1. Introduction
Chaque année, le volume d'Internet augmente considérablement, de sorte que la probabilité de trouver les informations dont vous avez besoin augmente considérablement. Internet connecte des millions d'ordinateurs, de nombreux réseaux différents, le nombre d'utilisateurs augmente de 15 à 80 % par an. Et, néanmoins, de plus en plus souvent lors de l'accès à Internet, le problème principal n'est pas le manque d'informations requises, mais la capacité de les trouver. En règle générale, une personne ordinaire, en raison de diverses circonstances, ne peut ou ne veut pas passer plus de 15 à 20 minutes à chercher la réponse dont elle a besoin. Par conséquent, il est particulièrement important d'apprendre correctement et avec compétence une chose apparemment simple - où et comment chercher afin d'obtenir les réponses DÉSIRÉES.
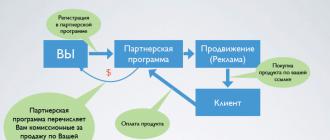
Pour trouver les informations dont vous avez besoin, vous devez trouver son adresse. Pour cela, il existe des serveurs de recherche spécialisés (robots d'indexation (moteurs de recherche), annuaires Internet thématiques, systèmes de méta-recherche, services de recherche de personnes, etc.). Cette master class révèle les principales technologies de recherche d'informations sur Internet, fournit les fonctionnalités générales des outils de recherche, examine la structure des requêtes de recherche pour les moteurs de recherche russophones et anglophones les plus populaires.
2. Technologies de recherche
Technologie Web À l'échelle mondiale Le Web (WWW) est considéré comme une technologie spéciale pour la préparation et la publication de documents sur Internet. Le WWW comprend à la fois des pages Web et bibliothèques numériques, des catalogues et même des musées virtuels ! Avec une telle abondance d'informations, la question se pose : « Comment naviguer dans un espace d'information aussi vaste et à grande échelle ?
Les outils de recherche viennent à la rescousse pour résoudre ce problème.
2.1 Outils de recherche
Les outils de recherche sont des logiciels spéciaux dont le but principal est de fournir aux internautes la recherche d'informations la plus optimale et la plus qualitative. Les outils de recherche sont hébergés sur des serveurs Web spéciaux, chacun remplissant une fonction spécifique :
- Analyse de pages web et saisie des résultats d'analyse à l'un ou l'autre niveau de la base de données serveur de recherche.
- Rechercher des informations sur la demande de l'utilisateur.
- Fournir une interface pratique pour rechercher des informations et afficher le résultat de la recherche par l'utilisateur.
Les méthodes de travail utilisées lors de l'utilisation de l'un ou l'autre outil de recherche sont pratiquement les mêmes. Avant de passer à leur discussion, considérez les concepts suivants :
- L'interface de l'outil de recherche se présente sous la forme d'une page avec des hyperliens, une ligne de soumission de requête (barre de recherche) et des outils d'activation de requête.
- L'index des moteurs de recherche est une base d'informations contenant le résultat de l'analyse des pages web, compilé selon certaines règles.
- Une requête est un mot-clé ou une phrase qu'un utilisateur entre dans la barre de recherche. Pour former diverses requêtes, des caractères spéciaux ("", ~), des symboles mathématiques (*, +,?) sont utilisés.
Le schéma de recherche d'informations sur Internet est simple. L'utilisateur tape une phrase clé et active la recherche, recevant ainsi une sélection de documents pour la requête formulée (spécifiée). Cette liste de documents est classée selon certains critères de sorte qu'en tête de liste figurent les documents qui correspondent le plus à la demande de l'utilisateur. Chacun des outils de recherche utilise des critères différents pour classer les documents, à la fois dans l'analyse des résultats de recherche et dans la constitution de l'index (remplissage de la base de données d'index des pages Web).
Ainsi, si vous spécifiez la même requête dans la chaîne de recherche pour chaque outil de recherche, vous pouvez obtenir des résultats de recherche différents. Pour l'utilisateur, il est très important de savoir quels documents apparaîtront dans les deux ou trois premières douzaines de documents en fonction des résultats de la recherche et dans quelle mesure ces documents correspondent aux attentes de l'utilisateur.
La plupart des outils de recherche proposent deux méthodes de recherche : recherche simple(recherche simple) et Recherche Avancée(recherche avancée) avec et sans formulaire de demande spéciale. Considérons les deux types de recherche en utilisant l'exemple de la langue anglaise moteur de recherche.
Par exemple, AltaVista est pratique à utiliser pour des requêtes arbitraires, "Quelque chose sur les diplômes en ligne en technologie de l'information", tandis que l'outil de recherche Yahoo vous permet d'obtenir des nouvelles du monde, des informations sur les devises ou des prévisions météorologiques.
La maîtrise des critères d'affinement d'une requête et des techniques de recherche avancées vous permet d'augmenter l'efficacité de la recherche et de trouver rapidement les informations dont vous avez besoin. Tout d'abord, vous pouvez augmenter l'efficacité de la recherche en utilisant des opérateurs logiques (opérations) Ou, Et, Près, Non, mathématiques et caractères spéciaux... A l'aide d'opérateurs et/ou de symboles, l'utilisateur associe des mots-clés dans l'ordre souhaité pour obtenir le résultat de recherche le plus approprié. Les formulaires de demande sont présentés dans le tableau 1.
Tableau 1
Une simple requête donne un certain nombre de liens vers des documents, puisque la liste comprend des documents contenant l'un des mots saisis lors de la requête, ou une simple phrase (voir tableau 1). L'opérateur et vous permet de spécifier que tous les mots-clés doivent être inclus dans le contenu du document. Cependant, le nombre de documents peut encore être important et leur examen prendra beaucoup de temps. Par conséquent, dans certains cas, il est beaucoup plus pratique d'utiliser l'opérateur de contexte proche, qui indique que les mots doivent être situés dans le document à une proximité suffisante. L'utilisation de near réduit considérablement le nombre de documents trouvés. La présence du caractère "*" dans la chaîne de requête signifie qu'un mot sera recherché par son masque. Par exemple, nous obtenons une liste de documents contenant des mots commençant par "gov" si nous écrivons "gov *" dans la chaîne de requête. Il peut s'agir des mots gouvernement, gouverneur, etc.
Le moteur de recherche tout aussi populaire Rambler maintient des statistiques sur le trafic de liens à partir de sa propre base de données, les mêmes sont prises en charge Opérateurs logiques AND, OR, NOT, métacaractère * (similaire au caractère d'extension de plage de requête * dans AltaVista), symboles de coefficient + et -, pour augmenter ou diminuer la signification des mots entrés dans la requête.
Jetons un coup d'œil aux technologies les plus populaires pour trouver des informations sur Internet.
2.2 Moteurs de recherche
Les moteurs de recherche Web sont des serveurs avec une énorme base de données d'URL qui accèdent automatiquement aux pages WWW à toutes ces adresses, examinent le contenu de ces pages, forment et écrivent des mots-clés à partir des pages dans leur base de données (pages d'index).
De plus, les robots des moteurs de recherche suivent les liens trouvés sur les pages et les réindexent. Étant donné que presque toutes les pages WWW contiennent de nombreux liens vers d'autres pages, alors avec un tel travail, le moteur de recherche dans le résultat final peut théoriquement contourner tous les sites sur Internet.
Ce type d'outils de recherche est le plus connu et le plus populaire parmi tous les internautes. Tout le monde connaît les noms des moteurs de recherche Web bien connus (moteurs de recherche) - Yandex, Rambler, Aport.
Pour utiliser ce type d'outil de recherche, vous devez vous y rendre et taper le mot-clé qui vous intéresse dans la barre de recherche. Ensuite, vous recevrez les résultats des liens stockés dans la base de données du moteur de recherche les plus proches de votre demande. Pour rendre votre recherche plus efficace, faites attention aux points suivants à l'avance :
- décider du sujet de votre demande. Qu'est-ce que tu veux trouver exactement ?
- Faites attention à la langue, à la grammaire, à l'utilisation de divers symboles non-lettres, à la morphologie.Il est également important de bien formuler et saisir les mots-clés. Chaque moteur de recherche a sa propre forme d'écriture d'une requête - le principe est le même, mais les symboles ou opérateurs utilisés peuvent différer. Les formulaires d'enquête requis diffèrent également en fonction de la complexité du logiciel des moteurs de recherche et des services qu'ils fournissent. D'une manière ou d'une autre, chaque moteur de recherche dispose d'une section "Aide", où toutes les règles de syntaxe, ainsi que les recommandations et astuces de recherche, sont expliquées facilement (capture d'écran des pages du moteur de recherche).
- utiliser les capacités de différents moteurs de recherche. Si vous ne le trouvez pas sur Yandex, essayez-le sur Google. Utilisez les services de recherche avancée.
- pour exclure les documents contenant certains termes, utilisez le signe "-" devant chacun de ces mots. Par exemple, si vous avez besoin d'informations sur les œuvres de Shakespeare, à l'exception de "Hamlet", alors saisissez une requête sous la forme : "Shakespeare-Hamlet". Et pour, au contraire, inclure dans les résultats de la recherche nécessairement certains liens, utilisez le symbole "+". Ainsi, pour trouver des liens sur la vente de voitures, vous avez besoin de la requête "vente + voiture". Pour augmenter l'efficacité et la précision de votre recherche, utilisez des combinaisons de ces symboles.
- chaque lien dans la liste des résultats de recherche contient - plusieurs lignes du document trouvé, parmi lesquelles se trouvent vos mots-clés. Avant de cliquer sur le lien, évaluez la correspondance de l'extrait avec l'objet de la demande. Après avoir cliqué sur un lien vers un site spécifique, regardez attentivement la page principale. En règle générale, la première page suffit pour comprendre si vous êtes venu à l'adresse ou non. Si oui, effectuez d'autres recherches pour les informations nécessaires sur le site sélectionné (dans les sections du site), sinon, revenez aux résultats de la recherche et essayez le lien suivant.
- rappelez-vous que les moteurs de recherche ne produisent pas d'informations par eux-mêmes (sauf pour des clarifications sur eux-mêmes). Le moteur de recherche n'est qu'un intermédiaire entre le propriétaire de l'information (site) et vous. Les bases de données sont constamment mises à jour, de nouvelles adresses y sont ajoutées, mais le retard par rapport aux informations réellement existantes dans le monde persiste. Tout simplement parce que les moteurs de recherche ne fonctionnent pas à la vitesse de la lumière.
Les moteurs de recherche Web les plus connus sont Google, Yahoo, Alta Vista, Excite, Hot Bot, Lycos. Parmi les russophones figurent Yandex, Rambler, Aport.
Les moteurs de recherche sont les plus importants et les plus précieux, mais loin d'être les seules sources d'information sur le Web, car en plus d'eux, il existe d'autres moyens de rechercher sur Internet.
2.3 répertoires
Le catalogue des ressources Internet est un catalogue hiérarchique constamment mis à jour et reconstitué contenant de nombreuses catégories et des serveurs Web individuels avec une brève description de leur contenu. La façon de rechercher dans le catalogue implique de "descendre les escaliers", c'est-à-dire de passer de catégories plus générales à des plus spécifiques. L'un des avantages des catalogues thématiques est que les explications des liens sont fournies par les créateurs du catalogue et reflètent pleinement son contenu, c'est-à-dire qu'elles vous donnent la possibilité de déterminer plus précisément comment le contenu du serveur correspond à l'objectif de Votre recherche.
