La plupart des utilisateurs de la communauté Internet commencent leur journée de travail avec des moteurs de recherche où ils essaient de trouver de telles informations dont ils ont besoin et de résoudre leurs problèmes. Malheureusement, les moteurs de recherche ne sont souvent pas en mesure d'interpréter avec précision les ressources. En conséquence, les sites se trouvent souvent dans les premiers postes de la recherche de la question en cours de décision. Dans le même temps, les ressources représentant de vrais avantages sont la recherche «à la fois à la mer».
La raison de cette position est simple et réside dans la technologie d'obtention et de présentation des résultats par des moteurs de recherche. Il faut comprendre que le principal problème est le manque de règles claires disponibles et ouvertes à tous. Plus l'incertitude dans les algorithmes de la formation d'index de recherche (une certaine boîte noire), plus les moteurs de recherche reflètent le processus de formation d'informations réelles. Et, en conséquence, plus le niveau de confiance dans les résultats de la recherche des moteurs de recherche.
Comme non paradoxalement, ce ne sont pas les vins des moteurs de non-recherche, car ils doivent masquer les règles de construction d'index de recherche. Ce sont les vins de la technologie elle-même lors de l'organisation d'une recherche. En substance, la technologie des moteurs de recherche est dirigée vers un utilisateur passif. Il est nécessaire d'enregistrer uniquement le site, puis tout fera un robot de recherche. Il scanne la page de ressources de la page, essayant d'analyser le contenu de chacun d'eux. La péniité de l'utilisateur est minime, ce qui permet d'utiliser différentes techniques pour "tromper" des robots de recherche à des coûts faibles des forces et des moyens. Dans un tel système de travail, les moteurs de recherche doivent modifier des algorithmes et des règles pour l'indexation des ressources et de la construction. indice de recherche.
Bien sûr, la plupart des utilisateurs ont apprécié, utiliser et seront utilisés par les moteurs de recherche classiques. C'est simple, pratique et distribué. C'est comme une habitude, profitez de moteurs de recherche.
Informations générales sur les moteurs de recherche
Système de recherche - Ce logiciel qui donne accès à la collection d'informations à faible résistance. Orientation sur des données à faible repose, c'est-à-dire Les données qui ne peuvent pas être soumises en tant que tableau relationnelle distinguent le moteur de recherche de la SGBD.
DANS cette définition Le moteur de recherche implique des informations de différents types, c'est-à-dire Texte, audio, vidéo, images, etc. Cependant, il convient de noter qu'il s'agit des données de texte idéales pour décrire la fonctionnalité complète du moteur de recherche, car Les algorithmes de recherche multimédia sont principalement basés sur des algorithmes de recherche de texte.
La tâche principale du moteur de recherche - minimiser le temps passé par l'utilisateur à rechercher une demande d'informations pertinente. La pertinence est l'un des concepts les plus subjectifs et les plus impliqués de la science. recherche d'information. Le plus souvent parle de la pertinence du point de vue de l'utilisateur, puis «Informations pertinentes de la demande» »et« les informations nécessaires à l'utilisateur »» est la même. Il s'agit d'une telle pertinence que nous parlons cette section. La question est la question que l'utilisateur compte-t-il nécessaire? Dans certaines circonstances, des informations pertinentes peuvent être définies comme toutes les informations de la base de données, qui est liée à la demande. Par exemple, si l'utilisateur doit tout apprendre sur une entreprise spécifique, il souhaite trouver tous les documents mentionnés par cette société. Dans d'autres circonstances, des informations pertinentes ne sont que cette information suffisante pour effectuer une tâche d'utilisateur spécifique, par exemple la recherche d'une réponse à une question spécifique. Si dans ce dernier cas dans les résultats de la recherche, il y aura beaucoup de données redondantes, c'est-à-dire Données liées à la demande, mais non nécessaires pour effectuer cette tâche, puis l'échantillon de la valeur souhaité / les informations pertinentes Je vais prendre le temps supplémentaire de l'utilisateur.
Ainsi, le moteur de recherche traditionnel utilise deux caractéristiques principales: Précision et plénitude , Plus précisément, leur dépendance. Chaque fois que l'utilisateur spécifie la demande du système, initialisation de la recherche, tous les documents de la collection de moteurs de recherche sont divisés en quatre parties. La précision définit un aspect de recherche, à savoir comment bien le moteur de recherche est capable de minimiser le temps passé par l'utilisateur à la recherche de pertinence. cette demande informations. Bien que l'exhaustivité détermine l'autre aspect - quelle est la qualité du système de trouver des informations pertinentes pour cette demande. Vous pouvez choisir la ou les requêtes optimales lorsque chaque document trouvé sera pertinent et que chaque document pertinent sera trouvé.
Moteurs de recherche lorsque vous utilisez Internet jouer un rôle très important. Sur Internet, une telle information est concentrée que sa recherche se transforme déjà en une tâche distincte et prend beaucoup de temps. Les serveurs de recherche émettent des milliers de liens vers une demande au lieu de plusieurs pages où vous avez vraiment les informations nécessaires. Les utilisateurs d'Internet mondiaux, réalisant les avantages fournis par la possibilité d'analyser des données spatiales, ont besoin d'un outil qui vous permet de faire une recherche rapide et pratique et d'accéder aux parties numériques du terrain et d'autres informations spatiales concentrées dans de nombreuses organisations gouvernementales, commerciales et académiques. .
Un peu de l'histoire ...
Moteur de recherche (serveur de recherche, moteur de recherche) - Un site spécial sur lequel l'utilisateur sur une requête donnée peut obtenir des liens vers des sites répondant à cette demande.
Le fonctionnement du moteur de recherche, en règle générale, se compose de deux étapes. D'abord - programme spécial (Robot de recherche) ou une personne collecte des informations à partir de pages Web et les indexe. Lorsque l'utilisateur spécifie la requête, la recherche se passe sur un index pré-construit. Le résultat de la recherche est le soi-disant Émission de recherche - Liste des références aux documents (pages Web) correspondant à la requête.
La plupart des moteurs de recherche recherchent des informations sur les sites Internet, mais il existe également des moteurs de recherche capables de rechercher des serveurs FTP, des documents, ainsi que des informations dans réseaux internes Etc. DANS dernièrement Un nouveau type de moteurs de recherche basés sur la technologie RSS est apparu.
Le moteur de recherche est basé sur le travail du moteur de recherche. Les principaux critères de la qualité du moteur de recherche sont la pertinence, la plénitude de la base, marquant la morphologie de la langue.
Le plus populaire machines à la recherche En Russie, Google, Yandex et Rambler sont aujourd'hui pris en compte.
Le premier moteur de recherche était "Wandex", ce qui n'a plus de site Web existant, qui a créé Matthew Gray de l'Institut de technologie Massachusetts en 1993. Un peu plus tard, le moteur de recherche "Aliweb", existant jusqu'à présent. Premier texte intégral moteur de recherche Il est devenu "webcrawler", lancé en 1994. Contrairement à ses prédécesseurs, il a permis aux utilisateurs de rechercher des mots-clés sur une page Web, car elle est devenue la norme dans tous les principaux moteurs de recherche. De plus, il s'agissait du premier moteur de recherche, connu dans de grands cercles. En 1994, Lycos a été lancé, développé à l'Université de Carnegie Melon.
Le développement des moteurs de recherche russes a débuté en 1996 avec l'avènement de l'expansion morphologique au moteur de recherche d'AltaVista et le lancement des moteurs de recherche russe originaux Rambler et APort. Bientôt, en 1997, le moteur de recherche Yandex a été ouvert.
Aujourd'hui, plusieurs centaines de divers moteurs de recherche, caractérisés par une spécialisation, des capacités et des techniques de recherche travaillent dans le monde.
nouvelles
- 20/ 12/ 2005
Tokyo, 20 décembre - Ria Novosti, Andrei Fesyun. Le Japon développera son propre moteur de recherche pour Internet dans l'opposition de la popularité du système Google américain.
Selon un employé du ministère politique d'information Le ministère de l'Économie, du commerce et de l'Industrie Fumihiro Kadzikawa (Fumihiro Kajikawa), sera créé à cette fin, une équipe de recherche sera créée avec la participation de représentants de vingt universités et de vingt sociétés pour la production d'électronique.
"Nous n'avons pas l'intention de rivaliser avec Google ou Yahoo, mais nous pensons à créer système unique Exclusivement pour le Japon », a déclaré Kadzikawa. Selon ses informations, le système sera principalement conçu pour rechercher des images, en particulier des photographies.
Le représentant du ministère a déclaré que la première réunion du Groupe tiendrait le vendredi le plus proche, un rapport intérimaire sur ses activités sera soumis au ministère en mars et le dernier en juillet de l'année prochaine.
- 09.2005
G.i. Ruzaykin
PC World :: Ruban de presseSur le chemin de l'espace d'information complet, les problèmes de recherche d'informations sur le réseau sont particulièrement graves. Cela devient évident dans le contexte du succès technologique du développement d'Internet, notamment relatives à la fourniture d'informations à l'utilisateur (ce qui signifie le taux de transfert de données, leur volume et leur qualité). C'est pourquoi le développement technologique et produits logiciels Pour rechercher des informations, des informations sont si importantes sur le marché informatique.
