Tableau superglobal $ _Server
L'un des tableaux prédéfinis les plus importants est un tableau $ _SERVER - A PHP Interprète Place les variables reçues du serveur. Sans ces variables, il est difficile d'organiser une prise en charge complète des applications Web. Ce qui suit est une description des éléments les plus importants de la matrice superglobale $ _Server.
Commenter
Afficher une liste complète d'une matrice de $ _Server peut être à l'aide de la fonction Print_R (), qui imprime le vidage de la matrice ou à l'aide de la fonction PHPInfo (), qui affiche des informations sur l'interpréteur PHP.
Element $ _Server ["document_root"]
L'élément $ _Server ["document_root"] contient le chemin d'accès au répertoire racine du serveur si le script est effectué dans l'hôte virtuel, cet élément indique le chemin d'accès au répertoire racine de l'hôte virtuel. Ceux. Dans le fichier de configuration httpd.conf, l'hôte virtuel dispose d'une directive de documentation, qui est attribuée à la valeur "D: / MAIN", l'élément $ _SERVER ["document_root] contiendra la valeur" D: Main ".
Element $ _Server ["http_accept"]
L'élément $ _Server ["http_accept"] décrit les préférences du client par rapport au type de document. Le contenu de cet élément est supprimé de l'en-tête HTTP de l'Accept, qui envoie le client au serveur. Le contenu de ce titre peut être comme suit.
image / gif, image / x-xbitmap, image / jpeg, image / pjpeg, application / x-choquwave-flash, application / vnd.ms-excel, application / msword, * / *
L'en-tête accepté vous permet de clarifier le type de support qui préfère obtenir le client en réponse à votre demande. Ce titre vous permet de dire au serveur que la réponse est limitée par un petit ensemble de types préférés.
Le symbole * est utilisé pour les groupes de groupe dans la ligne de média. Par exemple, le symbole * / * est défini pour utiliser tous les types et la désignation de type / * détermine l'utilisation de tous les sous-types du type de type sélectionné.
Commenter
Les types de supports sont séparés des autres virgules.
Chaque série de médias est également caractérisée par un ensemble supplémentaire de paramètres. L'un d'entre eux est le soi-disant coefficient de préférences relatives Q, qui prend des valeurs de 0 à 1, respectivement, des types moins préférés à plus préférés. L'utilisation de plusieurs paramètres Q permet au client d'informer le serveur avec un degré de préférence relatif pour un type de support particulier.
Commenter
Par défaut, le paramètre q prend une valeur 1. De plus, à partir du type de support, il est séparé par un point-virgule.
Un exemple de type d'en-tête accepte:
Accepter: Audio / *; Q \u003d 0,2, audio / basique
Dans ce titre, le premier type Audio / * inclut tous les documents de musique et caractérisé par le rapport de préférence de 0,2. Grâce à la virgule, le type d'audio / basique est spécifié pour lequel le coefficient de préférence n'est pas spécifié et la valeur par défaut est égale à une. En citant RFS2616, ce titre peut être interprété comme suit: "Je préfère le type d'audio / basique, mais je peux également envoyer des documents de tout autre type audio si elles sont disponibles, après avoir réduit le coefficient de préférence de plus de 80%."
Un exemple peut être plus compliqué.
Accepter: Texte / Plain; q \u003d 0.5, texte / html,
Texte / X-DVI; Q \u003d 0,8, texte / x-c
Commenter
Il convient de garder à l'esprit que l'élément $ _Server [http_accept] contient exactement les mêmes informations, mais sans l'en-tête d'acceptation initiale.
Cet en-tête est interprété comme suit: Les types de documents texte / HTML et Text / XC sont préférés, mais s'ils ne sont pas disponibles, le client envoiait cette demande préférera le texte / x-DVI, et s'il n'est pas, alors peut prendre de type texte / plain.
Element $ _Server ["http_accept_language"]
L'élément $ _Server ["http_accept_language"] décrit les préférences du client par rapport à la langue. Ces informations sont extraites de l'en-tête HTTP d'Accept-Langue, qui envoie le client au serveur. Vous pouvez donner l'exemple suivant:
Accepter-Langue: ru, en; Q \u003d 0.7.
Ce qui peut être interprété comme suit: le client préfère le russe, mais dans le cas de son absence, j'accepte d'accepter des documents en anglais. Un élément $ _Server ["http_accept_language"] contiendra exactement les mêmes informations, mais sans l'en-tête de langue acceptée:
ru, en; Q \u003d 0.7.
Le contenu de l'élément $ _Server ["http_accept_language"] peut être utilisé pour déterminer l'affiliation nationale des visiteurs. Toutefois, les résultats seront approximatifs car de nombreux utilisateurs utilisent des versions de navigateur anglais qui informeront le serveur que le visiteur préfère une seule langue - l'anglais.
Élément $ _Server ["http_host"]
L'élément $ _Server ["http_host"] contient un nom de serveur, qui, en règle générale, coïncide avec le nom de domaine du site situé sur le serveur. En règle générale, le nom spécifié dans ce paramètre coïncide avec le nom $ _Server ["nom_serveur"]. Le paramètre ne fournit qu'un nom de domaine sans nom de protocole (http: //), c'est-à-dire
www.sofftime.ru.
Élément $ _Server ["http_referer"]
L'élément $ _Server ["http_referer"] est donné une adresse de page avec laquelle le visiteur est venu sur cette page. La transition doit être exercée par référence. Créez deux pages index.php et page.php.
Page index.php.
Écho. "Lien vers la page PHP
"
;
Écho.
$ _Server ["http_referer"]
?>
Page.php Page sera un contenu similaire, mais le lien indique la page Index.PHP.
Page. Page.php.
Écho. "Lien vers la page PHP
"
;
Écho. "Contenu $ _Server [" http_regerer "] -".
$ _Server ["http_referer"]
?>
Lorsque vous passez d'une page à une autre, l'adresse de la page sera affichée avec laquelle la transition a été effectuée.
Element $ _Server ["http_user_agent"]
L'élément $ _Server ["http_user_agent"] contient des informations sur le type et la version du navigateur et du système d'exploitation des visiteurs.
Voici le contenu typique de cette chaîne: "Mozilla / 4.0 (compatible; MSIE 6.0; Windows NT 5.1)". La présence d'une sous-chaîne "MSIE 6.0" suggère que le visiteur navigue dans la page en utilisant Internet Explorer version 6.0. Les rapports de ligne "Windows NT 5.1" que Windows XP est utilisé comme système d'exploitation.
Commenter
Pour Windows 2000, l'élément $ _Server ["http_user_agent"] ressemble à ceci: "Mozilla / 4.0 (compatible; MSIE 5.01; Windows NT 5.0)") ", tandis que Windows XP -" Mozilla / 4.0 (compatible; MSIE 6.0; Windows NT 5.1) ".
Si le visiteur est livré avec le navigateur de l'opéra, le contenu de $ _server ["http_user_agent"] peut ressembler à ceci: "Mozilla / 4.0 (compatible; MSIE 5.0; Windows 98) Opéra 6.04". MSIE 6.0 La sous-chaîne ici est également présente, rapportant que le navigateur Opera est compatible avec Internet Explorer Browser et utilise les mêmes bibliothèques dynamiques Windows. Par conséquent, lors de l'analyse d'une ligne renvoyée par le navigateur, il convient de garder à l'esprit que l'explorateur Internet comprend une chaîne contenant le substitut MSIE 6.0 et ne contient pas la sous-chaîne "Opera". De plus, à partir de cette ligne, on peut en conclure que l'utilisateur utilise le système d'exploitation Windows 98.
