utilisation facile - vous pouvez former l'agent à l'aide d'une langue naturelle.
Une approche individuelle est une adaptation aux préférences des utilisateurs.
Intégration - Demande de formation continue ayant déjà des connaissances aux nouvelles situations.
Autonomie - Sensation de l'environnement et analyse des conclusions.
Conclusion.
Rechercher des voitures considérées par moi sont loin de la perfection. On pense que le moteur de recherche idéal doit répondre aux exigences suivantes:
1. Facile à utiliser
2. Index clairement organisé et mis à jour.
3. Recherche rapide dans la base de données et réponse rapide.
4. Fiabilité et précision des résultats de la recherche.
L'échelle des ressources d'information et leur nombre se développent constamment. Il devient clair que la base de données n'est pas parfaite. Agents intelligents - une nouvelle direction sous-jacente à une nouvelle génération de moteurs de recherche pouvant filtrer des informations et obtenir un résultat plus précis. Internet continue de se développer avec une intensité implacable, laver essentiellement une restriction sur la distribution et la réception de l'information dans le monde. Cependant, cette information océan n'est pas très facile à trouver document requis Il convient également de garder à l'esprit que sur le réseau avec des serveurs de longue durée, il y en a de nouveaux.
Systèmes d'information dans lesquels le stockage sont présentés et le traitement de l'information est effectué en utilisant Équipement informatique, désigné comme automatisé, diverses activités et la plupart des mémoires développant dans l'industrie des technologies de l'information.
Bibliographie.
1. E.A. Yakabatis "Réseau informatique-Electronics". M., "Finances et statistiques", 1989.
2 .. A. V. Gavrilov " Réseaux locaux EUM ", Moscou, maison d'édition" MIR ", 1990.
3. N.A. Gaidamakin "Systèmes d'information automatisés, bases de données et banques", M.: Helios, 2002.
Extrait du travail
introduction
La phase moderne du développement de la civilisation se caractérise par la transition de la partie la plus développée de l'humanité de la société industrielle à l'information. L'émergence et le développement du réseau informatique mondial de l'information sont l'un des phénomènes les plus vivants de ce processus.
Le problème de la recherche et de la collecte d'informations est l'un des problèmes les plus importants des moteurs de recherche d'informations. Bien sûr, il est impossible de comparer à cet égard, disons, au Moyen Âge, lorsque la recherche d'informations était un problème, car cette information n'était pas suffisante et que les efforts n'étaient pas obligés de trouver quoi que ce soit sur une question plus ou moins significative. Ainsi, au début, il était possible d'aller à la bibliothèque et de passer du temps à choisir parmi le livre souhaité sur le catalogue, trouvez les informations nécessaires. Mais les catalogues ne résolvent pas les problèmes de recherche d'informations même dans la même bibliothèque, car l'entrée de catalogue inclut relativement peu d'informations: le titre, l'auteur, le lieu de publication. Le problème de la recherche d'informations a gagné un nouveau caractère au XXe siècle, au début du développement des technologies de l'information. Maintenant, il ne réside pas dans le fait qu'il y a peu d'informations et qu'il est donc difficile de le trouver, mais qu'il est de plus en plus de plus en plus, et de trouver une réponse à la question d'intérêt peut également être une tâche assez difficile. . Le problème de la recherche d'informations est significativement compliqué lors de l'utilisation de sources virtuelles. Voici la technologie des annuaires en ligne, à la suite de l'application de laquelle l'utilisateur a la capacité de rechercher dans des répertoires de plusieurs bibliothèques à la fois, que, en fait, complique encore la tâche, mais d'autre part, augmente les chances de la résoudre.
1. Moteurs d'information et de recherche
Sous le système d'information est compris comme un ensemble organisé de logiciels et d'aides techniques et autres, processus technologiques et groupes de travailleurs définis fonctionnellement fournissant une collecte, une présentation et une accumulation de ressources d'information dans une certaine zone, la recherche et la délivrance des informations nécessaires pour répondre aux informations. besoins des utilisateurs. Les systèmes d'information sont les principaux moyens, des outils permettant de résoudre les problèmes d'appui à l'information de diverses activités et de l'industrie de l'industrie des technologies de l'information.