DVYGUN (www.dvygun.com) a annoncé la publication d'une nouvelle version du moteur de recherche personnelle gratuit Dvygun Smart Search 2.5.2.5 Beta, qui permet une recherche en texte intégral dans les tableaux des documents, des messages e-mail, fichiers multimédia, sur les pages Web visites et parmi les données de contact stockées dans le PC de l'utilisateur.
Dans le même temps, le programme de recherche intelligent de Dvygun effectue la recherche d'informations (fichiers) des types suivants:
- email et Outlook / Outlook Express Pièces jointes;
- des dossiers formats PDF, MS Word, MS Excel, RTF, HTML et Texte;
- les données archives zip, Rar, gzip, taxi, etc.;
- images, fichiers musicaux et vidéo;
- pages Web visitées, Adresses Internet Favoris navigateur Internet Explorateur;
- contacts Adresse des livres sous Windows et Outlook.
La recherche de données peut être guidée à la fois par tous les types et comme sélectionné. Une nouvelle réduction de la zone de recherche est effectuée lors de la spécification des paramètres de recherche. Par exemple, pour les fichiers, ils peuvent être le "nom de fichier", "dossier", "taille" et "date de changement". Le classement des documents trouvés est effectué en termes de conformité avec la requête de recherche. Pour les demandes verbales, la proximité contextuelle des mots est prise en compte, chaque document trouvé est affiché dans les résultats de la recherche avec la citation contextuelle, qui accélère dans la plupart des cas de compréhension de son contenu.
Pour l'organisation de la recherche instantanée, la recherche intelligente DVYGUN fabrique le traitement de données primaire pour créer une base spéciale (index) sur laquelle cette recherche est effectuée. Voici quelques fonctionnalités de la mise en œuvre de cette fonctionnalité dans ce programme: la recherche et l'indexation peuvent aller simultanément à la fois pour démarrer la recherche que vous n'avez pas besoin d'attendre la fin de l'indexation; La mise à jour de l'index se produit dans " mode de fond"Le programme surveille en permanence les actions de l'utilisateur, de sorte que les données modifiées et nouvelles sont immédiatement incluses dans l'index, c'est-à-dire que les résultats de la recherche sont actualisés; en cas de déficience des ressources système, le processus d'indexation s'arrête pour éviter de ralentir l'ordinateur de l'utilisateur.
Selon les développeurs de la recherche intelligente de Dvygun, vérifiant leurs programmes pour la présence et la qualité des panneaux de recherche (à la mise à jour de l'index à la volée, en comptant la pertinence des résultats, le réglage, le taux d'indexation et du support de la morphologie du Russe La langue) la met en avance sur de tels moteurs de recherche célèbres que Google, Yahoo, Microsoft, Copernic et Blinkx. Aucun concurrent satisfait aux exigences de la disponibilité et de la qualité de ces signes. Le programme de la recherche intelligente de DVYGUN effectue une indexation à un taux de 5 GB / H et le traitement morphologique des paroles de russe et langues ukrainiennes. Malheureusement, aucun des célèbres moteurs de recherche nationaux et ukrainiens n'est capable d'indexer si rapidement. Dans le même temps, les inconvénients de cette version de Dvygun Smart Search Developers incluent un petit nombre de formats de fichiers traités par celui-ci: vous pouvez corriger le cas soit en achetant les filtres appropriés, soit par leur propre développement.
Le développement des moteurs de recherche existants est mis en évidence par le message de Yandex (http://company.yandex.ru/news/2005/0628) que la nouvelle version du programme YANDEX.SERVER exécutive toutes les versions populaires de Windows et Unix, J'ai commencé à fonctionner plus vite. Cela a élargi un groupe de produits pour une recherche d'informations en texte intégral et augmenté la vitesse du traitement de documents un et demi. Le nombre de types de documents traités est augmenté: maintenant en plus des formats.txt, .doc, .rtf, .html, .xml i.pdf pris en charge .xls, .ppt i.swf. Augmentation également la vitesse des fichiers d'indexation de 25 à 40 Mo / s.
Pour les utilisateurs qui sont importants pour gérer la conception des résultats de la recherche, un paquet d'approvisionnement d'une nouvelle version de ce programme est au prix de près de 2 fois inférieur à celui de seulement 170 dollars. En outre, le comité de rédaction est apparu pour les propriétaires de la norme + et des sites professionnels + des fonctionnalités avancées.
Selon le bureau de représentation russe de convera (www.convera.su), l'année prochaine, ses efforts en Russie visaient à promouvoir le nouveau moteur de recherche Excalibur et à développer une version localisée de la rétrograité 8.2. Il mettra en œuvre de telles fonctions standard telles que des entités extraites du texte (dans la première version, les noms géographiques, les noms de Times, Devises, Dates, Numéros - Téléphone cartes de crédit et automobile, ainsi que des liens entre eux), adaptateurs de complexes logiciels WebSphere, Portail SharePoint, Documinum, New Lotus, Windchill et TeamLink.
À l'automne de l'année en cours, Excalibur apparaîtra en Russie. La différence la plus significative entre ce produit d'autres moteurs de recherche mondiaux similaires est de clarifier le montant des informations pertinentes offertes à la suite de la recherche. Une telle efficacité est possible grâce aux 12 millions de taxonomies intégrées dans le programme, avec lesquelles des informations sont traitées sur demande. Dans le processus de traitement de la demande, son concept taxonomique est déterminé ( domaine), Par conséquent, toutes les informations sont divisées en deux groupes - une enquête pertinente et non pertinente. Dans le même temps, les résultats de la requête peuvent être représentés comme tables, images graphiques, textes et connexions d'information. La réponse devient l'affichage de l'essence de la demande et de ses connexions dans l'ensemble des documents proposés à la suite de la recherche de documents.
- 23 mars 1998.
Nouveau moteur de recherche sur InternetNewman Seeart Recherche Recherche Définition Service Service lancé sur la technologie de l'information. Newman Search combine les avantages de la "distillation" et des répertoires en même temps. Toutes les sources pour lesquelles la recherche est produite est regroupée par les sujets "Presse informatique", "Actualités", " Entreprises informatiques"Etc. Les utilisateurs peuvent limiter la zone de recherche avec des sections pertinentes, réduisant de manière significative le" bruit d'information "et l'heure de la recherche du document souhaité.
Les sujets de sites Web de Newman Search sont limités exclusivement aux ordinateurs, Internet et informatique. La préférence est donnée aux sources primaires et aux sites contenant des informations systématiques (documentation, descriptions, tests, prix, opinions, nouvelles, communiqués de presse).
Newman Search se distingue par l'indexation quotidienne opérationnelle des serveurs - avec une période de 1 jour (pour la section "Actualités") jusqu'à 7 jours (pour les entreprises de sites entreprise informatique). Alors que les informations de mise à jour des moteurs de recherche habituelles doivent être attendues pendant des mois.
La recherche est effectuée en tenant compte de la morphologie de la langue russe et de la terminologie informatique. Par exemple, si vous recherchez "HDD", voir les mots "HDD" "Winchester" "" disque dur "" NZHMD ", etc.
Les statistiques de transition ouvertes forment une sorte de note de site Web informatique sur l'informatif. De plus, la note est supportée séparément pour chaque section du type "Actualités" "Entreprises informatiques", etc.
Moteur de recherche Yandex
Historique du moteur de recherche Yandex
L'histoire de Yandex a débuté en 1990 avec le développement de logiciels de recherche à Arkady.
En 1993, Arkady est devenue une division de Comptek. En 1993-1994 ans technologies logicielles Il a été considérablement amélioré grâce à la coopération avec le laboratoire Yu. D. APRESAN (Institut d'information Transfert de RAS).
À l'été 1996, les développeurs de la gestion et des moteurs de recherche Comptek ont \u200b\u200bconclu que le développement de la technologie elle-même est plus important et plus intéressant que de créer des produits appliqués à base d'applications. Les études de marché ont montré une rapidité et de grandes perspectives de technologie de recherche.
Le mot "Yandex" a inventé quelques années avant l'un des développeurs principaux et les plus anciens du moteur de recherche. "Yandex" signifie "index de langue" ou, si en anglais, "Yandex" - "Encore un autre indexeur".
Officiellement, le moteur de recherche Yandex.ru a été annoncé le 23 septembre 1997 à l'exposition Soellool. Les principales caractéristiques distinctives de Yandex.ru à cette époque constituaient l'inspection de l'unicité des documents (l'exception des copies dans différents codages), ainsi que des propriétés clés du noyau de recherche Yandex, à savoir: la comptabilité de la morphologie du russe langue (y compris la recherche de formulaire de texte précis), la recherche de distances d'inscription (y compris dans un paragraphe, une phrase précise) et un algorithme soigneusement développé pour évaluer la pertinence (réponse de la requête), en tenant compte non seulement du nombre de mots de la Demande trouvée dans le texte, mais aussi le "contraste" du mot (sa fréquence relative pour ce document), la distance entre les mots et la position du mot dans le document.
En novembre 1997, une demande de langue naturelle a été mise en œuvre. À partir de maintenant, Yandex.ru peut être adressé simplement "en russe", définir des demandes longues, par exemple: "Où acheter un ordinateur", "produits génétiquement modifiés" ou "codes internationaux" communication téléphonique"Et obtenir des réponses précises. La durée moyenne de la requête à Yandex.ru est maintenant de 2,7 mots. En 1997, il s'agissait de 1,2 mot, puis les utilisateurs de moteurs de recherche étaient habitués au style télégraphe.
