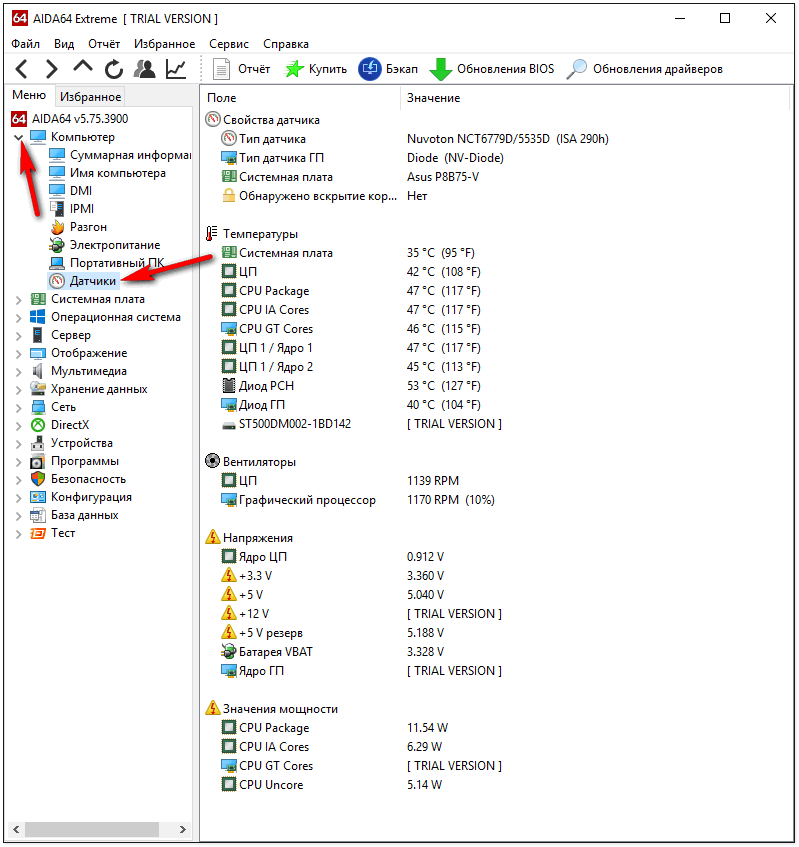
Post-relationalmodel
The classical relational model assumes the indivisibility of data stored in the fields of table entries. The post-relational model is an extended relational model that removes the restriction of the indivisibility of data. The model allows multi-valued fields - fields whose values \u200b\u200bconsist of subvalues. The set of values \u200b\u200bof multi-valued fields is considered an independent table embedded in the main table.
In fig. 2.6 on the example of information about invoices and goods for comparison, the presentation of the same data using the relational (a) and post-relational (b) models. It can be seen from the figure that, compared with the relational model, in the post-relational model, data is stored more efficiently, and processing does not require the operation of joining data from two tables.
Consignment notes Consignment goods
|
N waybill |
Customer |
N waybill |
amount |
||
Overhead
|
N waybill |
Customer |
amount |
|
Fig. 2.6. Data structures of relational and post-relational models
Since the post-relational model allows storing abnormalized data in tables, the problem of ensuring the integrity and consistency of data arises. This problem is solved by including appropriate mechanisms in the DBMS.
Virtuea post-relational model is the ability to represent a collection of related relational tables with one post-relational table. This provides high visibility of the presentation of information and increase the efficiency of its processing.
Disadvantagepost-relational model is the complexity of solving the problem of ensuring the integrity and consistency of stored data.
The considered post-relational data model is supported by uniVers DBMS. Other DBMSs based on the post-relational data model also include Bubba and Dasdb.
Multidimensional model
A multidimensional approach to the presentation of data appeared almost simultaneously with relational, but interest in multidimensional DBMSs has become widespread since the mid-90s. The impetus was in 1993, an article by E. Codd. It formulated 12 basic requirements for OLAP systems (OnLine Analytical Processing - operational analytical processing), the most important of which are related to the capabilities of conceptual presentation and processing of multidimensional data.
The following two areas can be distinguished in the development of information systems concepts:
Systems of operational (transactional) processing;
Analytical processing systems (decision support systems).
Relational DBMSs were intended for information systems of operational information processing and are very effective in this area. In systems of analytical processing, they proved to be somewhat clumsy and not flexible enough. More effective here are multidimensional DBMS.
Multidimensional DBMSs are highly specialized DBMSs designed for interactive analytical processing of information. The main concepts used in these DBMSs are: aggregability, historicity and predictability.
Aggregabilitydata means consideration of information at various levels of its generalization. In information systems, the degree of detail of the presentation of information for the user depends on his level: analyst, user, manager, leader.
Historicitydata involves ensuring a high level of static data itself and their relationships, as well as the binding of data to time.
Predictabilitydata involves setting forecasting functions and applying them to different time intervals.
The multidimensionality of the data model does not mean the multidimensionality of digital data visualization, but the multidimensional logical representation of the information structure in the description and in data manipulation operations.
Compared to the relational model, multidimensional data organization has higher visibility and information content. For illustration in fig. 2.7 shows the relational (a) and multidimensional (b) representations of the same data on car sales.
