Bonjour chers lecteurs! Avec toi, Ekaterina Kalmykova. L'article d'aujourd'hui sera consacré à un concept tel qu'un moteur de recherche, ce que c'est, ce à quoi il sert. Nous examinons également en détail les variétés de moteurs de recherche sur Internet.
Si vous avez une question: «Pourquoi dois-je savoir sur ces moteurs de recherche?», Je répondrai de cette manière. Lorsque vous mangez une délicieuse soupe dans un restaurant, souhaitez-vous savoir à partir de quels ingrédients est-il préparé pour le répéter vous-même à la maison? Après tout, si vous êtes satisfait du résultat final, c'est-à-dire du goût de la soupe, alors vous seriez certainement intéressé de savoir ce qui a conduit à ce résultat?
Vous pouvez également dire sur le travail avec le moteur de recherche (PS). Si vous créez votre blog à l'avenir, alors, connaissant le travail du PS, vous n'aurez plus à demander l'aide de spécialistes. Vous pourrez ainsi mener votre projet de manière indépendante, de sorte que le système de recherche le verra et le montrera à d’autres utilisateurs. Après tout, la présence de votre ressource et, par conséquent, vos revenus en dépendent.
Alors commençons.
Qu'est-ce qu'un moteur de recherche?
Un moteur de recherche est une ressource spéciale sur Internet qui fournit des informations à un utilisateur conformément à sa demande. En d'autres termes, cette ressource collecte toutes les données du réseau mondial, tous les projets Web et, lorsqu'un utilisateur reçoit une demande spécifique, fournit les informations requises en les envoyant, par exemple, à un blog thématique ou à un site Web. 
Ainsi, après la création de votre projet, votre tâche sera d'entrer dans le problème, c'est-à-dire dans la "liste" ou la base de données du moteur de recherche. Étant donné que la promotion de sites Web sur Internet n’est tout simplement pas possible sans l’utilisation d’un moteur de recherche, vous devez donc veiller à la qualité de votre ressource, à son optimisation interne et externe. Comment faire cela, nous parlerons dans les articles suivants. Alors, à ne pas manquer.
En attendant, si vous décidez de créer votre blog, je vous recommande de lire ces articles ici:
Comme de nouvelles ressources Web apparaissent presque tous les jours, la base de données du moteur de recherche doit donc être constamment mise à jour. Chaque site nouvellement créé doit être indexé par un robot. En termes simples, les assistants PS - les robots doivent se familiariser avec la nouvelle ressource et transmettre ces données au moteur de recherche lui-même.
Eh bien, alors vous avez probablement deviné que lors de la visite de votre blog avec un robot, il devrait tout aimer. Votre prochain destin dépendra de cet invité.
Comment faire pour que le robot de votre projet reste ravi, je vous raconterai dans l'un des articles suivants. Ne manquez pas, il y aura des informations intéressantes et très intéressantes que je partagerai avec vous.
Moteurs de recherche d'emploi
Tout travail lié à PS commence par la saisie de la requête de recherche dans la zone de recherche. Que peuvent rechercher les utilisateurs? N'importe quoi, à commencer par une recette de tourtes au chou et se terminant par la question pérenne «Comment gagner plus d'argent sans rien faire».
Pour que votre ressource puisse répondre à une question, vous devez être en avance sur vos concurrents. Pour cela, vous devez accorder une attention particulière à la promotion de votre projet, qui comprend des activités telles que la rédaction de contenu optimisé de haute qualité, c’est-à-dire répondre aux demandes d’article, améliorer les facteurs de comportement, c’est-à-dire que votre lecteur s’intéresse à la ressource, c’est-à-dire une amélioration de la convivialité. La commodité des visiteurs et de nombreux autres facteurs. C'est ce que nous apprenons tous à faire avec vous.
Composants du moteur de recherche
Et qu'est-ce qui aide les moteurs de recherche, par exemple, le même Google à indexer votre ressource? 
- Les agents sont des travailleurs qui effectuent l'essentiel du travail - indexation et analyse de sites.
- Spiders (spider) - programme permettant de télécharger les pages d'une ressource Web et de collecter des informations générales à ce sujet.
- Crawler (crawler) - un programme qui recherche tous les liens sur les pages, se déplaçant sur ce qui est à la recherche de nouvelles données non familières aux moteurs de recherche.
- Indexer (indexer) - analyse le texte, les en-têtes, le style, etc.
- Robots - indexez les pages de votre contenu et explorez divers liens.
