At the initial stage of the development of the Internet, users were a privileged minority and the amount of information available was relatively small. At that time, access was mainly provided to employees of various large educational institutions and laboratories, and the data obtained was used for scientific purposes. At that time, the use of the Network was not as relevant as it is now.
Research routes are very important for maintaining servers. Imagine that you are looking for the “history of Brazil”: according to the preliminary filter, there are probably pages containing the terms “history”, “make” and “Brazilian”. However, before talking about the order, let's understand what the results page looks like and what you can find in it.
Search Types: Horizontal and Vertical
Here is one of the fragments of our search. In some cases, fragments have special elements, for example, what we call “site links” and are shown in the image above. We call vertical searches, search engines with specific goals. An index is a great example of a vertical search engine, as we will find information about addresses and places to visit in it.
In 1990 British scientist Tim Berners-Lee (who is also the inventor of URI, URL, HTTP, World Wide Web) created the site info.cern.ch, which is the world's first accessible directory of internet sites. From this moment, the Internet began to gain popularity not only among the scientific community, but also among ordinary owners of personal computers.
How is the base fragment formed?
When searching in “Brazil”, vertical searches for maps and images appear. Now you may wonder: where do you see these elements? A website address is an obvious tool that needs no explanation. A small description can come from two places: from the description meta tag or excerpts from the contents of this page, i.e. summary.
Most often, find breadcrumbs instead of a website address. We chose exactly what is the main one, so you understand the operation. And what is the most important result, if not the answer to what we ask? The most relevant result is one that brings more information and more succinctly describes the term you are looking for.
Thus, the first way to facilitate access to information resources on the Internet was the formation of directory sites. Links to resources in them were grouped by topic.
The first project of this kind is considered to be Yahoo, open in April 1994. Due to the rapid growth in the number of sites in it, it soon became possible to search for the necessary information on request. Of course, this was not yet a complete search engine. The search was limited only to the data that was in the directory.
Whenever we do a search, we like that the result is the page we are looking for. Now this may make sense because all pages have a “Brazilian history” in the title: this is because the result must match the search. Obviously, many other factors will be taken into account, and there is no way to determine without prior thorough analysis why these and not other sites are well located. Other factors that are very important for positioning are the content of the site and how rich it is with keywords, the number of links received, the anchor of these links, as well as the authority of the sites and pages on which the links were made.
In the early stages of the development of the Internet, link directories were used very actively, but gradually lost their popularity. The reason is simple: even if there are many resources in modern directories, they still show only a small part of the information available on the Internet. For example, the largest network directory is - DMOZ (Open Directory Project). It contains information on just over five million resources, which is incommensurable with the Google search base, which contains more than eight billion documents.
Learn more about this portal, which is so popular in South Korea.
It was the first Korean web portal launched with its own search engine. The first is a site created for children, which allows them to play and study online in a safe and healthy environment for them. The second is an online donation site, this allows sponsors and people who need help to find each other.
These two are pioneers in their categories in South Korea. This is due to the fact that every day, thousands of millions of requests are made using the Internet. The top 10 positions are most in demand, they receive 94% of all clicks. This means that positioning on the second page is already a losing battle. If the site is not easy to find and is in a position further than on the second page, it practically does not exist for users.
The largest Russian-language catalog is the Yandex catalog. It contains information on a little over one hundred and four thousand resources.
Search Engine Development Timeline
1945 year - American engineer Vannevar Bush published notes of an idea that later led to the invention of hypertext, and a discussion about the need to develop a system for quickly extracting data from thus stored information (the equivalent of today's search engines). The concept of a memory expander introduced by him contained original ideas, which, in the end, were embodied on the Internet.
What is organic search and paid search?





- Getting more visitors to your site.
- Enhances the authenticity of your business.
- Creates a more commercial image.
1960s - Gerard Salton and his team at Cornell University developed the SMART information retrieval system. SMART is the abbreviation for Salton’s Magic Automatic Retriever of Text, that is, “Salton’s Magic Automatic Text Extractor.” Gerard Salton is considered the father of modern search technology.