Basic concepts of multidimensional data models: measurement and cell.
Measurement- this is a lot of the same type of data forming one of the faces of a hypercube. In a multidimensional model, measurements play the role of indices that serve to identify specific values \u200b\u200bin hypercube cells.
Cell- this is a field whose value is uniquely determined by a fixed set of measurements. The type of field is most often defined as digital. Depending on how the values \u200b\u200bof a certain cell are formed, it can be a variable (values \u200b\u200bchange and can be downloaded from an external data source or generated programmatically) or by a formula (values, like formula cells of spreadsheets, are calculated using predetermined formulas).
Fig. 2.7. Relational and multidimensional data representation
In the example in fig. 2.7 b each cell value Volume of salesuniquely determined by a combination of time measurement Sales monthand car models. In practice, more measurements are often required. An example of a three-dimensional data model is shown in Fig. 2.8.
Fig. 2.8. 3D model example
The existing multidimensional DBMS uses two main schemes for organizing data: hypercubic and polycubic.
AT polycubicthe scheme assumes that several hypercubes with different dimensions and with different dimensions as faces can be defined in the database. An example of a system that supports the polycubic version of the database is Oracle Express Server.
When hypercubicthe scheme assumes that all cells are determined by the same set of measurements. This means that if there are several hypercubes in the database, they all have the same dimension and the same dimensions.
The main worthmultidimensional data model is the convenience and efficiency of analytical processing of large amounts of data related to time.
Disadvantagemultidimensional data model is its bulkiness for the simplest tasks of the usual operational processing of information.
Examples of systems that support multidimensional data models are Essbase, Media Multi - matrix, Oracle Express Server, Cache. There are software products, such as Media / MR, that allow you to simultaneously work with multidimensional and relational databases.
Object oriented model
In an object-oriented model, when presenting data, it is possible to identify individual database records. Relationships between records and their processing functions are established using mechanisms similar to the corresponding tools in object-oriented programming languages.
The standardized object-oriented model is described in the recommendations of the ODMG -93 standard (Object Database Management Group - an object-oriented database management group).
Consider a simplified model of an object-oriented database. The structure of an object-oriented database is graphically representable in the form of a tree, the nodes of which are objects. Properties of objects are described by some standard type or user-constructed type (defined as class). The value of a property of type class is an object that is an instance of the corresponding class. Each instance object of a class is considered a descendant of the object in which it is defined as a property. An instance object of a class belongs to its class and has one parent. Generic relationships in the database form a connected hierarchy of objects. An example of the logical structure of an object-oriented library database is shown in Fig. 2.9. Here is an object of type Libraryis parent to class instance objects Subscriber, Catalogand Issue. Various type objects Of booksthey may have one or different parents. Type objects Bookhaving the same parent must differ by at least the inventory number (unique to each copy of the book), but have the same property values isbn udk, the namee and author.
The logical structure of an object-oriented database looks similar to the structure of a hierarchical database. The main difference between the two is data manipulation methods.
To perform actions on data in the database model under consideration, logical operations are used, reinforced by object-oriented mechanisms of encapsulation, inheritance, and polymorphism.
Encapsulationlimits the scope of a property name to the scope of the object in which it is defined. So if in an object of type Catalogadd a property that sets the phone number of the author of the book and has a name phone, then we get the same properties for objects Subscriberand Catalog. The meaning of this property will be determined by the object in which it is encapsulated.
Inheritance, on the contrary, extends the scope of the property to all descendants of the object. So, to all objects of type Bookthat are descendants of an object of type Catalog, you can attribute the properties of the parent object: isbn, udk, titleand author. If it is necessary to extend the effect of the inheritance mechanism on objects that are not immediate relatives (for example, between two descendants of the same parent), then an abstract property of the type is defined in their common ancestor abs. So, defining abstract properties ticketand numberin the facility Libraryleads to the inheritance of these properties by all child objects Subscriber, Bookand Extraditionbut. It is no coincidence that is why property values ticketgrades Subscriberand Issueshown in fig. 2.9 are the same - 00015.
Polymorphismin object-oriented programming languages \u200b\u200bmeans the ability of the same program code to work with heterogeneous data. In other words, it means that it is permissible for objects of different types to have methods (procedures or functions) with the same name. During the execution of an object program, the same methods operate on different objects depending on the type of argument. In relation to the considered example, polymorphism means that objects of class Bookhaving different parents from class Catalogmay have a different set of properties. Therefore, programs for working with class objects Bookmay contain a polymorphic code.
A search in an object-oriented database is to find out the similarities between the object specified by the user and the objects stored in the database.

Fig. 2.9. The logical structure of the library database
The main worththe object-oriented data model in comparison with the relational model is the ability to display information about the complex relationships of objects. An object-oriented data model allows you to identify a single database record and determine the processing functions.
Disadvantagesobject-oriented models are high conceptual complexity, inconvenience of data processing and low query execution speed.
Object-oriented DBMS include POET, Jasmine, Versant, O 2, ODB - Jupiter, Iris, Orion, Postgres.
When submitting data to OOMD, it is possible to identify individual database records. Relationships between database records and their processing functions are established using mechanisms similar to the corresponding tools in object-oriented programming languages.