Commenter
L'agent utilisateur du navigateur de Firefox peut être comme suit Mozilla / 5.0 (Windows; U; Windows NT 5.1; FR-US; RV: 1.8) Gecko / 20051111 Firefox / 1.5.
Lorsque vous utilisez le navigateur Netscape, le contenu de l'élément $ _Server ["http_user_agent"] peut être comme suit: "Mozilla / 5.0 (x11; u; Linux I686; EN-US; RV: 1.4) Gecko / 20030624 Netscape / 7.1" . L'appartenance à ce navigateur peut être déterminée par la présence d'une sous-chaîne "Netscape". De plus, vous pouvez savoir que le visiteur passe à Internet à l'aide de la version de fonctionnement de Linux, avec un noyau optimisé pour Pentium IV, tandis que dans la coque graphique de la fenêtre X. Ce mécanisme est pratique à utiliser pour collecter des informations statistiques, ce qui permet aux concepteurs d'optimiser les pages pour les navigateurs les plus courants.
Élément $ _Server ["Remote_addr"]
L'adresse IP du client est placée dans l'élément $ _Server ["Remote_addr"]. Lors du test sur une machine locale - cette adresse sera égale à 127.0.0.1. Toutefois, lors de l'essai sur le réseau, la variable renvoie l'adresse IP du client ou le dernier serveur proxy via lequel le client a atteint le serveur. Si le client utilise le serveur proxy pour apprendre son adresse IP à l'aide de la variable HTTP_X_FORWARDED_FOR, la valeur pouvant être obtenue à l'aide de la fonction getenv ().
Commenter
Les serveurs proxy sont des serveurs intermédiaires spéciaux fournissant un type de service spécial: compression du trafic, codage de données, adaptation sous appareils mobiles, etc. Parmi les multiples serveurs de proxy distinguent les serveurs proxy dites anonymes qui vous permettent de masquer l'adresse IP vraie du client, de tels serveurs ne renvoient pas la variable http_x_forwarded_for.
Supprimer la variable HTTP_X_FORWARD_FOR ENVIRONNEMENT
echo getenv (http_x_formwarded_for);
?>
Element $ _Server ["script_filename"]
L'élément $ _Server ["script_filename"] est placé un chemin absolu vers le fichier de la racine du disque. Donc, si le serveur exécute le système d'exploitation Windows, ce chemin peut ressembler à cette question "D: MAINSTINDEX.PHP", I.E. Le chemin est spécifié à partir du disque, dans un système d'exploitation de type UNIX, le chemin est indiqué à partir du répertoire racine /, par exemple, "/var/share/www/test/index.php".
Element $ _Server ["nom_serveur"]
Dans l'élément $ _Server ["Server_Name"], le nom du serveur est placé, en règle générale, coïncidant avec le nom de domaine du site situé dessus. Par example,
www.softtime.ru.
Le contenu de l'élément $ _Server ["nom_serveur"] coïncide souvent avec le contenu de l'élément $ _Server ["http_host"]. En plus du nom du serveur, la matrice Superglobal de $ _Server vous permet de trouver un autre nombre de paramètres de serveur, tels que l'adresse IP du serveur, écouter le port, lequel serveur Web est installé et la version du protocole HTTP. . Ces informations sont placées dans le $ _Server ["Server_addr"], $ _Server ["Server_Port"], $ _Server ["Server_software"] et $ _Server ["Server_protocol"], respectivement. Ce qui suit est un exemple utilisant des éléments de données.
Utilisation d'un tableau $ $ _Server
echo "nom du serveur -". $ _Server ["" Server_Name "]. "
"
;
Écho. "Adresse IP du serveur". $ _Server ["Server_addr"]. "
"
;
Echo "Port Server -". $ _Server ["Server_Port"]. "
"
;
Echo "serveur Web -". $ _Server ["serveur_software"]. "
"
;
Écho. "Version de protocole HTTP -". $ _Server ["serveur_protocol"]. "
"
;
?>
Élément $ _Server ["demande_method"]
L'élément $ _Server [demande_method] est placé dans la méthode de la requête, utilisée pour appeler le script: obtenir ou poster.
Attaques possibles
Utilisation de PHP en tant qu'application Binary CGI est l'une des options lorsque, pour une raison quelconque non souhaitée d'intégrer PHP à un serveur Web (par exemple Apache) en tant que module, ou il est censé utiliser ces utilitaires comme chroot et seuid pour organiser un environnement sûr. pendant le fonctionnement. Scripts. Cette installation est généralement accompagnée de copier le fichier exécutable PHP sur le répertoire CGI-bin du serveur Web. CERT (organisation suivant les menaces de sécurité) CA-96.11 recommande de ne pas placer aucun interprète dans le répertoire CGI-bin. Même si PHP est utilisé comme interprète indépendant, il est conçu pour empêcher la possibilité des attaques suivantes:
Accès aux fichiers système: http://my.host/cgi-bin/php?/etc/passwd
Les données saisies dans la ligne de requête (URL) après la transmission de la marque d'interrogation à l'interprète en tant qu'arguments de ligne de commande conformément au protocole CGI. Habituellement, les interprètes ouvrent et exécutent le fichier spécifié comme premier argument.
Dans le cas de l'utilisation de PHP via le protocole CGI, il ne interprétera pas les arguments de la ligne de commande.
Accès à un document arbitraire sur le serveur: http://my.host/cgi-bin/php/secret/doc.html
Selon l'accord généralement accepté, une partie du trajet dans la page demandée, située après le nom du module PHP effectué, /secret/doc.html, est utilisée pour spécifier un fichier interprété comme un programme CGI habituellement Certaines options de configuration pour un serveur Web (par exemple, Action for Server Apache) sont utilisées pour rediriger le document, par exemple, pour rediriger les demandes du type http://my.host/secret/script.php Interprète PHP. Dans ce cas, le serveur Web vérifie d'abord les droits d'accès au répertoire / secret, puis crée une demande redirigée http://my.host/cgi-bin/php/secret/script.php. Malheureusement, si la demande est initialement définie en totalité, la vérification du fichier /secret/script.php n'est pas effectuée, elle ne se produit que pour le fichier / cgi-bin / php. Ainsi, l'utilisateur a la possibilité de faire référence à / cgi-bin / php et, par conséquent, à tout document sécurisé sur le serveur.
En PHP, pointant à l'option de compilation --Enable-forcer-cgi-redirect, Et donc les options doc_root et user_dir pendant le script, vous pouvez empêcher des attaques similaires pour le répertoire avec un accès limité. Des options plus détaillées, ainsi que leurs combinaisons seront discutées ci-dessous.
Option 1: Seuls les fichiers disponibles publiquement sont desservi.
S'il n'y a pas de fichiers sur votre serveur, l'accès auquel est limité par mot de passe ou filtre par adresses IP, il n'est pas nécessaire d'utiliser ces options. Si votre serveur Web n'autorise pas les redirections ou n'a pas la possibilité d'interagir avec le module PHP exécutable au niveau de la sécurité requis, vous pouvez utiliser l'option. --Enable-forcer-cgi-redirect Pendant l'assemblage de php. Mais dans le même temps, vous devez vous assurer que des moyens alternatifs d'appeler le script, tels que appeler directement http://my.host/cgi-bin/php/dir/script.php ou avec renvoi http: // My. Host / dir / script .php, indisponible.
Dans le serveur Web Apache, la redirection peut être configurée à l'aide des directives Addhandler et Action (décrite ci-dessous).