En 1998, à Yandex.ru, il a été possible de "trouver un document similaire", une liste de serveurs trouvés, de rechercher dans une plage de date spécifiée et de trier les résultats de la recherche pour le dernier changement.
Pour 1999, Yandex a publié un nouveau robot de recherche, qui permettait d'optimiser et d'accélérer la traverse des sites de raquette. Le nouveau robot a permis aux utilisateurs de fournir aux utilisateurs de nouvelles fonctionnalités - recherchez différentes zones de zone de texte (titres, liens, annotations, adresses, inscrivez-vous pour des images), recherchant des liens et des images, ainsi que d'allouer documents en russe. Une recherche dans les catégories du catalogue est apparue et pour la première fois dans Runet, le concept de "citation" a été introduit.
En 2000, Yandex a été formé. Yandex a été créé par les actionnaires de Comptek - une entreprise créée et depuis longtemps développé le projet de Yandex. Les exploitations RU-NET ont investi 5 millions 280 000 dollars et ont reçu une part dans une nouvelle société de 35,72%. Les actionnaires incluent également la gestion et les principaux développeurs de moteurs de recherche. Le directeur général est devenu Arkady Volozh.
La société nouvellement formée est passée à tous les droits à la marque Yandex et au site www.yandex.ru, ainsi que sur technologie de recherche Index et famille de produits logiciels Simmental. De plus, le projet nouvellement démarré www.narod.ru a été transmis à Yandex.
Gestion d'indexation dans le moteur de recherche Yandex
Les autorisations et interdit l'indexation provient du fichier robots.txt. Yandex prend en charge la balise méta robots, la balise NOINDEX et les robots d'expansion non standard.txt - Directive hôte. Les autorisations et la prohibition de l'indexation sont prises par tous les moteurs de recherche du fichier robots.txt situé dans le répertoire racine du serveur. L'interdiction de l'indexation d'un certain nombre de pages peut apparaître, par exemple, du désir de ne pas indexer mêmes documents dans différents codages. Plus le serveur est petit, plus le robot le coûtera plus vite. Par conséquent, il est souhaitable d'interdire tous les documents du fichier robots.txt qui n'a pas de sens à indexer.
Le moteur de recherche Yandex prend en charge les robots d'expansion non standard.txt - Directive hôte. L'argument de la directive hôte est nom de domaine (Un nom d'hôte correct qui n'est pas une adresse IP) avec le numéro de port (80 par défaut) séparé par le côlon. Si un site n'est pas spécifié comme argument d'hôte, cela signifie la disponibilité de la directive DIBALL: /, I.e. Une interdiction complète de l'indexation (s'il existe au moins une directive hôte correcte du groupe).
Cette extension non standard vous permet d'aider le moteur de recherche à choisir le miroir droit pour l'indexation. En fait, dans la directive hôte, le miroir principal du site est indiqué, tandis que l'indexation de tous les autres miroirs est interdite.
Pour la compatibilité avec des robots qui ne sont pas entièrement suivis de la norme Robots.txt, la directive hôte doit être ajoutée au groupe commençant par l'entrée d'agent utilisateur, immédiatement après interdire les entrées.
Les analyses des moteurs de recherche Yandex et doivent indiquer la balise Meta Robots. Pour interdire l'indexation de certaines parties du texte, elles peuvent être étiquetées avec des balises.
Ajout de pages dans le moteur de recherche Yandex
Yandex parcourant des centaines de milliers de pages Web à la recherche de modifications ou de nouveaux liens. Les propriétaires de ressources peuvent ajouter indépendamment leur site Web en remplissant le formulaire de formurl. Yandex parcourant des centaines de milliers de pages Web à la recherche de modifications ou de nouveaux liens. Les propriétaires de ressources peuvent ajouter indépendamment leur site Web en remplissant le formulaire de formurl.
Index Yandex réseau russePar conséquent, les serveurs de domaines SU, RU, AM, AZ, BY, GE, KG, KZ, MD, UA, UZ sont introduits dans le moteur de recherche. Le reste des serveurs ne sont entrés que s'ils trouvaient du texte en russe ou si les propriétaires de ressources tuent l'administration de l'équipe dans le fait que leur serveur est intéressant pour les utilisateurs de l'Internet russophone (cela se fait généralement en écrivant sur [Email protégé]).
En règle générale, les pages apparaissent dans la base de recherche d'ici une semaine après leur apparition ou leur changement. Les nouvelles pages apportées à la base de données à l'aide de Advurl apparaîtront plus rapidement (s'ils sont dans la partie de langue russe du réseau et ne nécessitent pas de contrôle manuel).
Engine de recherche Yandex - Texte intégral, c'est-à-dire que son indice tombe (et deviennent accessibles à la recherche) uniquement les mots qui sont écrits sur les pages des sites.
Dans la liste des résultats de la recherche après l'adresse de la page, le texte est affiché, qui consiste en un titre (TEG TITLE), descriptions (TEG Meta Name \u003d "Desription" Content \u003d "") ou début du document (si cette balise est Non) et contextes - fragments du texte du texte senior contenant des mots de requête.
Indexation dans le moteur de recherche Yandex
Lorsque Yandex détecte une nouvelle page ou modifiée, il l'indique. Dans le processus de cette page, la page est divisée en éléments dont le contenu est entré dans l'index. Lorsque Yandex détecte une nouvelle page ou modifiée, il l'indique. Dans le processus de cette page, la page est divisée en éléments (texte, titres, signatures aux images, liens, etc.), dont le contenu est entré dans l'index. Dans le même temps, les positions des mots sont prises en compte, c'est-à-dire leur position dans le document ou son élément. Le document lui-même n'est pas stocké dans la base de données.
Yandex indexe les pages dans leurs véritables adresses. Cela signifie que si la page a une redirection, le robot le prendra en tant que lien vers une nouvelle adresse et le rend dans la file d'attente d'index.
Comme standard nécessite protocole HTTP, Yandex, après avoir reçu les informations dans l'en-tête les informations que cette URL est un redirection (codes 3xx) ajoute à l'adresse du contournement URL, qui est entraîné par la redirection. Si la redirection était permanente (code 301) ou si la directive méta-rafraîchissement a été remplie sur la page, l'ancienne URL sera exclue de la liste des horloges.
Le Robot Yandex stocke le dernier contexte de chaque page, la date de sa modification (envoyée par le serveur Web) et la date d'apporter les dernières modifications à la base de données de recherche (date d'indexation). Il optimise le contournement réseau de manière à visiter le plus souvent des serveurs les plus chancables. Le robot Yandex fonctionne automatiquement et le réindiffusion habituellement a lieu une fois toutes les deux ou trois semaines.
Les changements dans les pages déjà indexées des pistes de robot Yandex sont indépendamment au prochain entrant dans le site. Le robot a son propre horaire et le changement est impossible.
Index Yandex Le document Complètement: Texte, Titre, Signatures de photos, description (description), mots clés Et d'autres informations.
Yandex Robot contournez les pages «dynamiques» et les renvoient exactement aussi bien que «statique». Le robot de recherche Yandex Outre les formats Standard HTML, Indexes: PDF, Doc, RTF et FLASH FILE.
Dupliquer - Il s'agit du même texte sous une douzaine d'adresses différentes, selon, par exemple, de la méthode de navigation sur site. Sites avec un grand nombre de doublons de temps à autre exposés à un nettoyage impitoyable.
Sites de miroirs
Miroir - copie partielle ou complète du site. La présence de doublons de la ressource est nécessaire aux propriétaires de sites hautement simulés pour améliorer la fiabilité et la disponibilité de leur service.
Un grand nombre de miroirs portait la base de données des moteurs de recherche et conduit à l'apparition de duplicats dans les résultats de la recherche. Par conséquent, lorsque le robot Yandex découvre plusieurs miroirs du site, il en choisit l'un d'entre eux en tant que principal, le reste de l'indice est supprimé. Par défaut, le robot choisit dans le miroir principal en fonction de ses propres considérations. Et généralement pas ce que j'aimerais voir le propriétaire de la ressource.
Vous pouvez prendre un certain nombre de mesures pour sélectionner le site souhaité comme miroir principal.
Premièrement, vous pouvez supprimer les miroirs de site non centraux.
Deuxièmement, sur tous les miroirs, en plus de choisir le principal, placez le fichier robots.txt, qui interdisent complètement l'indexation du site. Soit déposer sur des miroirs robots.txt avec la directive hôte.
Troisièmement, placez sur les pages principales de la balise de miroirs non miniers, interdisant leur indexation et leurs liaisons de contournement.
Quatrièmement, modifiez le code des pages principales sur des miroirs non essentiels afin que tous les références (ou presque tout) de ceux-ci profondément dans le site soient absolus et conduits au miroir principal.
Dans le cas de la mise en œuvre de l'un des conseils ci-dessus, le miroir principal sera automatiquement modifié en tant que contournement de Robot de recherche Yandex.
Méthodes de travail du moteur de recherche Yandex
Le moteur de recherche Yandex contient dans son index sur chaque mot du numéro de texte du document, des suggestions, des mots de la proposition et du poids de chaque mot. La recherche Robot Yandex Index Les pages et sur la base d'informations sur eux forment un indice de recherche.