Le système de recherche d'informations est un système qui fournit la sélection et la sélection des données nécessaires dans une base de données spéciale avec des descriptions des sources d'informations (index) en fonction des informations et des règles de recherche associées.
Actuellement, deux moteurs d'information et de recherche fondamentalement différents (IPS) peuvent être utilisés pour rechercher des informations dans un espace d'information constamment croissant: systèmes de recherche d'informations pour les systèmes mondiaux de réseau et de référence et juridique (ATP). Les deux systèmes développent et fonctionnent indépendamment les uns des autres. Le partage de ces systèmes vous permet de résoudre rapidement et qualitativement la tâche de trouver des informations lorsque vous résolvez une large gamme de problèmes d'ingénierie.
La tâche principale de tout IPA est de rechercher des informations par les besoins d'informations pertinents de l'utilisateur. Il est très important du fait que la recherche ne contenait rien à perdre, c'est-à-dire de trouver tous les documents liés à la demande et de ne pas trouver quoi que ce soit superflu. Par conséquent, la caractéristique qualitative de la procédure de recherche est introduite - pertinence.
1.1 Information et moteur de recherche et informations
Lorsqu'ils parlent du moteur de recherche d'informations, il est impliqué qu'il utilise le pointeur substantiel. Le pointeur de sujet vous permet de trouver des documents relatifs à un certain "sujet". Pour compiler un pointeur de fond, le contenu du document est analysé et le "sujet" ou "objets" est déterminé, qui figure dans le document en question. Ensuite, les noms de ces éléments sont transférés dans la langue d'information et de recherche (IPA). Ainsi, nous obtenons l'image de recherche du document (sous). Appuyez sur (Création d'images de recherche) Toutes les ressources d'information, nous obtenons ce qui est coutume d'appeler l'index (la base de données d'index) est le tableau principal des données IPS.
Étant donné que le processus de recherche consiste à comparer la demande utilisateur avec les données disponibles, la demande reçue doit également être traduite dans l'IAPA. Après mapper une demande traduite dans l'IPA et des images de recherche, l'utilisateur reçoit une liste de références à des documents correspondant au système, sa demande.
La recherche ne se produit pas par le texte des documents, mais par leurs images de recherche, compilées sur l'IPA. Par conséquent, l'IPI est la partie principale du système d'information et de recherche, à partir de laquelle la qualité du système dépend principalement de. La composition de l'information et de la langue de recherche comprend:
1. Dictionnaire des termes indexés - de nombreux termes d'indexation.
2. Dictionnaire de code - Termes de code multiple.
3. Le dictionnaire d'entrée est une pluralité de termes d'entrée.
4. Des moyens auxiliaires Langage d'indexation - Moyens utilisés conjointement avec des conditions d'indexation pour élargir ou réduire certains concepts.
5. Conditions d'utilisation du langage d'indexation.
Schéma typique Les IP utilisant l'indexation du sujet sont présentés à la Fig. 1.1.
Figure 1.1 - Schéma typique des IPS
Pour améliorer l'efficacité de la recherche, le dictionnaire utilisé par le système doit être contrôlé, c'est-à-dire qu'il devrait être organisé de manière à ce que l'exhaustivité et la précision de la recherche soient optimales. De toute évidence, l'organisation du dictionnaire dépend de nombreux facteurs - la zone dans laquelle l'IPA sera utilisé, la nature des intérêts des utilisateurs, de leur degré de préparation, etc.
En général, la procédure de recherche est une procédure itérative, c'est-à-dire derrière la phase de résultats de la recherche, la demande est suivie de la demande, la recherche de cette demande, etc. schématiquement, une telle procédure est illustrée à la Fig. 1.2.
Figure 1.2 - Procédure de recherche
La correction de la demande se produit sur la base du nombre de documents reçus et de leur pertinence, et peut être effectuée en tant qu'utilisateur et le plus d'informations et du moteur de recherche.
1. 2 Sous-système du système d'information
La composition du système d'information peut distinguer trois sous-systèmes:
1. Le sous-système technologique d'organisation pour la collecte d'informations fournit le système d'information et comprend un ensemble de sources d'informations, de chaîne de sélection de chaîne de la chaîne organisationnelle et technologique pour l'accumulation dans le système. Sans le bon sous-système organisé de la collecte d'informations, une organisation efficace de l'opération est impossible pour l'ensemble du système d'information dans son ensemble.