1987-1989 - developed Archie - A search engine for indexing FTP archives. Archie was a script automating the introduction of listings on ftp-servers, which were then transferred to local files, and only then in the local files a quick search of the necessary information was carried out. The search was based on the standard Unix grep command, and user access to the data was based on telnet.
Before choosing between two models, you need to consider a few points. These agencies often have access to the latest search engine information that other companies usually do not have. Do you know, for example, what? China, due to its size and growth dynamics, is a very attractive market, but because of its past and how it opens to the West, it raises a number of problems and obstacles when an entrepreneur decides to do business there.
If the goal is to promote a particular product in the Chinese market, the Internet is undoubtedly a channel for consideration, but how? How is the payment process? It's simple, how to fill out a form? If we assume that in terms of effectiveness the search channel presents the results that it shows in the Western world, then marketing through search engines is undoubtedly an acceptable option.
In the next version, the data was divided into separate databases, one of which contained only textual file names; and the other - records with links to hierarchical directories of thousands of hosts; and another one connecting the first two. This version of Archie was more effective than the previous one, since the search was performed only by file names, excluding many previously existing repeats.
What is the dominant search engine in the Chinese market? The bad news is that opening an account is not an easy process. In this contact, documentation on registration of the company will be requested to confirm identity.
These documents must be submitted in Chinese. It is also necessary to make a transfer of about 750 euros. It is important to note that there is no English version of the site or platform, therefore human resources are needed that know the Chinese language. An alternative would be to use an American company.
The search engine was becoming more popular, and the developers thought about how to speed up its work. The database mentioned above has been replaced by another, based on the theory of a compressed tree. The new version essentially created a full-text database instead of a list of file names and was significantly faster than before. In addition, minor changes allowed the Archie system to index web pages. Unfortunately, for various reasons, work on Archie soon ceased.
The Chinese search engine wants to catch rivals and lead the next technological revolution - artificial intelligence. But there are still obstacles to overcome, for example, the fact that the company does not have much information about its users.
The company claims that the artificial intelligence revolution will be the next “industrial revolution", although it recognizes that it is already late for the "mobile" revolution. The company relies on artificial intelligence, which wants to become the leader of this technology in the East, attracting Chinese users, who make up the world's largest population in terms of content creation, a vital resource for research in the field of artificial intelligence. Last year, the company launched a news feed under the results panel, which tracks user interests and sets recommendations if users register.
In 1993 the world's first search engine for the World Wide Web was created Wandex. It was based on the World Wide Web Wanderer bot, developed by Matthew Gray of the Massachusetts Institute of Technology.
1993 year - Martin Coster creates Alliweb - One of the first search engines on the World Wide Web. Website owners had to add them to Aliweb index themselves so that they appeared in the search. Since too few webmasters did, Aliweb did not become popular.
Their initial task was to develop the most effective search engine. However, this success is sometimes accompanied by controversy. This decision of the British subsidiary of the French group intervenes after a dispute over banners and videos made on inappropriate and shocking content.
Our articles that answer search engine questions. The Tour de France, the Rio Olympics and the American election have also attracted the interest of Internet users. Three families filed a Monday complaint against social networks that they accuse of contributing to the radicalization of Omar Mateen, the author of the Orlando bombing.
April 20, 1994 - Brian Pinkerton of the University of Washington released Webcrawler - the first bot to index pages completely. The main difference between the search engine and its predecessors is the ability for users to search for any keywords on any web page. Today, this technology is the standard search for any search engine. Search engine "WebCrawler" was the first system that was known to a wide range of users. Alas, the throughput was low and in the daytime the system was often unavailable.
The flight search engine is improved with the help of an intelligent service that warns the consumer when the travel that he consults can increase and how much. Few concrete results to date, but it is a means of positioning oneself as a key player in this sector.
It has not yet been officially announced, several serious tracks appear in their usefulness. Using the “My Activities” option, the California giant gives you an overview of everything he knows about you. And allows you to delete certain personal data if you want.