Option 2: Utiliser - Force-CGI-REDIRCT
Cette option, spécifiée au cours de l'assemblage PHP, empêche les scripts d'être appelés directement à l'adresse de http://my.host/cgi-bin/php/secretdir/script.php. Au lieu de cela, PHP ne traitera que la demande demandée uniquement si elle est redirigée par un serveur Web.
Habituellement, la redirection du serveur Web Apache est configurée à l'aide des options suivantes:
| Action php-script / cgi-bin / php addhandler php-script .php |
Cette option n'est vérifiée que pour le serveur Web Apache, son fonctionnement est basé sur l'installation en cas de redirection de la variable non standard redirect_status, située dans l'environnement CGI. Si votre serveur Web ne fournit pas la capacité d'identifier sans ambiguïté si cette demande est redirigée, vous ne pouvez pas utiliser l'option décrite dans cette section et utiliser toute autre méthode de travail avec les applications CGI.
Option 3: Utilisation des options doc_rooot et user_dir
Placer du contenu dynamique, tels que des scripts ou de tout autre fichier exécutable, dans le répertoire Web Server le rend potentiellement dangereux. Si une erreur est effectuée dans la configuration du serveur, une situation est possible lorsque des scripts ne sont pas effectués, mais sont affichés dans le navigateur, en tant que documents HTML ordinaires, ce qui peut entraîner des fuites d'informations confidentielles (par exemple, des mots de passe) ou des informations que est la propriété intellectuelle. Sur la base de telles considérations, de nombreux administrateurs système préfèrent utiliser un répertoire distinct pour stocker des scripts, en fonctionnant avec tous les fichiers qui y sont placés par l'interface CGI.
S'il est impossible de veiller à ce que les demandes ne soient pas redirigées, comme indiqué dans la section précédente, vous devez spécifier la variable DOC_OOOT, qui diffère du répertoire racine des documents Web.
Vous pouvez définir le répertoire racine des scripts PHP en configurant le paramètre Doc_root dans le fichier de configuration ou en définissant la variable d'environnement php_document_rooot. Si PHP est utilisé par CGI, le chemin complet du fichier ouvert sera construit en fonction de la valeur de la variable doc_rooot et du chemin spécifié dans la requête. Ainsi, vous pouvez être sûr que les scripts ne seront exécutés que dans le répertoire que vous avez spécifié (à l'exception du répertoire User_Dir décrit ci-dessous).
Un autre utilisé lors de la configuration de l'option de sécurité - user_dir. Dans le cas où la variable User_Dir n'est pas installée, le chemin d'accès au fichier ouvert est construit par rapport à doc_root. Demande http://my.host/~user/doc.php mène à l'exécution d'un script qui n'est pas dans le répertoire de domicile de l'utilisateur correspondant et le script ~ utilisateur / doc.php dans le sous-répertoire Doc_root (Oui, Le nom du répertoire commence par le symbole ~).
Mais si la variable public_php est attribuée une valeur, par exemple, http://my.host/~user/doc.php, l'exemple de l'exemple sera exécuté un script doc.php situé dans le répertoire de base de l'utilisateur dans le Annuaire public_php. Par exemple, si le répertoire domestique de l'utilisateur / de l'utilisateur / utilisateur, le fichier /home/user/public_php/doc.php sera exécuté.
L'option user_dir est définie indépendamment de l'installation doc_rooot. Vous pouvez donc contrôler le répertoire racine du serveur Web et le répertoire personnalisé indépendamment les uns des autres.
Option 4: PHP en dehors de l'arbre de document Web
Un moyen d'améliorer de manière significative le niveau de sécurité consiste à placer le module exécutable PHP en dehors de l'arborescence de documents Web, par exemple en USR / local / bin. Le seul inconvénient de cette approche est que la première ligne de chaque script devrait être:
| #! / Usr / local / bin / php |
Vous devez également faire tous les fichiers exécutables des scripts. Ainsi, le script sera considéré comme une autre application CGI écrite dans Perl, SH ou toute autre langue scriptée utilisée en ajoutant #! Au début du fichier pour commencer vous-même.
Ce qui serait dans le script, vous pouvez obtenir les valeurs correctes des variables par path_info et path_translated, PHP doit être configuré avec l'option -Enable-jupard-path.
| <<< Назад | Contenu | Avant \u003e\u003e\u003e |
| Il y a encore des questions ou quelque chose d'incompréhensible - Bienvenue à notre | |
|
|
5 février. , 2017
Je ne connais pas un seul cadre PHP. C'est triste et honte, mais la loi n'est pas encore interdite. Et en même temps, jouez-vous avec l'API de repos que vous voulez. Le problème est que PHP par défaut ne supporte que $ _GET et $ _Post. Et pour le service reposant, il est nécessaire de travailler dès que possible avec Met, Supprimer et Patch. Et pas très évident comment traiter culturellement de nombreux types de types Obtenez http://site.ru/userers, supprimez http://site.ru/goods/5 Et d'autres dimensions. Comment envelopper toutes les demandes de telles demandes à un point unique, le désassemblable universellement dans des pièces et exécuter le code souhaité pour le traitement des données?
Presque n'importe quel cadre PHP peut le faire hors de la boîte. Par exemple, Laravel, où le routage est mis en œuvre et facile. Mais si nous n'avons pas besoin d'étudier maintenant pour étudier un nouveau gros sujet, mais je veux juste faire rapidement un projet avec le soutien de l'API de repos? Cela sera discuté dans l'article.
Que devriez-vous connaître notre service reposant?
1. Support tous les 5 types principaux de requêtes: obtenir, poster, mettre, patch, suppression.
2. Développer une variété de voies de l'espèce
Post / biens.
Mettre / marchandises / (goodid)
Obtenir / utilisateurs / (userID) / info
Et d'autres fois des longues chaînes.
ATTENTION: Cet article ne concerne pas les bases de l'API de repos
Je suppose que vous connaissez déjà l'approche de repos et comprends comment cela fonctionne. Sinon, alors à Internet, il existe de nombreux articles merveilleux sur les bases du reste - je ne veux pas les dupliquer, mon idée est de montrer comment travailler avec le reste dans la pratique.
Quelle fonctionnalité allons-nous soutenir?
Considérons 2 entités - biens et utilisateurs.
Pour les biens, ce qui suit est ce qui suit:
- 1. Obtenir / marchandises / (goodid) - obtenir des informations sur le produit
- 2. Post / biens. - Ajout d'un nouveau produit
- 3. Mettre / marchandises / (goodid) - Modification des marchandises
- 4. Patch / biens / (goodid) - Modification des paramètres de marchandises
- 5. Supprimer / marchandises / (goodid) - Élimination des marchandises
Par les utilisateurs de la diversité considérer plusieurs options avec obtenir
- 1. Obtenir / utilisateurs / (userid) - Informations complètes sur l'utilisateur
- 2. Obtenir / utilisateurs / (userID) / info - Seules des informations générales sur l'utilisateur
- 3. Obtenir / utilisateurs / (userID) / Commandes - Liste des commandes de l'utilisateur
Comment fonctionne-t-il sur un PHP natif?
La première chose que nous ferons est de configurer.htaccess afin que toutes les demandes soient redirigées vers le fichier index.php. C'est lui qui sera engagé dans l'extraction de données.
Le second - nous définirons quelles données nous avons besoin et écrivez le code pour les recevoir - Index.php.
Nous sommes intéressés par 3 types de données:
- 1. Méthode de demande (obtenir, poster, mettre, patch ou supprimer)
- 2. Données de l'URL-A, par exemple, utilisateurs / (userid) / info - tous les 3 paramètres sont nécessaires.
