Chacun de nous se considère unique. Chacun de nous pense qu'il se connaît parfaitement. Chaque réponse du moteur de recherche à l'une de nos requêtes prouve le contraire.
Nous ne sommes pas aussi uniques que nous le pensons: des millions de personnes avant nous étaient perplexes et des millions après nous ont intrigué le moteur de recherche avec des questions presque identiques. Par contre, nous sommes trop imprévisibles: la formulation de notre demande est influencée par un grand nombre de facteurs inconscients. Et même ainsi, la demande de chacun de nous, si banale soit-elle, nécessite une approche individuelle.
En fait, tout le travail du moteur de recherche Yandex se résume en deux choses simples: comprendre ce qu’une personne veut vraiment savoir et, en quelques secondes, trouver parmi les milliards de documents sur le Web qui conviennent.
Prendre des impressions
Le système d'exploitation du moteur de recherche est quelque peu similaire à celui de la "Matrix", et le robot de recherche (le programme complexe qu'il a créé lui-même qui lui permet de prendre des décisions) est similaire à l'agent Smith.
En 1997, alors que Yandex venait juste d'ouvrir, un serveur suffisait pour le travail. Trois ans plus tard, l'entreprise louait quatre baies contenant environ 40 ordinateurs. Ces quelques dizaines et sont devenus la base du premier centre de données. Aujourd'hui, Yandex dispose d'un réseau de centres étendu, indépendant des bureaux et hébergeant plusieurs milliers de serveurs.. Photo: Yandex
Afin de ne pas chercher sur Internet au complet à chaque fois que quelqu'un a besoin d'apprendre quelque chose, le moteur de recherche effectue une partie du travail à l'avance: il vérifie ce qui se trouve sur le Web et sa position à l'aide de milliers de robots de recherche. Ils sont de deux types: basique et rapide. Le principal contourne et traite Internet dans son ensemble, et le rapide - des documents parus il y a quelques minutes, voire quelques secondes. Les programmes de robot ont pour tâche de sélectionner les informations appropriées, utiles aux utilisateurs, pour les traiter, en éliminant toutes les informations obsolètes et inutiles. À certains égards, cela ressemble au tri des déchets: papier dans un conteneur, verre dans un autre, plastique dans le troisième, déchets alimentaires dans le quatrième ...
Les informations collectées par les robots constituent ce qu’on appelle la distribution d’Internet. Il est stocké sur des milliers de serveurs Yandex et est constamment mis à jour. L'impression est similaire à une liste, qui indique à quel endroit quelles informations peuvent être trouvées. Dans cette liste, chaque mot-clé n’a pas un mot, mais des millions de «pages». Pour que toutes les mises à jour de l'impression soient accessibles aux utilisateurs, celles-ci sont transférées du référentiel vers la «recherche de base». Les données du robot principal sont transférées tous les quelques jours et d'un robot rapide - en temps réel.
Apportez de l'eau propre
En cherchant une réponse à une question dans une base de données préparée, la machine est confrontée à deux difficultés principales. La première difficulté est la langue. Avant de chercher la réponse à la question, il est important que la machine comprenne dans quelle langue le faire. Par exemple, pour une personne de langue russe à la recherche de «l’escouade du prince Igor», elle recherchera des documents contenant des informations sur l’armée. Pour l’escouade ukrainienne, elle fournira également des documents mentionnant la princesse Olga, son épouse, car "Squad". Et dans la riche langue russe, le même mot ou ses dérivés peuvent signifier différentes choses. Par exemple, le mot “acier” est l’une des formes du nom “acier” et du verbe “devenir”. La deuxième difficulté est la psychologie humaine. Lors de la saisie d'une demande, nous attendons une réponse rapide et précise, sans se soucier, bien entendu, de la cohérence du libellé de la demande avec les principes de l'analyse mathématique sur lesquels le cerveau de la machine fonctionne. Par exemple, en tapant le mot "Napoléon" dans le champ de recherche, que veut obtenir une personne: une recette pour un gâteau ou la biographie d'un empereur français, pour acheter du brandy ou pour trouver l'adresse d'un hôpital psychiatrique?