The standardized object-oriented model is described in the recommendations of the ODMG-93 standard (Object Database Management Group - an object-oriented database management group). It is not yet possible to fully implement the recommendations of ODMG-93. To illustrate key ideas, we consider a somewhat simplified model of an object-oriented database.
The structure of an object-oriented database (OBD) is graphically representable in the form of a tree, the nodes of which are objects. Properties of objects are described by some standard type (for example, string) or a type constructed by the user (defined as class).
The value of a property of type string is a string of characters. The value of a property of type class is an object that is an instance of the corresponding class. Each instance object of a class is considered a descendant of the object in which it is defined as a property. An instance object of a class belongs to its class and has one parent. Generic relationships in the database form a connected hierarchy of objects.
An example of the logical structure of the library library system is shown in Fig. 2.8.
Here an object of the LIBRARY type is the parent for the instance objects of the classes SUBSCRIBER, CATALOG and ISSUE. Different objects like BOOK can have one or different parents. Objects of the BOOK type that have the same parent must differ by at least the inventory number (unique to each copy of the book), but have the same property values isbn, udk, nameand author.
Fig. 2.8. The logical structure of the library database
The logical structure of the OOBD is similar in appearance to the structure of the IDB. The main difference between the two is data manipulation methods.
To perform actions on data in the database model under consideration, logical operations are used, reinforced by object-oriented mechanisms of encapsulation, inheritance, and polymorphism. Operations similar to SQL commands can be used to a limited extent (for example, to create a database).
Creating and modifying a database is accompanied by automatic generation and subsequent adjustment of indexes (index tables) containing information for quick data retrieval.
Let us briefly consider the concepts of encapsulation, inheritance, and polymorphism as applied to an object-oriented database model.
Encapsulationlimits the scope of a property name to the scope of the object in which it is defined. So, if we add a property to the object of the CATALOG type that defines the phone number of the author of the book and has the name phone, we will get the same properties for the SUBSCRIBER and CATALOG objects. The meaning of this property will be determined by the object in which it is encapsulated.
Inheritance,on the contrary, extends the scope of the property to all descendants of the object. So, all objects of the BOOK type that are descendants of an object of the CATALOG type can be attributed to the properties of the parent object: isbn, udk, title and author. If it is necessary to extend the effect of the inheritance mechanism on objects that are not immediate relatives (for example, between two descendants of the same parent), then an abstract property of type abs is defined in their common ancestor. Thus, the definition of the abstract properties of the ticket and number in the LIBRARY object leads to the inheritance of these properties by all child objects of the SUBSCRIBER, BOOK and ISSUE. It is no coincidence therefore that the property ticketthe classes SUBSCRIBER and ISSUE shown in the figure will be the same - 00015.
Polymorphism atobject-oriented programming languages \u200b\u200bmeans the ability of the same program code to work with heterogeneous data. In other words, it means that it is permissible in objects of different types to have methods (procedures or functions) with the same name. During the execution of an object program, the same methods operate on different objects depending on the type of argument. As applied to our object-oriented database, polymorphism means that objects of the BOOK class that have different parents from the CATALOG class can have a different set of properties. Therefore, programs for working with objects of the BOOK class may contain a polymorphic code.
The search in the OBDB consists in finding out the similarities between the object specified by the user and the objects stored in the database. A user-defined object called a target object (the property of the object has type ofgoal), in the general case, it can be a subset of the entire hierarchy of objects stored in the database. The target object, as well as the result of the query, can be stored in the database itself. An example of a request for library card numbers and the names of subscribers who have received at least one book in the library is shown in Fig. 2.9.

Fig. 2.9. DB fragment with target object
The main worthOOMD in comparison with relational is the ability to display information about complex relationships of objects. OOMD allows you to identify a single database record and determine their processing functions.
The main disadvantagesOOMDs are high conceptual complexity, inconvenience of data processing and low query execution speed.
In the 90s, there were experimental prototypes of the OSBMS. Currently, there are more than 300 such DBMSs. Some systems are relatively widespread, for example, the following DBMSs: Cache (InterSystems), POET (POET Software), Jasmine (Computer Associates), Versant (VersantTechnologies), O2 (ArdentSoftware), ODB-Jupiter (Inteltek Plus Research and Production Center) ), as well as Iris, Orion, and Postgres.
In the future, the advantages of OBD should lead to their very wide distribution. To do this, it is first necessary to solve the problems of eliminating the inherent disadvantages of the ODBD: increase the flexibility of the database structure, build a clear programming language, work out the syntax for parsing queries, define several methods for accessing data, work out issues of simultaneous access, determine complex data enumeration, work out protection and data recovery. The list of problems requiring solution can be continued.
However, even after solving the aforementioned problems, the transition to OBDB will be gradual and not very fast, as it will be difficult to break away from the huge number of existing relational DBMSs for objective and subjective reasons. To make such a transition less painful will enable the inclusion of not only the object but also the relational component in the structure of the OSBMS. In addition, MMD should be introduced into the OSBMS for the formation of OLAP HD systems, which are increasingly in demand in practice.