2. Le sous-système de la fourniture et du traitement des informations est le noyau du système d'information et reflète la soumission des développeurs et des abonnés de la structure et de la situation de la zone, qui devrait refléter le système d'information. Le sous-système de soumission et de traitement est l'un des composants les plus complexes de l'élaboration du système d'information.
3. Réglementation - Le sous-système fonctionnel des informations émettrices définit les utilisateurs ou autrement des abonnés du système, met en œuvre l'aspect cible de la nomination et l'exécution des tâches du système d'information.
2. Fonctions de l'information et des moteurs de recherche
La base de tous les moteurs de recherche constituent des bases de données - un ensemble de données organisées par les règles limites prévoyant des principes généraux pour décrire, stocker et manipuler des données, quels que soient les programmes d'application.
Les éléments suivants du fonctionnement des systèmes d'information peuvent être distingués:
Collecte d'informations - organisé dans un processus spécial de collecte et d'affichage d'informations:
Recevoir les informations;
Évaluation des informations pertinentes;
L'ordre de sélection et de fixation d'informations.
L'emballage est le processus d'ajout d'informations provenant d'une variété de pièces en un seul tout et apportez-la à l'utilisateur.
La recherche et la délivrance de l'information sont la création d'une procédure technologique spéciale pour répondre aux besoins de l'information des abonnés du système d'information dans les activités de gestion et les processus technologiques.
Le maintien de l'intégrité et de la conservation de l'information - la révision, la révision et le dévouement à la pertinence croissante des informations font partie intégrante des divisions d'informations. La sécurité des informations est effectuée à l'aide d'instructions réglementaires.
Par la nature de la fourniture d'une organisation logique d'informations stockées, les systèmes d'information sont divisés en informations usines, documentaires et géographiques.
Les systèmes d'information factographiques accumulent et stockent des données sous la forme d'une pluralité d'instances d'un ou de plusieurs types d'éléments structurels. Chacune de ces cas d'éléments structurels ou une partie de leur combinaison reflète des informations, par tout fait, événement. La structure de chaque type d'objet d'information consiste en un ensemble fini de détails reflétant les principaux aspects et caractéristiques des informations pour les objets de ce domaine.
Dans les systèmes d'information documentaire, un seul élément d'information est indistinct en éléments plus petits, le document et les informations pour entrer, en règle générale, ne sont pas structurés ni structurés sous forme limitée. Pour le document d'entrée, certaines positions formalisées peuvent être installées - la date de fabrication, l'artiste, le thème. Certains types de systèmes d'information documentaire garantissent l'établissement de l'interconnexion logique des documents d'entrée - le Coenplex dans la teneur sémantique.
Dans les systèmes d'information géographique, les données sont organisées sous la forme d'objets d'information distincts liés à une base topographique électronique commune. Les systèmes d'information géographique sont utilisés pour l'appui des informations dans ces domaines, la structure des objets d'information et des processus dans lesquels il existe un composant géographique.
Un autre critère de classification des moteurs de recherche est des fonctions ou des tâches résolues. Cette fonctionnalité distingue les systèmes de référence, de recherche et de règlement.
Les références sont les fonctions types de systèmes d'information les plus courantes et permettent de fournir aux abonnés un système d'obtention de données d'installation à certaines classes d'objets.
La recherche est la classe la plus courante des systèmes d'information. En général, le formulaire peut être considéré comme une sorte d'espace d'information tel que défini en termes d'informations et de description logique de la zone.
Le calcul est calculé pour traiter des informations dans le système, selon certains algorithmes calculés à diverses fins.
Les fonctions technologiques des systèmes d'information sont d'automatiser l'ensemble du cycle technologique ou de ses composants individuels, de la production ou de la structure organisationnelle.
Ainsi, les principales fonctions de l'IPS peuvent être attribuées à:
- stockage de grandes quantités d'informations;
— recherche rapide Information requise;
- ajouter, supprimer et modifier des informations stockées;
- Afficher les informations dans une personne commode pour une personne.