Dans de telles situations, plusieurs technologies entrent en jeu à la fois. Sous la ligne de recherche, vous pouvez donner quelques astuces précisant la requête. Choisissez ce dont vous avez besoin: "Napoléon - recettes" ou "Napoléon - Bonaparte". Si l'utilisateur ne répond pas à la demande de la machine et n'ajoute pas de mots au mot "Napoléon", la technologie "Spectrum" est utile: sans espoir d'aide, la machine recherche immédiatement des informations dans plusieurs catégories (et sur le gâteau, sur l'empereur et sur le brandy .. .) De plus, des mécanismes de personnalisation aident l’utilisateur à comprendre qu’il savait que cet utilisateur cherchait dans son ordinateur il y a un ou deux ou trois mois: si vous posez souvent la question à Yandex au sujet de la cuisson, la machine vous montrera d’abord les résultats, ce napoléon est un gâteau.
Combinaisons: clubs d'intérêts
La tâche du moteur de recherche n’est pas de sélectionner simplement les documents contenant des mots et des expressions à partir de la requête de recherche. La machine doit comprendre quels documents correspondent à nos exigences contradictoires et pourquoi ils leur correspondent. Voulons-nous obtenir des informations sur napoleon-cake, ou peut-être allons-nous dans un club de fitness au nom pathétique depuis quelques années, ou même craignons-nous des complexes de gens de petite taille. Dans tous les cas, la solution du problème nécessite une approche non triviale.
Les créateurs du programme de recherche Yandex ont trouvé cette approche, en déléguant le droit de choisir la machine. D'un côté, la machine sans âme, mais très rapide et intelligente, ne sait pas et ne veut rien savoir de nous en tant qu'individus, mais de l'autre côté, elle essaie de découvrir autant que possible chacune d'entre elles.
Outre la localisation géographique de l'utilisateur et l'analyse linguistique de ses requêtes, le moteur de recherche utilise plusieurs milliers de critères totalement obscurs pour l'homme.
L'astuce est que la machine développe et met à jour ces critères elle-même.
Il utilise simplement des données sur les préférences et le comportement des utilisateurs de millions de personnes et relie cette «moyenne arithmétique» à l'historique de nos requêtes. Les principes qui guident la "matrice" en elle-même, comparant les milliers de catégories d’intérêts qu’elle a développées, ne correspondent souvent pas à la notion humaine traditionnelle de ce que les "intérêts" peuvent être en principe. Il y en a des dizaines de milliers. Ils créent ensemble des combinaisons différentes, parfois drôles. Par exemple, l'une de ces combinaisons peut être la pertinence des résultats de la recherche par rapport aux intérêts de la personne qui distribue les tritons. Dans ce cas, une personne ne s'intéresse pas seulement aux tritons, elle les élève déjà, mais seulement pour la première année.
Évaluations Aider les mains
La «matrice», bien sûr, décide elle-même (à l'aide de mathématiques avancées) de ce qui doit être montré dans quelle séquence aux utilisateurs en fonction de dizaines de milliers de critères. Mais «Matrix» utilise également des personnes vivantes - 1 000 employés de Yandex, les soi-disant «évaluateurs», évaluent les résultats de la recherche pour une requête particulière (bien sûr, toutes les requêtes ne sont pas évaluées et cela ne se fait pas en temps réel) pour leur conformité aux attentes. utilisateur régulier: pas aussi rationnel que la machine, pas aussi précis en termes, contradictoire et émotionnel.
La promotion de sites Web avec vos propres mains est une tâche à la fois simple et stimulante. Pour une personne expérimentée dans ce sujet, le spin-up est un ensemble d’étapes simples et claires, qui se résument, dans une plus large mesure, à des actions mécaniques. Mais pour un débutant qui, hier encore, a reconnu le mot SEO et n’en a pas encore compris le sens, il est presque impossible de "vaincre" les moteurs de recherche et les concurrents.
Avant de procéder à la promotion, il est nécessaire de comprendre comment fonctionnent les moteurs de recherche Yandex et Google?. Vous pouvez considérer cet article comme une introduction à mon cours de promotion de site web "Libérez le trafic des moteurs de recherche", je vous recommande donc de le lire avant de commencer à l’étudier.
La tâche des moteurs de recherche
Internet ne cesse de croître et de se développer, évolue avec et, mais leur tâche principale reste inchangée: ils doivent aider l'utilisateur à trouver la meilleure réponse à la question qu'il a saisie dans le champ de recherche. Plus le moteur de recherche affiche des résultats de haute qualité dans les résultats de recherche, plus les gens lui font confiance. Plus les gens lui font confiance, plus il peut gagner d'argent en publicité contextuelle, mais je suis déjà passé à côté ...
