L'éditeur de flux sed est un éditeur de texte non interactif qui effectue des opérations sur les données provenant d'une entrée standard ou d'un fichier. Sed édite les informations ligne par ligne.
Les bases du travail avec l'éditeur sed ont été décrites. Ce guide couvre des techniques plus avancées.
Fusionner des équipes
Parfois, il devient nécessaire de passer plusieurs commandes à l'éditeur sed en même temps. Cela se fait de plusieurs manières.
Si vous ne disposez pas déjà d'un fichier de test pour travailler avec sed, créez l'environnement suivant :
CD
cp /usr/share/common-licenses/BSD .
cp /usr/share/common-licenses/GPL-3 .
echo "c'est la chanson qui ne finit jamais
ne sachant pas ce que c'était
juste parce que..." > ennuyeux.txt
Puisque sed fonctionne sur des entrées et sorties standard, vous pouvez bien sûr simplement appeler les différentes commandes sed ensemble sur la même ligne :
sed "s/et/\&/" ennuyeux.txt | sed "s/personnes/chevaux/"
oui, ça continue encore et encore, mon ami
certains chevaux ont commencé à le chanter
ne sachant pas ce que c'était
Et ils continueront à le chanter pour toujours
juste parce que...
Cette méthode fonctionnera, mais plusieurs appels à sed créent une surcharge, occupent plus d'espace et ne profitent pas des fonctionnalités intégrées de sed.
Vous pouvez envoyer plusieurs commandes à sed en même temps en utilisant l'option –e, qui doit être insérée avant chaque commande :
sed -e "s/and/\&/" -e "s/people/horses/" ennuyeux.txt
Vous pouvez également concaténer des commandes dans une chaîne à l'aide du caractère point-virgule. Cette méthode fonctionne exactement de la même manière que la précédente.
sed "s/et/\&/;s/people/horses/" ennuyeux.txt
Notez que l'utilisation de l'indicateur -e nécessite de casser les guillemets simples, mais l'utilisation d'un point-virgule permet à toutes les commandes d'être répertoriées entre guillemets simples.
Ces deux méthodes pour appeler plusieurs commandes à la fois sont assez pratiques, mais il arrive parfois que vous deviez utiliser une simple ligne de commande.
Vous devez également être familier avec l'opérateur =. Cette instruction insère un numéro de ligne entre chaque ligne existante. Le résultat ressemble à ceci :
sed "=" ennuyeux.txt
1
c'est la chanson qui ne finit jamais
2
oui, ça continue encore et encore, mon ami
3
certaines personnes ont commencé à le chanter
4
ne sachant pas ce que c'était
5
et ils continueront à le chanter pour toujours
6
juste parce que...
Essayez maintenant de modifier le texte pour comprendre comment le format de numérotation change.
La commande G ajoute par défaut une ligne vide entre les lignes existantes.
sed "G" ennuyeux.txt
_
c'est la chanson qui ne finit jamais
_
oui, ça continue encore et encore, mon ami
_
certaines personnes ont commencé à le chanter
_
ne sachant pas ce que c'était
_
et ils continueront à le chanter pour toujours
_
juste parce que...
Essayez de combiner ces deux commandes. Au début, il peut sembler que la sortie de ces commandes contiendra une ligne vide entre la ligne de texte et la ligne contenant un numéro. Cependant, le résultat ressemble à ceci :
sed "=;G" ennuyeux.txt
1
c'est la chanson qui ne finit jamais
_
2
oui, ça continue encore et encore, mon ami
_
3
certaines personnes ont commencé à le chanter
_
4
ne sachant pas ce que c'était
. . .
. . .
Cela se produit parce que l'opérateur = modifie le flux de sortie (ce qui signifie que la sortie résultante ne peut pas être utilisée pour une édition ultérieure).
Ceci peut être surmonté en utilisant deux appels à sed, où le premier appel sera traité comme un simple flux de texte vers le second.
sed "=" ennuyeux.txt | sed "G"
1
_
c'est la chanson qui ne finit jamais
_
2
_
oui, ça continue encore et encore, mon ami
_
3
_
certaines personnes ont commencé à le chanter
. . .