Pour que l’indexation se déroule selon vos besoins et que vous créiez un document spécial, «robots.txt». Il permet au système de vérifier uniquement les pages dont vous avez besoin et de supprimer ce que vous ne devriez pas voir.
Types de moteurs de recherche
Il existe plusieurs options pour les systèmes de récupération d'informations:
- Répertoires. Une simple comparaison de recherche est une bibliothèque dans une bibliothèque. Là, tout est stocké dans des sous-catégories et des catégories d'un sujet particulier. Si vous utilisez ce moteur de recherche, croyez-moi, les informations que vous y trouverez seront plus qu'utiles et compréhensibles pour votre perception. Devinez de quel type de site commun parlez-vous? Bien sûr, à propos de Wikipedia, qui a rassemblé tout un répertoire d'informations utiles.
- Index de recherche. La recherche dans les données est effectuée par phrases clés. C'est à la fois pratique et peu pratique. Je pense que les personnes qui me cherchent, par exemple, «La fille montre la classe», vont me trouver comment la fille se présente, et quelque chose de pas très décent apparaît dans la recherche. Ce type de recherche caractérise la plupart des moteurs de recherche.
- Systèmes de notation. Déterminez votre popularité en raison du nombre de visites. Bien entendu, ce n'est pas le meilleur critère, car l'utilité et la qualité de la ressource elle-même ne sont pas toujours prises en compte. Un exemple d'un tel système est la ressource Internet alexa.com.
Les moteurs de recherche sont également divisés en général et spécialisé. Les moteurs de recherche généraux trient les données d'information sans aucune sélection pour toutes les ressources Web connues. Ceux-ci incluent Yandex, Rambler, Google. Spécialisé - effectuez un tri en fonction de la langue utilisée.
En outre, les moteurs de recherche peuvent être divisés en distribution régionale et mondiale.
À ce jour, tous les moteurs de recherche améliorent constamment leurs algorithmes pour la sélection de ressources pertinentes et de qualité.
Un peu d'histoire
Dans RuNet, PS est apparu en 1996 - il s’agit de Aport et Rambler. Un an plus tard, en 1997, Yandex a été formé et un an plus tard, en 1998, un autre concurrent est apparu - Google. Actuellement, les plus populaires sont Yandex et Google.
Quels sont les moteurs de recherche les plus populaires?
Nous donnons des statistiques:

Comme vous pouvez le constater, Yandex est actuellement le plus populaire en Russie, avec Google et Mail.
Ainsi, vous pouvez voir les principales recherches sur lesquelles vous devez vous concentrer lors de la création et de la promotion de votre projet.
Moteur de recherche Yandex (Yandex)
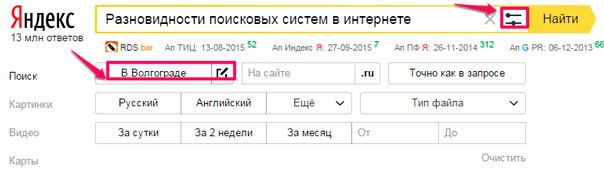
Le principe de fonctionnement est le suivant: dans la zone de recherche, entrez la requête de recherche, cliquez sur "Rechercher" et consultez le problème. Yandex a recueilli 13 millions de réponses à votre demande. Vous pouvez également rechercher en images, vidéo, marché (voir la colonne de gauche).

De plus, vous pouvez personnaliser la région à rechercher. Pour ce faire, dans la barre de recherche, cliquez sur l'icône à côté de la croix et sélectionnez la région dans la fenêtre du filtre.
Moteur de recherche Google (Google)
Google fonctionne par analogie avec Yandex. Vous pouvez rechercher des informations dans différentes sections: images, vidéos, actualités, cartes, etc.

Si vous cliquez sur «Outils de recherche», un panneau contenant les paramètres s'ouvrira, dans lequel vous pourrez sélectionner une région, une langue et le temps nécessaire à la recherche d'informations.
Maintenant que vous savez quels moteurs de recherche existent sur Internet, vous avez également vu les plus populaires, et maintenant, armés d'informations, vous pouvez établir vos connexions et vos interactions avec les moteurs de recherche.
C'est tout pour aujourd'hui. Comment aimez-vous l'article?
Au revoir tout le monde
Je vous conseille de mettre à jour le blog, afin de ne pas manquer la publication de nouvelles nouvelles.
Ekaterina Kalmykova
Les moteurs de recherche aident les internautes à trouver les informations dont ils ont besoin. Dans la barre de recherche, la personne entre sa requête: un mot clé de recherche ou un ensemble de mots clés. Et sélectionne dans la liste le site que vous aimez, reflétant ainsi l'essence de la question posée par le moteur de recherche. Les moteurs de recherche Internet sont confortables et modernes.