Distinguer: - automatisé (coputérisé);
- bibliographique (référence);
- dialogue (en ligne);
- Information documentaire et facturation et moteurs de recherche.
Les systèmes d'information et de recherche ont récemment commencé à développer par accroître, de nouveaux systèmes apparaissent, ils sont largement annoncés et vendus. Cela est dû à l'augmentation significative de la société dans des travaux efficaces avec des informations juridiques et réglementaires et l'utilisation des informations informatiques et des moteurs de recherche. L'extension généralisée des moteurs de recherche était une véritable avancée dans le domaine de l'informatisation en Russie et a fourni la possibilité d'obtenir un accès gratuit à des documents juridiques et réglementaires.
La qualité des solutions adoptées par un spécialiste dépend du nombre d'informations traitées. Dans des conditions modernes, il est impossible de se passer d'un outil puissant et pratique qui aide à trouver et transformer des informations. L'utilisation efficace des moteurs de recherche dépend de la manière dont les experts techniques connaissent les spécificités, les possibilités et la portée de ces nouveaux systèmes d'information.
Créature systèmes modernes Le stockage d'informations est effectué de deux manières principales: à l'aide de modèles hiérarchiques et hypertextes. Le modèle hiérarchique utilise une rubrique à plusieurs niveaux lors de la classification des informations. Il l'utilise pour rechercher un document brève descriptioncompilé lors de la saisie d'informations dans le système. Le modèle hypertexte moderne permet documents électroniques Utilisez des liens vers d'autres documents.
Expérience d'exploitation divers systèmes Le traitement et la recherche d'informations basés sur de tels modèles indiquent qu'ils ne sont pas dédiés. Les deux systèmes nécessitent des coûts importants pour le développement et la formation, et sont donc limités dans des volumes d'informations stockées. La formation de référenceurs et de liens est faite par des experts et leur compréhension de l'information et de la représentation des utilisateurs peuvent varier.
3. Examen des moteurs d'information et de recherche modernes
L'adoption de décisions éclairées dans le domaine de l'économie et des politiciens est impossible sans poser une quantité suffisante d'informations juridiques. Particulièrement aigu, cette nécessité est ressentie lors de la réforme de l'appareil économique et politique. La tâche de satisfaire la nécessité d'une disposition opportune de la quantité nécessaire d'informations juridiques résolvez divers médias (médias).
Dans cette zone, ils concluent à la fois les médias traditionnels et les systèmes de référence et juridiques (ATP). Un ATP vraiment efficace ne peut être créé qu'avec l'utilisation de technologies de l'information modernes. L'ATP créé de cette manière est appelé ordinateur.
La référence informatique et le système juridique est un package logiciel comprenant une gamme d'informations juridiques et d'outils de travail avec elle. Ces outils peuvent vous permettre de rechercher des documents, de sélectionner une sélection de documents, de documents de sortie ou de leurs fragments de joint. Les avantages de l'ATP informatique sont évidents. C'est la disponibilité d'informations et la commodité de travailler avec elle. Le problème inhérent à de tels systèmes est une efficacité insuffisante - peut être résolue à l'aide d'un Internet global.
Sur le marché des systèmes de référence et juridiques en Russie, un grand nombre d'entreprises travaillent comme développant leurs propres complexes logiciels et ceux qui servent ceux existants. Les produits les plus connus de telles entreprises (soumis par JSC "Consultant Plus"):
"Consultant plus" (JSC "Consultant Plus");
"GARANT" (NPP "GARANT-SERVICE");
Codex (Centre pour le développement informatique).
Systèmes créés par des entreprises appartenant à l'État pour assurer les besoins des informations juridiques des ministères:
"Etalon" (NCI sous le ministère de la Justice de la Fédération de Russie);
"Système" (système de NTC "à FAPSI).
outre marché russe Systèmes présentés tels que:
"Yusis" ("Intalex");
"Référencier" (référent-service CJSC);
"Monde juridique" (House d'édition "Affaire et droit");
"Votre droit" et "conseiller juridique" (Société "Systèmes d'information et technologies");
"Législation de la Russie" (Association de développement des technologies bancaires) et d'autres.
Divers produits peuvent différer de manière significative non seulement sur les tâches résolues avec leur aide, mais également en qualité.