. . .
Gardez à l’esprit que certaines commandes fonctionnent de la même manière, surtout si vous combinez plusieurs commandes et que le résultat est différent de celui attendu.
Adressage avancé
L'un des avantages des commandes d'adressage de sed est qu'elles peuvent utiliser des expressions régulières comme critères. Cela signifie que vous pouvez travailler avec des fichiers dont le contenu n'est pas exactement connu.
sed "1,3s/.*/Bonjour/" ennuyeux.txt
Bonjour
Bonjour
Bonjour
ne sachant pas ce que c'était
et ils continueront à le chanter pour toujours
juste parce que...
Au lieu de cela, vous pouvez utiliser une expression régulière qui correspond uniquement aux lignes contenant un modèle particulier. Pour ce faire, vous devez placer le modèle de recherche entre deux barres obliques (/) avant la commande.
sed "/chanter/s/it/& fort/" ennuyeux.txt
c'est la chanson qui ne finit jamais
oui, ça continue encore et encore, mon ami
certaines personnes ont commencé à le chanter fort
ne sachant pas ce que c'était
et ils continueront à le chanter fort pour toujours
juste parce que...
Cet exemple place le mot fort avant le premier sur chaque ligne contenant le mot chant. Notez que les deuxième et quatrième lignes restent inchangées car elles ne correspondent pas au modèle.
L'adressage des expressions peut être rendu plus complexe. Cela rend les équipes plus flexibles.
L'exemple suivant montre comment utiliser des expressions régulières pour générer des adresses pour d'autres commandes. Cette commande trouve toutes les lignes vides et les supprime :
sed "/^$/j" GPL-3
LICENCE PUBLIQUE GÉNÉRALE GNU
Version 3, 29 juin 2007
Copyright (C) 2007 Free Software Foundation, Inc.
Tout le monde est autorisé à copier et à distribuer des copies textuelles
de ce document de licence, mais sa modification n'est pas autorisée.
Préambule
La licence publique générale GNU est une licence gratuite avec copyleft pour
. . .
. . .
Gardez à l’esprit que les expressions régulières peuvent être utilisées n’importe où dans la plage.
Par exemple, vous pouvez supprimer les lignes entre les lignes START et END :
sed "/^START$/,/^END$/d" fichier d'entrée
Sachez que cette commande supprimera toutes les lignes du premier mot START trouvé au premier mot END trouvé, et si elle rencontre ensuite à nouveau le mot START, elle continuera à supprimer les données.
Pour inverser l'adressage (c'est-à-dire sélectionner des lignes qui ne correspondent pas au modèle), utilisez un point d'exclamation (!).
Par exemple, pour supprimer une ligne remplie, vous devez saisir :
sed "/^$/!d" GPL-3
Il n’est pas nécessaire qu’une adresse soit une expression complexe pour être inversée. L'inversion fonctionne de la même manière avec une numérotation régulière.
Utiliser un tampon supplémentaire
Le tampon de maintien supplémentaire augmente la capacité de sed à effectuer une édition multiligne.
Un buffer supplémentaire est une zone de stockage temporaire pouvant être modifiée par certaines commandes.
Avoir ce tampon supplémentaire vous permet de stocker des chaînes pendant que vous travaillez sur d'autres chaînes.
Commandes pour travailler avec le tampon :
- h : copie le tampon de traitement actuel (la dernière ligne correspondante sur laquelle vous travaillez) dans un tampon supplémentaire.
- H : ajoute le tampon de traitement en cours à la fin du traitement supplémentaire en cours, séparé par un caractère \n.
- g : copie le sous-tampon actuel dans le tampon de traitement actuel. Le tampon de traitement précédent sera perdu.
- G : ajoute le modèle actuel au tampon de traitement actuel, en les séparant par le caractère \n.
- x : échange le modèle actuel et le tampon supplémentaire.
Le contenu du tampon supplémentaire ne peut pas être traité tant qu'il n'est pas déplacé vers le tampon de traitement.
Regardons un exemple complexe.