- 3. Données des organes de la demande
.htaccess.
Créez un fichier à la racine du projet.htaccess
RewriteEngine sur RewriteCond% (Demande_Filename)! -F RewriteRule ^ (. +) $ Index.php? Q \u003d 1 $ 1
Nous commandons ces lignes mystérieuses à faire ceci:
1 - Envoyer toutes les demandes de tout type de fichier roi index.php
2 - Faire une chaîne dans l'URL disponible dans Index.php dans le paramètre GET Q. C'est-à-dire des données de l'URL / Users / (userID) / info Nous allons sortir de $ _GET [Q "].
index.php.
Envisager une chaîne index.php par ligne. Pour commencer, nous obtenons la méthode de la demande.
// Déterminez la méthode de demande $ Méthode \u003d $ _Server ["demande_method"];
Ensuite, les données des corps de la demande
// reçoivent des données du corps de la demande $ formdata \u003d getFormData (méthode $);
Pour obtenir et publier, il est facile de retirer les données des tableaux correspondants $ _GET et $ _Post. Mais pour le reste des méthodes, vous devez pervertir légèrement. Code pour eux est sorti du flux pHP: // entréeLe code est facile à google, je viens d'écrire une pellicule commune - la fonction getFormData (méthode $)
// Obtenir des données de la fonction GetformData Corps de requête ($ Méthode) (// Obtenir ou poster: Data Retour comme si ($ méthode \u003d\u003d\u003d "Obtenez") Retour $ _GET; Si ($ méthode \u003d\u003d\u003d "POST") Retour $ £ _Post; // Met, patch ou Supprimer $ Data \u003d Array (); $ explosé \u003d exploser ("&", file_get_contents ("PHP: // entrée"))); foreach ($) \u003d Exploser ("\u003d", paire $); si (comptage (article $ ($) \u003d\u003d 2) ($ data \u003d urldecode ($);)) renvoie $ données;)
C'est-à-dire que nous avons eu les données nécessaires, rares tous les détails de GetformData - et d'accord. Allez au routage le plus intéressant.
// désassembler l'URL $ URL \u003d (Isset ($ _ obtenir ["q"]))? $ _GET ["Q"]: ""; $ Url \u003d rtrim ($ URL, "/"); $ URLS \u003d exploser ("/", $ URL);
Au-dessus, nous avons appris que.htaccess mettra les paramètres de l'URL-A dans le paramètre Q de la matrice $ _GET. C'est-à-dire en $ _GET ["Q"], environ une telle ligne tombera: utilisateurs / 10.. Indépendamment de la manière dont la méthode nous donnons la demande.
MAIS exploser ("/", $ URL) Convertit nous cette chaîne en une matrice avec laquelle vous pouvez déjà travailler. Ainsi, constituent toutes les chaînes de requête longues, par exemple,
Obtenir / marchandises / Page / 2 / Limit / 10 / Trier / Price_asc
Et assurez-vous d'obtenir un tableau
$ Urls \u003d array ("marchandises", "page", "2", "limite", "10", "trier", "Price_asc");
Maintenant, nous avons toutes les données, vous devez faire quelque chose d'utile avec eux. Et cela ne fera que 4 lignes de code
// Déterminez les données de routeur et d'URL $ Router \u003d $ URL; $ urldata \u003d array_slice ($ URL, 1); // Connectez le fichier de routeur et exécutez la fonction principale include_once "routeurs /". $ Routeur. ".php"; Route ($ méthode, $ URLDATA, $ formdata);
Attraper? Nous commençons le dossier de routeurs dans lequel nous plions les fichiers qui manipulent une entité: des biens ou des utilisateurs. Dans le même temps, nous convenons que le nom des fichiers coïncident avec le premier paramètre de Urldata - ce sera un routeur, $ routeur. Et de Urldata, ce routeur doit être supprimé, il n'est plus nécessaire et n'est utilisé que pour connecter le fichier souhaité. array_slice ($ URL, 1) Et cela nous apportera tous les éléments du tableau, à l'exception du premier.
Il reste maintenant à relier le fichier de routeur souhaité et à exécuter la fonction d'itinéraire avec trois paramètres. Quelle est cette voie de fonction? Nous convenons que dans chaque fichier de routeur, cette fonction sera définie, ce que les paramètres d'entrée déterminent quelle action a initié l'utilisateur et exécuter le code souhaité. Maintenant, cela deviendra plus clair. Considérez la première demande de réception des données sur le produit.
Obtenir / marchandises / (goodid)
Fichier de routeurs / marchandises.php
// route de fonction routeur (méthode $, $ URLDATA, $ formdata) (// recevoir des informations sur le produit // get / marchandise / (goodid) si ($ méthode \u003d\u003d\u003d "get" && comptez ($ urldata) \u003d\u003d\u003d 1 ) (// Obtenir l'ID de produit $ goodid \u003d $ URLDATA; // Sortez les marchandises de la base ... // retirez la réponse au client ECHO JSON_ENCODE (matrice («Méthode» \u003d\u003e «Obtenir». "\u003d\u003e $ goodid," bon "\u003d\u003e" téléphone "," prix "\u003d\u003e 10000)); retour;) // retourner l'erreur d'en-tête (" HTTP / 1.0 400 Demande mauvaise "); echo json_encode (tableau (" Erreur "\u003d\u003e" mauvaise demande "));)
Le contenu du fichier est une fonction de route importante qui, selon les paramètres transmis, effectue les actions nécessaires. Si la méthode GET et URLDATA ont transmis 1 paramètre (goodid), il s'agit donc d'une demande de données sur le produit.
ATTENTION: un exemple est très simplifié
Dans la vie réelle, bien sûr, vous devez également vérifier les paramètres d'entrée, par exemple que GoodID est un nombre. Au lieu d'écrire le code ici, vous connectez probablement la classe souhaitée. Et pour obtenir l'article, créez un objet de cette classe et faites-la une méthode.
Ou peut-être donner le contrôle de certains contrôleurs, qui est déjà concerné par l'initialisation des modèles souhaités. Il existe de nombreuses options, nous considérons uniquement la structure générale du code.
En réponse au client, nous tirons les données nécessaires: le nom des marchandises et son prix. L'ID de produit et la méthode dans la réelle appendice ne sont pas totalement obligatoires. Nous ne leur montrerons que de s'assurer que la méthode souhaitée est appelée avec les paramètres corrects.
Essayons sur l'exemple: ouvrez la console du navigateur et exécutez le code.
$ .Ajax ((URL: "/ exemples / repos / marchandises / 10", méthode: "get", type de données: "json", succès: fonction (réponse) (Console.log ("réponse:", réponse))))))))))))))))))) )
Le code enverra une demande au serveur où j'ai déployé une application similaire et affiche la réponse. Assurez-vous que notre route / Biens / 10 vraiment travaillé. Dans l'onglet Réseau, vous remarquerez la même requête.
Et oui, / exemples / repos est le chemin racine de notre application de test sur le site
Si vous connaissez l'utilisation de la courrière dans la console, puis exécutez-la dans le terminal - la réponse sera la même, et même avec les en-têtes du serveur.
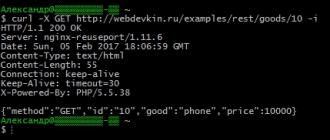
Curl -X Obtenir https: // Site / Exemples / Rest / Marchandises / 10 -i 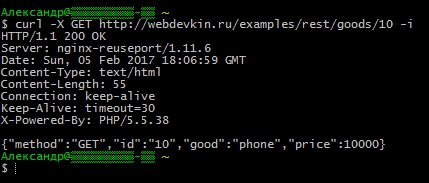
À la fin de la fonction, nous avons écrit un tel code.