Toutes ces informations sont utilisées lors de la recherche. Chaque demande est recherchée (et obtenez des classements plus haut), coïncidant exactement avec la demande, puis des suggestions contenant tous les mots de la demande, etc. Un rôle important est joué par la position relative des mots. Par exemple, si une demande de quatre mots n'a pas de réponse précise dans la base de données, les phrases ci-dessus contenant trois mots de la requête dans laquelle les mots se tiennent exactement dans la même séquence que dans la demande. Cela permet de résoudre une tâche de recherche typique - de rechercher un document sur "Citation inexacte".
Rambler des moteurs de recherche.
Historique du moteur de recherche Rambler
L'histoire du moteur de recherche "Rambler" commence en 1991 dans la ville de Pushchino dans la région de Moscou. C'était là que le groupe de personnes "pile" a été créée. Il a dirigé la société "Stack" Sergey Lysakov. Engagé dans l'entreprise réseaux locaux et se connecter à Internet.
Déjà en 1996, Sergey Lysakov et le programmeur Dmitry Kryukov ont décidé de développer le premier moteur de recherche russe pour Internet. Dmitry Kryukov est proposé le nom du projet - Rambler. Dans la traduction, Rambler signifie "Skitalets, Wanderer, Traging", qui est consonant avec le principe du robot du moteur de recherche.
Le 26 septembre 2006, le domaine Rambler.ru a été enregistré et déjà le 8 octobre, la Stack Société a activé le système. Au printemps 1997, "Rambler" top100 "apparaît - un classificateur de notation qui estime la popularité des ressources russes basées sur des données objectives.
En juin 2003, la société a lancé la société nouvelle version Un moteur de recherche, qui diffère de la précédente par deux paramètres principaux: a considérablement augmenté la vitesse de la recherche grâce à la nouvelle architecture de la mise à jour du système L'index de recherche se produit plusieurs fois par jour.
Pour ceux qui savent exactement ce qui cherche, et ne veut pas passer du temps supplémentaire, une version spéciale concise de la recherche "Rambler" a été ouverte à R0.ru (ou, comme on dit, Arnold).
Mécanisme des associations de Rambler
Lorsque quelqu'un effectue un certain nombre de demandes consécutives dans le moteur de recherche, ces mots et expressions sont interconnectés par les associations de Rambler. Les moteurs de recherche Rambler sont disponibles pour les associations de Rambler. Association Rambler. - Celles-ci sont des demandes connexes thématiquement (associatives) avec la demande source de l'utilisateur. Lorsque quelqu'un effectue plusieurs demandes consécutives dans le moteur de recherche Rambler, ces mots et phrases deviennent interconnectés. Et cette séquence crée la Rambler Association. En fait, c'est un concept "Nous recherchons également".
D'une part, à l'aide du mécanisme d'association Rambler, l'utilisateur peut rapidement clarifier ou développer sa demande. D'autre part, la chaîne d'associations typiques identifie les lacunes de la demande initiale, son ambiguïté, "flou". En conséquence, le visiteur du moteur de recherche Rambler apprend à demander correctement sans perdre de temps, c'est-à-dire que, en fait, a recours à l'aide de l'esprit "collectif".
Le mécanisme des associations "Nous recherchons également" intéressant pour quiconque veut voir quels milliers de visiteurs pensent. Ceci est un outil de recherche, ainsi qu'une source d'informations précieuses pour les linguistes et les maîtres Web.
Gestion de l'indexation dans le moteur de recherche Rambler
Limiter l'indexation des ressources de la page de ressources par le système de recherche Rambler peut être via robots.txt ou méta-tag "robots". Pour le moteur de recherche, le moteur Rambler s'appelle "Stackrambler". C'est lui qui télécharge les documents émis sur Internet, trouve des liens vers d'autres documents, des téléchargements à nouveau, etc. Le robot Stackrambler analyse le fichier robots.txt et limite la numérisation de ressources, en fonction de ses instructions. Grâce à robots.txt, vous pouvez interdire l'accès à des répertoires et / ou des fichiers spécifiques.
Limiter la numérisation des pages de ressources par le robot de moteur de recherche de Rambler est également possible via les "robots" de Meta Tag. La balise gère l'indexation d'une page Web spécifique. Dans le même temps, des robots peuvent être interdits non seulement l'indexation du document lui-même, mais également le passage selon les liens de celui-ci.
Ajouter des pages dans le moteur de recherche Rambler
Le robot de Rambler se contournez sur les liens et trouve donc de nouvelles ressources. Vous pouvez remplir le questionnaire d'inscription. Le robot de Rambler visit de manière indépendante des sites situés dans les domaines nationaux.ru, .su, .ua, .by, .kz, .kg, .uz, .ge. Si le site est situé dans l'une des autres zones de domaine (par exemple, v.com, .NET ou.org ou dans d'autres domaines nationaux), les robots par défaut de Rambler n'assistent pas aux pages de ces ressources. Pour ajouter des ressources d'intérêts aux utilisateurs de langue russe, au nombre de numérisés, il est nécessaire de contacter l'administrateur du moteur de recherche de Rambler.
Le robot de Rambler se contournez les liens sur les liens et trouve ainsi de nouvelles ressources pour l'indexation. Vous pouvez également remplir le formulaire d'inscription dans le moteur de recherche Rambler. Les champs de ce questionnaire - "Nom du site" et "Description" ne sont pas utilisés pour rechercher. Ils sont destinés uniquement à lire par les éditeurs et sont utilisés dans les bases de données Rambler internes.
Le robot scanne les pages du site dans les 24 heures à compter du moment de l'enregistrement (ou trouvant la ressource). Dans le même temps, il contourne immédiatement le site pendant une certaine profondeur (scanne les pages référencées par la page enregistrée). Les pages téléchargées par le robot apparaissent dans la base de recherche avec un certain délai. Le réindexage des documents reçus est effectué à un intervalle d'environ deux semaines.
Indexation dans le moteur de recherche Rambler
Lors de l'indexation du moteur de recherche, la Rambler prend uniquement en compte les informations que l'utilisateur peut voir sur la page. Les concepts de base et les mots-clés du site du mot sont souhaitants pour inclure dans les balises HTML suivantes (de l'ordre de l'importance): titre H1 ... H4 B, Strong, u. Plus le mot est trouvé dans ces champs, Plus le moteur de recherche Rambler donnera une référence à ce document est plus proche du sommet de la liste des résultats de la recherche.
La taille maximale du document pour Robots Rambler est de 200 kilo-octets. Les documents plus importants sont tronqués à la valeur spécifiée.
Le programme d'indexation traite (redirections), mais uniquement si la redirection est effectuée dans le domaine.RU ou dans les domaines de certains pays de la CEI.
Rambler traite toutes les pages "dynamiques" avec les noms du type * .asp *, * .php *, * .pl *, * / cgi-bin / *, etc., pour les sites visités (selon TOP100), ainsi que en tant que sites contenant des informations uniques utilisateurs utiles Moteur de recherche. Pour d'autres sites, seule une partie de ces pages est traitée.
Fragments HTML marqués d'étiquettes, les rambler ne sont pas indexés.
Le moteur de recherche Rambler sait comment récupérer des liens à partir d'objets flash et peut donc gérer les sites construits sur des technologies Flash. Cependant, les textes des objets flash ne sont pas encore indexés.
Lors de l'indexation, seules les informations que l'utilisateur peuvent voir sur la page sont prises en compte.
Champs cachés et tous les autres champs sauf lorsque des sites d'indexation sont ignorés. La même chose s'applique aux commentaires du site de code HTML. Vous devez également utiliser un texte invisible dans lequel la couleur de la police coïncide avec la couleur d'arrière-plan.
La recherche prend en compte les données TOP100. Le robot spécial de Rambler deux fois par jour ajoute de nouvelles pages de tous les sites à la base des moteurs de recherche, qui sont impliquées dans la top100 et ont publié un compteur sur leurs pages. Après avoir modifié les informations dans la notation TOP100, sa mise à jour dans le moteur de recherche se produit dans un délai d'un ou deux jours. Si le site est enregistré dans la top100, il figurera sur certaines demandes, même si les informations ont été supprimées de la base d'index.
Lors de la recherche, les informations reçues de la Rambler Note S TOP100 sont prises en compte si le site est enregistré. Le numéro indique lorsque ces informations ont été reçues. Des informations sur le TOP100 sont mises à jour presque tous les jours.
Système de recherche APORT
HISTORIQUE DE L'APORT DE MOTEUR DE RECHERCHE
La présentation officielle "APORT" a eu lieu le 11 novembre 1997. À ce moment-là, les premiers millions de documents situés sur 10 000 serveurs étaient indexés dans sa base. Le créateur du système de recherche de l'APORT est la société "AGAM" - Développeur de logiciels pour les plates-formes Windows. Il convient de noter que l'APORT a été créé et continue de travailler sous Windows OS (par opposition à la plupart des moteurs de recherche). Développements linguistiques "Agamas" ont été utilisés lors de la création d'un moteur de recherche pour AFT, dans lequel au moment de sa création, la morphologie des mots a été prise en compte et à la demande du client, l'orthographe du sort de requête a été réalisée.
Pour la première fois, le moteur de recherche "APORT" a été démontré en février 1996 à la conférence de presse Agama sur l'ouverture du club russe. Initialement, le système de recherche de l'aport effectué uniquement sur le site Russie.agama.com.
La présentation officielle du moteur de recherche "APORT" n'a eu lieu que le 11 novembre 1997. À ce moment-là, les premiers millions de documents situés sur 10 000 serveurs ont été indexés dans la base de données.