Essayez de concaténer les lignes adjacentes à l'aide de la commande suivante :
sed -n "1~2h;2~2(H;g;s/\n/ /;p)" ennuyeux.txt
Note: En fait, sed propose une commande N intégrée distincte pour cela ; mais pour la pratique, il est utile de considérer cet exemple.
L'option –n supprime la sortie automatique.
1~2h – définition de l’adresse, effectuant un remplacement séquentiel d’une ligne de texte sur deux, en commençant par la première (c’est-à-dire chaque ligne impaire). La commande h copie les lignes correspondantes dans un tampon supplémentaire.
Le reste de la commande est entouré d’accolades. Cela signifie que cette partie de la commande héritera de l'adresse qui vient d'être spécifiée. Sans ces parenthèses, seule la commande H héritera de l'adresse et les commandes restantes seront exécutées ligne par ligne.
Bien sûr, la fonction intégrée N mentionnée précédemment est beaucoup plus courte et plus simple et renvoie le même résultat :
sed -n "N;s/\n/ /p" ennuyeux.txt
c'est la chanson qui ne finit jamais oui, ça continue encore et encore, mon ami
certaines personnes ont commencé à le chanter sans savoir ce que c'était
et ils continueront à la chanter pour toujours juste parce que...
scripts sed
Les commandes peuvent être compilées en scripts. Cela vous permet d'exécuter tout un ensemble de commandes sur un modèle cible.
Par exemple, vous pouvez écrire un script pour créer des messages texte simples qui doivent être préformatés.
Vous n’aurez alors plus besoin de répéter constamment les mêmes commandes pour chaque message. Essentiellement, un script sed est une liste de commandes qui doivent être appliquées à un objet donné.
Par exemple:
s/ce/cela/g
s/neige/pluie/g
1,5s/pomme de pin/abricot/g
Ensuite, vous pouvez appeler le fichier :
sed -f sedScriptName fichierVersModifier
Conclusion
Vous connaissez maintenant des techniques plus avancées pour travailler avec sed.
Au début, les commandes sed sont difficiles à comprendre et faciles à confondre. Il est donc recommandé de les expérimenter avant de les utiliser sur des données importantes.
Mots clés: ,Auteur : Rares Aioanei
Date de publication : 19 novembre 2011
Traduction : A. Krivoshey
Date de traduction : juillet 2012
Nikolay Ignatushko a testé toutes les commandes mentionnées dans cet article sur GNU sed version 4.2.1 dans la distribution Gentoo. Tous les scripts n'ont pas bien fonctionné sur la version GNU sed. Mais c'était une question de petites choses qui ont été corrigées. Seul le scénario visant à remplacer les collines par des montagnes a dû être considérablement modifié.
1. Introduction
Bienvenue dans la deuxième partie de notre série sur sed, la version GNU. Il existe plusieurs versions de sed disponibles sur différentes plates-formes, mais nous nous concentrerons sur GNU sed version 4.x. Beaucoup d'entre vous ont entendu parler de sed ou l'ont déjà utilisé, probablement comme outil de remplacement. Mais ce n’est que l’un des objectifs de sed, et nous allons essayer de vous montrer tous les aspects de l’utilisation de cet utilitaire. Son nom signifie "Stream EDitor" et le mot "stream" dans ce cas peut signifier un fichier, un canal ou simplement stdin. Nous espérons que vous avez déjà une connaissance de base de Linux, et si vous avez déjà travaillé avec des expressions régulières, ou du moins savez ce qu'elles sont, alors tout sera beaucoup plus facile pour vous. L'espace ne nous permet pas d'inclure un didacticiel complet sur les expressions régulières ; à la place, nous couvrirons les concepts de base et donnerons de nombreux exemples sur la façon d'utiliser sed.
2.Installation
Il n’est pas nécessaire d’en dire beaucoup ici. Très probablement, vous avez déjà installé tout sed, car il est utilisé par divers scripts système, ainsi que par les utilisateurs de Linux qui souhaitent augmenter leur productivité. Vous pouvez savoir quelle version de sed vous avez installée avec la commande :
$sed --version
Sur mon système, cette commande montre que GNU sed 4.2.1 est installé ainsi qu'un lien vers la page d'accueil du programme et d'autres informations utiles. Le package est appelé « sed » quelle que soit la distribution, sauf Gentoo, où il est présent implicitement.