La qualité de l'ATP dépend de la qualité des informations fournies et de la qualité des outils utilisés pour travailler avec elle. L'utilisation du plus récent la technologie informatique Cela ne vous aidera pas si l'ATP ne contient pas d'informations légales complètes ou si les informations sont mises à jour avec une fréquence insuffisante. Inversement, l'ATP, qui contient même les informations les plus complètes et les plus modernisées, ne sera pas assez efficace si des outils de haute qualité ne sont pas fournis pour le traitement de ces informations. Ainsi, les principaux paramètres permettant de déterminer la qualité du contenu de la base d'informations sont les suivants:
plénitude des informations;
exactitude de l'information;
l'efficacité de la mise à jour des informations.
Paramètres caractérisant la qualité de la coque du logiciel:
capacités de recherche système;
moyens de mettre à jour des informations;
fonctions de service supplémentaires.
Considérons les principaux systèmes de référence.
3.1 Système de référence et juridique "Consultant plus"
Le système de référence et juridique "Consultant Plus" a été créé par JSC Consultant Plus et distribué depuis 1992. Le système est bien connu et dès le début de 2005, il faut l'une des principales positions en Russie. Le réseau de la société "Consultant Plus" combine plus de 300 centres d'information régionaux pour la fourniture d'informations d'ATP, de service et de transmission aux utilisateurs. Système de référence et juridique «Consultant plus» contient le plus différents types Informations juridiques: des actes de réglementation, des matériaux de pratique judiciaire, des commentaires, des projets de loi, des conseils financiers, des systèmes de réflexion des opérations en comptabilisation des rapports et des documents hautement spécialisés, des documents sont contenus dans le "consultant plus" d'information unifié. Étant donné que les documents de chaque type ont ses propres caractéristiques spécifiques, elles sont incluses dans les sections correspondantes de la matrice d'information: législation, justice judiciaire, conseil financier, commentaires de la législation, formes de documents, projets de loi, actes juridiques internationaux, actes juridiques pour les soins de santé .
Pour rechercher des documents dans ATP "Consultant Plus", vous pouvez utiliser plusieurs outils, la principale est une carte de recherche.
La carte de recherche est une table avec un certain nombre de champs de recherche. Pour chaque champ de recherche, le système fournit un dictionnaire, remplit et ajusté automatiquement en tant que documents dans la base d'informations (IB) arrive. Lors de la saisie du système de chaque document, ses détails sont enregistrés dans le dictionnaire approprié.
Dans l'ATP "Consultant Plus", il est possible de reporter le document trouvé ou la partie de celui-ci dans éditeur de texte Mot pour insérer des citations dans votre propre matériau.
Le programme "Consultant Plus" a un navigateur juridique. C'est un pointeur alphabétique substantiel constitué de concepts clés. Fermer les concepts clés sont combinés en groupes. Une telle structure à deux niveaux facilite le choix des concepts clés lorsque vous les spécifiez à rechercher des documents.
Toutes les bases de données ATP "Consultant Plus" sont liées à l'autre via des liens hypertextes qui vous permettent d'appuyer instantanément sur la clé instantanément, par exemple, du texte de la consultation au texte du document de réglementation référencé par l'auteur de la réponse. La chose la plus importante est qu'elle donne l'hypertexte aux utilisateurs - c'est une opportunité sans efforts supplémentaires pour retrouver la logique des arguments de l'auteur, qui examine rapidement les réglementations utilisées par eux pour plaider leur position à ce sujet ou à ce sujet.
3.2 Système juridique de référence "GARANT"
Le système juridique de référence "GARANT" est distribué depuis 1990 et bénéficie bien d'une grande popularité. grand nombre utilisateurs du marché de l'ATP. Elle a développé et distribue un cabinet informatique-développeur de systèmes juridiques de référence - une entreprise scientifique et manufacturière (NPP) "GARANT-SERVICE".
La société coopère activement avec le ministère juridique de l'État Douma et un certain nombre d'autres agences et organisations gouvernementales. Il possède une fabrication de haute technologie et de haute technologie avec un personnel important à Moscou et un vaste réseau de bureaux de représentation en Russie et à l'étranger.