Introduction
The emergence of the direction of object-oriented databases (OOBD) was determined primarily by the needs of practice: the need to develop complex information application systems for which the technology of previous database systems was not quite satisfactory. Of course, OOBD did not arise from scratch. The corresponding basis was provided both by previous work in the field of databases, and by the long-developing areas of programming languages \u200b\u200bwith abstract data types and object-oriented programming languages.
As regards the connection with previous work in the field of databases, the most significant impact on work in the field of OBD was made by the development of the DBMS and the next DB family chronologically behind them, which supported the management of complex objects. These works provided the structural basis for the organization of the ODBD. In this essay, OOMD and OOSUBD will be considered.
Object oriented data model
Consider one of the approaches to building a database - the use of an object-oriented data model (OOMD). Data modeling in OOMD is based on the concept of an object. OOMD is usually used in complex subject areas for the modeling of which the functionality of the relational model is lacking (for example, for design automation systems (CAD), publishing systems, etc.).
ODMG object-oriented data model differs from other models, primarily in one fundamental aspect. In an SQL data model and a true relational data model, a database is a collection of named data containers of the same generic type: tables or relationships, respectively. In an object-oriented data model, a database is a collection of objects (data containers) of any type.
When creating an object-oriented DBMS (OODBMS), different methods are used, namely:
embedding in the object-oriented language tools designed to work with the database;
extension of the existing language for working with databases with object-oriented functions;
creation of object-oriented libraries of functions for working with the database;
creating a new language and a new object-oriented data model.
The advantages of OOMD include the wide possibilities of domain modeling, expressive query language and high performance. Each object in OOMD has a unique identifier (OID - object identifier). OID lookups are significantly faster than looking up a relational table.
Among the shortcomings of OOMD, the lack of a generally accepted model, the lack of experience in the creation and operation of OOBD, the complexity of use and the lack of data protection tools should be noted.
Now let’s look at how data model support is implemented in real database management systems.
In an object-oriented model (OOM), when presenting data, it is possible to identify individual database records. Relationships are established between database records and their processing functions using mechanisms similar to the corresponding tools in object-oriented programming languages.
The standard OOM is described in the recommendations of the ODMG-93 standard (Object Database Management Group - an object-oriented database management group). It is not yet possible to fully implement the recommendations of ODMG-93. To illustrate key ideas, we consider a somewhat simplified model of an object-oriented database.
The structure of the database object is graphically represented in the form of a tree, the nodes of which are objects. Properties of objects are described by some standard type (for example, string) or a type constructed by the user (defined as class).
The value of a property of type string is a string of characters. The value of a property of type class is an object that is an instance of the corresponding class. Each instance object of a class is considered a descendant of the object in which it is defined as a property. An instance object of a class belongs to its class and has one parent. Generic relationships in the database form a related hierarchy of objects.
Basic concepts
Definition 1
Object oriented modelpresentation of data makes it possible to identify individual database records.
Database records and their processing functions are connected by mechanisms similar to the corresponding tools that are implemented in object-oriented programming languages.
Definition 2
Graphical representation The structure of an object-oriented database is a tree whose nodes represent objects.
Standard type (e.g. string - string) or a type created by the user ( class), describes object properties.
In Figure 1, the LIBRARY object is the parent for the instance objects of the CATALOG, SUBSCRIBER, and ISSUE classes. Different objects such as a BOOK may have one or different parents. Objects of the type BOOK that have the same parent must have at least different inventory numbers (unique to each copy of the book), but the same property values author, title, udk and isbn.
The logical structures of an object-oriented and hierarchical database are similar in appearance. They differ mainly in data manipulation methods.
When performing actions on data in an object-oriented model, logical operations are used that are enhanced by encapsulation, inheritance, and polymorphism. With some restriction, you can apply operations that are similar to SQL commands (for example, when creating a database).
When creating and modifying a database, the automatic generation and subsequent adjustment of indexes (index tables) that contain information for quick data retrieval is performed.
Definition 3
purpose encapsulation - restriction of the scope of a property name to the boundaries of the object in which it is defined.
For example, if a property is added to the CATALOG object that sets the author’s phone and has the name phone, then the properties of the same name will be obtained from the objects CATALOG and SUBSCRIBER. The meaning of a property is determined by the object in which it is encapsulated.
Definition 4
Inheritance, back encapsulation, is responsible for spreading the scope of the property relative to all descendants of the object.
For example, the properties of the parent object can be attributed to all BOOK objects that are descendants of the CATALOG object: author, title, udk and isbn.
If it is necessary to extend the action of the inheritance mechanism to objects that are not immediate relatives (for example, to two descendants of one parent), an abstract property of the type is defined in their common ancestor abs.
Thus, the properties number and ticket in the LIBRARY object are inherited by all child objects ISSUE, BOOK and SUBSCRIBER. That is why the values \u200b\u200bof this property of the classes SUBSCRIBER and ISSUE are the same - 00015 (Figure 1).
Definition 5
Polymorphism allows the same program code to work with heterogeneous data.
In other words, it allows in objects of different types to have methods (functions or procedures) with the same name.
Search in an object-oriented database is to determine the similarity between the object that the user sets and the objects that are stored in the database.