Les caractéristiques les plus importantes de la première version de "APORT" ont été la traduction des résultats de la demande et de la recherche en anglais et en arrière, ainsi que la reconstruction de toutes les pages opposées de sa propre base.
En novembre 1998, le moteur de recherche "APORT" a été acquis par un citoyen d'Israël avec Joseph Avchuk (avec la préservation des marques de commerce APORT et AGAMA). Le montant réel de la transaction était de 55 000 dollars.
En octobre 1999, un moteur de recherche fondamentalement nouveau "APORT 2000" a été présenté sur des expositions informatiques des deux côtés de l'océan, entièrement intégré à Atrus (maintenant "APORTAL-APORT").
"APORT 2000" est devenu le premier moteur de recherche russe construit sur la base des résultats émetteurs par des sites distincts. Pour scinder des ressources sur des sites, les informations que le catalogue ATRUS ou les informations saisies dans les propriétaires de ressources «APORT» sont utilisées pour partager.
"APORT 2000" est devenu le premier moteur de recherche russe, qui a réalisé deux technologies de base du moteur de recherche Google American. Comptabilité "Classement de la page" (Classement de la page), qui caractérise sa popularité. La valeur du rang est calculée par le nombre de références à la ressource de l'Internet externe. Le poids des liens du site populaire est supérieur au poids des références avec un moins populaire; Les références qui incluent des mots de demande ont plus de poids que, par exemple, le mot "ici". Demande de traitement avec analyse HTML TAGOV pages. Par exemple, le texte entre les balises H2 a une plus grande priorité que les étiquettes H6.
L'APORT 2000 "a également pris en compte l'entrée de la demande de mots dans l'URL. Parmi les caractéristiques non documentées, il est une plus grande priorité aux sites qui ont reçu les lieues les plus élevées et les ligues élites dans le répertoire Atrus.
Et, enfin, un autre championnat tiers - l'utilisation d'une ligne zéro payée dans l'extradition (d'ailleurs, le "APORT" d'abord de nos moteurs de recherche a commencé à acheter un tel service d'Altavista, qui, pour un petit supplément, a donné son Link d'abord lors de la demande de "recherche russe"). Cependant, dans le "APORT" ne peut être acheté pas à zéro, mais juste une place supérieure pour votre site dans les résultats de la recherche.
L'organisation de l'évolutivité de l'architecture "APORT 2000" est telle qu'elle est possible d'écraser la base de recherche de "APORT" dans plusieurs bases séparées, chaque petite "Ariat" fonctionne sur son ordinateur. "APORT 2000" estime que l'intégralité de l'Internet est divisée en fragments. Après avoir recherché ces fragments, l'utilisateur s'intègre et reçoit une réponse courante. Ajouter de nouveaux petits "élèves" ne peut être pas une procédure très difficile. En cas d'accident de machines individuelles, plusieurs résultats intégrés différents sont émis, ce qui peut être observé de temps à autre.
Le 31 juillet 2000, Golden Telecom a acheté une famille de projets Internet "Agama", y compris "APORT" et ATRUS, à inclure dans les projets en Russie et à proximité de thétopitations.
En mai 2001, la transaction a finalement été achevée sur le changement de "APORT" "Golden Telecom", "Alpha Bank" est devenu le nouveau propriétaire. NASDAQ À cette époque inquiet Un déclin orageux et des chances de revendre des projets Internet pour une quantité acceptable n'était pas. Cela a conduit à la décision des nouveaux propriétaires de "Golden Telecom" de minimiser les dépenses de soutien à des projets Internet coûteux.
Gestion de l'indexation dans le moteur de recherche de l'APORT
Lors de la visualisation du contenu du serveur pour indexer l'APORT, vérifie le fichier robots.txt et prend en charge les robots Meta Tags. Lors de la visualisation du contenu du serveur pour indexer l'APORT checks le fichier robots.txt. Ainsi, vous pouvez limiter «l'activité» de l'APPORT sur le serveur. Rechercher Robot APort a le nom APORT. Ce nom peut être utilisé pour limiter l'indexation via robots.txt.
En outre, le moteur de recherche de l'APORT est pris en charge par des robots META-TAGS, permettant, définir les règles du comportement du robot sur la page individuelle du site et au cas où il n'est pas possible de modifier le fichier robots.txt sur le serveur.
Ajout de pages dans le moteur de recherche de l'APORT
L'enregistrement du site dans l'intermédiaire est fabriqué à partir de la page Ajouter une URL. Ajouter seulement la racine du site. L'enregistrement du site dans l'autre est fabriqué à partir de la page http://catalog.aport.ru/rus/reg/Add.pente. Cette page est disponible sur le lien Ajouter URL presque de n'importe quelle page de l'APORT. Seule la racine du site doit être ajoutée, le reste des pages sera trouvé par l'exportation par les liens.
APORT est un moteur de recherche sur l'Internet russe, vous pouvez donc ajouter des sites russophones, ainsi que des sites directement liés à l'Internet russe. En cas de refus d'ajouter automatiquement un site (par exemple, si le robot de recherche ne trouve pas sur sa page racine du texte russophone), vous pouvez contacter le site d'ajout par e-mail: [Email protégé]
Indexation du système de recherche de ressources de l'APORT
APORT est un moteur de recherche en texte intégral. Cela signifie qu'il indexe tous les mots qu'une personne a vu sur l'écran en regardant via une page de serveur spécifique. APORT Vérifie périodiquement les sites disponibles dans sa base de données et conduit sa base conformément aux changements survenus. La période de vérification dépend en grande partie du site spécifique (sa popularité est prise en compte, le dynamisme de la mise à jour en fonction des données collectées par l'agent aux attitudes précédentes sur le site et un certain nombre d'autres facteurs).
Dès le moment de l'ajout d'un site au système de recherche de l'APort jusqu'à ce que son apparition dans la base de recherche passe de deux à trois jours à deux semaines. Dans certains cas, (par exemple, en cas de connexion instable avec le site ajouté), cette fois peut être un peu plus grand.
APORT Index Tous les documents statiques (dans l'URL dont le symbole "?"), L'a trouvé recherche robot Aussi des liens sur le site. Cette règle ne peut être observée pour une grande sur le volume de sites, ainsi que pour les sites observés dans l'application du spam de recherche.
Les documents contenant dans le symbole de l'URL "?" Sont indexés par le système de recherche de l'APORT SELECTIVE. Dans ce cas, la citation du nombre de ces documents pour chaque site est utilisée. La taille du quota est automatiquement calculée en fonction d'un certain nombre de conditions, en particulier de l'indice de citation de site, et peut notamment être nulle pour certains sites.
Il convient de garder à l'esprit que l'indexation complète du site peut se produire progressivement, ainsi que le fait que le contenu de la base est la prérogative du moteur de recherche et des garanties sur l'indexation (ainsi que la préservation de l'indice de déjà. Les documents indexés) ne donnent pas un APORT.
APORT est un moteur de recherche en texte intégral. Cela signifie qu'il indexe tous les mots qu'une personne a vu sur l'écran en regardant via une page de serveur spécifique. En conséquence, tout mot du texte des documents peut servir de critère de la recherche ultérieure.
Pour documents HTML En plus du texte principal du document, l'en-tête de document (titre), les mots-clés (META Mots-clés), les descriptions de page (méta description) et les signatures d'images (ALT) sont indexées. De plus, les index d'APORT appartenant au document, les textes de liens hypertextes dans ce document à partir d'autres pages situées, à la fois dans le site et au-delà, ainsi que des éditeurs compilés (ou éprouvés) de la description des sites à partir du catalogue APORT.
Moteur de recherche Google
Ce moteur de recherche au fil du temps devient de plus en plus de plus en plus populaire, mais il est inférieur aux moteurs de recherche ci-dessus. Selon les sondages, données Google Fournit environ 10% de toutes les requêtes de recherche de Runet. Sur le enregistrement de Google Prend des sites de n'importe quel domaine, c'est-à-dire qu'il ne se limite pas à la zone de Ru. C'est certainement un très grand avantage sur les concurrents (en Russie). Mais Google n'a plus d'avantages et ne peut même pas émettre de mots dans les résultats de la recherche synonymes de la requête. C'est-à-dire que si nous demandons à Google requête de recherche "Anecdote", puis Google recherchera sur les sites ce mot, tandis que Yandex, Rambler et APort, en plus de ce mot, prendront en compte sur les sites et les mots synonymes, par exemple, "blagues", et le Google ne peut pas faire cela. .
Moteurs de recherche étrangère
- Aol recherche
- Achla
- Altavista.
- Altavista (numérique)
- Autriche NetGuide.
- Austronaute
- ALLTHEREWEB.
- Antisearch.
- Demandez à Jeeves.
- Askalex.
- Anzwers
- Ausindex.
- Autriche www.
- Pages Baku.
- Index Brit
- Compnet.
- Copernic.
- Cyber411
- Coup direct.
- Daypop.com.
- Exciter
- Angleterre en ligne
- Freeality.
- Recherche FTP
- GBP Great Pages britanniques
- Hotbot.
- Handilinks.
- Infoseek.
- Infomarket.
- Info
- Intersearch Autriche.
- Entrevue
- Inktomi.
- Inforia.
- Guide.at.
- L'air intelligent.
- Lycos.
- Recherche de lumière.
- Libanis.com.
- Magellan.
- Maxoisearch.
- Recherche msn
- Mixcat.com.
- Meta-ukraine.com.
- Métacrawler.
- Lumière du nord
- Netscape Search.