Les moteurs de recherche analysent en permanence des téraoctets d'informations publiées sur des millions de pages Web, tout en essayant de déterminer quels sites méritent d'entrer dans le top du problème et quels sont les meilleurs candidats pour entrer dans l'interdiction.
Comment fonctionne le moteur de recherche?
Un moteur de recherche est un ensemble de programmes et de bases de données complexes fonctionnant selon un algorithme spécifique. Simplifié, cet algorithme peut être divisé en 3 étapes.
Étape 1. Recherche de nouvelles pages
Contrairement aux idées fausses de nombreux mannequins, les moteurs de recherche donnent des informations non pas sur les pages Internet, mais sur les pages figurant dans la base de données des moteurs de recherche. Autrement dit, si le site est inconnu de Yandex ou de Goögle, il n'apparaîtra pas dans le numéro.
La tâche du moteur de recherche à ce stade est de rechercher toutes les adresses possibles des pages sur Internet. Ce travail est effectué par le robot dit "araignée". Internet est constitué de liens, de liens et encore de liens. Cet «araignée» suit simplement divers liens, enregistrant les adresses de toutes les pages de sa base de données.
Je suis arrivé à la page principale du site, j'ai trouvé des liens vers les pages des en-têtes, des liens vers des pages contenant des articles, des fiches produits, des liens vers des fichiers ou d'autres informations sur les pages des en-têtes. Sur certaines des pages visitées d'un site, il a trouvé des liens vers d'autres sites - le moteur de recherche les examine et analyse tout ce qu'il y a trouvé.
Les fichiers robots.txt et les cartes du site Sitemap.xml aident les robots à la perfection. Ils doivent être exécutés, en particulier si le site comporte de nombreuses pages. Regardez ici, mais je vais vous parler des paramètres de Sitemap un peu plus tard.
La tâche du robot est de créer un répertoire d'adresses par type - Ville, Rue, Maison, Appartement.
Comme je l'ai déjà écrit ci-dessus, les résultats de recherche ne sont pas générés par des informations provenant de sites Internet, mais par des informations provenant d'une base de données de moteurs de recherche. Et le prochain programme du moteur de recherche est simplement engagé dans l’ajout d’informations à la base de données. Elle se rend à toutes les adresses connues des sites et des pages, en copiant leur contenu dans les magasins des moteurs de recherche.
Ce processus s'appelle l'indexation - obtenir des informations dans l'index du moteur de recherche.
Les premier et deuxième processus se déroulent de manière continue et, souvent, simultanément. La base de données d'adresses de pages et la base d'informations de ces pages sont constamment mises à jour.
En passant, au cours du processus d'indexation, les moteurs de recherche évaluent la qualité des pages et les informations de certaines d'entre elles ne sont pas incluses dans l'index. Comment le moteur de recherche pourrait-il connaître leur existence, mais pour une raison quelconque, il les considère comme inutiles pour l'utilisateur et n'ajoute donc rien au problème - il ne s'agit souvent pas de pages de contenu ou de services uniques. Comment vérifier les textes sur.
Étape 3: Détermination de la pertinence et du classement
Si ce que nous avons discuté dans les paragraphes précédents fonctionne de manière continue et indépendamment de facteurs externes (actions humaines), la troisième étape de l'algorithme des moteurs de recherche commence à n'agir que sous l'influence d'une personne.
Lorsqu'une requête est spécifiée dans un moteur de recherche, le système commence à chercher une réponse dans la base de connaissances renseignée en fonction des critères spécifiés par la personne dans la requête (comment).
Tout d’abord, le système effectue une sélection en identifiant toutes les pages pertinentes des pages connues à demander («pertinent» signifie approprié, approprié. Comment vérifier la pertinence des pages du site que j’ai écrit). Par exemple, pour la requête "achetez un frigo nord", les pages contenant les mots "acheter", "frigo", "nord" seront pertinentes. Toutes les pages contenant un ou plusieurs de ces mots tomberont dans les résultats du moteur de recherche.
La tâche suivante du moteur de recherche consiste à déterminer dans quel ordre l'utilisateur verra toutes ces pages - elles doivent être classées. De nombreux facteurs vont affecter l’ordre d’émission, mais si, d’une manière simple, l’utilisateur verra d’abord les pages contenant «acheter un réfrigérateur Nord», s’il n’y en a pas, il sera invité à «acheter un réfrigérateur» ou «réfrigérateur Nord» et à la toute fin. pages avec les mots "acheter", "réfrigérateur", "Nord".