July 20, 1994 - opened Lycos - A serious development in search technology, created at Carnegie Melon University. Michael Muldin was responsible for this search engine and still remains a leading specialist at Lycos Inc. Lycos opened with a catalog of 54,000 documents. And in addition to this, the results that he provided were ranked, in addition, he took into account prefixes and approximate coincidence. But the main difference between Lycos was the constantly updated catalog: by November 1996, 60 million documents were indexed - more than any other search engine of the time.
This is the second time a year when she is accused of abuse of her dominant position. Computer giant project digitizing books will resume. For users who want to protect their data, some smartphone manufacturers are developing secure terminals with information encryption and a fingerprint reader.
A huge opportunity for the engine, but also a threat. He will have to fight ad blockers. It all started with a simple question about Obama. "Well, how old is Obama?" If you quickly look at search engines today, you will notice that there are not many clusters under the keyboard.
January 1994 - was founded Infoseek. It was not truly innovative, but had a number of useful additions. One of these popular add-ons was the ability to add your page in real time.
1995 year - started Altavista. Having appeared, the search engine AltaVista quickly gained recognition from users and became a leader among their own kind. The system had almost unlimited bandwidth at that time, it was the first search engine in which it was possible to formulate queries in a natural language, as well as formulate complex queries. Users were allowed to add or remove their own URLs within 24 hours. AltaVista also offered a lot of search tips and tricks. The main merit of the AltaVista system is considered to provide support for many languages, including Chinese, Japanese and Korean. Indeed, in 1997 not a single search engine on the Web worked with several languages, especially with rare ones.
We use only multilingual language, we still have it. A small anthology of his most beautiful inventions. This list also does not include various updates, more or less important of all parts of the algorithm, which are performed very regularly. On the one hand there is the mechanics that are under the hood, the engine that we just touched. But on the other hand there is also a cockpit, options and comfort of use.
Candidates at the stand: Obama test
Some research illustrations, enriched by data collected from these products. To complete the theoretical study, a small practical example of a query made most likely, what is Obama's age? We are a lambda surfer and lazy, so we shorten our request to the shortest and forget accents and capital letters: we type "Obama's age." The test is conducted on November 12th.
1996 year - The search engine AltaVista launched a morphological extension for the Russian language. In the same year, the first domestic search engines were launched - Rambler.ru and Aport.ru. The appearance of the first domestic search engines marked a new stage in the development of the Runet, allowing Russian-speaking users to query in their native language, as well as respond quickly to changes occurring within the Web.
Moreover, images and data are not enriched, it is sober, the display makes us go back a little visually. An unsuccessful attempt to enrich the data at the very top of the mini-bio, but this does not answer the question, as well as the news column that does not understand the request. The same as before, visually it is a bit from the Internet.
As a result, the search results are very low, and we need to scroll to go, not very practical. However, be careful, this test is carried out with only one search, it is strictly empirical and does not intend to be an exhaustive study of the quality of search results.
May 20, 1996 - Inktomi Corporation appeared along with its search engine Hotbot. Its creators were two teams from the University of California. When the site appeared, it quickly became popular. In October 2001, Danny Sullivan wrote an article titled “Inktomi's Spam Sites Database is Open for Public Use,” describing how Inktomi accidentally made its spam sites database, which by then already had about 1 million URLs available for universal use.
1997 year - in Western countries there comes a turning point in the development of search engines when S. Brin and L. Page from Stanford University founded Google (original name of the BackRub project). They developed their own search engine, which gave users the opportunity to carry out high-quality searches taking into account morphology, spelling errors, as well as increase relevance in the results of queries.
September 23, 1997 - announced Yandex, which quickly became the most popular search engine among Russian-speaking Internet users. With the launch of the Yandex search engine, domestic search engines began to compete with each other, improving the search and indexing of sites, issuing results, as well as offering new services
Thus, the development of search engines and their formation can be characterized by the stages listed above.
To date, three leaders have settled in the global market - Google, Yahoo and Bing. They have their own bases, and their search algorithms. Many other search engines use the results of these three major search engines. For example, AOL uses the Google database while AltaVista, Lycos and AllTheWeb use the Yahoo database. All other search engines in various combinations use the results (results) of the listed systems.