Advantages and disadvantages of an object-oriented model
Main advantage An object-oriented data model, in contrast to the relational model, consists in the ability to display information about the complex relationships of objects. The considered data model allows you to define a separate database record and its processing functions.
TO disadvantages Object-oriented models include high conceptual complexity, inconvenient data processing and low query execution speed.
To date, such systems are quite widespread. These include the DBMS:
- Postgres
- Orion,
- Iris
- ODBJupiter,
- Versant
- Objectivity / DB,
- ObjectStore
- Statice
- Gemstone
- G-Base.
The database technologies based on the above MDs are based on a static concept of information storage, focused on data modeling. However, new areas of technology application with complex, interconnected database objects, such as:
Computer-aided design;
Automated production;
Automated software development;
Office Information Systems;
Multimedia systems;
Geographic information systems;
Publishing systems and others have demonstrated the limited capabilities of a static concept in terms of modeling real-world objects.
For new types of complex specialized database applications, a dynamic information storage concept is effective, which allows parallel modeling of data and processes acting on this data. This allows you to take into account the semantics of the subject area and therefore most adequately describe these applications. This concept is based on an object-oriented approach that is widely used in software development. MD, which implements this concept and is based on an object-oriented paradigm (OOP), is called an object-oriented data model (OOMD).
The construction of OOMD is based on the assumption that the subject area can be described by a set of objects. Each object is a uniquely identifiable entity that contains attributes that describe the state of objects in the "real world" and related actions. The current state of an object is described by one or more attributes, which can be simple or complex. A simple attribute can have a primitive type (for example, an integer, a string, etc.) and take a literal value. A composite attribute may contain collections and / or links. A reference attribute is a relationship between objects.
A key property of an object is the uniqueness of its Identification. Therefore, each object in an object-oriented system must have its own identifier.
An Object Identifier (OID) is an internal way for a database to tag individual objects. Users who work with a dialog program for querying or viewing information usually do not see these identifiers. They are assigned and used by the DBMS itself. The semantics of the identifier in each DBMS is different. It can be either a random value or contain information necessary to search for an object in the database file, for example, the page number in the file and the offset of the object from its beginning. That identifier should be used to organize links to the object.
All objects are encapsulated, i.e., the representation or internal structure of the object remains hidden from the user. Instead, the user only knows that a given object can perform certain functions. So, for the WAREHOUSE object, methods such as ACCEPT_ GOODS, DELIVER_TOBAP, etc. can be used. The advantage of encapsulation is that it allows you to change the internal representation of objects without having to redo applications that use these objects. In other words, encapsulation implies data independence.
An object encapsulates data and functions (methods, according to OOP). Methods determine the behavior of an object. They can be used to change the state of an object by changing the values \u200b\u200bof its attributes or to create queries on the values \u200b\u200bof selected attributes. For example, there may be methods to add information about a new property intended for rent, to update employee salary information, or to print out information about a particular product.
Objects that have the same set of attributes and respond to the same messages can be grouped into the class (in the literature, the terms “class” and “type” are often used as synonyms). Each such class has its own representative - an object, which is a data element. Objects of some class are called it copies.
In some object-oriented systems, a class is also an object and has its own attributes and methods called class attributes and class methods.
The important concepts of OOP are class hierarchy and container hierarchy.
Class hierarchy implies the possibility of each class, then called a superclass, its own subclass. An example is the following chain: all programmers of an enterprise are its employees, therefore, every programmer who is an object of the PROGRAMMERS class in the framework of OOMD is also an employee, who, in turn, is an object of the EMPLOYEES class. Thus, PROGRAMMERS will be a subclass, EMPLOYEES will be a superclass. But programmers can also be divided into system and application. Consequently, the PROGRAMMERS will be a superclass to the subclasses of SIS_Programs and App_Programmers. Continuing this chain further, we obtain a class hierarchy in which each object of the subclass inherits variable instances and methods of the corresponding superclass.
There are several types of inheritance - single, multiple and selective. Single inheritance is the case when subclasses inherit from no more than one superclass. Multiple inheritance - inheritance from more than one superclass. Selective inheritance allows a subclass to inherit a limited number of properties of its superclass.
Inheritance of variable instances is called structural inheritancemethod inheritance - behavioral inheritance, and the ability to use the same method for different classes or, rather, use different methods with the same name for different classes is called polymorphism.
Object-oriented architecture also has another type of hierarchy - container hierarchy. It consists in the fact that some objects can conceptually be contained within others. So, an object of the DEPARTMENT class must contain the public variable HEADMAN, which is a link to the object of the class EMPLOYEES corresponding to the head of the department, and must also contain a link to a collection of links to objects corresponding to the employees working in this department.
In some object-oriented systems, a class is also an object and has its own attributes and methods. The general characteristics of a class are described by its attributes. Object class methods are a kind of analogue of the properties of real-world objects. Each object belonging to any particular class has these properties. Therefore, when creating an object, it is necessary to declare the class to which it belongs in order to thus determine its inherent properties.
The user and the object interact through messages. In response to each message, the system performs the corresponding method.
All relationships in the object model are made using reference attributes, which are usually implemented as OID identifiers.