Facteurs affectant le classement
Comme je l'ai dit plus haut, selon les responsables de Yandex, plus de 700 facteurs influencent l'ordre de positionnement des sites dans les résultats des moteurs de recherche, chiffre impressionnant et impossible à révéler tous. De plus, tous ces facteurs sont inconnus de tout référencement, car les moteurs de recherche les gardent secrets. Mais en termes généraux, ces facteurs peuvent être divisés en trois groupes.
1. Facteurs internes
Ce groupe inclut des facteurs pouvant affecter le webmaster lui-même. Ceux-ci incluent le texte lui-même, placé sur la page, son design (paragraphes, titres et autres balises) - lu. Celles-ci incluent également des images dans le texte et la conception du site lui-même. Les liens situés sur le site vers différentes pages (liens internes) renvoient également à des facteurs internes.
2. Facteurs externes
En général, ce groupe de facteurs détermine la popularité d'un site particulier en fonction d'autres ressources Internet. Cette popularité est déterminée par la quantité et la qualité des sites qui renvoient vers différentes pages de votre site, ainsi que par les références qui y sont contenues dans le texte. Les moteurs de recherche évaluent cette autorité sur un schéma complexe prenant en compte un très grand nombre de facteurs.
En outre, les moteurs de recherche attribuent divers signaux sociaux à des facteurs internes, tels que les retweets, les likes, Facebook ou Odnoklassniki (j'ai déjà expliqué comment créer des "like" dans VK gratuitement).
3. Facteurs comportementaux
Les moteurs de recherche n'étaient pas toujours en mesure de suivre le comportement des utilisateurs sur Internet. La popularité de ce groupe de facteurs a commencé à gagner relativement récemment. Divers compteurs de statistiques et barres spéciales dans les navigateurs collectent de nombreuses informations sur le comportement des personnes sur les sites Web. Selon ces données, Yandex et Google déterminent le degré d'importance des sites pour les personnes vivantes. S'il y a un faible taux de rebond sur les pages de votre site - les visiteurs restent longtemps, lisent attentivement des articles de qualité, suivent les liens internes et réalisent diverses autres tâches, ce qui signifie que les gens l'aiment et méritent d'être placés à des positions plus élevées dans les moteurs de recherche.
Pourquoi les sites d'index longs Yandex
Beaucoup d'entre vous ont fait attention au fait que l'indexation de nouvelles pages par Yandex prend généralement plus de temps que celle de Google. Cela est dû au fait que les nouvelles pages trouvées par les robots de recherche entrent d'abord dans la base de données générale des pages et qu'après avoir été traitées et filtrées, elles apparaissent dans la sortie de l'utilisateur.
Google tente de transférer en continu de nouveaux documents dans le numéro. À son tour, Yandex accumule une nouvelle page, la traite puis l'envoie au problème d'un utilisateur dans un ensemble commun. Cela se produit tous les quelques jours (en moyenne une semaine) et cette procédure de mise à jour (AP) est appelée. Presque toujours, les mises à jour ont lieu la nuit, lorsque la charge sur les serveurs du moteur de recherche est minimale.
Selon cet algorithme, une nouvelle page entre dans la base de données du moteur de recherche (cela peut prendre plusieurs jours), puis cette page attend son tour jusqu'à ce que les informations le concernant soient traitées et classées en fonction des demandes pertinentes (une autre mise à jour passe) et uniquement pour le prochain numéro de mise à jour. Le document apparaît dans l'index principal.
Ainsi, certaines pages peuvent attendre leur tour assez longtemps.
Maintenant, vous savez comment fonctionnent les moteurs de recherche et vous pouvez commencer à travailler sur vos sites. Créez une page pertinente pour votre requête, laissez le moteur de recherche l'indexer et aidez-la à classer vos pages au-dessus de ses concurrents.
Autres articles de blog utiles:

Chacun de nous se considère unique. Chacun de nous pense qu'il se connaît parfaitement. Chaque réponse du moteur de recherche à l'une de nos requêtes prouve le contraire.
Nous ne sommes pas aussi uniques que nous le pensons: des millions de personnes avant nous étaient perplexes et des millions après nous ont intrigué le moteur de recherche avec des questions presque identiques. Par contre, nous sommes trop imprévisibles: la formulation de notre demande est influencée par un grand nombre de facteurs inconscients. Et même ainsi, la demande de chacun de nous, si banale soit-elle, nécessite une approche individuelle.
En fait, tout le travail du moteur de recherche Yandex se résume en deux choses simples: comprendre ce qu’une personne veut vraiment savoir et, en quelques secondes, trouver parmi les milliards de documents sur le Web qui conviennent.