// renvoie l'erreur d'en-tête ("HTTP / 1.0 400 Demande BAD"); Echo json_encode (tableau ("erreur" \u003d\u003e "mauvaise demande"));
Cela signifie que si nous nous trompons avec les paramètres ou la route demandée n'est pas défini, nous renvoyons la mauvaise demande du client 400-M. Ajouter, par exemple, à l'URL, quelque chose comme marchandises / 10 / un autre_param Et vous verrez un bug dans la console et la réponse 400 - la courbe n'est pas une demande.
Sur les réponses du serveur HTTP-CODES
Nous ne nous embêterons pas avec le retrait de différents codes, bien que sur le reste, cela vaut la peine de faire. Les erreurs de clients sont beaucoup. Même dans notre cas simple, 405 est approprié dans le cas d'une méthode incorrectement transmise. Je ne veux intentionnellement pas compliquer.
En cas de succès, le serveur retournera toujours 200 OK. Pour de bon, lors de la création d'une ressource vaut la peine de 201 Create. Mais encore une fois, en termes de simplification, ces subtilités que nous jetons et dans le vrai projet, vous vous mettez facilement en œuvre.
Selon la conscience, l'article est terminé. Je pense que vous avez déjà compris l'approche, comment toutes les routes sont détruites, les données sont supprimées, comment tester, comment ajouter de nouvelles demandes, etc. Mais je vais apporter la mise en œuvre des 7 demandes restantes que nous avons identifiées au début de l'article. En cours de route, je vais apporter quelques commentaires intéressants et, à la fin, posez les archives avec la source.
Post / biens.
Ajout d'un nouveau produit
// Ajout d'un nouveau produit // poteau / marchandise si ($ méthodory \u003d\u003d\u003d "Post" && vide ($ UrLData)) (// Ajouter des marchandises à la base de données ... // Affiche la réponse au client Echo JSON_ENCODE ( Array ("Méthode" \u003d\u003e "POST", "ID" \u003d\u003e RAND (1, 100), "formdata" \u003d\u003e $ formdata)); retour;)
urldata est maintenant vide, mais formdata est utilisé - nous l'apportons simplement au client.
Comment faire "à droite"?
Selon les canons de repos de la requête post, vous ne devez récupérer que l'ID de l'entité créée ou l'URL, selon laquelle cette entité peut être obtenue. C'est-à-dire qu'il y aura une réponse ou juste un nombre - (Godid), ou alors / Biens / (goodid).
Pourquoi ai-je écrit "à droite" dans des citations? Oui, parce que le repos est un ensemble de règles non difficiles, mais des recommandations. Et comme vous vous mettrez en œuvre, cela dépend de vos préférences ou de vos accords déjà acceptés sur un projet spécifique.
Gardez simplement à l'esprit qu'un autre code de lecture de programmeur et le conscience de l'approche de repos devra répondre à un identifiant post-requête de l'objet créé ou de l'URL, qui peut être obtenue par la demande d'obtention de la demande de données sur cet objet. .
Test de la console
$ .Ajax ((URL: "/ Exemples / REST / Produits /", méthode: "POST", DATA: (Good: "Notebook", Prix: 20 000), le type de données: "JSON", Succès: Fonction (Réponse) ( Console.log ("réponse:", réponse)))))
Curl -X Publier HTTPS: // Site / Exemples / Reste / Marchandises / --Data "Good \u003d Notebook & Prix \u003d 20000" -J'ai
Mettre / marchandises / (goodid)
Édition de biens
// Mise à niveau Tous les produits de données // Put / Produits / (GoodID) si (méthode $ \u003d\u003d\u003d "PUT" && Count ($ Urldata) \u003d\u003d\u003d 1) (// Obtenir le produit ID \u003d GOODID Urldata $; // Nous mettons à jour tous les champs de marchandises dans la base de données ... // Affiche la réponse au client Echo JSON_ENCODE (tableau ("Méthode" \u003d\u003e "Met", "ID" \u003d\u003e $ goodid, "formdata" \u003d\u003e $ formdata) ); Revenir;)
Ici, toutes les données sont entièrement utilisées. De Urldata, l'ID de produit est retiré et des propriétés de formdata.
Test de la console
$ .AJAX ((URL: "/ Exemples / Exemples / Repos / marchandises / 15", Méthode: "Mettez", Data: (Bon: "Notebook", Prix: 20 000), DataType: "Json", Succès: Fonction (réponse) (Console.log ("réponse:", réponse)))))
CURL -X PUT HTTPS: // site / Exemples / REST / Produits / 15 --data "Good \u003d Notebook & Prix \u003d 20000" -i
Patch / biens / (goodid)
Mise à jour partielle des marchandises
// mise à jour de service partielle // Patch / Produits / (GoodID) si (méthode $ \u003d\u003d\u003d "Patch" && Count ($ urldata) \u003d\u003d\u003d 1) (// Obtenir l'ID de produit $ goodid \u003d $ urldata; // Nous mettons à jour seuls les champs spécifiés de la marchandise dans la base de données ... // affiche la réponse au client Echo JSON_ENCODE (tableau ("Méthode" \u003d\u003e "PATCH", "ID" \u003d\u003e $ goodid, "formdata" \u003d\u003e $ Formdata)); retour;)
Test de la console
$ .Ajax ((URL: "/ Exemples / Exemples / Repos / marchandises / 15", Méthode: "Patch", Données: (Prix: 25000), DataType: "Json", Succès: Fonction (Console.log (" Réponse: ", réponse)))))
CURL -X PATCH HTTPS: // Site / Exemples / Repos / marchandises / 15 --Data "Prix \u003d 25000" -J'ai
Quels sont ces ponte avec mis et patch?
Est-ce que l'on ne met pas assez? Ne remplissent-ils pas la même action - mettez-vous à jour les données d'objet?
C'est comme ça qu'une chose est une chose. La différence entre les données transmises.
Met suppose que le serveur est transmis tout Champs de l'objet et patch - seulement modifié. Ceux qui sont transmis dans le corps de la requête. Veuillez noter que dans la précédente mise, nous avons également transféré le nom des marchandises et le prix. Et en patch - seulement le prix. C'est-à-dire que nous avons envoyé uniquement des données modifiées sur le serveur.
Avez-vous besoin de patch - décidez pour vous-même. Mais rappelez-vous du code de programmeur de lecture que j'ai mentionné ci-dessus.
Supprimer / marchandises / (goodid)
Suppression de biens
// Supprimer les marchandises // Supprimer // Marchandises / (goodid) Si ($ méthode \u003d\u003d\u003d "Supprimer" && Count ($ URLDATA) \u003d\u003d\u003d 1) (// Obtenir l'ID de produit $ goodid \u003d $ URLDATA; // Supprimer les produits de la base ... // Affiche la réponse au client Echo json_encode (array ( "Méthode" \u003d\u003e "Supprimer", "id" \u003d\u003e $ goodid)); rendement;)
Test de la console
$ .Ajax ((URL: "/ exemples / repos / marchandises / 20", Méthode: "Supprimer", DataType: "JSON", Succès: fonction (réponse) (Console.log ("Réponse:", Réponse))))))))))))) )
CURL -X Supprimer HTTPS: // Site / Exemples / Repos / marchandises / 20 -i
Avec une demande de suppression, tout est clair. Examinons maintenant le travail avec les utilisateurs - les utilisateurs de routeurs et, en conséquence, le fichier user.php
Obtenir / utilisateurs / (userID)
Obtention de toutes les données utilisateur. Si le type GET-Demande / Users / (userid), alors nous vous rembourserons toutes les informations sur l'utilisateur s'il est également indiqué. / Info. ou alors / Ordres., en conséquence, seulement des informations générales ou une liste des ordonnances.