Un exemple de catalogue thématique en russe est la ressource http://www.ulitka.ru/.
Sur la page principale de ce site il y a un rubrificateur thématique,
à l'aide de laquelle l'utilisateur saisit la rubrique avec des liens vers les produits qui l'intéressent.

De plus, certains répertoires thématiques permettent des recherches par mot clé. L'utilisateur entre le mot-clé requis dans la barre de recherche

et reçoit une liste de liens avec des descriptions de sites qui correspondent le mieux à sa demande. Il convient de noter que cette recherche n'a pas lieu dans le contenu des serveurs WWW, mais dans leurs brèves descriptions stockées dans le catalogue.
Dans notre exemple, le catalogue a aussi la possibilité de trier les sites par nombre de visites, par ordre alphabétique, par date d'entrée.

Autres exemples d'annuaires en russe :
[email protected]
Liste Web
Vsego.ru
Parmi les catalogues de langue anglaise figurent :
http://www.DMOS.org
http://www.yahoo.com/
http://www.looksmart.com
2.4 Collections de liens
Les collections de liens sont des liens triés par sujet. Ils sont assez différents les uns des autres en termes de contenu, donc afin de trouver une sélection qui correspond le mieux à vos intérêts, vous devez les parcourir vous-même afin de vous faire votre propre opinion.
A titre d'exemple, nous donnerons la Sélection de liens "Trésors Internet" de JSC "Relcom"

Utilisateur en cliquant sur l'une des rubriques qui l'intéressent
Pour les automobilistes
- Astronomie et astrologie
- Ta maison
- Vos animaux de compagnie
- Les enfants sont des fleurs de vie
- Loisirs
- Les villes sur Internet
- Santé et médecine
- Agences de presse et services
- Musée des traditions locales, etc.,
- Electronique automobile.
- Musée de l'automobile de l'Antiquité.
- Collège de Protection Juridique des Propriétaires de Voitures.
- Sportdrive.
L'avantage de ce type d'outils de recherche est leur pertinence, généralement la sélection comprend des ressources Internet rares sélectionnées par un webmaster spécifique ou le propriétaire d'une page Internet.
2.5 base de données d'adresses
Les bases de données d'adresses sont des serveurs de recherche spéciaux qui utilisent généralement des classifications par type d'activité, par produits et services fournis, par géographie. Parfois, ils sont complétés par une recherche alphabétique. Les enregistrements de la base de données stockent des informations sur les sites qui fournissent des informations sur l'adresse e-mail, l'organisation et l'adresse postale moyennant des frais.
La plus grande base de données d'adresses en anglais peut être appelée : http://www.lookup.com/ -

En entrant dans ces sous-répertoires, l'utilisateur découvre des liens vers des sites qui proposent des informations qui l'intéressent.

Nous ne connaissons pas de bases de données d'adresses officielles et largement disponibles dans la Fédération de Russie.
2.6 Recherche dans les archives Gopher
Gopher est un système de serveurs interconnectés (espace Gopher) distribué sur Internet.
La bibliothèque littéraire la plus riche est rassemblée dans l'espace Gopher, mais les matériaux ne sont pas disponibles pour une visualisation à distance : l'utilisateur ne peut visualiser qu'une table des matières organisée hiérarchiquement et sélectionner un fichier par son nom. À l'aide d'un programme spécial (Veronica), une telle recherche peut être effectuée automatiquement, à l'aide de requêtes basées sur des mots-clés.
Jusqu'en 1995, Gopher était la technologie la plus dynamique sur Internet, la croissance du nombre de serveurs associés dépassant la croissance de tous les autres types de serveurs Internet. Les serveurs Gopher n'ont pas été activement développés dans le réseau EUnet / Relcom, et aujourd'hui, presque personne ne s'en souvient.
2.7 Système de recherche FTP
Le moteur de recherche de fichiers FTP est un type particulier de moteur de recherche Internet qui permet de trouver des fichiers disponibles sur des serveurs FTP « anonymes ». FTP est conçu pour transférer des fichiers sur un réseau, et en ce sens, c'est fonctionnellement une sorte d'analogue de Gopher.
Le critère de recherche principal est le nom de fichier donné par différentes façons(correspondance exacte, sous-chaîne, regex, etc.). Ce type de recherche, bien sûr, ne peut pas rivaliser avec les moteurs de recherche en termes de capacités, car le contenu des fichiers n'est pas pris en compte dans la recherche et les fichiers, comme vous le savez, peuvent recevoir des noms arbitraires. Néanmoins, si vous avez besoin de trouver un programme ou une description bien connu de la norme, alors avec un degré de probabilité élevé, le fichier qui le contient aura un nom approprié, et vous pouvez le trouver en utilisant l'un des serveurs de recherche FTP :

FileSearch recherche les fichiers sur les serveurs FTP par les noms des fichiers et des répertoires eux-mêmes. Si vous recherchez un programme ou autre chose, vous trouverez probablement leurs descriptions sur les serveurs WWW, et à partir des serveurs FTP, vous pouvez les télécharger vous-même.
2.8 Moteur de recherche de conférence Usenet News
USENET NEWS est un système de téléconférence pour la communauté Internet. En Occident, ce service est généralement appelé news. Les "échos" du réseau FIDO sont un proche analogue des téléconférences.
Du point de vue d'un abonné à une téléconférence, USENET est un babillard qui contient des sections où vous pouvez trouver des articles sur tout, de la politique au jardinage. Ce babillard est accessible via un ordinateur, semblable à un courrier électronique. Sans quitter votre ordinateur, vous pouvez lire ou publier des articles dans l'une ou l'autre conférence, trouver des conseils utiles ou participer à des discussions. Naturellement, les articles occupent de l'espace sur les ordinateurs, ils ne sont donc pas stockés pour toujours, mais sont périodiquement détruits, libérant de l'espace pour de nouveaux. À l'échelle mondiale meilleur service Le serveur de Google Groups (Google Inc.) est utilisé pour trouver des informations dans les groupes de discussion Usenet.
Google Groupes est une communauté en ligne gratuite et un service de groupe de discussion qui offre la plus grande archive de messages Usenet sur Internet (plus d'un milliard de messages). Pour plus d'informations, veuillez visiter http://groups.google.com/intl/ru/googlegroups /tour/index.html

Parmi les russophones, le système de serveur Worldwide USENET et les téléconférences Relcom se démarquent. Tout comme dans d'autres services de recherche, l'utilisateur tape une chaîne de requête et le serveur génère une liste de conférences contenant des mots-clés. Ensuite, vous devez vous abonner aux conférences sélectionnées dans le programme d'actualités. Il existe également un serveur russe similaire FidoNet Online : les conférences Fido sur le WWW.
2.9 Méta-moteurs de recherche
Pour recherche rapide dans les bases de plusieurs moteurs de recherche à la fois, mieux vaut se tourner vers les méta-moteurs de recherche.
Les méta-moteurs de recherche sont des moteurs de recherche qui envoient votre requête à un grand nombre de moteurs de recherche différents, puis traitent les résultats obtenus, suppriment les adresses de ressources en double et représentent un éventail plus large de ce qui est présenté sur Internet.
Le moteur de méta-recherche le plus populaire au monde est Search.com.

Le moteur de recherche combiné Search.com de CNET, Inc. comprend près de deux douzaines de moteurs de recherche, dont les liens regorgent de tout Internet.
Avec l'aide de ce type d'outils de recherche, l'utilisateur peut rechercher des informations dans une variété de moteurs de recherche, cependant, le côté négatif de ces systèmes peut être appelé leur instabilité.
2.10 Systèmes de recherche de personnes
Les systèmes de recherche de personnes sont des serveurs spéciaux qui vous permettent de rechercher des personnes sur Internet, l'utilisateur peut spécifier le nom complet. personne et obtenez son adresse e-mail et son URL. Cependant, il convient de noter que les moteurs de recherche de personnes prennent principalement des informations sur adresses mailà partir de sources ouvertes telles que les groupes de discussion Usenet. Parmi les systèmes de recherche de personnes les plus connus, citons :
Rechercher des adresses e-mail

dans les colonnes spéciales de la recherche d'informations de contact (Prénom. Ville, Nom, Numéro de téléphone), vous pouvez trouver les informations qui vous intéressent.

Les moteurs de recherche de personnes sont vraiment gros serveurs, leurs bases de données contiennent environ 6 000 000 d'adresses.
3. Conclusion
Nous avons examiné les principales technologies de recherche d'informations sur Internet et présenté en termes généraux les outils de recherche qui existent actuellement sur Internet, ainsi que la structure des requêtes de recherche pour les moteurs de recherche russophones et anglophones les plus populaires et , résumant ce qui précède, nous voulons noter qu'un seul schéma optimal il n'y a pas de recherche d'informations sur Internet. Selon les spécificités des informations dont vous avez besoin, vous pouvez utiliser les outils et services de recherche appropriés. Et la qualité des résultats de recherche dépend de la qualité de la sélection des services de recherche.
Dans le cas général, la recherche de la phrase de requête est effectuée sur les pages Internet, et à l'aide de certains critères et algorithmes, les résultats de la recherche sont classés et présentés à l'utilisateur. Les critères de classement les plus couramment utilisés dans moteurs de recherche sont:
- la présence des mots de la demande dans le document, leur nombre, la proximité du début du document, la proximité les uns des autres ;
- la présence de mots issus de la demande dans les titres et sous-titres des documents ;
- le nombre de références à ce document à partir d'autres documents ;
- « respectabilité » des documents référencés.
Comme le montrent les critères de classement, le véritable critère de pertinence d'un document est la présence de mots issus de la requête ( expression de recherche) - n'affecte pas de manière significative son classement dans les résultats de recherche. Cette situation entraîne une baisse de la qualité de la recherche, car les documents potentiellement plus utiles sont inévitablement poussés en fin de liste par leurs concurrents « optimisés ». En effet, beaucoup ont découvert que les ressources vraiment utiles dans les moteurs de recherche se trouvent sur la deuxième troisième page d'une requête de recherche. C'est là que se manifeste l'inefficacité des algorithmes de classement des documents trouvés. Cela est largement dû au fait que les requêtes de recherche, en moyenne, ne contiennent que trois à cinq mots, c'est-à-dire qu'il n'y a tout simplement pas assez d'informations initiales pour un classement SERP efficace.
Et voici les problèmes lors de la recherche ...
C'est là que l'efficacité à 100% des algorithmes de classement des documents trouvés ne se manifeste pas. Bien entendu, cette situation se présente également parce que les recherches des utilisateurs ne comportent en moyenne que trois à cinq mots. Autrement dit, ces informations initiales pour les moteurs de recherche sont trop rares pour un classement SERP efficace.
Le deuxième problème est de savoir comment traiter une telle quantité d'informations (= "digérer", "considérer", "mettre en évidence l'essentiel", "éliminer les inutiles et les inutiles") pour un utilisateur spécifique, en tenant compte de ses besoins, c'est-à-dire et le sujet de la demande, son historique de recherche précédent, sa situation géographique, ses opinions sur les résultats de recherche, etc. Certes, les moteurs de recherche se développent activement dans ce sens, mais force est de constater que le moteur de recherche est loin d'être parfait. Car, aujourd'hui, seule une personne peut évaluer l'utilité sémantique, la qualité, la spécificité des informations trouvées, etc.