Le système d'exploitation du moteur de recherche est quelque peu similaire à celui de Matrix, et le robot de recherche (il a créé un programme de prise de décision complexe et indépendant) est similaire à Agent Smith.

En 1997, alors que Yandex venait juste d'ouvrir, un serveur suffisait pour le travail. Trois ans plus tard, l'entreprise louait quatre baies contenant environ 40 ordinateurs. Ces quelques dizaines et sont devenus la base du premier centre de données. Aujourd'hui, Yandex dispose d'un réseau de centres de succursales indépendant des bureaux et compte plusieurs milliers de serveurs. Photo: Yandex
Afin de ne pas chercher sur Internet au complet à chaque fois que quelqu'un a besoin d'apprendre quelque chose, le moteur de recherche effectue une partie du travail à l'avance: il vérifie ce qui se trouve sur le Web et sa position à l'aide de milliers de robots de recherche. Ils sont de deux types: basique et rapide. Le principal contourne et traite Internet dans son ensemble, et le rapide - des documents parus il y a quelques minutes, voire quelques secondes. Les programmes de robot ont pour tâche de sélectionner les informations appropriées, utiles aux utilisateurs, pour les traiter, en éliminant toutes les informations obsolètes et inutiles. À certains égards, cela ressemble au tri des déchets: papier dans un conteneur, verre dans un autre, plastique dans le troisième, déchets alimentaires dans le quatrième ...
Les informations collectées par les robots constituent ce qu’on appelle la distribution d’Internet. Il est stocké sur des milliers de serveurs Yandex et est constamment mis à jour. L'impression est similaire à une liste, qui indique à quel endroit quelles informations peuvent être trouvées. Dans cette liste, chaque mot-clé n’a pas un mot, mais des millions de «pages». Pour que toutes les mises à jour de l'impression soient accessibles aux utilisateurs, celles-ci sont transférées du référentiel vers la «recherche de base». Les données du robot principal sont transférées tous les quelques jours et d'un robot rapide - en temps réel.
Apportez de l'eau propre
En cherchant une réponse à une question dans une base de données préparée, la machine est confrontée à deux difficultés principales. La première difficulté est la langue. Avant de chercher la réponse à la question, il est important que la machine comprenne dans quelle langue le faire. Par exemple, pour une personne de langue russe à la recherche de «l’escouade du prince Igor», elle recherchera des documents contenant des informations sur l’armée. Pour l’escouade ukrainienne, elle fournira également des documents mentionnant la princesse Olga, son épouse, car "Squad". Et dans la riche langue russe, le même mot ou ses dérivés peuvent signifier différentes choses. Par exemple, le mot “acier” est l’une des formes du nom “acier” et du verbe “devenir”. La deuxième difficulté est la psychologie humaine. Lors de la saisie d'une demande, nous attendons une réponse rapide et précise, sans se soucier, bien entendu, de la cohérence du libellé de la demande avec les principes de l'analyse mathématique sur lesquels le cerveau de la machine fonctionne. Par exemple, en tapant le mot "Napoléon" dans le champ de recherche, que veut obtenir une personne: une recette pour un gâteau ou la biographie d'un empereur français, pour acheter du brandy ou pour trouver l'adresse d'un hôpital psychiatrique?

Dans de telles situations, plusieurs technologies entrent en jeu à la fois. Sous la ligne de recherche, vous pouvez donner quelques astuces précisant la requête. Comme, choisissez ce dont vous avez besoin: recettes Napoléon ou Napoléon - Bonaparte. Si l'utilisateur ne répond pas à la demande de la machine et n'ajoute pas de mots au mot "Napoléon", la technologie Spektr est utile: sans espoir d'aide, la machine recherche immédiatement des informations dans plusieurs catégories (à propos du gâteau, de l'empereur et du cheval yak). ..). De plus, des mécanismes de personnalisation aident l’utilisateur à comprendre qu’il savait que cet utilisateur cherchait dans son ordinateur il y a un ou deux ou trois mois: si vous posez souvent la question à Yandex au sujet de la cuisson, la machine vous montrera d’abord les résultats, ce napoléon est un gâteau.