3. Concepts
Avant d'aller plus loin, nous pensons qu'il est important de se concentrer sur ce que fait « sed », puisque l'expression « éditeur de flux » ne nous dit pas grand-chose sur son objectif. sed prend le texte en entrée, effectue les opérations spécifiées sur chaque ligne (sauf indication contraire) et génère le texte modifié. Les opérations spécifiées peuvent être ajouter, insérer, supprimer ou remplacer. Ce n'est pas aussi simple qu'il y paraît : attention, il existe un grand nombre d'options et de combinaisons d'options qui peuvent rendre la commande sed très difficile à comprendre. Nous vous recommandons donc d’apprendre les bases des expressions régulières pour comprendre leur fonctionnement. Avant de commencer le tutoriel, nous aimerions remercier Eric Pement et les autres pour l'inspiration et pour ce qu'il a fait pour tous ceux qui souhaitent apprendre et utiliser sed.
4. Expressions régulières
Étant donné que les commandes sed (scripts) restent un mystère pour beaucoup, nous pensons que nos lecteurs devraient comprendre les concepts de base plutôt que de copier et coller aveuglément des commandes dont ils ne comprennent pas la signification. Quand on veut comprendre ce que sont les expressions régulières, le mot clé est « matching », ou plus précisément « pattern matching ». Par exemple, dans un rapport destiné à votre service, vous avez écrit le nom Nick, en référence à l'architecte réseau. Mais Nick est parti et John est venu à sa place, vous devez donc maintenant remplacer le mot Nick par John. Si le fichier de rapport s'appelle report.txt, vous devez exécuter la commande suivante :
$ rapport de chat.txt | sed "s/Nick/John/g" > report_new.txt
Par défaut, sed utilise stdout, vous pouvez utiliser l'opérateur de redirection de sortie comme indiqué dans l'exemple ci-dessus. C'est un exemple très simple, mais nous illustrons quelques points : nous recherchons toutes les correspondances avec le motif "Nick" et les remplaçons dans tous les cas par "John". Notez que les recherches sed sont sensibles à la casse, alors soyez prudent et vérifiez le fichier de sortie pour vous assurer que tous les remplacements ont été effectués. L'exemple ci-dessus pourrait s'écrire ainsi :
$ sed "s/Nick/John/g" report.txt > report_new.txt
D'accord, pourriez-vous dire, mais où sont les expressions régulières ? Oui, nous voulions d’abord montrer un exemple, et vient maintenant la partie intéressante.
Si vous n'êtes pas sûr d'avoir écrit « nick » ou « Nick » et que vous souhaitez couvrir les deux cas, vous devez utiliser la commande sed « s/Nick|nick/John/g ». La barre verticale a une signification que vous devez connaître si vous avez étudié le C, c'est-à-dire que votre expression correspondra à « nick » ou « Nick ». Comme vous le verrez ci-dessous, le canal peut être utilisé d’autres manières, mais la signification reste la même. Les autres opérateurs couramment utilisés dans les expressions régulières sont "?", qui correspond à la répétition du caractère précédent zéro ou une fois (c'est-à-dire que la saveur correspondrait à la saveur et à l'arôme), "*" - zéro ou plusieurs fois, "+" - une ou plusieurs fois. "^" correspond au début d'une ligne et "$" fait le contraire. Si vous êtes un utilisateur de vi ou vim, beaucoup de choses vous sembleront familières. Après tout, ces utilitaires, ainsi que awk et C, remontent aux débuts d'UNIX. Nous n'aborderons pas davantage ce sujet car il est plus facile de comprendre la signification de ces caractères avec des exemples, mais sachez qu'il existe diverses implémentations d'expressions régulières : POSIX, POSIX Extended, Perl, ainsi que diverses implémentations d'expressions régulières floues. des expressions qui ne manqueront pas de vous donner des maux de tête.