- Ouvrir le répertoire.
- Texte ouvert.
- Qango.
- Ragage de recherche.
- Nom de réalité.
- Search.com.
- Sachuk.
- Search.lv
- Search.iwon.com.
- Soumetter.bentral.com.
- Superpromo.com.
- Search.escapeartistist.com.
- Surfgopher.com.
- Slider.com.
- Indice britannique
- UKDirectory.
- Ukmax
- WhaneSeek.com.
- Webcrawler.
- Webbat web.
- Yahoo.
- 2kcity.com.
Architecture des systèmes de métapoik
introduction
Dans cet article, sur l'exemple d'un système de métapoisisk, le métaping considère l'architecture des systèmes de métapoiques et des principes de base de leur travail et de leur construction.
Qu'est-ce qu'un système de métapoisisk?
Ce n'est plus secret que le réseau Internet mondial contenant l'énorme quantité d'informations modifiant de manière dynamique développe un rythme rapide sans précédent. Afin de rationaliser en quelque sorte ce flux de données continu, et la chose la plus importante est de permettre aux utilisateurs du réseau de trouver les informations nécessaires, des moteurs de recherche spéciaux ont été créés. Chacun de ces systèmes dispose d'informations de service d'indexation sur le contenu des documents indexés, où chaque mot du texte correspond à la fréquence de son utilisation et les coordonnées de ce mot dans le texte.
Chaque moteur de recherche n'a que ses propres ressources limitées, beaucoup de documents disponibles à la recherche. Aucun de ces systèmes ne pourra couvrir toutes les ressources Internet. Ainsi, à tout moment, il peut y avoir une situation dans laquelle les besoins de l'information de l'utilisateur ne peuvent pas être satisfaits. En règle générale, dans ce cas, l'utilisateur va à un autre moteur de recherche et essaie de rechercher ce dont il avait besoin là-bas.
Pour résoudre ce problème et développer les capacités de recherche, les systèmes appelés METAPOISK ont été créés. Ils n'ont pas leur propre base de recherche Les données ne contiennent aucun index et lors de la recherche d'une utilisation des ressources de plusieurs moteurs de recherche. En raison de cela, l'exhaustivité de la recherche dans ces systèmes est le maximum et la probabilité de trouver information nécessaire Très haut.
Principes de fonctionnement des systèmes de métapoiques
Lors de la conception d'un système de métapoisisk, un certain nombre de problèmes devraient être résolus.
Tout d'abord, à partir de la multitude de documents reçus des moteurs de recherche, il est nécessaire de mettre en évidence le plus pertinent, c'est-à-dire la demande utilisateur correspondante. En règle générale, les créateurs de METAPOISK SYSTEMS ne sont pas entièrement justifiés que les moteurs de recherche qu'ils utilisent renvoient les résultats de recherche pertinents et s'appuient trop sur la position à laquelle un document est dans ce moteur de recherche.
Cette approche standard est présentée à la Fig. 1. Dans de tels systèmes, l'analyse des descriptions obtenues des documents n'est pas faite, ce qui peut mettre des documents non pertinents allant d'abord dans un moteur de recherche, ci-dessus pour un autre, plus la qualité de la recherche elle-même. Ce principe s'est avéré être bon lors de la création d'un analyseur de position d'un site dans les moteurs de recherche, mais en général, les systèmes de métaporation n'étaient pas satisfaisants.
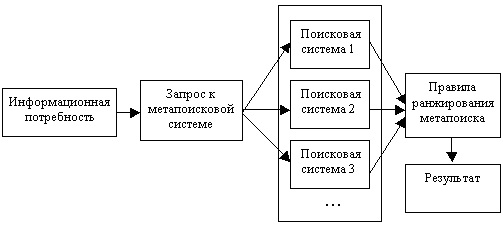
Fig.1 Système de métapoik standard
Lors de l'élaboration de la prochaine génération de systèmes de métapoiques, des inconvénients inhérents aux systèmes de métapoiques standard ont été pris en compte. Les systèmes ont été créés avec la possibilité de choisir ces moteurs de recherche, dans lesquels, selon l'utilisateur, il est plus susceptible de trouver ce qu'il a besoin (Fig. 2)
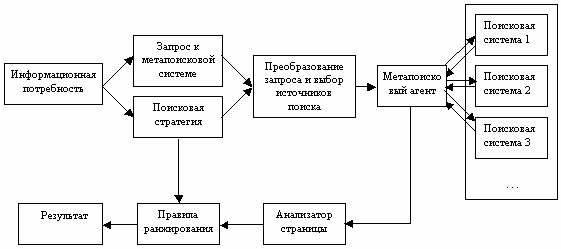
Figure. 2. Next génération de systèmes de métapoik
De plus, cette approche vous permet de réduire les ressources informatiques de MetaPOISK Server utilisées, sans surcharger avec trop d'informations inutiles et de trafic sérieusement enregistré. Il convient de noter ici que, dans n'importe quel système méta-papier, l'endroit le plus étroit est principalement la bande passante du canal de données, depuis le traitement des pages avec les résultats de la recherche obtenus à partir de plusieurs dizaines de dizaines. serveurs de recherche L'opération n'est pas trop laborieuse, car le temps passé à traiter des informations sur la commande est inférieur à la date d'arrivée des pages demandées à partir de serveurs de recherche.
À titre d'exemple de systèmes ayant une organisation similaire, vous pouvez appeler Profusion, Ixquick, Savvysearch, Mettabiling.
Comment tout cela fonctionne-t-il?
Le principe de fonctionnement du système de métapoisisk Mettabiling développé par l'auteur de cet article sera décrit, mais des principes généraux seront vrais pour d'autres systèmes de cette classe (voir Fig. 2).
Commençons par la page de démarrage de ce système de métapoisisk. Habituellement, l'interface d'un tel système est extrêmement simplifiée et permet immédiatement de comprendre quoi, où et comment puis-je rechercher ici. Dans notre cas (METAPING), la recherche est possible dans trois domaines de recherche: en Russie, en Ukraine et dans le monde entier, il a la possibilité de rechercher tout, en notant la recherche sur Internet ou de réduire la zone de recherche et recherchez Annonces spécifiques, nouvelles, fichiers et résumés (Fig. 3).
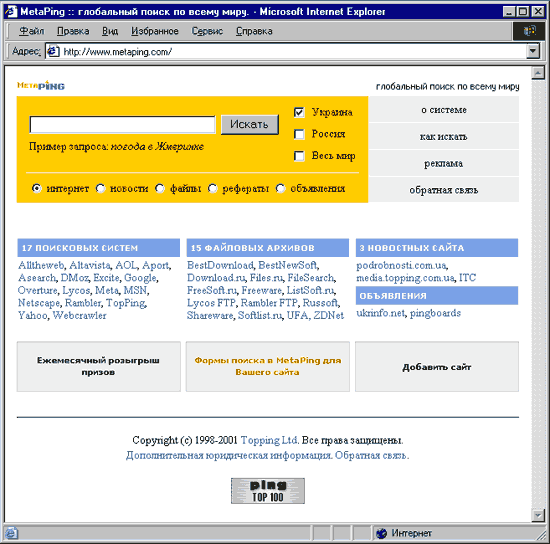
FIGUE 3. page de démarrage METAPING.
L'utilisateur choisit, disons, rechercher en Russie et entre, par exemple, une telle demande: "Les meilleurs moteurs de recherche" (fig. 4).
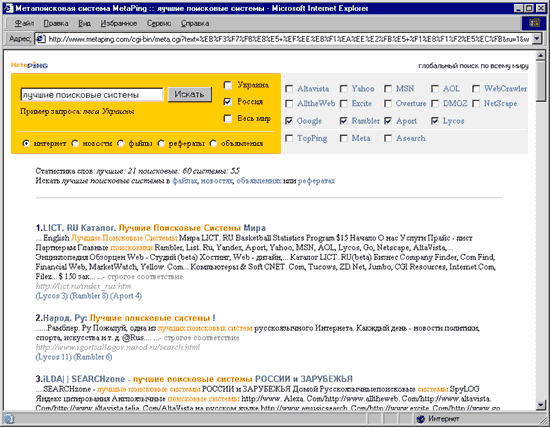
Figure. 4 Page de métaponnage avec Résultats de la recherche
Après cela, la demande est relayée par les moteurs de recherche russe spécifiés (dans notre cas, Rambler, APORT, LYCOS et Google). Il convient de noter que Google, bien que ce ne soit pas un moteur de recherche russe, est actuellement en concurrence avec succès avec eux à la fois par la plénitude des bases de données et la qualité de la recherche, et c'est pourquoi il était ici. À propos, le lecteur attentionné a probablement noté l'absence du plus grand système de recherche russe Yandex. Au moment du lancement, les métapeurs Yandex ont également assisté ici, mais après le célèbre scandale, il devait être enlevé.
Pour transmettre un système de recherche, un agent de métapoisisk spécial est utilisé, qui répond non seulement au processus de retransmission et aux pages de réception, mais également à la demande à transmettre dans le codage correct adopté dans chacun des moteurs de recherche sélectionnés, sinon un autre ensemble sera Recevez des descriptions de document ou ne sera pas obtenue du tout, ce qui affectera négativement la recherche comme recherche.
Après traitement de la requête reçue, chaque système renvoie une description multiple et des liens vers l'agent METAPOISK, qui estime pertinent pour cette demande.