Relationships in a relational database are represented by a comparison of primary and foreign keys. There are no structures in the database for the formation of associations between tables; relations are used as necessary when joining tables. On the contrary, relations form the basis of an object-oriented database, since the identifiers of the objects with which it is associated are included in each object.
In OOMD, not only traditional ties can be implemented, but also ties due to inheritance.
One-to-One Communication (1: 1)between objects A and B is implemented by adding a reference attribute on object B to object A and (to maintain referential integrity) a reference attribute on object A to object B.
One-to-many relationship (1: M) between objects A and B is implemented by adding a reference attribute to object B to an object A and an attribute containing a set of links to object A to object B (for example, a reference attribute B is added to object A (ОID2, OID3 ...), and instances of object B with OID2, OID3, ... a reference attribute A: OID1 is added.
Many-to-many relationship (M: N) between objects A and B is implemented by adding an attribute containing a set of links to each object.
In OOMD, you can use an integer-part relationship that describes that an object of one class contains objects of other classes as its parts. In the case of a production database, between the class PRODUCT and the classes DETAIL and ASSEMBLY, there would be a whole-part relationship. This connection is a many-to-many relationship with special semantics. The whole-to-part relationship is implemented, like any other many-to-many relationship, using a variety of identifiers of related objects. However, it, in contrast to the usual many-to-many relationship, has a different semantic meaning.
Since the object-oriented paradigm supports inheritance, in the OOMD it is possible to apply a connection of the “is” type and a connection of the “expand” type. The “is” relationship, which is also called the generalization-specialization relation, gives rise to a hierarchy of inheritance in which subclasses turn out to be particular cases of superclasses. This eliminates the need to describe re-inherited traits. When using communication, “extends” the subclass develops the functionality of the superclass, and is not limited to its special case.
Let's consider how such components as integrity constraints and data operations are implemented in OOMD.
Features of these components are determined by the specifics of the model. This specificity in OOMD is dictated primarily by such internal concepts as encapsulation of objects, i.e., secrecy of the internal structure, access to data only through predefined methods, class hierarchy and container hierarchy.
The specificity of the OOMD is dictated by the specifics of the object. It manifests itself in the need to group objects into classes. Each object is included in one or another class depending on the task, and one object can belong to several classes at once (for example, the PROGRAMMERS and HIGHLY PAYING families). Another specificity of an object is that it can “run over” from one class (subclass) to another. So, the SYSTEM PROGRAMMER can become APPLIED over time. Thus, the class hierarchy is not an analog of the hierarchical model, as it might have seemed earlier, but it requires the ability of the system to change the location of each object within the class hierarchy, for example, to move “up” or “down” inside this hierarchy. But a more complex process is also possible - the system must provide the ability of the object to be attached (disconnected) to an arbitrary vertex of the hierarchy at any time.
An important role in OOMD is played by constraints on the integrity of communications. For the communications in the object-oriented MD to work, the identifiers of the objects on both sides of the communication must correspond to each other. For example, if there is a connection between the SERVANTS and their CHILDREN, then there must be some guarantee that when an object describing a child is inserted into an object that displays an employee, the identifier of the latter is added to the corresponding object. This kind of link integrity, somewhat similar to referential integrity in a relational data model, is established using feedbacks. To ensure the integrity of the links, the designer is provided with a special syntactic construction necessary to specify the location of the inverse identifier of the object. The obligation to set constraints on the integrity of relationships (as well as referential integrity in a relational database) rests with the designer.
In OOMD, both the description of the data and the manipulation of it occur using the same object-oriented procedural language.
The standardization of object database technology is dealt with by the ODMG (Object Database Management Groop) group. She developed an object model (ODMG 2.0 was adopted in September 1997), which defines a standard model for the semantics of database objects. This model is of great importance because it defines the built-in semantics that an object-oriented DBMS (OOS DBMS) understands and can implement. The structure of libraries and applications using this semantics must be portable among the various OSOSMS that support this object MD. The main components of the ODMG architecture are: Object Model (OM), Object Definition Language (ODL), Object Query Language (OQL), and the ability to communicate with C ++, Java, and Smalltalk.
The data object model in accordance with the ODMG 2.0 standard is characterized by the following properties:
The basic design elements are objects and literals. Each object has a unique identifier. A literal does not have its own identifier and cannot exist separately as an object. Literals are always embedded in objects and cannot be referenced individually;
Objects and literals vary in type. Each type has its own domain, shared by all objects and literals of this type. Types may also have behavior. If a type has some behavior, then all objects of this type have the same behavior. In practice, a type can be the class from which an object is created, an interface, or a simple data type (for example, an integer). An object can be represented as an instance of a type;
The state of an object is determined by the set of current values \u200b\u200bimplemented by a variety of properties. These properties can be attributes of an object or a relationship between an object and one or more other objects;
The behavior of an object is determined by the set of operations that can be performed on the object or the object itself. Operations can have a list of input and output parameters, each of which is of a strictly defined type. Each operation can also return a typed result;
The database definition is stored in a schema written in the Object Definition Language (ODL). The database stores objects, allowing them to be shared among various users and applications.