5. Exemples d'utilisation de sed
| Syntaxe des commandes | Description |
|
Sed "s/Nick/John/g" rapport.txt |
Remplace chaque occurrence de Nick par John dans le fichier report.txt |
|
Sed "s/Nick\|nick/John/g" rapport.txt |
Remplace chaque occurrence de Nick ou nick par John. |
|
Sed "s/^/ /" fichier.txt > fichier_nouveau.txt |
Ajoute 8 espaces à gauche du texte pour améliorer la qualité d'impression. |
|
Sed -n "/Bien sûr/,/attention à vous/p" monfichier |
Affiche tous les paragraphes commençant par « Bien sûr » et se terminant par « attention à vous ». |
|
Sed -n 12.18p fichier.txt |
Affiche uniquement les lignes 12 à 18 du fichier.txt |
|
Sed 12,18d fichier.txt |
Imprime l'intégralité du fichier.txt sauf les lignes 12 à 18 |
| Insère une ligne vide après chaque ligne dans file.txt | |
|
Sed -f script.sed fichier.txt |
Écrit toutes les commandes dans script.sed et les exécute. |
|
Sed "5!s/ham/cheese/" fichier.txt |
Remplace le jambon par le fromage dans le fichier.txt sauf à la ligne 5 |
|
Sed "$d" fichier.txt |
Supprime la dernière ligne |
|
Sed -n "/\(3\)/p" fichier.txt |
Imprime uniquement les lignes avec trois chiffres consécutifs |
|
Sed "/boom/s/aaa/bb/" fichier.txt |
Si "boom" est trouvé, remplacez aaa par bb |
|
Sed "17,/disk/d" fichier.txt |
Supprime toutes les lignes à partir de la ligne 17 jusqu'à "disque". S'il y a plusieurs lignes avec "disque", supprime jusqu'à la première d'entre elles. |
|
Écho UN DEUX | sed "s/un/unos/je" |
Remplace un par unos quelle que soit la casse, il affichera donc "unos TWO" |
|
Sed "G; G" fichier.txt |
Insère deux lignes vides après chaque ligne dans file.txt |
|
Sed "s/.$//" fichier.txt |
Façon de remplacer dos2unix :). En général, supprime le dernier caractère de chaque ligne. |
|
Sed "s/^[ \t]*//" fichier.txt |
Supprime tous les espaces/tabulations avant chaque ligne du fichier.txt |
|
Sed "s/[ \t]*$//" fichier.txt |
Supprime tous les espaces/tabulations à la fin de chaque ligne dans le fichier.txt |
|
Sed "s/^[ \t]*//;s/[ \t]*$//" fichier.txt |
Supprime tous les espaces/tabulations au début et à la fin de chaque ligne dans le fichier.txt |
|
Sed "s/foo/bar/" fichier.txt |
Remplace foo par bar uniquement dans la première occurrence de la ligne. |
|
Sed "s/foo/bar/4" fichier.txt |
Remplace foo par bar uniquement dans la quatrième occurrence de la ligne. |
|
Sed "s/foo/bar/g" fichier.txt |
Remplace foo par bar pour toutes les occurrences de la chaîne. |
|
Sed "/baz/s/foo/bar/g" fichier.txt |
Remplacez foo par bar uniquement si la chaîne contient baz. |
|
Sed "/./,/^$/!d" fichier.txt |
Compressez toutes les lignes vides consécutives en une seule. Il n'y a pas de ligne vide en haut. |
|
Sed "/^$/N;/\n$/D" fichier.txt |
Condensez toutes les lignes vides consécutives en une seule, mais laissez la ligne supérieure vide. |
|
Sed "/./,$!d" fichier.txt |
Supprimer toutes les premières lignes vides |
|
Sed -e:a -e "/^\n*$/($d;N;);/\n$/ba" fichier.txt |
Supprimer toutes les lignes vides de fin |
|
Sed -e:a -e "/\\$/N; s/\\\n/ /; ta" fichier.txt |
Si une ligne se termine par un dosseret, concaténez-la avec la suivante (utile pour les scripts shell) |
|
Sed -n "/regex/,+5p" fichier.txt |
Imprime 5 lignes après la ligne contenant l'expression régulière |
|
Sed "1~3d" fichier.txt |