Combinaisons: clubs d'intérêts
La tâche du moteur de recherche n’est pas de sélectionner simplement les documents contenant des mots et des expressions à partir de la requête de recherche. La machine doit comprendre quels documents correspondent à nos exigences contradictoires et pourquoi ils leur correspondent. Voulons-nous obtenir des informations sur Napoléon - un gâteau, ou peut-être allons-nous dans un club de fitness au nom pathétique depuis quelques années, ou même craignons-nous des complexes de gens de petite taille? Dans tous les cas, la solution du problème nécessite une approche non triviale.

Les créateurs du programme de recherche Yandex ont trouvé cette approche, en déléguant le droit de choisir la machine. D'un côté, la machine sans âme, mais très rapide et intelligente, ne sait pas et ne veut rien savoir de nous en tant qu'individus, mais de l'autre côté, elle essaie de découvrir autant que possible chacune d'entre elles.
Outre la localisation géographique de l'utilisateur et l'analyse linguistique de ses requêtes, le moteur de recherche utilise plusieurs milliers de critères qui ne sont absolument pas évidents pour l'homme.
L'astuce est que la machine développe et met à jour ces critères elle-même.
Il utilise simplement des données sur les préférences et le comportement des utilisateurs de millions de personnes et relie cette «moyenne arithmétique» à l'historique de nos requêtes. Les principes qui guident la matrice en elle-même, comparant les milliers de catégories d’intérêts d’utilisateur développés par celle-ci, ne correspondent souvent pas aux notions humaines traditionnelles de ce que peuvent être des «intérêts». Il y en a des dizaines de milliers. Ils créent ensemble des combinaisons différentes, parfois drôles. Par exemple, l'une de ces combinaisons peut être la pertinence des résultats de la recherche par rapport aux intérêts de la personne qui distribue les tritons. Dans ce cas, une personne ne s'intéresse pas seulement aux tritons, elle les élève déjà, mais seulement pour la première année.
Évaluations Aider les mains
La matrice, bien sûr, décide elle-même (à l'aide de mathématiques avancées) de ce qui doit être montré dans quelle séquence aux utilisateurs en fonction de dizaines de milliers de critères. Mais les personnes vivantes utilisent également la matrice - 1000 employés de Yandex, les soi-disant évaluateurs, évaluent les résultats de la recherche pour une requête particulière (bien sûr, toutes les requêtes ne sont pas évaluées et cela ne se fait pas en temps réel) pour leur conformité aux attentes de l'utilisateur moyen. : pas aussi rationnelle qu'une machine, pas aussi précise en termes, contradictoire et émotionnelle.
Ensuite, nous n’avons abordé que le processus d’ajout proprement dit, et je vous ai parlé de l’importance de spécifier le miroir principal de votre blog pour les moteurs de recherche. Voyons-le plus en détail aujourd’hui.
Tout d’abord, quel est le miroir d’un blog ou d’un site Web? Dans les moteurs de recherche, le miroir d’un site est considéré comme un affichage complet ou partiel ou, plus simplement, comme une copie d’un site.
Voyons maintenant comment cela peut affecter votre site. Par exemple, l'adresse de votre site ressemble à ceci: lors de la saisie dans la barre d'adresse du navigateur, le visiteur accède à la page principale de votre site et la même chose se produit si vous tapez. Mais les moteurs de recherche considèrent cela comme deux sites différents, mais avec le même contenu, c'est-à-dire une copie complète l'un de l'autre (double). Je pense que tout le monde comprend que tout cela peut résulter.
Par conséquent, lors de l'ajout d'un site à un moteur de recherche, il est très important d'indiquer son miroir principal, c'est-à-dire avec ou sans www.
Aucun avantage de www sur l'adresse de votre site ne donne et vient de la profondeur de la création d'un réseau mondial. Il représente le World Wide Web. Par conséquent, aujourd'hui, il ne sert à rien de l'utiliser, mais le choix vous appartient bien entendu.
Et donc, si vous avez décidé de ce que le miroir principal sera sur votre site. Vous devez le signaler aux moteurs de recherche Yandex et Google. Commençons par le premier.
Comment pointer Yandex vers le miroir du site principal
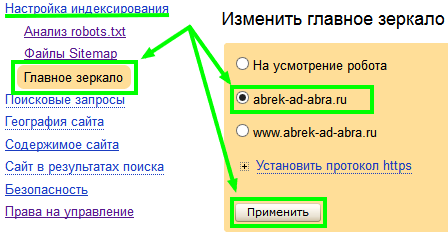
Comme vous pouvez le constater, rien n’est compliqué.
Faisons maintenant la même opération pour Google.
Et ici, vous pouvez rencontrer une difficulté, regardons de plus près.