Alternatives aux moteurs de recherche
Par conséquent, comme alternative, apparaissent des services qui structurent en quelque sorte Internet pour faciliter la recherche des informations dont l'utilisateur a besoin. Et pour le moment, il existe déjà des signets sociaux, des répertoires, des trackers torrent, des forums, des moteurs de recherche spécialisés, le partage de fichiers, etc. Tous ces services structurent à un degré ou à un autre Internet et « réduisent la distance » entre l'utilisateur et les informations dont il a besoin (qu'il s'agisse de films, de musique, de livres, de réponses à des questions, etc.). Et ce qui est le plus important, ce sont surtout les utilisateurs eux-mêmes qui « structurent Internet ».
Non, rien n'indique ici que les moteurs de recherche sont inutiles ou peu efficaces. Je crois que les moteurs de recherche sont idéaux pour trouver des informations superficielles et les plus populaires. Et pour rechercher des informations plus approfondies, y compris livres utiles, articles, magazines, musique, etc. (c'est-à-dire avec la possibilité de télécharger tout cela) les ressources précitées "structurant Internet" sont plus adaptées.
Comment ne pas du tout se perdre sur Internet ?

Brièvement:
1.Pour rechercher des informations de surface, utilisez les moteurs de recherche, par exemple http://google.com, http://yandex.ru, http://nigma.ru, http://nibbo.com
2.Pour rechercher des sites pertinents au sujet, utilisez des annuaires Internet, par exemple,
Trouver les informations dont vous avez besoin sur Internet est souvent difficile. L'Internet se développe de manière chaotique, il n'y a pas de structure clairement définie. Personne ne peut garantir que sur un domaine il n'y aura que des informations sur un certain sujet, et sur l'autre - des informations sur un autre, mais aussi sur un sujet clairement défini. Par exemple, sur les domaines .com, vous pouvez trouver non seulement des informations commerciales, mais, par exemple, diverses documentations sur produits logiciels voire des anecdotes.
Si la structure du domaine était similaire à la structure du répertoire, par exemple, dans le domaine ru.comp.os.linux (comme dans le système de nouvelles), il y aurait toutes les informations sur le fonctionnement Système Linux en russe et certaines organisations de modérateurs ont veillé à ce que les informations sur Linux ne soient pas publiées dans d'autres domaines, la recherche serait alors beaucoup plus facile. Après tout, nous saurions où chercher. Vous ouvrez votre navigateur, entrez ru.comp.os.linux et vous obtenez ... des millions de liens différents vers des articles, des HOWTO et d'autres informations liées à Linux d'une manière ou d'une autre.
Efficacité de la recherche
- L'efficacité de la recherche dépend de nombreux facteurs :
- De l'information elle-même - il peut y avoir beaucoup d'informations sur un sujet, mais peu sur un autre. Parfois, vous pouvez trouver beaucoup d'informations sur un sujet donné, mais l'efficacité de cette recherche s'avérera proche de 0,0%, mais vous ne pourrez trouver que 3-4 liens, et ce sera exactement ce dont vous avez besoin. Cela inclut également la capacité du webmaster à soumettre correctement les informations afin que les moteurs de recherche eux-mêmes puissent les trouver. Supposons que quelque part très loin se trouve l'information dont vous avez besoin, mais que le moteur de recherche n'en sache rien. Peut-être que l'information vient d'être publiée ou que l'éditeur qui a publié l'information n'est même pas au courant de l'existence de moteurs de recherche. Vous recherchez des informations à l'aide d'un moteur de recherche. Si elle ne "connaît" pas les informations dont vous avez besoin, alors, par conséquent, vous ne saurez rien d'elle non plus.
- D'un moteur de recherche - il existe de nombreux moteurs de recherche et ils sont tous différents. Même s'ils appartiennent au même type (nous parlerons des types de moteurs de recherche un peu plus loin), sans aucun doute, chacun d'eux aura son propre algorithme. Si vous ne pouvez pas trouver d'informations à l'aide d'un moteur de recherche, essayez de les rechercher à l'aide d'un autre. Ne vous attardez pas sur un seul moteur de recherche, même si vous l'aimez.
- Cela dépend beaucoup de la capacité à utiliser un moteur de recherche - de la façon dont vous êtes capable d'utiliser un moteur de recherche. Si vous ne savez pas comment utiliser un moteur de recherche, il est peu probable que la recherche soit efficace.
Comment rechercher des informations correctement
Comme le plus souvent vous ne sélectionnez pas le site dont vous avez besoin dans l'annuaire du moteur de recherche, mais entrez un mot-clé spécifique (ou plusieurs mots-clés), alors vous devez spécifier ce mot-clé le plus précisément possible. Plus vous définissez le sujet de votre recherche avec précision, plus le résultat sera précis. Après tout, un moteur de recherche ne peut pas deviner vos pensées, vous devez lui indiquer clairement ce que vous recherchez.
Chaque moteur de recherche a sa propre syntaxe que vous devez connaître. Ce chapitre décrira la syntaxe des moteurs de recherche Google, Yandex et Rambler. Si vous souhaitez utiliser un autre moteur de recherche, vous pouvez découvrir sa syntaxe sur son propre site Web (généralement elle est décrite en détail).
Moteurs de recherche Internet
Parlons maintenant des moteurs de recherche eux-mêmes.
Sur le territoire de l'ex-CEI, les moteurs de recherche suivants sont les plus populaires, selon SpyLog (Openstat) :
- 1. Yandex (www.yandex.ru);
- 2. Google (www.google.com) ;
- 3. [email protected] (go.mail.ru);
- 3. Rambler (www.rambler.ru);
- 5. Yahoo! (www.yahoo.com);
- 6. Altavista (www.altavista.com) ;
- 7. Bing (www.bing.com).
Les moteurs de recherche sont classés par ordre décroissant de popularité. Comme vous pouvez le voir, le plus populaire d'entre nous est le moteur de recherche Yandex.
Types de moteurs de recherche
- Il existe deux principaux types de moteurs de recherche :
- index - Google, AltaVista, Rambler, HotBot, Yandex, etc.
- classification (catalogue) - Rambler, Yahoo! et etc.
Ne soyez pas surpris que le moteur de recherche Rambler soit répertorié deux fois - il s'agissait à la fois d'un index et d'une classification. Nous y reviendrons plus tard, mais pour l'instant parlons des différences entre ces deux systèmes.
Comment fonctionne un moteur de recherche d'index ? Le moteur de recherche lance un programme spécial qui scanne le contenu des serveurs web, indexant les informations : il entre dans sa base de données les mots-clés d'une page web particulière, certaines informations d'une page web.
Une brève histoire de Google
Commençons par le titre. Google est une version légèrement modifiée du mot googol (ce n'est pas pour rien qu'on l'appelle souvent "google"). À son tour, ce mot a été introduit par Milton Sirota, neveu du célèbre mathématicien Edward Kasner, puis a été popularisé dans le livre "Mathematics and the Imagination" de Kasner et Newman. Le mot "googol" affiche un nombre avec un un et 100 zéros. Le nom "Google" reflète une tentative d'organiser une énorme quantité d'informations sur le Web.
Commençons donc par le tout début. Les futurs développeurs de Google, Sergey Brin et Larry Page, se sont rencontrés en 1999 à l'université de Stanford. Ensuite, Larry avait 24 ans et Sergei en avait 23. Larry était alors étudiant à l'Université du Michigan et est venu à Stanford pour quelques jours. Sergei faisait partie d'un groupe d'étudiants censé familiariser les invités avec l'université. Dès la première rencontre, Sergei et Larry, pour le moins, se sont détestés - ils se sont disputés sur tout ce qui pouvait être discuté. Bien qu'en fin de compte, cela s'est avéré être un moment positif, car leurs opinions différentes ont conduit à la création d'un algorithme pour résoudre l'un des problèmes informatiques les plus urgents : trouver les informations nécessaires parmi un vaste éventail de données. En janvier 1996, Larry et Sergey ont commencé à travailler sur le moteur de recherche BackRub, qui était censé analyser les liens "retour" pointant vers ce site. Le travail sur ce serveur a été effectué dans un manque constant de fonds - après tout, à cette époque, Sergey et Larry étaient des étudiants diplômés de l'université - vous comprenez vous-même que les étudiants diplômés n'ont pas beaucoup de fonds. Soit dit en passant, Larry a participé pour la première fois à un projet aussi sérieux, et avant cela, il était engagé dans toutes sortes de projets « frivoles », même parfois anecdotiques, par exemple, il a construit une imprimante fonctionnelle à partir d'un ensemble Lego.
Algorithmes de recherche Google
L'interface de Google frappe par sa simplicité : un champ de saisie et deux boutons. Comme on dit, tout ingénieux est simple.
Syntaxe spéciale (étendue) de Google
En plus de la logique aux opérateurs Google vous fournit les modificateurs de recherche répertoriés dans le tableau. Les modificateurs de recherche sont appelés syntaxe spéciale Google. Prenez ce tableau au sérieux : une fois que vous essayez de rechercher quelque chose à l'aide de modificateurs, vous ne les abandonnez pas.
Modificateur d'inurl Google
Le modificateur inurl est utilisé pour rechercher l'URL spécifiée. Et contrairement au modificateur de site, qui permet de rechercher des informations uniquement sur un site ou un domaine, le modificateur inurl permet de rechercher des informations dans les sous-répertoires du site, par exemple :
inurl : siteskype-zvonim-besplatno
Le modificateur inurl vous permet d'utiliser le caractère * pour spécifier un domaine, par exemple :
inurl : "* .redhat.com"
Il est plus efficace d'utiliser inurl en conjonction avec site. La prochaine requête recherchera des informations dans le domaine gidmir.ru, sur tous ses sous-domaines, à l'exception de www :
site : gidmir.ru inurl : "* .gidmir" -inurl : "www.gidmir.ru"
Langue de recherche Google
Google autorise la syntaxe mixte, c'est-à-dire une syntaxe qui utilise plusieurs modificateurs de recherche spéciaux dans une requête. Cela vous permet d'obtenir le meilleur résultat possible.
Voici l'exemple le plus simple de syntaxe mixte :
site : ru inurl : disque
Dans ce cas, la recherche sera effectuée sur les sites du domaine, et l'URL doit contenir le mot disc.
Voici un autre exemple :
site : ru -inurl : org.ua
La recherche sera effectuée sur les sites du domaine ru, mais les résultats de la recherche ne contiendront pas de pages situées sur org.ua.
Recherches Google
Pour la plupart des particuliers Utilisateurs de Google la limite de 10 touches n'est pas perceptible. Mais les amateurs de longs termes de recherche ont probablement remarqué que Google ne prend en compte que les 10 premiers mots-clés, et tous les autres sont simplement ignorés.
Pourquoi rechercher des phrases longues ? Dans la plupart des cas, il s'agit d'extraits d'œuvres. Supposons que nous recherchions l'œuvre "Le Maître et Marguerite". Il convient de noter que la phrase-clé doit ressembler à "Maître Marguerite", car les mots et, ou, et, de, ou, I, a, le et quelques autres sont ignorés par le moteur de recherche. Si vous souhaitez forcer l'inclusion d'un de ces mots dans la recherche, faites précéder le mot d'un signe "+", par exemple + le.