Supprimez une ligne sur trois, en commençant par la première. |
|
Sed -n "2~5p" fichier.txt |
Imprimez toutes les cinq lignes, en commençant par la seconde. |
|
Sed "s/ick/John/g" rapport.txt |
Une autre façon d’écrire certains des exemples ci-dessus. Pouvez-vous proposer le vôtre ? |
|
Sed -n "/RE/(p;q;)" fichier.txt |
Imprime la ligne avec la première correspondance RE (expression régulière) |
|
Sed "0,/RE/(//d;)" fichier.txt |
Supprime la chaîne avec la première correspondance |
|
Sed "0,/RE/s//to_that/" fichier.txt |
Ne change que le premier match |
|
Sed "s/^[^,]*,/9999,/" fichier.csv |
Remplace toutes les valeurs de la première colonne d'un fichier CSV par 9999 |
|
S/^ *\(.*[^ ]\) *$/|\1|/; s/"*, */"|/g; : boucle s/| *\([^",|][^,|]*\) *, */|\1|/g; s/| *, */||/g; t boucle s/ *|/|/g ; s/| */|/g; s/^|\(.*\)|$/\1/; |
Script Sed pour convertir un fichier CSV en fichier avec un délimiteur de barre verticale (fonctionne uniquement avec certains types CSV, ceux avec des guillemets et des virgules intégrés). |
|
Fichier Sed ":a;s/\(^\|[^0-9.]\)\(\+\)\(\(3\)\)/\1\2,\3/g;ta" .SMS |
Modifie le format numérique dans file.txt de 1234.56 à 1.234.56 |
|
Sed -r "s/\<(reg|exp)+/\U&/g" |
Convertit n'importe quel mot commençant par reg ou exp en majuscule. |
|
Sed "1,20 s/Johnson/Blanc/g" fichier.txt |
Remplace Johnson par White uniquement dans les lignes 1 à 20. |
|
Sed "1.20 !s/Johnson/White/g" fichier.txt |
L'exemple précédent est inversé (remplace partout sauf les lignes 1 à 20) |
|
Sed "/de/,/jusqu'à/ ( s/\<red\>/magenta/g; s/<blue\>/cyan/g; )" fichier.txt |
Remplace uniquement entre "de" et "jusqu'à". S'il y a plusieurs zones "de" à "jusqu'à", remplace dans chacune d'elles. |
|
Sed "/ENDNOTES:/,$ ( s/Schaff/Herzog/g; s/Kraft/Ebbing/g; )" fichier.txt |
Remplace uniquement le mot « ENDNOTES : » par EOF |
|
Sed "/./(H;$!d;);x;/regex/!d" fichier.txt |
Imprime un paragraphe uniquement s'il contient une expression régulière |
|
Sed -e "/./(H;$!d;)" -e "x;/RE1/!d;/RE2/!d;/RE3/!d" fichier.txt |
Imprime les paragraphes uniquement s'ils contiennent RE1, RE2 et RE3. L'ordre de RE1, RE2 et RE3 n'a pas d'importance. |
|
Sed "s/14"/quatorze pouces/g" fichier.txt |
De cette façon, vous pouvez utiliser des guillemets doubles |
|
Sed "s/\/some\/UNIX\/path/\/a\/new\/path/g" fichier.txt |
Travailler avec les chemins Unix |
|
Sed "s///g" fichier.txt |
Supprime tous les caractères commençant par a et se terminant par g du fichier.txt |
|
Sed "s/\(.*\)foo/\1bar/" fichier.txt |
Remplace uniquement la dernière correspondance de foo dans la chaîne par bar |
|
Sed "1!G;h;$!d" |
Remplacement de la commande tac |
|
Sed "/\n/!G;s/\(.\)\(.*\n\)/&\2\1/;//D;s/.//" |
Remplacement de la commande rev |
|
Fichier Sed 10q.txt |
Remplacement de la commande head |
|
Sed -e:a -e "$q;N;11,$D;ba" fichier.txt |
Remplacement de la commande tail |
|
Sed "$!N; /^\(.*\)\n\1$/!P; D" fichier.txt |
Remplacement de la commande uniq |
|
Sed "$!N; s/^\(.*\)\n\1$/\1/;t; D" fichier.txt |
Commande inverse (équivalent à uniq -d) |
|
Sed "$!N;$!D" fichier.txt |
Équivalent à queue -n 2 |
|
Sed -n "$p" fichier.txt |
... tail -n 1 (ou tail -1) |
|
Sed "/regexp/!d" fichier.txt |
Équivalent à grep |
|
Sed -n "/regexp/(g;1!p;);h" fichier.txt |