DBMSs based on OOMD are called object-oriented DBMSs (OODBMS). These DBMS belong to the third generation DBMS * (* The history of the development of data storage models is often divided into three stages (generations): the first generation (late 1960 - early 70s) - hierarchical and network models; the second generation (approximately 1970-1980s) - the relational model; the third generation (1980s - early 2000s) - object-oriented models.).
Today, object-oriented databases are used in various organizations to solve a wide range of problems. The analysis and generalization of the accumulated experience in the field of information technology data made it possible to identify applications in which the use of object-oriented databases is justified:
The application consists of a large number of interacting parts. Each of them has its own behavior, which depends on the behavior of others;
The system must process large volumes of unstructured or complex data;
The application will provide predictable access to data, so the navigational nature of object-oriented databases will not be a significant drawback;
The need for unplanned requests is limited;
The structure of the stored data is hierarchical or similar in nature.
Currently, there are many object-oriented DBMSs in the software market. In the table. 10.6 presents some of the commercial systems of this class.
Table 10.6
Modern commercial OSOSBD,
their manufacturers and applications
One of the fundamental differences between relational and relational databases is the ability to create and use new data types. An important feature of the OSBMS is that the creation of a new type does not require modification of the base kernel and is based on the principles of object-oriented programming.
The OSOSBD kernel is optimized for operations with objects. Natural operations for him are caching objects, maintaining versions of objects, sharing access rights to specific objects. OOSMBD is characterized by higher performance on operations that require access and retrieval of data packed into objects, as compared to relational DBMSs, for which the need to select connected data leads to additional internal operations.
Of considerable importance for the OSBMS is the ability to move objects from one database to another.
When creating various applications based on OOSBMS, the built-in class structure of one or another DBMS is important. The class library supports, as a rule, not only all standard data types, but also an extended set of multimedia and other complex data types, such as video, sound, and a sequence of animation frames. Some OSOSMS have created class libraries that enable the storage and full-text search of document information (for example, Jasmine, ODB-Jupiter). An example of the basic structure of classes is shown in Fig. 10.17.
The main position in it is occupied by the TOdbObject class, which contains all the necessary properties and methods for controlling access to the database and performing indexing. All other classes override its methods, adding the correctness of the type they implement and a specific indexer.
As can be seen from fig. 10.17, in the structure there are various classes focused on the processing of documentary information - TOdbText, TOdbDocument, TODBTextDocument, etc. Each document is represented by a separate object. This ensures the natural storage of documents. One of the most important operations is to search for documents upon request. For most classes, the ability to search for objects by the value of a specific key is implemented. For the TOdbText class, the possibility of forming a search query for a phrase written in natural language is implemented.
The TOdbDocument class is a special class that can accommodate heterogeneous objects. It consists of fields, each of which has a name and is associated with an object of a certain type. The presence of this class allows the user to expand the set of types. By modifying the container object (document), you can set a specific set of fields and get a new type of Document.
On the basis of ODB-Jupiter, OSOSBMS developers created a fully-functional information retrieval system ODB-Text, which has a universal structure of stored data and a powerful search engine. The ODB-Text system is a means of collective processing of documents and maintaining a corporate archive. Among the possible applications, we will name the automation of accounting for the document management of a modern office, the construction of reference and information systems (similar to the well-known Legal databases), the maintenance of network databases, personnel records, bibliography, etc.
41. Features of the design of applied IP. Phases of development of IP. (Theme 11, pp. 100-103).
11.1.3. Features of system design of applied IP
When constructing (choosing, adapting) an information system, two basic concepts can be used, two basic approaches (the third concept is their combination):
1. focus on problems that need to be addressed using this information system, i.e. a problem-oriented approach (or an inductive approach);
2. focus on technology that is available (updated) in a given system, environment, i.e. technology-oriented approach (or deductive approach).
The choice of concept depends on strategic (tactical) and (or) long-term (short-term) criteria, problems, resources.
If at first the possibilities of the available technology are studied, and then the actual problems that can be solved with their help are determined, then it is necessary to rely on a technology-oriented approach.
If, first, urgent problems are identified, and then a technology sufficient to solve these problems is introduced, then a problem-oriented approach should be relied on.
At the same time, both concepts of building an information system depend on each other: the introduction of new technologies changes the problems to be solved, and the change in problems solved leads to the need to introduce new technologies; both that and another influences the made decisions.
System design (development) and the use of any applied (corporate) information system must go through the following life cycle of an information system:
- pre-project analysis (experience in creating other similar systems, prototypes, differences and features of the developed system, etc.), analysis of external manifestations of the system;
- intrasystem analysis, internal analysis (analysis of system subsystems);
- systemic (morphological) description (representation) of the system (description of the systemic purpose, systemic relationships and relationships with the environment, other systems and systemic resources - material, energy, informational, organizational, human, spatial and temporal);
- determination of the criteria of adequacy, effectiveness and sustainability (reliability);
- a functional description of the subsystems of the system (description of models, algorithms for the functioning of the subsystems);
- prototyping (mock description) of the system, evaluating the interaction of the subsystems of the system (developing a mockup - implementing subsystems with simplified functional descriptions, procedures, and testing the interaction of these mockups to meet the system goal), while it is possible to use “mock-ups” of criteria of adequacy, stability, efficiency ;
- "assembly" and testing of the system - the implementation of full-fledged functional subsystems and criteria, evaluation of the model according to the formulated criteria;
- functioning of the system;
- determination of the goals of further development of the system and its applications;
- system maintenance - clarification, modification, expansion of the system's capabilities in the mode of its functioning (with the goal of its evolution).