La construction correcte de la requête permet de dépasser la limite de 10 mots. Les directives suivantes vous aideront non seulement à raccourcir la longueur de votre requête, mais également à améliorer vos performances de recherche globales.
Recherche Google avancée
Nous tapons dans la ligne de saisie du navigateur l'adresse - www.google.ru/advanced_search et allons à la recherche Google avancée.
Avec la recherche avancée, vous pouvez rechercher des informations de manière presque aussi flexible qu'avec les modificateurs de recherche. Pourquoi "presque" ? L'interface de recherche avancée ne donne pas accès à tous les modificateurs de recherche.

Définition des propriétés de recherche Google dans les cookies du navigateur
Je ne veux pas vous perdre la tête avec des détails techniques, alors je vais vous dire brièvement ce que sont les cookies et non, il n'y a rien pour les manger, mais comment vous devez travailler avec eux.
Imaginons que nous soyons confrontés à la tâche suivante : nous devons rédiger un rapport de visite individuel pour chaque client du site Web de notre entreprise. C'est-à-dire que pour que l'utilisateur ne voie pas le nombre total de visites, il sache exactement combien de fois il a visité notre site. Pour chaque adresse IP, vous devez conserver les enregistrements dans une table, qui est susceptible d'être volumineuse, et il s'ensuit que nous perdons du temps CPU et de l'espace disque. Il serait beaucoup plus correct de notre part d'utiliser cet espace avec plus d'avantages.
Résultat de recherche Google
Un résultat de recherche Google n'est pas simplement une collection de liens qui correspondent à des termes de recherche spécifiés. C'est quelque chose de plus qui mérite un examen séparé. Entrez le mot "rusopen" et cliquez sur le bouton Recherche Google.
En haut, on voit le nombre total de résultats (883 000 000) et le temps total que la recherche a pris, soit 0,34 seconde.
- Dans la plupart des cas, le résultat est présenté comme :
- titre de la page;
- Description de la page;
- L'URL de la page;
- taille de la page;
- date de la dernière indexation de la page ;
Recherche d'images Google
Google Images vous permet de trouver diverses images sur Internet. Bien que les images elles-mêmes ne puissent pas être indexées, les pages contenant ces images sont indexées. Entrez une description de l'image et vous obtiendrez de nombreux liens, ainsi que les images elles-mêmes, présentées sous la forme d'une galerie.
- Pour une recherche d'images plus efficace, vous devez utiliser les modificateurs de recherche suivants :
- intitle : - recherche dans le titre de la page ;
- type de fichier : - permet de spécifier le type d'image, vous pouvez spécifier les types suivants : JPEG et GIF, pas BMP, PNG, les images d'autres types ne sont pas indexées ;
- inurl : - recherche par l'URL spécifiée, par exemple inurl : www.gidmir.ru ;
- site : recherche le domaine ou le site spécifié, tel que site : com.
Services Google
Google est un moteur de recherche puissant avec plus de 3 milliards de pages. En plus des pages Web classiques, Google indexe les fichiers aux formats Word, Excel, PowerPoint, PDF et RTF. Vous pouvez également utiliser Google pour rechercher des images et des numéros de téléphone par Google Images et Phonebook, respectivement. Dans cet article, nous parlerons des services spéciaux de Google.
Courriel Google
Essayez d'utiliser la messagerie Google. Il convient de noter qu'il ne s'agit pas exactement de votre messagerie Web habituelle.
- Parmi les fonctionnalités de Gmail figurent les suivantes :
- taille de boîte aux lettres énorme - plus de 7 Go;
- au lieu de supprimer des lettres, vous pouvez les archiver - il y aura alors suffisamment d'espace pour vous pendant longtemps et vous pourrez restaurer les lettres que vous avez reçues ou envoyées il y a plusieurs années;
- la possibilité de rechercher par boites aux lettres avec l'efficacité de Google ;
- organisation pratique des lettres et des réponses : toutes les lettres et réponses forment une chaîne, facile à suivre ;
- bonne protection anti-spam ;
- adresse mémorable [email protected] ;
- interface conviviale.
Moteur de recherche de randonneurs
L'histoire des randonneurs
Tout a commencé en 1991 dans la ville de Pushchino, dans la région de Moscou. Au cours de cette année lointaine, un groupe de personnes partageant les mêmes idées se sont réunis, parmi lesquels Dmitry Kryukov, Sergey Lysakov, Viktor Voronkov, Vladimir Samoilov, Yuri Ershov. L'intérêt général de ce groupe était Internet. Probablement, en 1991, aucun des futurs développeurs de Rambler n'imaginait qu'ils deviendraient les créateurs de l'un des moteurs de recherche les plus importants et les plus célèbres de Runet. Après tout, avant cela, ils servaient tous des appareils radiotechniques à l'Institut de biochimie et de physiologie des micro-organismes de l'Académie des sciences de Russie. En 1992, la société "Stack" est créée, dirigée par Sergei Lysakov. Le profil de l'entreprise est les réseaux locaux et Internet. Essentiellement, Stack était un fournisseur de services Internet. L'entreprise a créé un réseau intra-urbain, puis a connecté Pushchino à Moscou et, à travers celui-ci, à Internet. Soit dit en passant, il s'agissait du premier canal IP en dehors de Moscou. Et c'est en 1992 ! Maintenant, il est assez problématique de poser un canal - il y aura toujours beaucoup de nuances, mais les câbles devaient alors être posés indépendamment, manuellement, sous terre, et tout cela a été fait en hiver.
Comment fonctionnait la recherche Rambler
Internet est en constante évolution : le nombre de sites et leur taille augmentent chaque jour. Après tout, imaginez : les grands sites sont mis à jour chaque jour, même si le volume de mises à jour est de 1024 octets (1 Ko), alors si nous supposons qu'il y a 10 000 de tels sites, chaque jour un moteur de recherche doit en traiter (indexer) 10 000 Ko (environ 10 Mo ) d'informations. Le nombre 10 000 est pris "du plafond" - par exemple. Il peut être supérieur ou inférieur - même les grands sites ne sont pas mis à jour tous les jours. La taille de la mise à jour est également exagérée. Imaginez un site d'information et d'analyse où de nouveaux articles sont publiés presque tous les jours ou des documents d'autres sites sont réimprimés. Dans ce cas, la taille des mises à jour ne sera pas de 1 Ko, mais d'au moins 10. Ajoutez des actualités et autres informations à tout cela et il s'avère qu'avec le nombre de sites mis à jour 10 000, le moteur de recherche devrait indexer 120 Mo de texte. Et avec tout cela, le moteur de recherche doit non seulement afficher avec précision les résultats de la recherche, mais aussi le faire le plus rapidement possible pour que l'utilisateur se sente à l'aise avec. Qui veut attendre 10 minutes pour les résultats de la recherche ? J'exagère bien sûr, mais personnellement, je n'attendrais pas les résultats de la recherche plus de 30 secondes (à partir du moment où vous cliquez sur le bouton Rechercher jusqu'à ce que les dix premiers résultats apparaissent). Il s'avère que les développeurs du moteur de recherche doivent constamment maintenir au bon niveau non seulement le "matériel", qui devrait être capable de traiter des volumes d'informations en constante augmentation, mais les "mathématiques" ne peuvent pas être prises avec un seul matériel. Il est nécessaire d'améliorer constamment les algorithmes de recherche afin qu'avec une augmentation du volume de la base de recherche, le temps de recherche n'augmente pas (je veux dire une augmentation significative du temps - cela ne fait aucune différence pour l'utilisateur combien de temps la recherche sera effectué pendant 2,5 secondes ou 2,0555 secondes, car il n'est pas en mesure d'estimer ce temps).
Requêtes Rambler, syntaxe Rambler
Une demande à Rambler peut consister en un ou plusieurs mots et la demande peut contenir des signes de ponctuation. Les développeurs de Rambler ont conçu leur moteur de recherche pour un maximum de confort d'utilisation. Rambler pourrait être utilisé même par un utilisateur inexpérimenté qui n'est pas du tout familier avec le langage de requête. Tout ce qu'il avait à faire était d'entrer une requête composée de plusieurs mots (par exemple, une phrase) et sans signes de ponctuation - Rambler lui-même a trouvé les documents nécessaires, et il l'a fait aussi efficacement que possible. Bien sûr, si le langage de requête était utilisé correctement, l'efficacité augmentait considérablement, mais même avec une ignorance totale du langage de requête, l'efficacité de la recherche était à un niveau élevé. Comme déjà indiqué, la connaissance du langage de requête est dans votre meilleur intérêt, vous pouvez simplement trouver les informations dont vous avez besoin beaucoup plus rapidement.
Moteur de recherche Yandex (Яindex)
Référence historique
En 1990, le développement de logiciels de recherche a commencé dans la société Arcadia, dirigée par Arkady Borkovsky et Arkady Volozh. Six ans plus tard, le site Yandex est apparu. Mais que s'est-il passé pendant ces six années ?
En deux ans, deux systèmes de recherche documentaire ont été créés - "Classification internationale des inventions" et "Classificateur de biens et services". Les deux systèmes fonctionnaient sous DOS et permettaient de rechercher un mot dans un dictionnaire donné à l'aide d'opérateurs logiques.
En 1993, Arcadia est devenue une division de CompTek. En 1993-1994, les technologies de recherche ont été considérablement améliorées, par exemple, un dictionnaire qui propose une recherche tenant compte de la morphologie de la langue russe n'occupait que 300 Ko, ce qui signifie qu'il était librement placé dans RAM, et le travail avec lui a été très rapide. Sur la base de cette nouvelle technologie, en 1994, le "Bible Computer Directory" a été créé - un système de recherche d'informations qui fonctionne avec les traductions de l'Ancien et du Nouveau Testament.
Recherche de langue Yandex
Comment le moteur de recherche interprétera-t-il le mot que vous avez saisi ?
- Maintenant, nous allons parler de ceci :
- Règle 1. Il s'avère que le système l'interprète selon les règles de la langue russe. Exemple : Si vous avez entré le mot "voiture", vous obtiendrez également des résultats contenant les mots "voitures", "voiture", etc. Il en va de même pour les verbes - sur demande "aller", vous recevrez des documents contenant les mots "aller", "aller", "marcher", "marcher", etc. Comme vous pouvez le voir, le moteur de recherche est plus intelligent que vous ne le pensiez - ce n'est pas seulement un moyen de trouver un mot spécifique dans une base de données.
- Règle 2. Une attention particulière est portée aux mots écrits avec une majuscule. Si un mot est en majuscule et n'est pas le premier d'une phrase, seuls les mots en majuscule seront trouvés. Sinon, des mots avec des majuscules et des minuscules seront trouvés. Exemple : sur demande "Teckel A." des documents contenant à la fois "teckel" (payant) et "teckel" (nom de famille) seront trouvés, puisque le mot "teckel" est écrit avec une majuscule, mais c'est le premier dans la phrase. Mais sur la demande "A. Taxa" on trouvera des documents ne contenant que le mot "Taxa", écrit avec une majuscule.