En d’autres termes, nous devons suivre toute la procédure d’ajout d’un site à Google. Ce que nous avons fait dans le dernier article que j'ai déjà mentionné.
C’est-à-dire comment ajouter un nouveau site et si j’ai ajouté pour la dernière fois un site avec une adresse: le site, il doit maintenant être spécifié lors de l’ajout, en tant que site à partir de: www ..
Et nous passons à nouveau par toute la procédure. Dans le même temps, nous confirmons également les droits d'utilisation du domaine avec www. Bien sûr, vous n’avez pas besoin de télécharger un fichier de confirmation sur le nouveau, car nous l’avions déjà fait la dernière fois. Nous avons donc immédiatement cliqué sur Confirmer.
Et si la dernière fois nous avions un message de ce genre.
Maintenant ce sera comme ça:

Maintenant, nous revenons à la page principale des «outils pour les webmasters», sélectionnez les sites un par un, la version avec www et sans. Dans chaque cas, cliquez sur l'image sous la forme d'un engrenage, comme indiqué dans l'image ci-dessus, puis sélectionnez les paramètres du site. Où nous spécifions le miroir désiré.
Comme vous pouvez le voir, tout s’est avéré.
Pour la redirection finale vers votre site, vous devez en faire plus avec le fichier .htaccess. Nous en discuterons également dans les prochains articles. mises à jour et à bientôt!
Bonjour chers lecteurs. Aujourd'hui, je vais vous expliquer comment diriger les moteurs de recherche Yandex et Google vers le miroir du site principal.
Qu'est-ce qu'un miroir de site? Selon Yandex, le miroir est une copie partielle ou complète du site. Il y a d'autres interprétations, mais l'essence est la même: c'est très mauvais pour la promotion des moteurs de recherche.
Quel est ce genre de spécularité? Si vous essayez de saisir le domaine de votre site, par exemple: www.site.com et simplement site.com, vous accédez à la page principale dans les deux cas. Donc, pour un moteur de recherche, ce sont deux sites complètement différents avec un contenu complètement identique.
C'est-à-dire qu'il s'agit d'un double site complet. J'ai écrit à propos de divers doublons de contenu dans des articles: "et" ".
Le fait est qu'il est nécessaire de décider du miroir principal, il y aura un site avec ou sans www. En passant, les opinions sur ce sujet varient grandement, mais si vous lisez l'histoire de www, vous constaterez que www est déjà au sens littéral et figuré du siècle dernier. Je me permets de conseiller à mon lecteur d’abandonner les abréviations notoires des créateurs du World Wide Web.
L'abréviation WWW désigne le World Wide Web et traduit simplement - le World Wide Web.
Maintenant que nous avons choisi le miroir principal, il est temps de le signaler aux principaux moteurs de recherche.
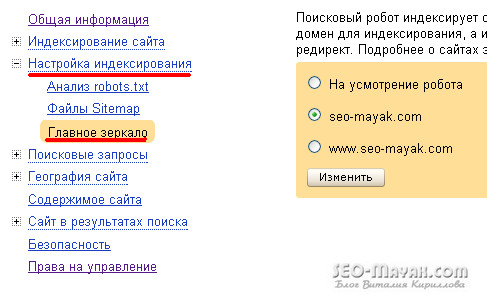