Vue d'ensemble des moteurs de recherche
Le moteur de recherche traite des centaines de giga-octets d'informations et fournit à l'utilisateur les sites nécessaires dans un format pratique de la liste des pages trouvées. Cette liste peut contenir des centaines de milliers de pages contenant ces mots. De tout cela, vous pouvez déjà trouver les informations nécessaires, cela peut parfois être problématique. Et parfois, vous trouvez immédiatement le bon site avec des informations pertinentes.
Le serveur de recherche AltaVista est le moteur de recherche le moins connu de Runet. Il était populaire auprès du public anglophone lors du lancement du système "Vista" de Microsoft. Sa base de données ne compte que cinq cent cinquante millions de pages. Quatre millions d'articles de 15 000 groupes de discussion dans l'agrégateur Juzenet. Et il y a une recherche d'images et d'autres fichiers multimédias, tels que des vidéos et des sons. L'émission des images produites dans un format légèrement délicat. Ils sont affichés avec une description de la taille lorsque vous pointez la souris sur l'image.
Projet Open Directory - ce service fait plutôt référence à des annuaires qu'à des moteurs de recherche. Mais à travers elle, la recherche ne porte que sur les ressources Internet de qualité. Travailler pour le confort des utilisateurs comporte environ 38 000 éditeurs qui sélectionnent chaque jour des sites pour leur catalogue.
Serveur de recherche WebCrawler - le nombre d’index du service de recherche est d’environ 1,6 million de documents indexés. Le répertoire du projet contient environ 100 000 catégories, dans lesquelles vous pouvez définir presque tous les sites. Le moteur de recherche a une base de données commune avec un autre projet Internet appelé Excite, mais ce projet est spécialisé dans le trafic de divertissement, l’indexation des chats et les horoscopes.
Lycos - ce serveur contient des informations sur 50 millions de pages. Vous recevez des requêtes sur le serveur de recherche. Vous pouvez écrire, par exemple: "Comment rédiger un article pour le site" et le moteur de recherche donnera les informations nécessaires. Ils sont triés en fonction de votre demande. Peut-être que parmi eux, vous trouverez le bon. Des requêtes sont adressées au serveur de recherche pour chaque moteur de recherche ci-dessous.
HotBot - contient des informations sur 55 millions de pages de partout sur Internet. Parmi eux, vous pouvez trouver les informations nécessaires. Pour plus de commodité, vous pouvez spécifier la position géographique souhaitée. Par exemple, vous recherchez un café dans une ville particulière et demandez la demande correspondante. Le moteur de recherche recherche également des sons, des graphiques, des scripts de site et d'autres éléments non essentiels dont vous pourriez avoir besoin. Le serveur s'est récemment connecté à "Juzenet" et une recherche peut également être effectuée à cet endroit.

Google et Yahoo - géants de la recherche
Serveur de recherche "Google" (Google) - il a toujours été indexé pour environ 2 milliards de pages qui recherchent un contenu intéressant pour l'utilisateur. "Runet" est bien indexé, mais "Google" n'est pas devenu meilleur que "Yandex", car il prend en compte les caractéristiques individuelles de la langue russe, l'orthographe et l'orthoépie des mots lors de la recherche.
Le moteur de recherche Yahoo (Yahoo!) - dispose d’un service d’information développé, rassemblé dans les médias du monde entier. Il a environ 3 000 000 de liens indexés. Le service est assez bien structuré. Est l'un des premiers au monde. Mais n'est pas devenu aussi populaire que "Google".

Métasystèmes
Outre les moteurs de recherche classiques, il existe des métasystèmes qui effectuent une recherche simultanée dans tous les systèmes. Les résultats vous seront présentés sous une forme pratique. Le service Yandex est le plus important de Runet et le premier du genre. Après que le moteur de recherche se soit étendu aux pays de la CEI, il prend en compte la morphologie de la langue. Le programme Copernic 2001 fonctionne depuis longtemps et met constamment à jour sa base de données à partir de divers services. La recherche peut être effectuée par catégorie ou par géodonnées. L'extradition peut être liée à la localité d'où provient la demande.

Il existe une version gratuite et payante du service, utilisée par plus de 14 millions de personnes. Le serveur utilise pour rechercher "Google", "Yandex" et autres.