Syntaxe Yandex
Par défaut, Yandex utilise l'opérateur logique ET. Cela signifie que si vous avez entré la requête "Samsung TV", vous recevrez dans les résultats des documents dans lesquels les mots "TV" et "Samsung" se trouveront dans la même phrase. Si vous souhaitez spécifier explicitement l'opérateur AND, utilisez le caractère &. En d'autres termes, la requête "Samsung TV" est la même que la requête "TV & Samsung". Vous pouvez également utiliser la requête "TV + Samsung".
Si vous voulez l'effet inverse, c'est-à-dire si vous souhaitez obtenir des documents dans lesquels il y a un mot séparé "TV" et un mot séparé "Samsung", alors vous devez utiliser l'opérateur OU (|), par exemple : "TV | Samsung".
Syntaxe de requête Yandex
Yandex numérote tous les mots du texte du document dans l'ordre. La distance entre les mots adjacents est 1 (pas 0 !), Et la distance entre les mots dans l'ordre inverse est -1. Idem pour les offres.
Pour indiquer la distance entre les mots, le signe / est mis, suivi immédiatement d'un nombre, ce qui signifie qu'il s'agit de la distance entre les mots. Par exemple, la requête "développeur / 2 programmes" trouvera les documents contenant les mots "développeur" et "programmes", et la distance entre les mots ne doit pas dépasser deux mots et tous ces mots doivent être dans une phrase. Dans ce cas, les documents contenant « développeur d'applications », « développeur de logiciels système », etc. seront trouvés.
Si nous connaissons exactement la distance et l'ordre des mots, alors nous pouvons utiliser la syntaxe / + n. Par exemple, la requête "rouge / + 1 casquette" donnera un résultat où le mot "casquette" suit immédiatement le mot "rouge". La requête "petit chaperon rouge" conduirait au même résultat.
Opérateurs de recherche Yandex
Les crochets sont utilisés pour représenter une expression entière dans une requête. Par exemple, la requête "(historique | technologie | programmes) / + 1 Linux" trouvera des documents contenant l'une des phrases "historique Linux", "technologie Linux", " Programmes Linux".
Zones
La zone est l'endroit où trouver les informations dont vous avez besoin. Vous pouvez spécifier la zone dans laquelle vous souhaitez effectuer la recherche - titres (Title zone), liens (ancres) ou adresse (Address). Vous pouvez également utiliser la zone tous pour rechercher dans l'ensemble du document.
Syntaxe : $ requête nom_zone.
Par exemple : la requête $ title "(! LANG : Microsoft" найдет все документы, в заголовках которых встречается точная фраза "Microsoft".!}
Capacités de recherche supplémentaires Yandex
Le moteur de recherche Google permettait de limiter le site de recherche à une certaine liste de serveurs, ou, à l'inverse, d'exclure certains serveurs de la liste de recherche. Exactement les mêmes capacités sont disponibles dans le moteur de recherche Yandex. Vous pouvez également rechercher des documents contenant des liens vers des URL ou des images spécifiques. Lorsque vous spécifiez un masque pour un fichier (par exemple, une image), vous pouvez utiliser le symbole *, qui signifie tous les caractères, par exemple : "audi- *".
La syntaxe est : # item_name = ”valeur”.
cViatcheslav Tikhonov, novembre 2000atomzone.hypermart.net
1. Introduction
2. Moteurs de recherche
2.1. Comment fonctionnent les moteurs de recherche 2.2. Revue comparative des moteurs de recherche
3. Rechercher des robots
3.1. Utilisation de robots de recherche
3.1.1. Analyse statistique 3.1.2. Au service de l'hypertexte 3.1.3. Mise en miroir 3.1.4. Recherche de ressources 3.1.5. Utilisation combinée
3.2. Coûts accrus et dangers potentiels lors de l'utilisation de robots de recherche
3.2.1 Ressource réseau et charge serveur 3.2.2 Mise à jour des documents
3.3. Robots / agents clients
3.3.1 Mauvaises implémentations logicielles des robots
4.1. Détermination par le robot des informations à inclure/exclure 4.2. Le format de fichier est /robots.txt. 4.3. Enregistrements du fichier /robots.txt 4.4. Commentaires au format étendu. 4.5. Détermination de l'ordre de circulation à travers le Réseau 4.6. Résumer les données
5. Conclusion
1. Introduction
Les principaux protocoles utilisés sur Internet (ci-après également le Réseau) ne sont pas dotés de fonctions de recherche intégrées suffisantes, sans parler des millions de serveurs qui s'y trouvent. Le protocole HTTP utilisé sur Internet n'est bon que pour la navigation, qui n'est considérée que comme un moyen de visualiser des pages, pas de les trouver. Il en va de même pour FTP, qui est encore plus primitif que HTTP. Avec la croissance rapide des informations disponibles sur le Web, les méthodes de navigation par navigation atteignent rapidement leur limite de fonctionnalité, sans parler de la limite de leur efficacité. Sans préciser de chiffres précis, on peut dire qu'il n'est plus possible d'obtenir immédiatement les informations nécessaires, car il existe aujourd'hui des milliards de documents sur le Web et tous sont à la disposition des internautes, de plus, aujourd'hui leur nombre augmente selon une dépendance exponentielle. Le nombre de changements auxquels ces informations ont été soumises est énorme et, surtout, ils se sont produits dans un laps de temps très court. Le problème principal est qu'un seul système fonctionnel il n'y a jamais eu de mise à jour et de saisie d'un tel volume d'informations accessibles simultanément à tous les internautes du monde entier. Afin de structurer les informations accumulées sur Internet et de fournir à ses utilisateurs des moyens pratiques de trouver les données dont ils ont besoin, des moteurs de recherche ont été créés.
2. Moteurs de recherche
Les moteurs de recherche ont généralement trois composants :
un agent (araignée ou robot d'exploration) qui parcourt le Web et recueille des informations ;
une base de données qui contient toutes les informations collectées par les araignées ;
un moteur de recherche que les gens utilisent comme interface pour interagir avec la base de données.
2.1 Comment fonctionnent les moteurs de recherche
Des outils de recherche et de structuration, parfois appelés moteurs de recherche, sont utilisés pour aider les gens à trouver les informations dont ils ont besoin. Les outils de recherche tels que les agents, les araignées, les robots d'exploration et les robots sont utilisés pour collecter des informations sur les documents sur Internet. il programmes spéciaux qui recherchent des pages sur le Web, extraient les liens hypertextes sur ces pages et indexent automatiquement les informations qu'ils trouvent pour construire la base de données. Chaque moteur de recherche a son propre ensemble de règles régissant la façon de collecter des documents. Certains suivent chaque lien sur chaque page qu'ils trouvent, puis, à leur tour, explorent chaque lien sur chaque nouvelle page, et ainsi de suite. Certaines personnes ignorent les liens qui mènent à des fichiers graphiques et sonores, des fichiers d'animation ; d'autres ignorent les références à des ressources telles que les bases de données WAIS ; d'autres sont invités à parcourir les pages les plus populaires en premier.
Les agents sont les moteurs de recherche les plus intelligents. Ils peuvent faire plus que simplement rechercher : ils peuvent même exécuter des transactions en votre nom. Déjà, ils peuvent rechercher des sites sur un sujet spécifique et renvoyer des listes de sites triés par leur fréquentation. Les agents peuvent traiter le contenu des documents, rechercher et indexer d'autres types de ressources, pas seulement des pages. Ils peuvent également être programmés pour récupérer des informations à partir de bases de données préexistantes. Quelles que soient les informations que les agents indexent, ils les renvoient à la base de données du moteur de recherche.
La recherche générale d'informations sur le Web est effectuée par des programmes appelés araignées. Les araignées rapportent le contenu du document trouvé, l'indexent et extraient les informations récapitulatives. Ils examinent également les en-têtes, certains liens et envoient les informations indexées à la base de données du moteur de recherche.
Les robots d'exploration regardent les en-têtes et ne renvoient que le premier lien.
Les robots peuvent être programmés pour suivre divers liens de différentes profondeurs d'imbrication, effectuer une indexation et même vérifier les liens dans un document. En raison de leur nature, ils peuvent se retrouver coincés dans des boucles, ils ont donc besoin de ressources Web importantes pour suivre les liens. Cependant, il existe des méthodes conçues pour empêcher les robots de rechercher sur des sites dont les propriétaires ne souhaitent pas qu'ils soient indexés.
Les agents récupèrent et indexent divers types d'informations. Certains, par exemple, indexent chaque mot d'un document rencontré, tandis que d'autres n'indexent que les 100 mots les plus importants de chacun, indexent la taille du document et le nombre de mots qu'il contient, le titre, les en-têtes et les sous-titres, etc. Le type d'index construit détermine quelle recherche peut être effectuée par le moteur de recherche et comment les informations résultantes seront interprétées.
Les agents peuvent également naviguer sur Internet et trouver des informations, puis les mettre dans la base de données du moteur de recherche. Les administrateurs de moteurs de recherche peuvent déterminer quels sites ou types de sites les agents doivent visiter et indexer. Les informations indexées sont envoyées à la base de données du moteur de recherche de la même manière que décrit ci-dessus.
Les gens peuvent soumettre des informations directement à l'index en remplissant un formulaire spécifique pour la section dans laquelle ils souhaitent soumettre leurs informations. Ces données sont transférées dans la base de données.
Lorsqu'une personne souhaite trouver des informations disponibles sur Internet, elle visite une page de moteur de recherche et remplit un formulaire détaillant les informations dont elle a besoin. Des mots clés, des dates et d'autres critères peuvent être utilisés ici. Les critères du formulaire de recherche doivent correspondre aux critères utilisés par les agents lors de l'indexation des informations qu'ils trouvent en surfant sur le Web.
La base de données récupère l'objet de la requête sur la base des informations fournies dans le formulaire rempli et sort les documents correspondants préparés par la base de données. La base de données utilise un algorithme de classement pour déterminer l'ordre dans lequel la liste des documents sera affichée. Idéalement, les documents les plus pertinents pour la requête de l'utilisateur seront placés en premier dans la liste. Différents moteurs de recherche utilisent différents algorithmes de classement, mais les principes de base pour déterminer la pertinence sont les suivants :
Le nombre de mots de requête dans le contenu textuel du document (c'est-à-dire dans le code html).
Balises dans lesquelles se trouvent ces mots.
L'emplacement des mots de recherche dans le document.
La proportion de mots pour lesquels la pertinence est déterminée dans le nombre total de mots du document.
Ces principes sont appliqués par tous les moteurs de recherche. Et ceux présentés ci-dessous sont utilisés par certains, mais assez connus (comme AltaVista, HotBot).
Temps - combien de temps la page a été dans la base de données du moteur de recherche. Au début, il semble que ce soit un principe plutôt dénué de sens. Mais, si vous pensez au nombre de sites qui existent sur Internet et qui durent un mois maximum ! Si le site existe depuis assez longtemps, cela signifie que le propriétaire est très expérimenté sur ce sujet et que l'utilisateur est plus approprié pour un site qui diffuse au monde sur les règles de comportement à table depuis quelques années que celui qui est paru il y a une semaine avec le même sujet.
Citation Index - combien de liens vers une page donnée mènent à partir d'autres pages enregistrées dans la base du moteur de recherche.