If we conduct a similar analysis of search engines popular in the CIS countries, we will see that mail.ru broadcasts Google search, while superimposing its new best practices, Rambler, in turn, broadcast Yandex. Therefore, the entire Runet market can be divided between these two giants.
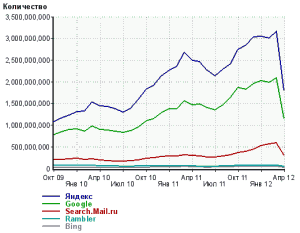
That is why, in the CIS countries, website promotion, as a rule, is carried out only in these two substations.
Andrew
really good
Igor Kokorev
Good story
Modern search engines are simple and easy to use, which their predecessors could not boast of. Finding the necessary information with their help was extremely difficult, they required huge, at that time, network resources, disabling the web server.
Today, the search engine is one of the most widely used methods of navigation in cyberspace. It is a website that provides the ability to search for information on the Internet. Its main part is a search engine, or a search engine - a set of programs that provides the functionality of a search engine. The main criteria for the quality of the search engine are the degree to which the query matches the result found, the completeness of the database, and the morphology of the language.
First on the internet
The first Internet search engine appeared in 1989, its author was a student of computer science at the University of Montreal. Mack Gilla Alan Emtage. The first search engine was called Archie (from the distorted word archive - “archive”). The program collected the file names of public ftp-servers into a single database. However, the Archie files themselves were not indexed.
The next step in the history of search engines was the emergence of the Gopher network protocol. Its author was Mark Mack Cahill of the University of Minnesota. The protocol indexed text documents and provided access to them on the Internet.
A little later, two scientists from the University of Nevada, Fred Barry and Stephen Foster, developed the Veronica program. Veronica could search by keyword among the document names listed in Gopher.
Shortly after its appearance, another search tool was created - Jughead. It had similar functionality as Veronica did, but logical search capabilities were added to it. Jughead allowed to receive the information menu from various Gopher servers.
The first network robot
In 1993, Matthew Gray, a student at the Massachusetts Institute of Technology, created the first robot to index Internet pages. It was called the World Wide Web Wanderer, literally - "the wanderer on the World Wide Web." Previously, the inventory of network resources was compiled manually. The program allowed to recount web servers, measuring the scale of the Web. The database of sites, collected using the first robot, was called Wandex. However, over time, this database has become increasingly less searchable, and has gradually lost relevance to users. The first generation search robots were extremely slow and simply could not keep up with the growth of the World Wide Web. Problems with the automatic collection of information led to the emergence of a fundamentally different concept of the search engine. This is how the ALIWEB system came about - the first global catalog (or directory) of World Wide Web resources. Its database was filled not by a robot program, but by the owner of a site or web page.
Profitable business
After businessmen realized that they could benefit from the Internet, intensified funding for the development of search engines began. More and more search engines with an improved set of functions began to appear.
So, in 1993, six Stanford students introduced Excite. The program used statistical analysis of words in the text to facilitate the search process on the Internet. A year later, the Galaxy Network came into being - the first searchable online directory. In the same 1994, the WebCrawler program was introduced. It was the first search engine to index all the text of websites. Unlike its predecessors, it allowed users to search for any keywords on any web page - since then it has become the standard in all major search engines. In addition, it was the first search engine that was known to a wide range of users. At the same time, Dr. Michael Moldin developed the Lycos search engine. Along with search results, she offered links to topics related to the search query. In 1995, AltaVista appeared, which was the first to offer an advanced search system. In addition, she accepted language queries in the so-called “natural language”, that is, Alta Vista could search not only for one keyword, but for a whole phrase. In addition, the system offered the ability to search for images, music and video files.
In a sense, all of these search engines competed with popular online directories such as Yahoo !. Yahoo! appeared in 1994. Its authors were Jerry Young and David Filo. The project began by compiling a catalog of their favorite websites. The only thing that distinguished this list from the others was a comment on each URL link. A year later, the developers received funding and created Yahoo !.
The first search engines became available to Runet users in 1996. These were a morphological extension to the Altavista search engine and the original Russian search engines Rambler and Aport.