Le système GARANT est un système de référence qui permet de rechercher et de travailler avec divers documents juridiques. Le système comprend règlementsCommentaires et explications, pratique judiciaire et arbitrale, ainsi que des dictionnaires intelligents.
Le système a un mécanisme de mise à jour périodique bases d'informationDonc, tout le temps sera conscient des derniers changements dans la législation.
Dans le système "GARANT", il existe tout un groupe d'informations et de blocs juridiques importants, à partir duquel l'utilisateur peut choisir l'activité nécessaire dont ils ont besoin et compiler un ensemble individuel dans lequel une recherche de document transversale sera effectuée.
Le kit «Garant Maximum» comprend tous les blocs du gouvernement fédéral et un bloc de la législation régionale. Ce kit comprend des documents sur toutes les sections de la législation: le droit pénal, administratif et international, ainsi que la pratique judiciaire et d'arbitrage et bien plus encore.
Certains blocs d'informations spéciales n'ont pas d'analogues à ce jour dans d'autres ATP. Celles-ci incluent "la législation dans les régimes", "projets de droit", "commentaires à la loi", "législation russe en anglais".
Très souvent, la situation se produit lorsque, lors de la mise en contact d'un ou d'un autre ATP, l'utilisateur ne connaît que le problème considéré et il n'y a aucune information sur les détails formels du document. Dans de tels cas, sans un système de recherche puissant pour la situation, il est presque impossible de trouver le bon taux de droit. Dans l'ATP "GARANT", cette tâche est résolue par un dictionnaire de mots-clés à deux niveaux ("Encyclopédie de situations").
3. 3 Informations et systèmes juridiques de la série Codex
Le développeur du système d'information et de juridiction (IPS) "Codex" est l'entreprise d'État "Centre de développement informatique" (GP "TSKR", Saint-Pétersbourg), créée au début de 1991
Les ventes de la première version du système contenant des actes de réglementation de Saint-Pétersbourg et de la Russie ont commencé en mai 1992
Le Codex IPS fait référence aux produits logiciels effectués à un bon niveau professionnel avec des caractéristiques positives dans tous les paramètres de base (complétude, efficacité, traitement juridique, etc.).
Produits d'information "Codex" comprennent: systèmes juridiques professionnels, systèmes judiciaires et arbitraux, systèmes de référence spécialisés, annuaires juridiques électroniques.
Indépendamment du nombre de bases d'information connectées, le travail est effectué dans un espace d'information unique associé à des hyperliens.
Une seule ligne produits logiciels Comprend un certain nombre de développements, y compris le package logiciel Codex-Master, qui est un ensemble d'outils permettant de créer et de gérer des informations de texte intégral et des moteurs de recherche de différentes directions.
Le principe d'ouverture du système d'information du Codex a permis au Codex-Master Complex de créer de nouveaux projets, tout en élargissant de manière significative la gamme de produits d'information "Code", par exemple: "Auditeur adjoint", "Services communaux de la Russie", " Sécurité industrielle »extrêmement pertinente dans notre ère des catastrophes artificielles.
Une activité importante du consortium du Codex est de fournir un accès aux informations juridiques via Internet, offrant ainsi un accès commercial et gratuit aux ressources légales du système Codex.
3. 4 Systèmes de la série "Référence"
garant de moteur de recherche d'informations
À la fin de 1995, le service de référence CJSC a enregistré un système d'information intégré (référent de référence », dont la propagation a débuté depuis 1996. À ce moment-là, ATP« Consultant Plus »,« Garant »et« Code »étaient déjà bien- Les dirigeants de marché connus et le "service référent" ont eu la possibilité de prendre en compte tout le meilleur, qui a été réalisé par ces entreprises.
Les systèmes de la famille de référents se composent d'un coquille et de modules d'information. Actuellement, le shell "référent-2000" utilise la plus grande popularité. Il vous permet de travailler simultanément avec des bases de données locales et des serveurs d'informations juridiques Internet, ainsi que de créer à l'intérieur de la coque de votre propre base de données avec un puissant éditeur et outil d'administration.
Les systèmes juridiques de référence de la famille de référents ont une interface conviviale pratique et mettent en œuvre toutes les fonctions principales des bases de données juridiques traditionnelles pour la recherche de documents, ainsi que de travailler avec une liste et un texte de documents.