La base de données génère une liste de documents HTML classés de manière similaire et la renvoie à la personne qui fait la demande. Divers moteurs de recherche choisissent également différentes façons afficher la liste résultante - certains affichent uniquement des liens ; d'autres affichent des liens avec les premières phrases contenues dans le document, ou le titre du document avec un lien.
2.2 Aperçu comparatif des moteurs de recherche
Lycos ... Lycos utilise le mécanisme d'indexation suivant :
mots dans Titre les en-têtes ont la priorité la plus élevée ;
mots au début de la page;
Comme la plupart des systèmes, Lycos propose une requête simple et une méthode de recherche plus sophistiquée. Dans une requête simple, une phrase en langage naturel est saisie comme critère de recherche, après quoi Lycos normalise la requête en en supprimant les mots dits vides, et alors seulement commence son exécution. Presque immédiatement, des informations sur le nombre de documents par mot sont affichées, puis une liste de liens vers des documents formellement pertinents. La liste contre chaque document indique sa mesure de proximité à la requête, le nombre de mots de la requête qui sont entrés dans le document et la mesure de proximité estimée, qui peut être calculée de manière plus ou moins formelle. Bien que vous ne puissiez pas entrer d'opérateurs logiques dans une ligne avec des termes, vous pouvez utiliser la logique via le système de menu Lycos. Cette opportunité est utilisée pour construire un formulaire de demande avancé destiné aux utilisateurs avertis qui ont déjà appris à travailler avec ce mécanisme. Ainsi, on voit que Lycos appartient à un système avec un langage de requête de type « Like this », mais il est prévu de l'étendre à d'autres modes d'organisation des prescriptions de recherche.
AltaVista ... L'indexation dans ce système est effectuée par un robot. Dans ce cas, le robot a les priorités suivantes :
phrases clés au début de la page;
phrases clés par le nombre d'occurrences de phrases de mots ;
S'il n'y a pas de balises sur la page, il utilise les 30 premiers mots, qu'il indexe et affiche à la place de la description (description de la balise)
La caractéristique la plus intéressante d'AltaVista est sa recherche avancée. Il convient de noter tout de suite que, contrairement à de nombreux autres systèmes, AltaVista prend en charge l'opérateur NOT unique. En outre, il existe également l'opérateur NEAR, qui implémente la capacité de recherche contextuelle lorsque les termes doivent être placés côte à côte dans le texte du document. AltaVista permet de rechercher des phrases clés, alors qu'il dispose d'un dictionnaire phraséologique assez volumineux. Entre autres, lors de la recherche dans AltaVista, vous pouvez spécifier le nom du champ où le mot doit apparaître : lien hypertexte, applet, nom de l'image, titre et plusieurs autres champs. Malheureusement, la procédure de classement n'est pas décrite en détail dans la documentation du système, mais on peut voir que le classement est appliqué à la fois pour une recherche simple et pour une requête étendue. En réalité, ce système peut être classé comme un système avec une recherche booléenne étendue.
Yahoo . Ce système est apparu sur le Web l'un des premiers, et aujourd'hui Yahoo coopère avec de nombreux fabricants de fonds récupération de l'information, et différents logiciels sont utilisés sur ses différents serveurs. Le langage de Yahoo est assez simple : tous les mots doivent être saisis séparés par un espace, ils sont reliés par un lien ET ou OU. Lors de l'émission, le degré de conformité du document avec la demande n'est pas indiqué, mais seuls les mots de la demande qui se trouvent dans le document sont soulignés. Dans le même temps, le vocabulaire n'est pas normalisé ou analysé pour les mots « communs ». De bons résultats de recherche ne sont obtenus que lorsque l'utilisateur sait que l'information se trouve à coup sûr dans la base de données Yahoo. Le classement est basé sur le nombre de termes de requête dans le document. Yahoo appartient à la classe des systèmes traditionnels simples avec des capacités de recherche limitées.
OpenText . Système d'Information OpenText est le produit d'information le plus commercialisé sur le Web. Toutes les descriptions ressemblent plus à des publicités qu'à des guides d'emploi informatifs. Le système vous permet de rechercher à l'aide de connecteurs logiques, mais la taille de la requête est limitée à trois termes ou expressions. Dans ce cas, nous parlons de recherche avancée. Lors de la publication des résultats, le degré de conformité du document avec la demande et la taille du document sont signalés. Le système vous permet également d'améliorer les résultats de la recherche dans le style d'une recherche booléenne traditionnelle. OpenText pourrait être classé comme un système de recherche d'informations traditionnel, si ce n'est pour le mécanisme de classement.
Recherche d'informations ... Dans ce système, le robot crée l'index, mais il n'indexe pas tout le site, mais uniquement la page spécifiée. En même temps, le robot a les priorités suivantes :
mots dans le titre Titre avoir la plus haute priorité ;
mots dans les mots-clés, balise de description et la fréquence des occurrences de répétitions dans le texte lui-même ;
en répétant les mêmes mots l'un à côté de l'autre, il le jette
Autorise jusqu'à 1024 caractères pour la balise de mots-clés, 200 caractères pour la balise de description ;
Si aucune balise n'a été utilisée, il indexe les 200 premiers mots de la page et les utilise comme description ;
Le système Infoseek dispose d'un langage de recherche d'informations assez développé, qui permet non seulement d'indiquer quels termes doivent être trouvés dans les documents, mais aussi de les peser d'une manière particulière. Ceci est réalisé à l'aide de signes spéciaux "+" - le terme doit être dans le document et "-" - le terme doit être absent du document. De plus, Infoseek permet ce qu'on appelle la recherche contextuelle. Cela signifie qu'en utilisant un formulaire de requête spécial, vous pouvez exiger une co-occurrence cohérente de mots. Vous pouvez également spécifier que certains mots doivent apparaître ensemble non seulement dans un document, mais même dans un paragraphe ou un titre séparé. Il est possible de spécifier des phrases clés qui représentent un seul tout, jusqu'à l'ordre des mots. Le classement lors de l'émission est effectué par le nombre de termes de requête dans le document, par le nombre de phrases de requête moins les mots courants. Tous ces facteurs sont utilisés comme des procédures imbriquées. Pour résumer brièvement, on peut dire qu'Infoseek appartient aux systèmes traditionnels avec un élément de pondération des termes lors de la recherche.
WAIS ... WAIS est l'un des moteurs de recherche les plus sophistiqués sur Internet. Seules la recherche d'ensemble flou et la recherche probabiliste n'y sont pas implémentées. Contrairement à de nombreux moteurs de recherche, le système permet non seulement de construire des requêtes booléennes imbriquées, de calculer la pertinence formelle par diverses mesures de proximité, de pondérer les termes de la requête et du document, mais également de corriger la requête par pertinence. Le système vous permet également d'utiliser la troncature des termes, de diviser les documents en zones et de gérer les index distribués. Ce n'est pas un hasard si ce système particulier a été choisi comme moteur de recherche principal pour la mise en œuvre de l'encyclopédie Britannica sur Internet.
3. Rechercher des robots
Au cours des dernières années Le World Wide Web est devenu si populaire qu'Internet est désormais l'un des principaux moyens de publier des informations. Alors que la taille du Web passait de quelques serveurs et d'un petit nombre de documents à d'énormes limites, il est devenu évident que la navigation manuelle dans une grande partie de la structure des liens hypertextes n'était plus possible, et encore moins méthode efficace recherche de ressources.
Ce problème a incité les chercheurs sur Internet à expérimenter une navigation Web automatisée appelée « robot ». Un robot Web est un programme qui navigue dans la structure hypertexte du Web, demande un document et renvoie de manière récursive tous les documents auxquels ce document fait référence. Ces programmes sont aussi parfois appelés « araignées », « vagabonds » ou « vers » et ces noms sont peut-être plus attrayants, cependant, ils peuvent être trompeurs, car les termes « araignée » et « vagabond » donnent la fausse impression que le robot se déplace lui-même et le terme "ver" peut impliquer que le robot se reproduit également comme un ver Internet. En réalité, les robots sont implémentés comme un simple système logiciel qui demande des informations à des sites distants sur Internet à l'aide de protocoles réseau standard.
3.1 Utilisation de robots de recherche
Les robots peuvent être utilisés pour effectuer de nombreuses tâches utiles telles que l'analyse statistique, la maintenance hypertexte, l'exploration de ressources ou la mise en miroir de pages. Examinons ces tâches plus en détail.
3.1.1 Analyse statistique
Le premier robot a été créé afin de détecter et de compter le nombre de serveurs web sur le web. D'autres calculs statistiques peuvent inclure le nombre moyen de documents par serveur sur le Web, les proportions de certains types de fichiers sur le serveur, la taille moyenne des pages, le degré de liaison, etc.
3.1.2 Servir l'hypertexte
L'une des principales difficultés liées au maintien d'une structure hypertexte est que les liens vers d'autres pages peuvent devenir des « liens morts » lorsqu'une page est déplacée vers un autre serveur ou supprimée complètement. À ce jour, il n'existe aucun mécanisme général qui pourrait informer le personnel de service du serveur, qui contient un document avec des liens vers une telle page, qu'il a changé ou a été complètement supprimé. Certains serveurs, tels que le CERN HTTPD, enregistreront les demandes ayant échoué causées par des liens morts ainsi qu'une recommandation pour la page où le lien mort a été trouvé, en supposant que le problème sera résolu manuellement. Ce n'est pas très pratique, et en réalité les auteurs de documents constatent que leurs documents ne contiennent des liens morts que lorsqu'ils sont notifiés directement, ou, ce qui est très rare, lorsque l'utilisateur lui-même les notifie par e-mail.
Un robot comme MOMSPIDER qui vérifie les liens peut aider l'auteur du document à trouver ces liens morts et peut également aider à maintenir la structure hypertexte. Les robots peuvent également aider à maintenir le contenu et la structure eux-mêmes en vérifiant le document HTML pertinent, sa conformité aux règles acceptées, les mises à jour régulières, etc., mais cela n'est généralement pas utilisé. Peut-être que les données Fonctionnalité devrait être intégré lors de l'écriture de l'environnement du document HTML, car ces vérifications peuvent être répétées chaque fois que le document change et tout problème peut être résolu immédiatement.
3.1.3 Mise en miroir
La mise en miroir est un mécanisme populaire pour maintenir les archives FTP. Le miroir copie récursivement l'arborescence complète des répertoires via FTP, puis redemande régulièrement les documents qui ont changé. Cela vous permet de répartir la charge sur plusieurs serveurs, de gérer avec succès les pannes de serveur et de fournir plus rapidement et moins cher accès local ainsi que l'accès hors ligne aux archives. Sur Internet, la mise en miroir peut être effectuée à l'aide d'un robot, mais au moment d'écrire ces lignes, aucun moyen sophistiqué n'existait pour cela. Bien sûr, il existe plusieurs robots qui reconstruisent le sous-arbre de la page et l'enregistrent sur le serveur local, mais ils n'ont pas les moyens de mettre à jour exactement les pages qui ont changé. Le deuxième problème est l'unicité des pages, c'est-à-dire que les liens dans les pages copiées doivent être écrasés lorsqu'ils renvoient à des pages qui ont également été mises en miroir et peuvent nécessiter une mise à jour. Ils doivent être remplacés par des copies, et lorsque les liens relatifs pointent vers des pages qui n'ont pas été mises en miroir, ils doivent être étendus aux liens absolus. Le besoin de moteurs de mise en miroir pour des raisons de performances est considérablement réduit par l'utilisation de serveurs de mise en cache sophistiqués qui offrent des mises à niveau sélectives qui peuvent garantir que le document mis en cache n'est pas mis à jour et est en grande partie égoïste. Cependant, on s'attend à ce que les installations de mise en miroir se développent comme prévu à l'avenir.