// routeur Fonction Route (Méthode $, Urldata $, FormData $) (// Obtenir toutes les informations utilisateur // Get / Users / (UserID) si (méthode $ \u003d\u003d\u003d "Get" && Count ($ Urldata) \u003d\u003d \u003d 1) (// Obtenir l'ID de produit ID utilisateur \u003d $ URLDATA; // Tirez sur toutes les données utilisateur de la base de données ... // Affiche la réponse au client Echo JSON_ENCODE (tableau ("Méthode" \u003d\u003e "Obtenir" ". id "\u003d\u003e $ UserID, "info"\u003d\u003e Array ( "E - mail"\u003d\u003e" [Email protégé]"" NOM "\u003d\u003e" WebDevkin ")," Commandes "\u003d\u003e Array (Array (" Commander "\u003d\u003e 5," Summa "\u003d\u003e 2000," OrderDate "\u003d\u003e" 12/01/2017 « ), Array ( "ORDERID "\u003d\u003e 8," Summa "\u003d\u003e 5000," OrderDate "\u003d\u003e" 02/03/2017 ")))); retour;) // Retourne l'erreur HEADER (" HTTP / 1.0 400 Bad Request"); Echo json_encode (Array ( "Error" \u003d\u003e "Bad Request"));)
Test de la console
.Ajax $ ((URL: "/ examples / REST / Utilisateurs / 5", Méthode: "Get", type de données: "JSON", Succès: Fonction (Réponse) ( "Réponse:", réponse))))
Curl -X Obtenir https: // Site / Exemples / Rest / Utilisateurs / 5 -i
Obtenir / utilisateurs / (userID) / info
Informations générales sur l'utilisateur
// Obtenir des informations utilisateur général // Get / Users / (UserID) / surInfosi (méthode $ \u003d\u003d\u003d "Get" && Count ($ Urldata) \u003d\u003d\u003d 2 && $ urldata \u003d\u003d\u003d "info") (/ / Obtenez le produit du produit $ userid \u003d $ urldata; // tirer les données utilisateur générales de la base de données ... // Afficher la réponse au client Echo json_encode (array ( "Méthode" \u003d\u003e "Get", « id "\u003d\u003e $ UserID," info "\u003d\u003e array (" email "\u003d\u003e" [Email protégé]"," Nom "\u003d\u003e" Webdevkin "))); retour;)
Test de la console
$ .AJAX ((URL: "/ Exemples / EXEMPLES / EXEMPLES / 5 / INFO", MÉTHODE: "GET", DataType: "JSON", Succès: fonction (réponse) (Console.log ("Réponse:", Réponse) ))))
Curl -X Obtenir https: // Site / Exemples / Rest / Utilisateurs / 5 / Info -I
Obtenir / utilisateurs / (userID) / Commandes
Obtenir une liste des commandes de l'utilisateur
// recevant les commandes utilisateur // get / user / (userid) / commandes si ($ méthody \u003d\u003d\u003d "obtenez" && comptez ($ urldata) \u003d\u003d\u003d 2 && $ urldata \u003d\u003d\u003d "Commandes") (// Obtenir ID de produit $ userid \u003d $ URLDATA; // Sortez les données de commande de l'utilisateur à partir de la base de données ... // Affiche la réponse au client ECHO JSON_ENCODE (tableau ("Méthode" \u003d\u003e "ID" \u003d\u003e $ Userid, "Commandes" \u003d\u003e Array (tableau ("Commande" \u003d\u003e 5, "Summa" \u003d\u003e 2000, "OrderDate" \u003d\u003e "12.01.2017"), Array ("Summa" \u003d 8, "Suma" \u003d \u003e 5000, "ordredate" \u003d\u003e "03.02.2017"))); retour;)
Test de la console
$ .AJAX ((URL: "/ Exemples / EXEMPLES / RED / UTILISANTS / COMMANDES", MÉTHODE: "GET", DataType: "JSON", SUCCESS: Fonction (réponse) (Console.log ("Réponse:", Réponse) ))))
Curl -X Obtenir https: // Site / Exemples / Rest / Utilisateurs / 5 / Commandes -I
Résultats et sources
Sources d'exemples de l'article -
Comme vous pouvez le constater, organiser la prise en charge de l'API de repos sur le PHP natif s'est avéré être aussi difficile et totalement légitime. La principale chose est de prendre en charge les itinéraires et les méthodes PHP non standard, PATCH et Suppr.
Le code principal qui implémente ce support a été monté à 3 dizaines de lignes Index.PHP. Le reste est déjà une passoire pouvant être réalisée comme vous le souhaitez. Je l'ai suggéré sous la forme de fichiers de routeurs connectés, dont les noms coïncident avec les entités de votre projet. Mais vous pouvez connecter la fantaisie et trouver une solution plus intéressante.
Dans la deuxième leçon, nous écrirons deux autres classes et terminerons complètement la partie interne du script.
Plan
Le but de la série de leçons de créer une application simple permettant aux utilisateurs de s'inscrire, d'entrer, de quitter et de modifier les paramètres. Une classe qui contiendra toutes les informations utilisateur sera appelée utilisateur et il sera défini dans le fichier user.class.php. Une classe qui sera responsable de l'entrée \\ Sortie sera appelée USERTOOLS (USERTOOLS.CLASS.PHP).
Un peu sur le nom des classes
La bonne tonalité consiste à appeler des fichiers avec une description de classe comme le même nom que la classe elle-même. Il est donc facile de déterminer le but de chaque fichier dans le dossier avec des classes.
En outre, à la fin du nom du fichier de classe, add.class ou.inc. Ainsi, nous définissons clairement le but du fichier et pouvons utiliser.htaccess pour limiter l'accès à ces fichiers.
Classe des utilisateurs (user.class.php)
Cette classe définira chaque utilisateur. Avec la croissance de cette application, la définition «utilisateur» peut changer de manière significative. Heureusement, la programmation OOP facilite l'ajout d'attributs d'utilisateur supplémentaires.
Constructeur
Dans cette classe, nous utiliserons le constructeur - il s'agit d'une fonction qui est automatiquement appelée lors de la création d'une autre copie de la classe. Cela nous permet de publier automatiquement certains attributs après avoir créé un projet. Dans cette classe, le concepteur prendra le seul argument: une matrice associative contenant une rangée de la table des utilisateurs de notre base de données.