Comment pointer Yandex vers le miroir principal
Vous pouvez pointer Yandex vers le miroir principal en cliquant sur ce lien. Suivre - " Mes sites", Choisissez votre site ou l'un de vos sites, -" Réglage de l'index» — « Miroir principal«:
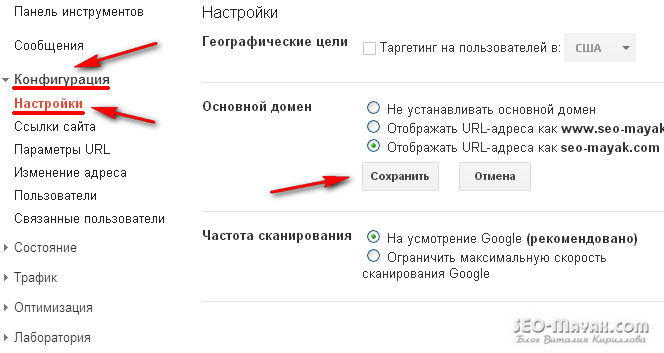
Comment pointer Google sur le miroir principal
Pour pointer Google vers le miroir principal, j’ai suivi le chemin déjà emprunté par d’autres webmasters, des outils pour les webmasters - " La configuration» — « Paramètres»

J'ai trouvé dans ma petite référence Google que pour passer par cette procédure, je devais entrer dans google Apps for Business

Nous passons l'enregistrement et arrivons au panneau d'administration. Ensuite, sélectionnez - "Confirmer la propriété du domaine"

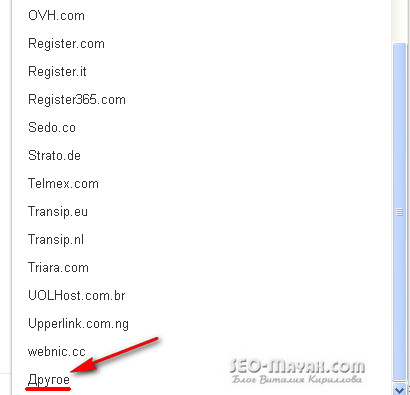
Dans la fenêtre contextuelle, cliquez sur "Continuer" et accédez à la page où nous sommes invités à choisir un registraire de domaine ou un fournisseur:

Si vous n'avez pas trouvé votre registraire de domaine dans la liste proposée, choisissez tout à la fin «Autre»
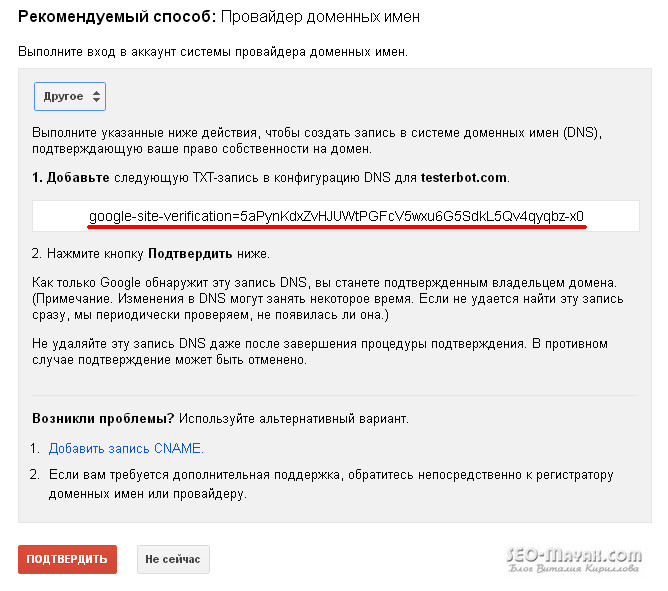
Tâche! Mais tout n'est pas aussi effrayant que cela puisse paraître à première vue. Copiez le code proposé et accédez au panneau de configuration de votre fournisseur d'hébergement, accédez aux paramètres DNS et collez le code copié dans le champ d'enregistrement TXT. Sur mon hébergement, le champ d'enregistrement TXT ressemble à ceci:
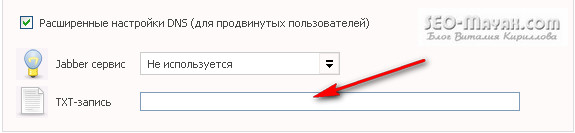
S'il existe déjà des caractères, remplacez-les simplement par le code copié de Google. Maintenant, nous retournons au panneau de commande et appuyons sur le bouton - «Confirmer» et si nous avons tout fait correctement, le message suivant apparaîtra:
Google propose également d'autres méthodes de vérification et j'ai essayé d'utiliser l'une d'entre elles pour mon domaine de test:

Mais comme je n'ai pas essayé de récupérer le fichier googleb1c540918a6ec845.html Google m'a constamment envoyé un fichier complètement différent, le même que celui que j'avais chargé à la racine du site lorsque je me suis inscrit au moteur de recherche Google et que je ne voulais pas le voir obstinément. Puis je suis allé dans l'autre sens, en ajoutant le fichier de méta-balise header.php. et cette fois la confirmation était réussie.
Laquelle des options proposées à utiliser dépend bien sûr de vous, mais il est probablement préférable de suivre le chemin recommandé, ce n’est pas pour rien qu’il est «recommandé».
Afin de terminer la redirection, outre ce qui précède, il est nécessaire que
Si vous rencontrez des difficultés, parlez-en dans les commentaires.
Aujourd'hui j'ai tout. Comment aimez-vous mon article?
Ce sont les routes en Sibérie, mais aussi les voitures ...
Cordialement, Vitaly Kirillov