Imprime la ligne précédant la première correspondance d'une expression régulière, mais sans inclure la correspondance elle-même |
|
Sed -n "/regexp/(n;p;)" fichier.txt |
Imprime la ligne après la première correspondance d'expression régulière, mais sans inclure la correspondance elle-même |
|
Sed "/pattern/d" fichier.txt |
Supprime les lignes correspondant au motif |
|
Sed "/./!d" fichier.txt |
Supprime toutes les lignes vides d'un fichier |
|
Sed "/^$/N;/\n$/N;//D" fichier.txt |
Condense toutes les lignes vides consécutives en deux lignes vides. Les lignes vides simples ne sont pas modifiées. |
|
Sed -n "/^$/(p;h;);/./(x;/./p;)" fichier.txt |
Supprime la dernière ligne de chaque paragraphe |
| Obtient l'en-tête du message. En d’autres termes, il supprime tout après la première ligne vide. | |
La dernière fois, nous avons parlé des fonctions des scripts bash, en particulier de la manière de les appeler depuis la ligne de commande. Notre sujet d'aujourd'hui est un outil très utile pour traiter les données de chaîne - un utilitaire Linux appelé sed. Il est souvent utilisé pour travailler avec des textes sous forme de fichiers journaux, de configuration et autres fichiers.
Si vous effectuez des manipulations de données dans des scripts bash, vous devez vous familiariser avec les outils sed et gawk. Ici, nous allons nous concentrer sur sed et travailler avec des textes, car il s'agit d'une étape très importante dans notre voyage à travers les vastes étendues de développement de scripts bash.
Nous allons maintenant examiner les bases du travail avec sed, ainsi que plus de trois douzaines d'exemples d'utilisation de cet outil.
Bases du travail avec sed
L'utilitaire sed est appelé éditeur de texte en streaming. Dans les éditeurs de texte interactifs comme nano, vous travaillez avec des textes à l'aide du clavier, en éditant des fichiers, en ajoutant, supprimant ou modifiant des textes. Sed vous permet de modifier des flux de données en fonction des ensembles de règles spécifiés par le développeur. Voici à quoi ressemble cette commande :Fichier d'options $sed
Par défaut, sed applique les règles spécifiées lors de son appel, exprimées sous la forme d'un ensemble de commandes, à STDIN . Cela vous permet de transmettre des données directement à sed.
Par exemple, comme ceci :
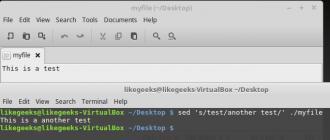
$ echo "Ceci est un test" | sed "s/test/un autre test/"
C'est ce qui se passe lorsque vous exécutez cette commande.
Un exemple simple d'appel de sed
Dans ce cas, sed remplace le mot « test » dans la ligne passée pour le traitement par les mots « un autre test ». Pour formuler une règle de traitement du texte entre guillemets, des barres obliques sont utilisées. Dans notre cas, nous avons utilisé une commande comme s/pattern1/pattern2/ . La lettre « s » est une abréviation du mot « substitut », c'est-à-dire que nous avons une commande de remplacement. Sed, en exécutant cette commande, parcourra le texte transmis et remplacera les fragments qui s'y trouvent (nous parlerons de ceux ci-dessous) correspondant au motif 1 par le motif 2.
Ci-dessus est un exemple primitif d'utilisation de sed pour vous mettre au courant. En fait, sed peut être utilisé dans des scénarios de traitement de texte beaucoup plus complexes, comme l'utilisation de fichiers.