Exiger_once "db.class.php"; Utilisateur de classe (Public $ ID; Public $ Nom d'utilisateur; Public $ Hashedpassword; Public $ email;
public $ joinder;
//Le concepteur est appelé lors de la création d'un nouvel objet // prend un tableau associatif avec la rangée de DB comme argument. FONCTION __construct ($ DATA) ($ this-\u003e ID \u003d (isset ($ data [ID "])) $ Données [ID?"]: ""; $ This-\u003e UserName \u003d (isset ($ data [ "UserName" ?])) $ data [ » username "]:" "; $ this-\u003e hashedpassword \u003d (isset ($ data [" mot de passe])) de données $ [ "Password"]: ""; $ this-\u003e email \u003d (issset ($ data [ "email"])) $ data [ "E - mail"]: ""; $ this-\u003e JOINDATE \u003d (isset ($ DATA [ "join_date])) $ DATA [" join_date « ]?: "";)
Fonction publique Save ($ isnewuser \u003d false) (// Création d'un nouvel objet de base de données $ db \u003d new db ()..! // si l'utilisateur est déjà enregistré et nous « re // Juste Mise à jour leurs informations, si ($ isnewuser ) (// Définissez le tableau de données $ data \u003d Array ( "Nom d'utilisateur" \u003d\u003e "" $ this-\u003e nom d'utilisateur "", "password" \u003d\u003e "" $ this-\u003e hashedpassword "",
"Email" \u003d\u003e "" $ this-\u003e email "");
// mise à jour de la ligne dans la base de données $ DB-\u003e Mettre à jour ($ données, "utilisateurs", "id \u003d". $ This-\u003e id); ) AUTRE (// si l'utilisateur est enregistré pour la première fois. $ Data \u003d array ( "nom d'utilisateur" \u003d\u003e "" $ this-\u003e nom d'utilisateur "", "password" \u003d\u003e "" $ this-\u003e hashedpassword "" , "E - mail" \u003d\u003e "" $ this-\u003e email "", "join_date" \u003d\u003e "" .date ( "AMJ H: I: S", Time ()). "" « ); $ this-\u003e id \u003d $ Db-\u003e insert ($ données, "utilisateurs"); $ this-\u003e joindate \u003d heure ();) retourne vrai; ))?\u003e
Explication
La première partie du code, en dehors de la zone de classe, fournit une connexion de la classe dans la base de données (puisque la classe d'utilisateur a une fonction qui nécessite cette classe).
Au lieu de variables de classe "protégées" (utilisées dans la 1ère cours), nous les définissons comme "public". Cela signifie que tout code en dehors de la classe a accès à ces variables lorsque vous travaillez avec l'objet utilisateur.
Le concepteur prend un tableau dans lequel les colonnes de la table sont des clés. Nous spécifions une variable de classe en utilisant $ ceci-\u003e VariaBlename. Dans l'exemple de cette classe, nous vérifions d'abord si la valeur d'une clé spécifique est. Si tel est le cas, nous assimilons la variable de la classe à cette valeur. Sinon, une chaîne vide. Le code utilise une brève forme d'un chiffre d'affaires si:
$ Valeur \u003d (3 \u003d\u003d 4)? "UN B";
Dans cet exemple, nous vérifions si 3 quatre est égal à 3! Si oui, alors $ valeur \u003d "a", non - valeur $ \u003d "B". Dans notre exemple, le résultat est $ Value \u003d "B".
Nous enregistrons des informations sur les utilisateurs de la base de données
La fonction de sauvegarde est utilisée pour modifier la table de base de données avec les valeurs actuelles de l'objet utilisateur. Cette fonctionnalité utilise la classe BD, que nous avons créée dans la première leçon. À l'aide de variables de classe, un tableau de données $ est installé. Si les données utilisateur sont enregistrées pour la première fois, alors $ isnewuser est transmis en tant que $ vrai (Faux par défaut). Si $ isnewuserer \u003d $ vrai, alors la fonction Insérer () DB Class est appelée. Sinon, la fonction UPDATE () est appelée. Dans les deux cas, les informations de l'objet utilisateur seront enregistrées dans la base de données.
Userools.class.php classe classe
Cette classe contiendra des fonctions liées aux utilisateurs: connexion (), déconnexion (), checksernesernesxistes () et obtenir (). Mais avec l'extension de cette application, vous pouvez ajouter de nombreux autres autres.
//Usertools.class.php require_once "user.class.php"; Exiger_once "db.class.php";
classe USERTools (
// enregistre l'utilisateur dans. Premièrement vérifie si le nom d'utilisateur et le nom d'utilisateur et le mot de passe correspondent à une ligne de la base de données. // Si cela réussit, définissez les variables de la session // et stockez l'objet utilisateur dans.
login de fonction publique ($ nom d'utilisateur, $ mot de passe)
{
$ hashedpassword \u003d md5 (mot de passe $); $ résultat \u003d mysql_query ("Select * à partir des utilisateurs où nom d'utilisateur \u003d" $ US Nom "et mot de passe \u003d" $ hashedpassword "); si (mysql_num_rows ($ result) \u003d\u003d 1) ($ _SESSION [ "utilisateur"] \u003d sérialisation (nouvel utilisateur (mysql_fetch_assoc ($ result)); $ _SESSION [ "login_time"] \u003d time (); $ _SESSION [ "logged_in" ] \u003d 1; retour vrai;) sinon (retour faux;))
// enregistre l'utilisateur. Détruire les variables de session. fonction publique logout () (MHS ($ _ séance [ "utilisateur"]); unset ($ _ séance [ "login_time"]) non durci (séance $ _ [ "logged_in"]); session_destroy ();) // Check pour voir si lorsqu'Lorsqu'une un nom d' utilisateur existe. // Ceci s'appelle lors de l'inscription pour vous assurer que tous les noms d'utilisateur sont uniques. Fonction publique checkunameExists ($ nom d'utilisateur) ("" Select \u003d mysql_query ("Sélectionnez l'identifiant des utilisateurs où nom d'utilisateur \u003d" $ US Nom ""); if (mysql_num_rows ($ résultat) \u003d\u003d 0) (retourne false) (retourne vrai;)
}
// Obtenir un utilisateur // retourne un objet utilisateur. Prend Les utilisateurs ID AS Une entrée Fonction publique Get ($ ID) ($ db \u003d new db (); $ result \u003d $ db-\u003e select ( "utilisateurs", "id \u003d $ id"); retour nouvel utilisateur ($ result ););))
?>
Login () Fonction
La fonction de connexion () est claire par le nom. Il prend le nom d'utilisateur $ et des arguments d'utilisateur $ mot de passe et les vérifie. Si tout correspond, crée un objet utilisateur avec toutes les informations et l'enregistre dans la session. Veuillez noter que nous utilisons uniquement la fonction PHP Serialize (). Il crée une version enregistrée de l'objet qui peut être facilement annulée à l'aide de désexservation (). En outre, le temps de connexion sera enregistré. Cela peut être utilisé à l'avenir pour fournir aux utilisateurs des informations sur la durée du séjour sur le site.
Vous pouvez également remarquer que nous avons défini $ _session ["Logged_in"] à 1. Cela nous permet de vérifier facilement sur chaque page de connexion logiquement. Il suffit de ne vérifier que cette variable.
Se déconnecter ()
Aussi une caractéristique simple. La fonction PHP nonset () efface les variables en mémoire, tandis que Session_Destroy () supprime la session.
Fonction checkuserExists ()
Qui sait que l'anglais comprendra facilement la fonction. Il demande simplement à la base de données, que la même connexion soit utilisée ou non.
Obtenir () fonction
Cette fonctionnalité prend un identifiant unique unique et fait une requête à la base de données à l'aide de la classe DB, à savoir Select () fonctions. Il faudra une matrice associative avec un certain nombre d'informations de l'utilisateur et créera un nouvel objet utilisateur, en transmettant un tableau au concepteur.
Où puis-je l'utiliser? Par exemple, si vous créez une page qui devrait afficher des profils d'utilisateur spécifiques, vous devrez prendre ces informations de manière dynamique. C'est ainsi que vous pouvez faire ceci: (Je dirai ul http://www.website.com/profile.php?userid\u003d3)
// Remarque: vous devrez d'abord ouvrir une connexion de base de données. // Voir la partie 1 pour plus d'informations sur le faire. // Vous devez également vous assurer que vous avez inclus les fichiers de classe.