Rambler et Yandex - les plus grands annuaires de sites
Rambler est un site Web russe proposant des services permettant de trouver la bonne information sur Internet. Le moteur de recherche est assez récent, mais a déjà gagné en popularité en Russie et dans la CEI. Il existe un catalogue et un agrégateur de nouvelles avec un grand nombre de sites en russe. C'est le plus grand de la CEI, suivi de Yandex, qui le contourne en qualité. Dans "Yandex" devenir assez difficile pour les sites obscurs. Dans le "Rambler" l'inscription est gratuite pour tous les portails qui remplissent les conditions pour l'adoption du projet dans l'annuaire.
Recherche de fichier
"Index FTP". Il contient des informations sur les serveurs FTP utilisés pour stocker et distribuer des informations. Mais des informations sous forme de fichiers.
Filez - avec son aide, vous pouvez visualiser plus de 100 millions de fichiers contenus dans l'index de recherche de fichiers.
Examinons plus en détail le concept d’une requête de recherche sur l’exemple du système de recherche Yandex. La requête de recherche doit être formulée par l'utilisateur en fonction de ce qu'il souhaite trouver, le plus brièvement et le plus simplement possible. Supposons que nous voulions trouver des informations dans Yandex sur la manière de choisir une voiture. Pour ce faire, ouvrez la page principale de "Yandex" et entrez le texte de la requête de recherche "Comment choisir une voiture". De plus, notre tâche consiste à ouvrir des liens vers des sources Internet fournies par notre demande. Cependant, il est tout à fait possible de ne pas trouver les informations dont nous avons besoin. Si cela se produit, vous devez reformuler votre demande ou dans la base de données, le système de recherche ne contient aucune information pertinente sur notre demande (cela peut être le cas lors de la définition de requêtes très «étroites», telles que «Comment choisir une voiture à Arkhangelsk»)
La tâche principale de tout moteur de recherche est de fournir exactement les informations recherchées. Et pour apprendre aux utilisateurs à faire les "bonnes" requêtes au système, c.-à-d. requêtes correspondant aux principes des moteurs de recherche, c’est impossible. Par conséquent, les développeurs créent de tels algorithmes et principes des moteurs de recherche qui permettraient aux utilisateurs de trouver les informations qu’ils recherchent.
Cela signifie que le moteur de recherche doit «penser» exactement comme le pense l'utilisateur lorsqu'il recherche des informations. Lorsqu'un utilisateur demande un moteur de recherche, il veut trouver ce dont il a besoin, aussi rapidement et facilement que possible. En obtenant le résultat, il évalue le travail du système, guidé par plusieurs paramètres clés. A-t-il trouvé ce qu'il cherchait? Sinon, combien de fois a-t-il dû reformuler sa requête pour trouver ce qu'il cherchait? Quelle information pertinente pourrait-il trouver? Combien de temps le moteur de recherche a-t-il traité? Dans quelle mesure les résultats de la recherche étaient-ils pratiques? Le résultat souhaité était-il le premier ou le centième? Combien de déchets inutiles ont été trouvés avec des informations utiles? Y aura-t-il les informations nécessaires pour accéder au moteur de recherche, par exemple, dans une semaine ou dans un mois?
Afin de répondre à toutes ces questions avec des réponses, les développeurs de moteurs de recherche améliorent constamment leurs algorithmes et leurs principes de recherche, ajoutent de nouvelles fonctionnalités et capacités, et tentent d'accélérer le système de toutes les manières possibles.
3. Les principales caractéristiques du moteur de recherche
Nous décrivons les principales caractéristiques des moteurs de recherche:
- Complétude
L’exhaustivité est l’une des caractéristiques principales d’un moteur de recherche. Elle représente le rapport entre le nombre de documents trouvés sur demande et le nombre total de documents sur Internet qui répondent à cette demande. Par exemple, si 100 pages sur Internet contiennent la phrase «Comment choisir une voiture» et que seules 60 d'entre elles ont été trouvées dans la demande correspondante, la recherche sera alors remplie à 0,6. Évidemment, plus la recherche est complète, moins il est probable que l'utilisateur ne trouvera pas le document dont il a besoin, à condition qu'il existe déjà sur Internet.
- Précision
La précision est une autre caractéristique principale du moteur de recherche, qui est déterminée par le degré de conformité des documents trouvés à la demande de l'utilisateur. Par exemple, si sur demande «comment choisir une voiture», il existe 100 documents, dont 50 contiennent la phrase «comment choisir une voiture», et le reste contient simplement ces mots («comment choisir le magnétophone et l'installer dans la voiture»), la précision de la recherche est alors: égal à 50/100 (= 0,5). Plus la recherche est précise, plus l'utilisateur trouvera rapidement les documents dont il a besoin, moins il y aura de «déchets» parmi eux, moins les documents trouvés ne correspondront souvent pas à la requête.