3.1.4 Recherche de ressources
L'utilisation la plus excitante des robots est peut-être l'exploration des ressources. Là où les gens ne peuvent pas traiter une énorme quantité d'informations, il est tout à fait possible de transférer tout le travail sur l'ordinateur qui semble assez attrayant. Il existe plusieurs robots qui collectent des informations sur la plupart des sites Internet et alimentent les résultats dans une base de données. Cela signifie qu'un utilisateur qui se basait auparavant uniquement sur la navigation Web manuelle peut désormais combiner la recherche avec la navigation sur les pages pour trouver les informations qu'il souhaite. Même si la base de données ne contient pas exactement ce dont il a besoin, il y a de fortes chances que cette recherche trouve de nombreux liens vers des pages, qui, à leur tour, peuvent renvoyer au sujet de sa recherche.
Le deuxième avantage est que ces bases de données peuvent être mises à jour automatiquement sur une période de temps afin que les liens morts dans la base de données soient trouvés et supprimés, contrairement à la maintenance manuelle des documents, où la vérification est souvent spontanée et incomplète. L'utilisation de robots pour l'exploration des ressources sera discutée ci-dessous.
3.1.5 Utilisation combinée
Un simple robot peut effectuer plusieurs des tâches ci-dessus. Par exemple, le robot RBSE Spider effectue une analyse statistique des documents demandés et gère une base de données de ressources. Cependant, une telle utilisation combinée est, malheureusement, très rare.
3.2 Coûts accrus et dangers potentiels lors de l'utilisation de robots de recherche
Les robots peuvent coûter cher, surtout lorsqu'ils sont utilisés à distance sur Internet. Dans cette section, nous verrons que les robots peuvent être dangereux car ils imposent des exigences trop élevées au Web.
Les robots nécessitent une bande passante de serveur importante. Premièrement, les robots fonctionnent en continu pendant de longues périodes, souvent même pendant des mois. Pour accélérer les opérations, de nombreux robots effectuent des requêtes parallèles de pages auprès du serveur, ce qui entraîne par la suite une utilisation accrue de la bande passante du serveur. Même des parties éloignées du Web peuvent ressentir la charge du réseau sur une ressource si le robot effectue un grand nombre de requêtes sur une courte période de temps. Cela peut conduire à un manque temporaire de bande passante du serveur pour les autres utilisateurs, notamment sur les serveurs à faible bande passante, car Internet ne dispose d'aucun moyen d'équilibrer la charge en fonction du protocole utilisé.
Traditionnellement, Internet était perçu comme « gratuit » car les utilisateurs individuels n'avaient pas à payer pour l'utiliser. Cependant, cela est maintenant remis en question, puisque ce sont surtout les utilisateurs en entreprise qui paient les coûts liés à l'utilisation du Web. L'entreprise peut penser que ses services aux clients (potentiels) valent l'argent payé, mais les pages automatiquement transférées aux robots ne le sont pas.
En plus de faire des demandes sur le Web, le robot fait également des demandes supplémentaires sur le serveur lui-même. Selon la fréquence à laquelle il demande des documents au serveur, cela peut entraîner une charge importante sur l'ensemble du serveur et une diminution de la vitesse d'accès des autres utilisateurs accédant au serveur. De plus, si l'ordinateur hôte est également utilisé à d'autres fins, cela peut ne pas être acceptable du tout. A titre expérimental, l'auteur a exécuté une simulation de 20 requêtes parallèles de son serveur faisant office de serveur Plexus sur un Sun 4/330. Pendant plusieurs minutes, la machine, ralentie par l'utilisation de l'araignée, était généralement inutilisable. Cet effet peut être ressenti même en demandant constamment des pages.
Tout cela montre que vous devez éviter les situations avec une demande simultanée de pages. Malheureusement, même les navigateurs modernes (par exemple Netscape) créent ce problème en demandant simultanément des images dans le document. Le protocole Web HTTP s'est avéré inefficace pour de tels transferts et de nouveaux protocoles sont en cours de développement pour lutter contre ces effets.
3.2.2 Mise à jour des documents
Comme déjà mentionné, les bases de données créées par les robots peuvent être automatiquement mises à jour. Malheureusement, il n'existe toujours pas de mécanismes efficaces pour surveiller les changements qui se produisent sur le Web. De plus, il n'y a même pas une simple requête qui pourrait déterminer lequel des liens a été supprimé, déplacé ou modifié. Le protocole HTTP fournit un mécanisme "Si-Modifié-Since" par lequel un agent utilisateur peut déterminer quand un document mis en cache est modifié en même temps qu'il demande le document lui-même. Si le document a été modifié, alors le serveur ne transférera que son contenu, puisque ce document a déjà été mis en cache.
Cet outil ne peut être utilisé par le robot que s'il maintient une relation entre les totaux qui sont récupérés du document : c'est le lien lui-même et l'horodatage lorsque le document a été demandé. Cela introduit des exigences supplémentaires pour la taille et la complexité de la base de données et n'est pas largement utilisé.
3.3 Robots / agents clients
Le chargement Web est un problème particulier avec l'application de la catégorie de robots utilisés par les utilisateurs finaux et implémentés dans le cadre d'un client Web à usage général (par exemple, Fish Search et le robot tkWWW). L'une des caractéristiques communes à ces robots est la capacité de transmettre les informations découvertes aux moteurs de recherche lorsqu'ils naviguent sur le Web. Ceci est présenté comme une amélioration des méthodes d'exploration des ressources, car plusieurs bases de données distantes sont interrogées automatiquement. Cependant, selon l'auteur, cela est inacceptable pour deux raisons. Premièrement, l'opération de recherche entraîne une charge de serveur plus importante que même une simple demande de document, donc utilisateur ordinaire il peut y avoir des inconvénients importants lorsque vous travaillez sur plusieurs serveurs avec une surcharge plus importante que d'habitude. Deuxièmement, c'est une erreur de supposer que les mêmes mots-clés sont également pertinents, syntaxiquement corrects dans la recherche, sans parler de l'optimalité pour différents socles données, et la gamme de bases de données est complètement cachée à l'utilisateur. Par exemple, une requête pour "Ford and Garage" peut être envoyée à une base de données qui stocke la littérature du XVIIe siècle, une base de données qui ne prend pas en charge les opérateurs booléens ou une base de données qui spécifie que les requêtes pour les voitures doivent commencer par le mot "voiture :" . Et l'utilisateur ne le sait même pas.
Un autre aspect dangereux de l'utilisation d'un robot client est qu'une fois qu'il a été distribué sur le Web, aucune erreur ne peut être corrigée, aucune connaissance des problèmes ne peut être ajoutée et aucune nouvelle propriété efficace ne peut l'améliorer, tout comme tous les utilisateurs ne peuvent pas par la suite mettra à niveau ce robot avec la dernière version.
L'aspect le plus dangereux, cependant, est le grand nombre d'utilisateurs potentiels de robots. Certaines personnes sont susceptibles d'utiliser un tel appareil à bon escient, c'est-à-dire en se limitant à un certain maximum de liens dans une zone connue du Web et pour une courte période de temps, mais il y a aussi des personnes qui en abusent par ignorance ou arrogance. De l'avis de l'auteur, les robots distants ne devraient pas être partagés avec les utilisateurs finaux, et heureusement, jusqu'à présent, il a été possible de convaincre au moins certains auteurs de robots de ne pas les distribuer ouvertement.
Même sans considérer le danger potentiel des robots clients, une question éthique se pose : où l'utilisation de robots peut être utile à l'ensemble de la communauté Internet pour regrouper toutes les données disponibles, et où elle ne peut pas être appliquée, puisqu'elle ne profitera qu'à un seul utilisateur.
Les « agents intelligents » et « assistants numériques », destinés à l'utilisateur final à la recherche d'informations sur Internet, sont actuellement un sujet de recherche populaire en informatique, et sont souvent considérés comme l'avenir du Web. Dans le même temps, cela peut effectivement être le cas, et il est déjà clair que l'automatisation est inestimable pour la recherche de ressources, bien que davantage de recherches soient nécessaires pour les rendre efficaces. Les robots simples contrôlés par l'utilisateur sont très loin des agents de réseau intelligents : l'agent doit avoir une idée de l'endroit où trouver certaines informations (c'est-à-dire quels services utiliser) au lieu de les rechercher aveuglément. Considérez une situation où une personne cherche une librairie ; il utilise les Pages Jaunes du quartier où il habite, trouve une liste de magasins, en sélectionne un ou plusieurs et les visite. Un robot client se rendrait dans tous les magasins de la région pour demander des livres. Sur le web, comme dans la vraie vie, cela est inefficace à petite échelle, et devrait être totalement interdit à grande échelle.
3.3.1 Mauvaises implémentations logicielles des robots
La charge du réseau et du serveur est parfois augmentée par une mauvaise implémentation logicielle, en particulier des robots récemment écrits. Même si le protocole et les liens envoyés par le robot sont corrects et que le robot gère correctement le protocole renvoyé (y compris d'autres fonctionnalités telles que la réaffectation), il existe des problèmes moins évidents.
L'auteur a observé comment plusieurs robots similaires contrôlent un appel vers son serveur. Alors que dans certains cas, les conséquences négatives ont été causées par des personnes utilisant leur site pour des tests (au lieu d'un serveur local), dans d'autres cas, il est devenu évident qu'elles étaient causées par la mauvaise écriture du robot lui-même. Dans ce cas, des demandes de pages répétées peuvent se produire s'il n'y a pas d'enregistrements de liens déjà demandés (ce qui est impardonnable), ou lorsque le robot ne reconnaît pas lorsque plusieurs liens sont syntaxiquement équivalents, par exemple, lorsque les alias DNS pour la même adresse IP sont différent. , ou lorsque les liens ne peuvent pas être traités par un robot, par exemple "foo / bar / baz.html" est équivalent à "foo / baz.html".
Certains robots demandent parfois des documents GIF et PS, qu'ils ne peuvent pas traiter et donc ignorent.
Un autre danger est que certaines zones du Web sont presque infinies. Par exemple, considérons un script qui renvoie une page avec un lien vers le bas d'un niveau. Il commencera, par exemple, par "/cgi-bin/pit/", et continuera par "/cgi-bin/pit/a/", "/cgi-bin/pit/a/a/", etc. Parce que de tels liens peuvent attirer un robot dans un piège, ils sont souvent appelés « trous noirs ».
4. Problèmes de catalogage des informations
Il est indéniable que les bases de données robotiques sont populaires. L'auteur utilise directement et régulièrement ces bases de données pour trouver les ressources dont il a besoin. Cependant, il existe plusieurs problèmes qui limitent l'utilisation de robots pour explorer les ressources sur le Web. La première est qu'il y a trop de documents ici et qu'ils changent tous de manière dynamique tout le temps.