Comment parmi cet ensemble de choisir exactement ce qui est nécessaire à l'utilisateur?
Au début de cet article, une approche standard a déjà été mentionnée, qui est utilisée par la plupart des systèmes méta-papier et consiste simplement à organiser les références reçues dans l'ordre de leur suivant dans les résultats de recherche de chacun des moteurs de recherche. Dans le même temps, si le même site a été trouvé dans différents moteurs de recherche, sa valeur pour l'utilisateur, naturellement, est considérablement augmentée.
L'approche est définitivement correcte, mais que faire si un système, par exemple, indexe des pages générées de manière dynamique, et l'autre n'est pas? Ils ont des ensembles différents de documents indexés, diverses données de base de données, par conséquent, les informations demandées par l'utilisateur peuvent être trouvées dans le même système et peuvent ne pas être trouvées dans une autre. Dans ce cas, l'utilisateur peut obtenir plusieurs références véritablement pertinentes à partir d'un système, qui sera mélangée avec absolument non pertinente d'une autre (par exemple, dans le cas où la phrase n'est pas complètement trouvée, la recherche va une des mots-clés du mot-clé). En conséquence, l'utilisateur doit sélectionner manuellement des références pertinentes et la probabilité de ce qui se propage dans une telle "vigrette", il part tout simplement et ne reviendra jamais.
Y a-t-il un moyen de résoudre ce problème? Bien sûr avoir. Il est nécessaire d'obtenir une multitude de descriptions de documents obtenues à partir de moteurs de recherche pour faire la même chose avec ces documents, c'est-à-dire pour déterminer les fréquences de mots-clés dans chaque titre et une description et essayer de déterminer de manière indépendante la note de chacun d'entre eux. .
C'est pour ce principe qu'un réseau de métapoik a été construit, où un algorithme mixte d'informations de traitement a été mis en œuvre. L'auteur a été développé programmes spéciaux Pour analyser les données obtenues, en raison de laquelle dans la première étape, un ensemble de descriptions des documents reçus est classée, au second, le rang est également ajusté en fonction du lieu où le document est situé et le nombre total de documents trouvé sur demande (cela permet d'évaluer l'exhaustivité des bases de recherche d'un système particulier).
Ce traitement permet non seulement de supprimer les documents, dans la description de laquelle il n'y a pas de mots-clés comme une requête potentiellement non pertinente, mais trouve également une correspondance stricte si tous les mots-clés sont trouvés dans la description du document complètement, ce qui améliore de manière inutile la qualité et précision de la recherche.
Quête inféroienne 98 et Métapoik Copernic 98
 Quête inféroienne 98 (IQ - Abréviation réussie, est-ce?). Produit d'Infoorian, le fruit des efforts collectifs des programmeurs japonais, chinois et américains.
Quête inféroienne 98 (IQ - Abréviation réussie, est-ce?). Produit d'Infoorian, le fruit des efforts collectifs des programmeurs japonais, chinois et américains.
Poids d'environ 3,5 Mo, nécessite jusqu'à 5 Mo libres espace disque. Coût version complète 25 dollars américains, shareware - 1 mois.
Utilise deux styles: essence, pour les utilisateurs expérimentés et l'assistant, pour les débutants. Les deux styles se distinguent par une simplicité d'urgence. Infoorian Quest 98 vous permet d'effectuer un métapoik rapide pour sept serveurs les plus populaires (Yahoo!, Altavista, Infoseek, Excite, Hotbot, OpenText, Webcrawler), Contact A plus de 200 serveurs consultables d'Amérique, Europe, Japon et Chine, ainsi qu'une Enquête au sein de ces bases de données Données pour sept sections thématiques Art and Entertainment (Arts et divertissements), Actualités et entreprises (Actualités et entreprises), Ordinateurs et Internet (Logiciels et FTP), groupes de discussion (Usenet (groupe de discussion)), Technologies scientifiques (technologie) , adresses et numéros de téléphone (pages jaunes). Il y a de l'espoir d'inclusion dans un proche avenir dans la liste des serveurs "recherchés" des clients israéliens et russes.
En fonction du degré de votre souffrance longue, il est recommandé de configurer le temps d'attente (attendre ...) émettant des résultats de recherche (minimum - 1 seconde, maximum - presque 4 mois, recommandé - 1-2 minutes) et spécifier le Nombre maximum de messages de chaque site trouvé (liens par site) (par défaut, 10). Si vous souhaitez recevoir des informations extrêmement fraîches et êtes prêt pour cela un peu de sacrifice de la vitesse de recherche, - refuse d'utiliser le serveur proxy. Si vous le souhaitez, vous pouvez facilement modifier la langue de l'interface de l'anglais en allemand, en français ou en espagnol, si votre ordinateur est non seulement assemblé, mais également commencé avec le logiciel d'artre-Eastern Arcasemen, vous pouvez essayer une interface japonaise ou chinoise. Il frappe une "pointe" superbement exécutée, allez à laquelle vous pouvez en cliquant sur le clavier la touche F1 ou par l'aide -\u003e Aide Script Script.
 Pas moins populaire aujourd'hui et Copernic 98 est un système de métapoisisk de ATC (Agents Technologies Corporation). Le principal avantage du programme est le manque de besoin de payer pour la version principale, le temps d'utilisation n'est pas limité. Ce programme Supérieur à son concurrent aussi facilement (environ 2,5 Mo) et le volume du répondant dans la recherche d'espace d'information. Le noyau des serveurs de recherche principaux est ajouté, comparé au concurrent, NetFind, LookMart, Lycos, Magellan, bien que OpenText très prometteur oublié. Il est à noter que la recherche d'un de vos amis du réseau à l'aide de Copernic, vous utilisez non seulement les ressources du traditionnel qui, où ?, Bigfoot, Four11, mais aussi le "héros de la saison actuelle", Mirabilis. Le répertoire thématique contenant environ 20 sections et une accumulation d'informations sur 100 moteurs de recherche peut être utilisé si vous avez choisi la version de "Plus" (30 jours gratuitement, payez 30 $). À ce jour, le développement est le kit de développement de canaux, qui vous permettra d'ajouter de manière indépendante n'importe quel moteur de recherche à la liste. Si en même temps, Copernic ne comptera pas erroné phrase de recherche En russe ou en hébreu, il y a une popularité considérable dans notre pays.
Pas moins populaire aujourd'hui et Copernic 98 est un système de métapoisisk de ATC (Agents Technologies Corporation). Le principal avantage du programme est le manque de besoin de payer pour la version principale, le temps d'utilisation n'est pas limité. Ce programme Supérieur à son concurrent aussi facilement (environ 2,5 Mo) et le volume du répondant dans la recherche d'espace d'information. Le noyau des serveurs de recherche principaux est ajouté, comparé au concurrent, NetFind, LookMart, Lycos, Magellan, bien que OpenText très prometteur oublié. Il est à noter que la recherche d'un de vos amis du réseau à l'aide de Copernic, vous utilisez non seulement les ressources du traditionnel qui, où ?, Bigfoot, Four11, mais aussi le "héros de la saison actuelle", Mirabilis. Le répertoire thématique contenant environ 20 sections et une accumulation d'informations sur 100 moteurs de recherche peut être utilisé si vous avez choisi la version de "Plus" (30 jours gratuitement, payez 30 $). À ce jour, le développement est le kit de développement de canaux, qui vous permettra d'ajouter de manière indépendante n'importe quel moteur de recherche à la liste. Si en même temps, Copernic ne comptera pas erroné phrase de recherche En russe ou en hébreu, il y a une popularité considérable dans notre pays.
Avec chaque opération de recherche, vous pouvez modifier les valeurs maximales du nombre total de résultats de recherche et le nombre de messages dans un canal de recherche séparé (Recherche -\u003e Nouveau -\u003e Paramètres -\u003e Recherche personnalisée). Vous pouvez vous connecter au travail du serveur proxy (vue -\u003e Options -\u003e Connexion -\u003e Proxies).
Il y a plus de mille ans, les Saints Cyril et Methodius ont fait une erreur stratégique en prenant la base des lettres grecques comme base de l'alphabet russe. L'une des conséquences les plus frappantes est la nécessité de perdre du temps sur la commutation du registre du clavier - il y a quelques décennies, lorsque des ordinateurs ont été inventés. Un autre, beaucoup moins important, est la nécessité d'écrire un chapitre distinct sur la recherche de documents en langue russe.
Essayons d'en apprendre davantage sur l'origine de l'écriture russe, cette fois par le moteur de recherche Rambler. Dans la section "Notes" des chapitres 1, nous avons déjà parlé de Rambler parmi le classement des sites russes. Dans cette section, il conviendra de dire que Rambler - non seulement et pas seulement d'une note d'index automatique, à peu près la même chose que APORT. En effet, sur la page Rambler principale au début, il existe un champ de recherche et trouvez le bouton de recherche! Envoyer une demande.
Pour trouver des documents, où il raconte la création d'écriture russe, il est raisonnable d'introduire dans le domaine de la recherche du mot "histoire", "russe", "écrit", entourez les mots entrés avec des citations pour demander la recherche de phrase, et cliquez sur le bouton Trouver! Fragment de résultats de recherche.
Comme vous pouvez le constater, le premier document (hors du 234 trouvé), à en juger par sa tête, ainsi que le début, montré par Rambler, la date du dernier changement (18 mai 2005) et la taille (150 Ko) répond pleinement à nos attentes. Peut-être que les 233 pages restants parlent d'écriture russe. Mais s'agit-il des documents? Quelque chose d'important n'est-il pas important? Pour répondre correctement à ces questions, vous devez connaître la langue des demandes de randonnées.