- La pertinence
La pertinence est un élément tout aussi important de la recherche, qui se caractérise par le temps qui s'écoule entre le moment de la publication des documents sur Internet et leur saisie dans la base de données des index des moteurs de recherche. Par exemple, le lendemain de l’apparition de nouvelles intéressantes, de nombreux utilisateurs se sont tournés vers les moteurs de recherche avec des requêtes pertinentes. Objectivement, moins d'une journée s'est écoulée depuis la publication de nouvelles sur ce sujet. Toutefois, les principaux documents ont déjà été indexés et disponibles pour la recherche, grâce à l'existence de la «base rapide» parmi les principaux moteurs de recherche, qui est mise à jour plusieurs fois par jour.
- Vitesse de recherche
La vitesse de recherche est étroitement liée à sa résistance à la charge. Par exemple, selon Rambler Internet Holding LLC, aujourd’hui, pendant les heures ouvrables, environ 60 requêtes par seconde sont transmises au moteur de recherche Rambler. Cette charge nécessite une réduction du temps de traitement d'une requête individuelle. Ici, les intérêts de l'utilisateur et du moteur de recherche sont les mêmes: le visiteur veut obtenir les résultats le plus rapidement possible et le moteur de recherche doit traiter la requête le plus rapidement possible afin de ne pas ralentir le calcul des requêtes suivantes.
- La visibilité
4. Bref historique du développement des moteurs de recherche
Au début de la période de développement d’Internet, le nombre de ses utilisateurs était faible et la quantité d’informations disponibles était relativement faible. Dans la plupart des cas, seuls les employés du secteur de la recherche avaient accès à Internet. À l'heure actuelle, la tâche de rechercher des informations sur Internet n'était pas aussi urgente qu'aujourd'hui.
L’un des premiers moyens d’organiser l’accès aux ressources d’information du réseau a été la création de répertoires de sites ouverts, avec des liens vers des ressources regroupées en fonction du sujet. Yahoo.com, le premier projet de ce type, a été lancé au printemps 1994. Une fois que le nombre de sites dans le catalogue a considérablement augmenté, la possibilité de rechercher les informations nécessaires dans le catalogue a été ajoutée. En un sens, il ne s’agissait pas encore d’un moteur de recherche, la zone de recherche n’étant limitée que par les ressources présentes dans l’annuaire, et non par toutes les ressources Internet.
Les catalogues de liens étaient largement utilisés auparavant, mais ils ont presque complètement perdu leur popularité à l'heure actuelle. Même modernes, les catalogues volumineux ne contiennent que des informations sur une partie négligeable d’Internet. Le plus grand répertoire du réseau DMOZ (également appelé projet Open Directory) contient des informations sur 5 millions de ressources, tandis que la base du moteur de recherche Google comprend plus de 8 milliards de documents.
En 1995, les moteurs de recherche Lycos et AltaVista sont apparus. Dernière depuis de nombreuses années était un chef de file dans le domaine de la recherche d'information sur Internet.
En 1997, Sergey Brin et Larry Page ont créé un moteur de recherche Google dans le cadre d'un projet de recherche mené à l'Université de Stanford. Google est actuellement le moteur de recherche le plus populaire au monde!
En septembre 1997, Yandex a été officiellement annoncé le moteur de recherche Yandex, qui est le plus populaire sur Internet en langue russe.
Il existe actuellement trois principaux moteurs de recherche (internationaux) - Google, Yahoo et disposant de leurs propres bases de données et algorithmes de recherche. La plupart des moteurs de recherche restants (qui sont nombreux) utilisent, sous une forme ou une autre, les résultats des trois répertoriés. Par exemple, la recherche AOL (search.aol.com) utilise la base de données Google et AltaVista, Lycos et AllTheWeb utilisent la base de données Yahoo.
5. La composition et les principes du moteur de recherche
En Russie, le moteur de recherche principal est Yandex, ci-après Rambler.ru, Google.ru, Aport.ru, Mail.ru. Et, pour le moment, Mail.ru utilise le moteur de recherche et la base de recherche Yandex.
Presque tous les principaux moteurs de recherche ont leur propre structure, différente des autres. Cependant, il est possible d'identifier les principaux composants communs à tous les moteurs de recherche. Les différences dans la structure ne peuvent être que sous la forme de la mise en œuvre des mécanismes d'interaction de ces composants.