L'interface "Référence" est aussi proche que possible de Windows, grâce auquel l'utilisateur n'a pas besoin de passer beaucoup de temps pour maîtriser le programme. Le référent prend en charge la fonction Glisser et Drop, permettant à la requête de rechercher des documents pour déplacer des informations à l'écran à l'aide de la souris. La recherche elle-même peut être effectuée simultanément dans les modules combinés et un certain nombre de documents contiennent des objets graphiques de couleur intégrés, par exemple, la couche d'armes de la Russie ou de Moscou.
L'éditeur de document intégré permet non seulement d'éditer des textes, mais également de créer une carte de documentation, de faire des commentaires, ainsi que d'insérer des images graphiques, y compris des liens d'animation (déplacement) et d'élargir les liens hypertextes.
Une autre caractéristique de la coque "référente" est la possibilité de créer et de maintenir votre propre base de données de documents contenant jusqu'à 200 documents, y compris la planification et la vidéo. Cette fonctionnalité est particulièrement intéressante pour les entreprises avec un petit flux de documents et numériques. Les grandes entreprises offrent un système de stockage de documents à 65 000 documents.
Conclusion
Le moyen le plus simple d'obtenir des informations dans l'espace d'information Internet en constante expansion est l'utilisation de divers moteurs de recherche. La fonction principale d'une telle machine est la visualisation automatique des nœuds de réseau et de la collection. information nécessaire. Les informations collectées sont soumises à l'indexation, c'est-à-dire intégrée dans un certain ordre et sont classées selon un critère spécifique. À l'avenir, ces informations sont utilisées pour maintenir les demandes des clients.
Des catalogues spécialisés ou des livres de référence sont créés sur des industries individuelles et des sujets, des nouvelles, des villes, des adresses e-mail etc.
Lors de l'entretien de l'utilisateur, deux approches principales sont en cours d'implémentation: recherchez des informations ou en déplaçant autour de l'arborescence de catalogue hiérarchique ou formez une requête de recherche dans le cadre d'un système de langue de recherche pris en charge.
Pour l'utilisateur de l'Internet moderne, le principal problème est l'organisation. recherche efficace informations. Les difficultés associées à la solution de ce problème sont évidentes, au fil du temps augmentera, car tous les quatre mois, la quantité d'informations sur le réseau double.
BIBLIOGRAPHIE
1. Alekseev E. G., Bogatyrev S. D. Informatique. Tutoriel électronique multimédia.
2. Ashmanov I. S. Promotion du site dans les moteurs de recherche / I. S. Ashmanov. - M.: Williams, 2007. - 304 p.
3. Ivassenko A. G. Informatique En économie et en gestion: didacticiel / A.G.i Vasamenko, A. Yu. Gridasov, V. A. Pavlenko. - 2e éd., Bien sûr .: Knuus, 2007. 160c.
4. Informatique. Cours de base: Tutoriel / ed. S. V. Simonovich. - SPB.: "Peter", 2007.-110 s.
5. Kadeev D. N. Technologies de l'information et communications électroniques / D. N. Kadeev. - M.: "Electro", 2005.- 250 p.
6. Kolisnichenko D.n. Moteurs de recherche et promotion de sites sur Internet / D. N. Kolisnichenko. - M.: "Dialectique", 2007. - 272 p.
7. LANDE D.V. Recherche de connaissances dans Internet / D. V. LANDE. - M.: "Dialectique", 2005. - 272 p.
8. Manning K. Introduction à l'information Recherche / C. Manning. - M.: "Williams", 2011.- 200 p.
9. Mikheeva E. V. Technologies de l'information dans les activités professionnelles: tutoriel. - M.: TK VELBY, PROSPECTION DE LA MAISON DE PUBLICATION, 2007.- 448C.
10. Organisation de travail avec Documents: Textbook / Ed. prof. V. A. Kudryaeva. - 2e éd., Pererab. et supplémentaire - M.: Infra-M, 2001.- 592C.
11. Sakharov E. V. Informatique. Instructions méthodiques / E. V. Sakharov. - Stavropol: STI, 2006.- 200 p.
12. Chursin N. A. Populaire Informatique / N. A. Chursin. - M.: Williams, 2007. 300 p.