Bien que nous sachions que Rambler recherche une phrase lorsque des mots dans le champ de recherche sont encadrés par des citations. Il est important de comprendre que les mots constituant la phrase, des feuilles de randonnées inchangées inchangées. Rambler trouvera des documents contenant la phrase "Histoire de l'écriture russe", mais ne trouvera pas la phrase "Histoire de l'écriture russe". Pour trouver toutes les formes grammaticales de mots, il est nécessaire de les libérer des citations, introduisant dans le champ de recherche "Kirill", "Methodius", "Russe", "Rédaction".
Pour une telle demande, Rambler trouve déjà 4229 sites et plus de 34 000 documents. Fragment de résultats de recherche. Comme vous pouvez le constater, Rambler a alloué les mots "russe" "," écrivant "par les mots", c'est-à-dire qu'il n'y a pas de différence entre les mots "russe" et "russe", toutes les formes grammaticales sont considérées comme un mot. Mais il vaut la peine d'entrer dans le mot dans des citations et Rambler examinera exactement ce qui est indiqué. Selon la demande suivante, des documents seront trouvés, où il existe des mots "russe", "écriture" et toutes formes grammaticales des mots "Cyril" (par exemple, Kirill) et méthode:
Kirill méthodius "russe" "écrit"

Par défaut, Rambler recherche des documents où il y a tous les mots séparés par des espaces. Mais presque tous les moteurs de recherche modernes essaient de deviner ce que le demandeur voulait dire, il est donc préférable d'indiquer explicitement la randonneuse qu'il devrait faire. Si vous avez besoin de trouver tous les mots, il existe un opérateur logique entre eux. Selon la demande suivante, des documents seront trouvés, où il y a à la fois des mots (y compris leur variabilité):
Kirill et méthode
Mais si vous avez besoin de trouver un des mots, utilisez l'opérateur ou l'opérateur, par exemple:
(écrire ou alphabet ou abc) et russe et "cyril" et "méthodius"
Cette demande signifie que les pages sont recherchées, où vous devez avoir les mots "Cyril", "méthodiodius", une des formes grammaticales du mot "russe" et l'un des mots: "écrire", "alphabet", "ABC "(Prendre en compte leur variabilité grammaticale). Dans le dernier exemple, les mots "cyril" et "méthodius" sont écrits avec lettres de couléeParce que Rambler est toujours avant de faire référence à son index, tourne lettres majuscules Dans les minuscules.
En plus de et ou des opérateurs de Rambler, il existe toujours un opérateur qui vous permet de trouver des documents où il n'y a pas de mot spécifié (phrase). Sur la demande suivante, des pages seront trouvées, où il existe des mots "historique", "russe", "écriture" (en tenant compte de leur variabilité grammaticale), mais aucun mot "cyril": histoire et russe et écrit non cyril
Utilisation de l'opérateur non, vous pouvez effectuer des demandes très difficiles, par exemple: historique et russe et écrire non (Cyril ou Méthode)
Cette demande de demande de recherche de rechercher des pages dans lesquelles les trois mots sont connectés par l'opérateur et, et il n'y a pas un mot "Cyril" ou les mots "Méthode". Cela peut être compris en utilisant une telle demande de moteur de recherche:
Kirill ou méthode
Dans ce cas, des documents seraient trouvés, où il y a le mot "Cyril", soit le mot "méthodiodius", soit ces deux mots. De toute évidence, tous les documents indexés par le moteur de recherche peuvent être divisés en deux parties: le premier correspond à la demande de Kirill ou de la méthode, la seconde n'est pas. Donc, l'opérateur ne commande que le moteur de recherche de montrer cette deuxième partie. Évidemment, dans cette partie, les pages sont collectées dans lesquelles il n'y a pas un mot "Cyril" ou les mots "Méthode".
Nous sommes partis pour vous familiariser avec le mode de recherche étendu, configurer que vous pouvez en sélectionner la recherche avancée de lien de liaison, placée sous le bouton de recherche !. Pacuiiiiipehhhoro Formulaire de demande.
Dans le champ de recherche, vous pouvez entrer des mots liés opérateurs logiques (Dans ce cas, le commutateur doit tout doit être défini sur le groupe pour rechercher le mot de requête) et vous pouvez simplement spécifier si l'un des mots sélectionnés ou précis ([phase peut être [phase [Phase. Vous pouvez spécifier où la recherche sera Go - dans les documents eux-mêmes, dans les noms (titre) ou dans des textes de liaison. Vous pouvez limiter la distance entre les mots; ceci, bien sûr, ne remplacera pas la recherche de phrases, mais peut parfois aider. Vous ne pouvez parfois rechercher spécifique. Sites (recherchez des documents uniquement sur les sites suivants). Vous pouvez rechercher des documents de type définis, poser la langue du document et le format du document créé à la période spécifiée (date de document). Enfin, vous pouvez définir les pages non Seulement par respect de la demande (pertinence). Mais par date, ainsi que de demander à une recherche de documents ne contenant pas de mots spécifiés (éliminer les documents contenant les mots suivants).
Rambler (péché. Rambler, Rambler, Transl. De l'anglais comme Wanderer, Tramp) — Moteur de recherche Internet Holding Thinbler Group Media.
Le moteur de recherche prend en compte la morphologie de russe, ukrainien et anglaisDe plus, lors de la recherche de réussite tout au long des formes de demandes et de problèmes, des résultats en termes de conformité à la demande.
Rambler, l'un des tout premiers moteurs de recherche sur le marché en ligne a joué un rôle énorme dans la formation de Runet. Avec un petit nombre (pas plus de 5%), le moteur de recherche est debout sur 3 lieu après Yandex et Google.
Le public de Rumbler est basé sur les personnes utilisant le système avec presque le moment de son apparition.
Parmi les avantages de Rambler, vous pouvez mettre en évidence le classement thématique de sites, service de presse, Internet messenger, service de paiement en ligne, courrier gratuit et service publicité contextuelle Coureur, etc.
Chronique des événements
En 1991, un groupe de scientifiques, à savoir Sergey Lysakov, Yuri ershov, Dmitry Kryukov, Victor Voronkov et Vladimir Samoilov, de l'Institut de biochimie et de physiologie des micro-organismes de l'Académie de sciences russes, a pris le développement d'un réseau local pour le échange de scientifique et informations techniques dans Pushchino. Bientôt, le réseau a été connecté à Moscou, puis avec Internet. Le projet a rapidement gagné et a commencé à se développer activement.
L'année officielle de la naissance du moteur de recherche est 1996, lorsque Dmitry Kryukov a créé le service de recherche appelé Rambler. En 1996, d'autres moteurs de recherche ont déjà été créés et travaillés, mais ils, contrairement à Rambler, n'étaient pas populaires.
En 1997, Dmikov a introduit une échelle spécifique, le classificateur TOP100 de Rambler, responsable de la détermination de l'autorité des sites, en fonction de la fréquence de leurs visites.
En 1999, la position du directeur du développement et de la recherche, puis la place du directeur exécutif a pris Igor Ashmanov, qui a quitté la société en 2001. Il a décrit son travail à Rambler dans le livre "Life au sein d'une bulle", où les activités de la société décrites en détail pour 1999-2001., Et aussi, pourquoi Rambler a perdu sa 1ère place sur le marché Internet national.
En 2004 Le top 100 de Rambler a émis un certificat de qualité ISO 9001.
En 2007 Le poste du Directeur général a pris Mark Ozzumer. En 2009, une recherche verticale a été ajoutée en fonction de la technologie d'agrégateur étendue. Le 31 décembre 2009, l'ensemble de la direction a été résigné à Rambler avec le directeur général de Marka Ozzumer et la même année, le moteur de recherche a reçu un «prix du raket» dans la nomination «Culture et Communications de masse».
D'avril 2009 Olga Tourskieva, qui a travaillé à Vympel, directrice du développement de l'entreprise de Venture, dirigée par Rambler.
À la fin de juin 2011, Rambler est passé à la technologie de recherche Yandex. Parallèlement aux avantages du moteur de recherche, il y a des inconvénients, notamment par rapport à Yandex ou à Google. Rambler est rarement mis à jour par des algorithmes, il n'existe pratiquement aucun filtres pour contrôler la qualité des sources Internet pour des demandes à basse fréquence ou à moyenne fréquence, ce qui augmente le nombre de sites de spam, est faible et l'algorithme de déterminer la pertinence des sites. À cet égard, la part de Rambler parmi les moteurs de recherche a diminué de 20 à 5%.
Quel Rableler peut offrir?
Rambler fournit non seulement de nombreux projets de divertissement, mais également les sections suivantes:
1) "Cartes" - contient cartes détaillées grandes villes. Les utilisateurs peuvent apprendre leurs adresses, ouvrir des itinéraires et être conscients des embouteillages routiers.
2) À PRICA.RU, vous pouvez trouver des catalogues de produits, des informations sur les réductions, des critiques de nouveaux produits, des activités planifiées, etc.
3) "Finance" fournira toujours les informations nécessaires sur les devis, les situations sur le marché moderne, les actions, etc.
4) À Ferra.Ru, vous pouvez trouver des critiques des nouveautés de la technologie numérique: caméras, téléphones, ordinateurs, etc.