Module d'indexation
Le module d’indexation comprend trois programmes auxiliaires (robots):
Spider (spider) - un programme conçu pour télécharger des pages Web. Spider télécharge la page et extrait tous les liens internes à partir de cette page. Téléchargez le code HTML de chaque page. Les robots utilisent les protocoles HTTP pour télécharger des pages. Fonctionne "araignée" comme suit. Le robot envoie une requête «get / path / document» et d'autres commandes de requête HTTP au serveur. En réponse, le robot reçoit un flux de texte contenant des informations de service et le document lui-même.
- URL de la page
- date à laquelle la page a été téléchargée
- en-tête de réponse du serveur http
- corps de la page (code html)
Crawler ("travelling" araignée) - un programme qui passe automatiquement à travers tous les liens trouvés sur la page. Sélectionne tous les liens présents sur la page. Sa tâche est de déterminer où l'araignée doit aller, en se basant sur les liens ou sur une liste d'adresses prédéterminée. Crawler, à la suite des liens trouvés, recherche de nouveaux documents inconnus du moteur de recherche.
Indexer (robot indexer) est un programme qui analyse les pages Web téléchargées par des araignées. L'indexeur analyse la page dans ses composants et les analyse à l'aide de ses propres algorithmes lexicaux et morphologiques. Divers éléments de la page sont analysés, tels que le texte, les en-têtes, les liens structurels et les fonctions de style, les balises HTML de service spéciales, etc.
Ainsi, le module d'indexation vous permet d'explorer un ensemble donné de ressources par des liens, de télécharger des pages de réunion, d'extraire des liens vers de nouvelles pages à partir de documents reçus et d'effectuer une analyse complète de ces documents.
Base de données
La base de données, ou index du moteur de recherche, est un système de stockage de données, un tableau d'informations dans lequel les paramètres convertis de tous les documents téléchargés et traités par le module d'indexation sont stockés de manière spéciale.
Serveur de recherche
Le serveur de recherche est un élément essentiel de tout le système, car la qualité et la rapidité de la recherche dépendent directement des algorithmes sous-jacents à son fonctionnement.
Le serveur de recherche fonctionne comme suit:
- La demande reçue de l'utilisateur est soumise à une analyse morphologique. L’environnement d’information de chaque document contenu dans la base de données est généré (qui sera ensuite affiché dans le formulaire, c’est-à-dire la demande d’information textuelle correspondante sur la page de résultats de recherche).
- Les données reçues sont transmises en tant que paramètres d'entrée à un module de classement spécial. Il en résulte un traitement des données pour tous les documents. Par conséquent, pour chaque document, son propre classement est calculé, ce qui caractérise la pertinence de la requête entrée par l'utilisateur et les divers composants de ce document stockés dans l'index du moteur de recherche.
- Selon le choix de l'utilisateur, cette classification peut être ajustée par des conditions supplémentaires (par exemple, la «recherche avancée»).
- Ensuite, un extrait de code est généré, c’est-à-dire que pour chaque document trouvé, un en-tête, un résumé, la requête la plus pertinente et un lien vers le document sont extraits de la table des documents et les mots trouvés sont mis en surbrillance.
- Les résultats de recherche obtenus sont transmis à l'utilisateur sous la forme d'une page de résultats de recherche SERP (Search Engine Result Page).
Comme vous pouvez le constater, tous ces composants sont étroitement liés les uns aux autres et travaillent en coopération, formant un mécanisme de fonctionnement de moteur de recherche clair et plutôt complexe, qui nécessite une énorme quantité de ressources.
6. Conclusion
Maintenant, résumez tout ce qui précède.
- La tâche principale de tout moteur de recherche est de fournir exactement les informations recherchées.
- Les principales caractéristiques des moteurs de recherche:
- Complétude
- Précision
- La pertinence
- Vitesse de recherche
- La visibilité
- Le premier moteur de recherche à part entière a été le projet WebCrawler, lancé en 1994.
- Le moteur de recherche comprend des composants:
- Module d'indexation
- Base de données
- Serveur de recherche
Nous espérons que notre master class vous permettra d’examiner de plus près le concept de PS, afin de mieux connaître les fonctions de base, les caractéristiques et le principe de fonctionnement des moteurs de recherche.
Basé sur des matériaux du site: http://www.seonews.ru/
Annuaires mondiaux et moteurs de recherche
Tous ces systèmes sont conçus pour rechercher des informations sur Internet dans son ensemble, sans référence à aucune région du monde. S'il est nécessaire d'identifier des informations complètes, il est recommandé d'effectuer une recherche cohérente à l'aide de plusieurs moteurs de recherche ou ouvrages de référence.