Une mesure de l'efficacité d'une approche de recherche d'informations est le "rappel", qui contient des informations sur tous les documents pertinents qui ont été trouvés. Brian Pinkerton soutient que le rappel dans les systèmes d'indexation d'Internet est une approche parfaitement acceptable, puisque trouver des documents suffisamment pertinents n'est pas un problème. Cependant, si nous comparons l'ensemble des informations disponibles sur Internet avec les informations de la base de données créée par le robot, le retour ne peut pas être trop précis, car la quantité d'informations est énorme et change très souvent. Ainsi, en pratique, la base de données peut ne pas contenir une ressource spécifique disponible sur Internet pour le moment, et il y aura de nombreux documents de ce type, car le Web ne cesse de croître.
4.1. Détermination par le robot des informations à inclure/exclure
Le robot ne peut pas déterminer automatiquement si une page Web donnée a été incluse dans son index. De plus, les serveurs Web sur Internet peuvent contenir des documents qui ne concernent que le contexte local, des documents qui existent temporairement, etc. En pratique, les robots conservent presque toutes les informations sur l'endroit où ils ont été. Notez que même si le robot a pu déterminer si la page spécifiée doit être exclue de sa base de données, il a déjà encouru la surcharge de demander le fichier lui-même, et le robot qui décide d'ignorer un grand pourcentage de documents est très inutile. Pour tenter de remédier à cette situation, la communauté Internet a adopté le « Robot Exception Standard ». Cette norme décrit l'utilisation d'un simple fichier texte structuré disponible à un emplacement connu sur le serveur ("/robots.txt") et utilisé pour déterminer quelle partie de leurs liens doit être ignorée par les robots. Cet outil peut également être utilisé pour alerter les robots des trous noirs. Chaque type de robot peut recevoir des commandes spécifiques si l'on sait que ce robot est spécialisé dans un domaine précis. Cette norme est gratuite, mais très simple à mettre en œuvre et exerce une pression importante sur les robots pour s'y conformer.
4.2. Le format de fichier est /robots.txt.
Le fichier /robots.txt est destiné à demander à tous les robots de recherche d'indexer les serveurs d'informations tels que définis dans ce fichier, c'est-à-dire uniquement les répertoires et fichiers serveur qui ne sont PAS décrits dans /robots.txt. Ce fichier doit contenir 0 ou plusieurs enregistrements associés à un robot particulier (tel que déterminé par la valeur du champ agent_id), et indiquer pour chaque robot ou pour tous à la fois ce qu'ils N'ONT PAS besoin d'indexer. La personne qui écrit le fichier /robots.txt doit spécifier la sous-chaîne Product Token du champ User-Agent, que chaque robot envoie à la requête HTTP du serveur indexé. Par exemple, le robot Lycos actuel répond à une requête telle que le champ User-Agent :
Lycos_Spider_ (Rex) /1.0 libwww / 3.1
Si le robot Lycos ne trouve pas sa description dans /robots.txt, il fait comme bon lui semble. Un autre facteur à prendre en compte lors de la création du fichier /robots.txt est la taille du fichier. Étant donné que chaque fichier qui ne doit pas être indexé est décrit, et même pour de nombreux types de robots séparément, avec un grand nombre de fichiers qui ne doivent pas être indexés, la taille de /robots.txt devient trop importante. Dans ce cas, vous devez utiliser une ou plusieurs des méthodes suivantes pour réduire la taille de /robots.txt :
spécifier un répertoire qui ne doit pas être indexé et, par conséquent, les fichiers qui ne doivent pas être indexés doivent y être situés
créer une structure de serveur prenant en compte la simplification de la description des exceptions dans /robots.txt
spécifier une méthode d'indexation pour tous les agents_id
spécifier des masques pour les répertoires et les fichiers
4.3. Les enregistrements du fichier /robots.txt
Description générale du format d'enregistrement.
[# chaîne de commentaire NL] *
User-Agent : [[WS] + agent_id] + [[WS] * # chaîne de commentaire] ? Pays-Bas
[# chaîne de commentaire NL] *
# chaîne de commentaire NL
Interdire : [[WS] + path_root] * [[WS] * # chaîne de commentaire] ? Pays-Bas
Paramètres
Description des paramètres utilisés dans les entrées /robots.txt
[...] + Les crochets suivis d'un signe + indiquent qu'un ou plusieurs termes doivent être spécifiés en tant que paramètres. Par exemple, après "User-Agent :", un ou plusieurs agent_id peuvent être spécifiés après un espace.
[...] * Les crochets suivis de * signifient que zéro ou plusieurs termes peuvent être spécifiés comme paramètres. Par exemple, vous pouvez écrire ou non des commentaires.
[...]? Crochets suivis d'un caractère ? signifie que zéro ou un terme peut être spécifié en tant que paramètres. Par exemple, un commentaire peut être écrit après "User-Agent : agent_id".
.. | .. signifie soit ce qui est avant la ligne, soit ce qui est après.
WS l'un des caractères est un espace (011) ou une tabulation (040)
NL l'un des caractères - fin de ligne (015), retour chariot (012) ou les deux (Entrée)
User-Agent : mot-clé (les majuscules et les majuscules n'ont pas d'importance). Les paramètres sont l'agent_id des robots de recherche.
Interdire : mot-clé (pas de lettres majuscules et minuscules). Les paramètres sont des chemins complets vers des fichiers ou des répertoires non indexés.
# le début de la ligne de commentaire, chaîne de commentaire - le corps réel du commentaire.
agent_id est un nombre quelconque de caractères, à l'exclusion de WS et NL, qui définissent l'agent_id de divers robots. Le signe * identifie tous les robots à la fois.
path_root est un nombre quelconque de caractères non-WS et NL qui définissent des fichiers et des répertoires qui ne doivent pas être indexés.
4.4. Commentaires au format étendu.
Chaque enregistrement commence par la ligne User-Agent, qui décrit à quel robot de recherche cet enregistrement est destiné. Ligne suivante : Interdire. Les chemins et fichiers à ne pas indexer sont décrits ici. CHAQUE entrée DOIT avoir au moins ces deux lignes. Toutes les autres lignes sont des options. Un message peut contenir un nombre illimité de lignes de commentaires. Chaque ligne de commentaire doit commencer par un caractère #. Des lignes de commentaires peuvent être placées à la fin des lignes User-Agent et Disallow. Le # à la fin de ces lignes est parfois ajouté pour indiquer au robot que la longue chaîne agent_id ou path_root est terminée. Si plusieurs agents_ids sont spécifiés dans la ligne User-Agent, alors la condition path_root dans la ligne Disallow sera remplie de manière égale pour tous. Il n'y a aucune restriction sur la longueur des chaînes User-Agent et Disallow. Si le robot de recherche ne trouve pas son agent_id dans le fichier /robots.txt, il ignore alors /robots.txt.
Si vous ne tenez pas compte des spécificités du travail de chaque robot de recherche, vous pouvez spécifier des exceptions pour tous les robots à la fois. Ceci est réalisé en spécifiant la ligne
Si le robot d'exploration trouve plusieurs enregistrements dans le fichier /robots.txt avec une valeur agent_id correspondante, le robot est libre de choisir l'un d'entre eux.
Chaque robot déterminera l'URL absolue à lire à partir du serveur à l'aide des entrées /robots.txt. Les caractères majuscules et minuscules dans path_root DO MATTER.
Exemple 1:
User-Agent : Lycos
Interdire : /cgi-bin//tmp/
Dans l'exemple 1, le fichier /robots.txt contient deux entrées. La première s'applique à tous les robots de recherche et interdit l'indexation de tous les fichiers. Le second fait référence au robot de recherche Lycos et lorsqu'il indexe le serveur, il interdit les répertoires /cgi-bin/ et /tmp/, et autorise le reste. Ainsi, le serveur sera indexé uniquement par le système Lycos.
4.5. Détermination de l'ordre de navigation sur le Web
Déterminer comment naviguer sur le Web est un défi relatif. Étant donné que la plupart des serveurs sont organisés hiérarchiquement, la première fois que vous naviguez en profondeur à travers les liens du haut à une profondeur d'imbrication limitée, il est plus probable de trouver un ensemble de documents avec un niveau de pertinence plus élevé et des services plus rapidement que d'aller plus loin, et donc cette méthode est de loin préférable pour explorer les ressources. De plus, lorsque vous naviguez dans les liens du premier niveau d'imbrication, il est plus probable de trouver les pages d'accueil des utilisateurs avec des liens vers d'autres serveurs potentiellement nouveaux, et donc il y a une plus grande probabilité de trouver de nouveaux sites.
4.6. Résumer les données
Il est très difficile d'indexer un document arbitraire sur le Web. Les premiers robots stockaient simplement le nom et l'ancre du document dans le texte lui-même, mais les robots plus récents utilisent déjà des mécanismes plus avancés et prennent généralement en compte le contenu complet du document.
Ces méthodes sont de bonnes mesures générales et peuvent être appliquées automatiquement à toutes les pages, mais elles ne peuvent malheureusement pas être aussi efficaces que l'indexation de la page par l'auteur lui-même. HTML fournit à l'auteur d'un document un moyen d'y joindre des informations générales. Il s'agit de définir un élément tel que ". Cependant, aucune sémantique n'est définie ici pour les valeurs d'attributs spécifiques d'une balise HTML donnée, ce qui limite fortement son utilisation, et donc son utilité. Cela conduit à une faible " précision " par rapport à la nombre total de documents demandés qui sont pertinents pour une requête particulière. Y compris des fonctionnalités telles que l'utilisation d'opérateurs booléens, la recherche de poids de mots comme c'est le cas dans WAIS, ou des commentaires sur la pertinence peuvent améliorer la précision des documents, mais étant donné que les informations actuellement sur Internet est extrêmement diversifié, ce problème continue d'être grave et les moyens les plus efficaces de le résoudre n'ont pas encore été trouvés.
5. Conclusion
Cet ouvrage, bien entendu, ne prétend ni à l'exhaustivité ni à l'exactitude de sa présentation. La plupart des documents ont été tirés de sources étrangères, en particulier les critiques de Martin Koster (Martijn Koster) ont servi de base. Par conséquent, je n'exclus pas la possibilité que ce document contienne des inexactitudes liées à la fois à la traduction et au phénoménal développement rapide technologies de l'information. Cependant, j'espère toujours que cet article sera utile à tous ceux qui s'intéressent au World Wide Web, à son développement et à son avenir. Dans tous les cas, je serai heureux de recevoir des réponses sur mon travail par e-mail : [email protégé]
6. Liste de la littérature utilisée
Pavel Khramtsov "Recherche et navigation sur Internet". http://www.osp.ru/cw/1996/20/31.htm
Comment fonctionnent les outils de recherche intranet et les araignées http://linux.manas.kg/books/how_intranets_work/ch32.htm
Martijn Koster "Robots dans la toile: menace ou traitement ? "http://info.webcrawler.com/mak/projects/robots/threat-or-treat.html
Formation aux métiers de l'Internet. Expert en moteurs de recherche. http://searchengine.narod.ru/archiv/se_2_250500.htm
Andrey Alikberov "Quelques mots sur le fonctionnement des robots des moteurs de recherche". http://www.citforum.ru/internet/search/art_1.shtml