These stages are basic for information systems reengineering.
The development of a corporate information system is usually carried out for a well-defined enterprise. Features of the subject activity of the enterprise, of course, will affect the structure of the information system. But at the same time, the structures of different enterprises are generally similar to each other. Each organization, regardless of its type of activity, consists of a number of units that directly carry out a particular type of company activity. And this situation is true for almost all organizations, no matter what type of activity they are engaged in.
Thus, any organization can be considered as a set of interacting elements (units), each of which can have its own, quite complex structure. The relationship between units is also quite complicated. In the general case, there are three types of relationships between business units:
Functional relationships - each unit performs certain types of work within the framework of a single business process;
Information communications - units exchange information (documents, faxes, written and oral instructions, etc.);
External relations - some units interact with external systems, and their interaction can also be both informational and functional.
The common structure of different enterprises allows us to formulate some common principles for building corporate information systems.
In general, the process of developing an information system can be considered from two points of view:
By time, or by stages of the life cycle of the developed system. In this case, we consider the dynamic organization of the development process, described in terms of cycles, stages, iterations, and stages.
The enterprise information system is being developed as a project. Many features of project management and the project development phase (life cycle phase) are common, not depending not only on the subject area, but also on the nature of the project (it does not matter whether it is an engineering project or an economic one). Therefore, it makes sense to first consider a number of general project management issues.
A project is a time-limited, purposeful change in an individual system with initially clearly defined goals, the achievement of which determines the completion of the project, as well as with the established requirements for the timing, results, risk, framework for spending funds and resources and for the organizational structure.
Usually for a complex concept (which, in particular, is the concept of a project), it is difficult to give an unambiguous wording that fully covers all the features of the introduced concept. Therefore, the above definition does not pretend to uniqueness and completeness.
The following main distinguishing features of the project as a management object can be distinguished:
Variability is a purposeful transfer of a system from an existing to some
desired state described in terms of project objectives
Limitations of the ultimate goal;
Limited duration;
Limited budget;
Limited resources;
Novelty for the enterprise for which the project is being implemented;
Complexity - the presence of a large number of factors that directly or indirectly affect the progress and results of the project;
Legal and organizational support - the creation of a specific organizational structure for the duration of the project.
Efficiency of work is achieved by managing the project implementation process, which ensures the distribution of resources, coordination of the work sequence and compensation of internal and external disturbances.
From the point of view of the theory of control systems, the project as a control object should be observable and manageable, that is, there are some characteristics that can be used to constantly monitor the progress of the project (property of observability). In addition, mechanisms are needed for timely impact on the course of project implementation (manageability property).
The property of controllability is especially relevant in conditions of uncertainty and variability of the subject area, which often accompany projects for the development of information systems.
Each project, regardless of the complexity and scope of work necessary for its implementation, undergoes certain states in its development: from the state when “the project is not yet” to the state when “the project is already gone”. The set of stages of development from the idea to the complete completion of the project is usually divided into phases (stages, stages).
There are some differences in determining the number of phases and their contents, since these characteristics largely depend on the conditions for the implementation of a particular project and the experience of the main participants. Nevertheless, the logic and main content of the process of developing an information system in almost all cases are common.
The following phases of information system development can be distinguished:
Formation of the concept;
Development of technical specifications;
Design;
Manufacture;
Putting the system into operation.
Let's consider each of them in more detail. The second and partially third phases are called phases of system design, and the last two (sometimes include the design phase here) - implementation phases.
Conceptual phase
Formation of ideas, setting goals;
Formation of a key project team;
Studying the motivation and requirements of the customer and other participants;
Collection of initial data and analysis of the existing state;
Definition of the basic requirements and restrictions, required material, financial and labor resources;
Comparative evaluation of alternatives;
Submission of proposals, their examination and approval.
Development of a technical proposal
Development of the main content of the project, the basic structure of the project;
Development and approval of technical specifications;
Planning, decomposition of the basic structural model of the project;
Estimation and budget of the project, determination of resource requirements;
Development of calendar plans and enlarged work schedules;
Signing a contract with a customer;
Putting into operation communication tools of project participants and monitoring the progress of work.
Design
At this phase, subsystems are determined, their interconnections, the most effective ways of project implementation and resource use are selected. Characteristic work of this phase:
Implementation of basic design work;
Development of private technical tasks;
Performing conceptual design;
Drawing up technical specifications and instructions;
Presentation of design development, examination and approval.
Development
At this phase, coordination and operational control of the project is carried out, subsystems are manufactured, their integration and testing are carried out. Main content:
Performing software development;
Preparation for the implementation of the system;
Monitoring and regulation of the main indicators of the project.
Putting the system into operation
At this phase, tests are carried out, trial operation of the system in real conditions, negotiations are underway on the results of the project and on possible new contracts. The main types of work:
Comprehensive tests;
42. The concept of the life cycle of IP. (Theme 11, pp. 103-105).