À propos de
Répertoire soutenu par des experts dans divers domaines de la connaissance. La tâche principale est de ne pas refléter toutes les ressources mais uniquement les ressources les plus précieuses. Les descriptions de site sont très expertes. Pratique lorsque vous devez sélectionner les ressources de la plus haute qualité sur un sujet spécifique. Le principal inconvénient est la lente mise à jour du matériel.
Alltheweb
Initialement - le moteur de recherche, situé en Europe et principalement axé sur les sites européens. Depuis mars 2004, le moteur de recherche Yahoo !, hébergé et lancé sous la marque AlltheWeb. et maintenant AlltheWeb est le «miroir» réel de Yahoo! Serach, la seule différence étant que, dans son module de production de résultats, les problèmes de production de documents dans différentes langues à l'aide de codages autres que le latin étendu sont beaucoup mieux résolus. Dans les 36 langues avec lesquelles le système fonctionne assez correctement, le russe a également diminué.
Alta Vista
Dans le passé, l'un des moteurs de recherche les plus populaires au monde. Depuis mars 2004, sous la marque Alta Vista, le moteur de recherche Yahoo! a été mis en ligne et lancé. et maintenant, Alta Vista est le véritable «miroir» de Yahoo! Serach.
Excite
Le système de recherche, le volume de la base de données qui compte plus de 250 millions de documents. Il possède un sous-système de recherche de source multimédia déployé.
Meilleur service de recherche au monde. Le moteur de recherche de la dernière génération, qui déclare la plus grande taille de base de données - plus de 8 milliards de documents. Il fournit une interface dans la langue de l'utilisateur, ainsi que la possibilité de trouver des illustrations. Google a été le premier moteur de recherche à indexer des documents aux formats PDF, PS, DOC, XLS, PPT, RTF et WP5.
Hotbot
Un moteur de recherche dont la taille de l'index de base de données n'excède pas 500 millions de documents. Il a la capacité de rechercher des illustrations, des fichiers audio et vidéo. Ne permet pas l'identification de documents en russe.
Looksmart
Répertoire de ressources, axé sur les intérêts de l’utilisateur Internet moyen.
Lycos
Le projet a connu plusieurs changements dramatiques. En 1996, il a été lancé en tant que moteur de recherche. En 1999, Lycos a été transformé en un répertoire de ressources. Depuis juillet 2002, avec l’introduction du mécanisme de recherche Search Lycos 6.0, il est à nouveau utilisé principalement comme moteur de recherche. Vous permet de rechercher des illustrations, des fichiers audio et vidéo. La déclaration du plus grand volume du fichier d'index n'indique toutefois pas sa taille exacte. Cela fonctionne mal avec les ressources russophones.
Recherche MSN
Moteur de recherche créé par Microsoft. Depuis février 2005, j'ai finalement adopté mon propre module de recherche. Enregistre plus de 5 milliards de documents. Le système permet de rechercher sur des sites d’information, de rechercher des illustrations, de rechercher dans l’encyclopédie Encarta de Microsoft, ainsi qu’un module qui, après téléchargement et installation gratuites, effectue une recherche sur le propre ordinateur de l’utilisateur.
Répertoire ouvert
Répertoire des ressources Internet, qui est aujourd'hui l’un des plus complets au monde: reflète environ 4 millions de ressources. C'est un projet à but non lucratif, formé par les forces de la communauté Internet. Pour cette raison, de nombreuses sections de l'Open Directory sont entièrement réalisées dans les langues nationales, y compris le russe.
Teoma
Moteur de recherche ouvert au début du troisième millénaire. Le seul avantage est le volume impressionnant du fichier d'index. Impossible de rechercher des documents en russe.Webtop
Un moteur de recherche qui déclare une base de données de plus de 500 millions de documents. A actuellement un mécanisme de création de requête primitive. N'a pas la capacité de rechercher des documents en russe.
Wisenut
Le moteur de recherche de dernière génération. Le principal avantage est un grand nombre de documents indexés. Impossible de rechercher des documents en russe.Yahoo! Répertoire
L’un des répertoires les plus complets et les plus fiables des ressources Internet. Son volume est impressionnant (environ 2 millions de ressources comptabilisées) et sa structure hiérarchique bien ramifiée. Idéal pour rechercher des listes de sites étrangers, principalement en anglais, sur un sujet donné. Des frais annuels étant facturés pour la réflexion sur les ressources, de nombreuses ressources précieuses ont été exclues de Yahoo! Répertoire et répertoire actuellement ne peuvent prétendre être exhaustifs.