$ Outils \u003d nouveau USERTOOLS (); $ Utilisateur \u003d $ outils-\u003e obtenir ($ _ exiger ["userid"]); Echo "Nom d'utilisateur:". $ Utilisateur-\u003e nom d'utilisateur. ""; Echo "Joins sur:". $ User-\u003e Joindate. "";
Facilement! Vérité?
Dernier serveur de course Partie: global.inc.php
global.inc.php est requis pour chaque page du site. Pourquoi? Ainsi, nous allons placer toutes les opérations habituelles dont nous avons besoin sur la page. Par exemple, nous allons commencer la session_start (). La connexion BD sera également ouverte.
exiger_once "classes / usserools.class.php";
exiger_once "classes / db.class.php";
// Connexion à la base de données $ DB \u003d Nouveau DB (); $ DB-\u003e Connect ();
// initialiser l'objet USERTOOLS $ USERTOOLS \u003d nouvel UserTools (); // Démarrer la session
session_start ();
// rafraîchissez les variables de session si connectées si (Isset ($ _ Session ["LOGNED_IN])) ($ utilisateur \u003d non désériorize ($ _ session [" utilisateur]); $ _Session] \u003d Serialize ($ userools- \u003e Obtenir ($ utilisateur-\u003e id));)?\u003e
Qu'est-ce qu'il fait?
Il y a quelques choses ici. Tout d'abord, nous ouvrons une connexion à la base.
Après la connexion, nous commençons la fonction session_start (). La fonction crée une session ou continue le courant si l'utilisateur est déjà connecté. Étant donné que notre application est conçue pour que les utilisateurs entrent \\ Out, cette fonctionnalité est obligatoire sur chaque page.
Ensuite, nous vérifions si l'utilisateur est logvisé. Si oui, nous mettrons à jour $ _Session ["utilisateur"] pour afficher les dernières informations sur l'utilisateur. Par exemple, si l'utilisateur change son email, un ancien sera stocké dans la session. Mais avec l'aide de la mise à jour automatique, cela ne se produira pas.
À ce sujet, la deuxième partie est arrivée à la fin! Demain attend la dernière leçon sur ce sujet.
Tous mes vœux!
Obtient l'objet WP_USER, qui contient toutes les données de l'utilisateur spécifié.
Les fonctions retournées de données correspondent pleinement aux champs de la table de base de données: WP_USERS et WP_USERMETA (descriptions de table).
Ceci est une fonction pluggable - c'est-à-dire Il peut être remplacé à partir du plugin. Cela signifie que cela fonctionnera (connecté) uniquement après la connexion de tous les plug-ins et jusqu'à ce point, la fonction n'est pas encore définie ... Par conséquent, il est impossible d'appeler cette fonction en dépendant directement à partir du code du plug-in. . Ils doivent être appelés à travers les plugins de crochet ou plus tard, par exemple, Hook init.
Remplacement de la fonction (redéfinition) - Dans le plug-in, vous pouvez créer une fonction avec le même nom, puis remplacera la fonction actuelle.
✈ 1 fois \u003d 0.000296C \u003d vite | 50000 fois \u003d 0.78C \u003d très vite | PHP 7.1.2RC1, WP 4.7.2
Pas de crochets.
Retour
Wp_user / faux. Objet de données ou faux, sinon réussi à trouver l'utilisateur spécifié.
Utilisant
get_userdata ($ userid); $ Userid. (numéro) (obligatoire) L'ID utilisateur dont les données doivent être obtenues.Par défaut: Non
Exemples
# 1 Comment générer des données de l'objet de données reçu
$ user_info \u003d get_userdata (1); Echo "Nom d'utilisateur:". $ user_info-\u003e user_login. "\\ n"; Echo "Niveau d'accès:". $ user_info-\u003e user_level. "\\ n"; ECHO "ID:". $ user_info-\u003e id. "\\ n"; / * Sautera: Nom d'utilisateur: Admin Accès Niveau: 10 ID: 1 * /# 1.2 Données dans la variable
Un autre exemple, seulement ici, je vais d'abord écrire des données en variables, puis supprimerez de l'écran:
$ utilisateur \u003d get_userdata (1); $ nom d'utilisateur \u003d $ utilisateur-\u003e user_login; $ Premier_name \u003d $ utilisateur-\u003e nom_nuaire; $ Last_name \u003d $ utilisateur-\u003e last__name; Echo "$ Premier_Name $ $ Last_Name est allé sur le site sous Login: $ nom d'utilisateur."; / * Objet $ utilisateur: WP_USER Object (\u003d\u003e Objet STDCLASS (\u003d\u003e 80 \u003d\u003e Kogian \u003d\u003e $ P $ BJFHKJFUKYWV1TWALLSNYU0JGNSQ. \u003d\u003e Kogian \u003d\u003e [Email protégé] \u003d\u003e http://example.com/ \u003d\u003e 2016-09-01 00:34:42 \u003d\u003e \u003d\u003e \u003d\u003e \u003d\u003e kogian) \u003d\u003e 80 \u003d\u003e tableau (\u003d\u003e 1) \u003d\u003e wp_capabilities \u003d\u003e Array (\u003d\u003e Abonné) \u003d\u003e Array (\u003d\u003e 1 \u003d\u003e 1 \u003d\u003e 1) \u003d\u003e \u003d\u003e 1) * /
Méthodes de classe # 2
L'objet résultant avec GET_USERDATA () est une instance de la classe et ses méthodes peuvent être utilisées. Parfois, il peut être utile. Voici un exemple simple d'obtention de l'option utilisateur, à l'aide de la méthode $ utilisateur-\u003e get ():
$ utilisateur \u003d get_userdata (1); echo $ nom d'utilisateur \u003d $ utilisateur-\u003e obtenir ("user_login");
Liste de certaines méthodes:
- set_role ($ rôle) - définit le rôle de l'utilisateur;
obtenir ($ clé) - renvoyer la valeur de l'option;
has_prop ($ clé) - vérifie si l'option spécifiée est installée;
has_cap ($ cap) - vérifie si l'utilisateur a la possibilité ou le rôle spécifié;
get_role_caps () - Obtient toutes les fonctionnalités du rôle de l'utilisateur et les combine avec des capacités utilisateur individuelles;
add_role ($ rôle) - ajoute un rôle à l'utilisateur;
retirer_role ($ rôle) - supprime le rôle de l'utilisateur;
Remarques
Voici quelques valeurs utiles des tables WP_USERS et WP_USERMETA, que vous pouvez utiliser pour obtenir des données:
- afficher un nom.
user_meta.
-
description de l'utilisateur.
wp_capabilités (tableau)
admin_color (panneau d'administration thématique. Par défaut - frais (frais))
ferméboxes_page.
- source_Domain.
Il convient également de noter qu'à partir de la version 3.2., Les données renvoyées ont changé un peu: l'objet WP_USER est renvoyé. Les données de l'objet sont divisées en groupes: données, capuchons, rôles (plus tôt, les données ont été renvoyées dans la liste globale).
Cependant, grâce aux méthodes "Magic" (Service) de PHP, des données peuvent être obtenues comme avant, par exemple, les données sont désormais stockées comme suit: get_userdata (1) -\u003e Data-\u003e rich_diting, mais vous pouvez les obtenir comme Ceci: get_userdata (1) -\u003e rich_endata, malgré le fait que Var_Dump () ne montrera pas cette relation.