Le moteur de recherche Yahoo !, qui est devenu un service distinct après la transformation du portail en 2004. Selon les résultats du test, comprend environ 4 milliards de documents. Il a de bonnes capacités de recherche pour les illustrations et les fichiers vidéo. Permet la recherche en russe.
Systèmes de métarecherche
Les systèmes de métarecherche sont un type d’outils de recherche qui ne possèdent pas leurs propres robots de recherche et bases de données (fichiers d’index). Leur principal avantage est la possibilité d'envoyer une requête à plusieurs "vrais" moteurs de recherche à la fois, puis de résumer les résultats. Leur utilisation est recommandée dans le cas de recherche d'informations sur un objet très rare ou avec un temps extrême, car les outils de méta-recherche ne sont souvent pas en mesure de traiter correctement une requête pour différents moteurs de recherche, ni de combiner correctement les résultats obtenus par différents systèmes.
Dogpile
Fait appel à divers outils de recherche de manière cohérente, plutôt que simultanément. Permet l'identification des données dans les conférences UseNet et sur les serveurs FTP, ainsi que la recherche d'illustrations, de fichiers audio et vidéo.
Ez2find.com
Le système fournit une recherche pertinente en russe. Il y a de très bonnes possibilités pour former une demande. La recherche est faite dans Google, AllTheWeb, Altavista, Yahoo, Open Directory. Les résultats sont triés par sections.
Métarecherche Ixquick
Le système utilise par défaut 14 principaux moteurs de recherche, à l'exception de Google. La requête utilise la syntaxe traditionnelle qui est exactement la même que celle utilisée dans Alta Vista. La liste des moteurs de recherche auxquels on a accès peut être facilement définie par l'utilisateur. Il fournit également une recherche de nouvelles, recherchant des illustrations et des fichiers audio.
KartOO
Une caractéristique distinctive est l'utilisation de la technologie flash dans l'interface. De ce fait, le chargement rapide de la page est réalisé, ainsi que la visualisation des liens entre les sites consacrés à un sujet spécifique.
Mamma Meta Search
Développement relativement nouveau. Avec la recherche de texte, fournit l'identification des fichiers multimédia. Il possède une interface simple, qui n’est toutefois pas configurable.
Méta-Crawler
Service de métarecherche pour anciens combattants. Par défaut, fait référence aux 14 outils de recherche les plus fiables. Permet de rechercher par n'importe quel mot de la requête, tous les mots ou une phrase exacte. Il possède les options de personnalisation les plus riches (l'élément de menu supérieur est Personnaliser).
Vivisimo
Le système dispose de nombreuses options personnalisables. Les résultats de la recherche sont automatiquement triés en sections. Vous permet d'afficher des aperçus des pages trouvées directement à partir de la liste des résultats.
Robot d'indexation
Ancien combattant d'un service de recherche qui est passé de systèmes de recherche à recherche automatique à un service de méta-recherche. Diffère dans la rapidité du travail et dans la pertinence des liens.
Annuaires nationaux et régionaux et moteurs de recherche
Actuellement, dans la plupart des pays développés, il existe au moins deux ou trois annuaires et moteurs de recherche qui reflètent le contenu des ressources Internet d'un État donné. Leur utilisation est plus efficace pour identifier les documents situés sur des serveurs d’un pays donné. Les outils de recherche russes sont pris en compte.
Afrique
Wo Yaa Africa Search (http://www.woyaa.com)Afrique du sud
Ananzi (http://www.ananzi.co.za)Zèbre (http://www.zebra.co.za)
Aadvark (http://www.aardvark.co.za)
Autres pays
(http://www.balaa.com) Référence. Nouvelle-Zélande (http://nzexplorer.co.nz) Carrefour.net (http://www.yupi.com) Annuaire. URUGUAY GUIA MUNDIAL Uruguay (http://web2mil.intercanal.com/uruguay) Répertoire.Selon le site: http://library.vadimstepanov.ru/
Prikhodko Valentin Ivanovich, Copyright © 2010 - 2016 E-mail: [email protégé]
Ukraine
Réimpression de documents avec un lien obligatoire vers le site - BIENVENUE!.
Tous les matériaux sur le site sont fournis uniquement à des fins d'information et d'éducation.
l'administration du site ne réclame pas leur auteur et n'est pas responsable de leur contenu.