Vous trouverez ci-dessous un fichier contenant un morceau de texte et les résultats de son traitement avec cette commande :
$ sed "s/test/un autre test" ./monfichier

Fichier texte et les résultats de son traitement
Cela utilise la même approche que celle utilisée ci-dessus, mais sed traite désormais le texte stocké dans le fichier. Cependant, si le fichier est suffisamment volumineux, vous remarquerez que sed traite les données par morceaux et affiche ce qui est traité à l'écran, sans attendre que l'intégralité du fichier soit traitée.
Sed ne modifie pas les données du fichier qu'il traite. L'éditeur lit le fichier, traite ce qu'il a lu et envoie le résultat obtenu à STDOUT. Afin de s'assurer que le fichier source n'a pas changé, il suffit de l'ouvrir après l'avoir transféré vers sed. Si nécessaire, la sortie sed peut être redirigée vers un fichier, écrasant éventuellement l'ancien fichier. Si vous connaissez l'un des précédents de cette série, qui traite de la redirection des flux d'entrée et de sortie, vous devriez pouvoir le faire.
Exécuter des jeux de commandes lors de l'appel de sed
Pour effectuer plusieurs actions sur les données, utilisez le commutateur -e lors de l'appel de sed. Par exemple, voici comment organiser le remplacement de deux fragments de texte :$ sed -e "s/This/That/; s/test/another test/" ./monfichier

Utiliser le commutateur -e lors de l'appel de sed
Les deux commandes sont appliquées à chaque ligne de texte du fichier. Ils doivent être séparés par un point-virgule et il ne doit y avoir aucun espace entre la fin de la commande et le point-virgule.
Pour saisir plusieurs modèles de traitement de texte lors de l'appel de sed, vous pouvez, après avoir saisi le premier guillemet simple, appuyer sur Entrée, puis saisir chaque règle sur une nouvelle ligne, sans oublier le guillemet fermant :
$ sed -e " > s/This/That/ > s/test/another test/" ./monfichier
C'est ce qui se passera après l'exécution de la commande présentée sous ce formulaire.

Une autre façon de travailler avec sed
Lire des commandes à partir d'un fichier
Si vous devez utiliser de nombreuses commandes sed pour traiter du texte, il est généralement préférable de les pré-écrire dans un fichier. Pour spécifier un fichier sed contenant des commandes, utilisez le commutateur -f :Voici le contenu du fichier mycommands :
S/This/That/ s/test/un autre test/
Appelons sed, en passant à l'éditeur un fichier avec des commandes et un fichier à traiter :
$ sed -f mescommandes monfichier
Le résultat lors de l'appel d'une telle commande est similaire à celui obtenu dans les exemples précédents.

Utiliser un fichier de commande lors de l'appel de sed
Remplacer les indicateurs de commande
Examinez attentivement l’exemple suivant.$sed "s/test/un autre test/" monfichier
C'est ce qui est contenu dans le fichier et ce qui sera obtenu après que sed l'ait traité.

Fichier source et résultats de son traitement
La commande replace gère normalement un fichier multiligne, mais seules les premières occurrences du texte recherché sur chaque ligne sont remplacées. Afin de remplacer toutes les occurrences d'un modèle, vous devez utiliser l'indicateur approprié.
Le schéma d'écriture d'une commande de remplacement lors de l'utilisation d'indicateurs ressemble à ceci :
S/motif/remplacement/drapeaux
L'exécution de cette commande peut être modifiée de plusieurs manières.
- Lors de la transmission du numéro, le numéro de série de l'occurrence du motif dans la chaîne est pris en compte, et c'est cette occurrence qui sera remplacée.
- L'indicateur g indique que toutes les occurrences du modèle dans la chaîne doivent être traitées.
- L'indicateur p indique que le contenu de la chaîne d'origine doit être imprimé.
- L'indicateur de fichier w indique à la commande d'écrire les résultats du traitement de texte dans un fichier.
$ sed "s/test/un autre test/2" monfichier
Appel de la commande de remplacement indiquant la position du fragment à remplacer
Ici, nous avons spécifié le chiffre 2 comme indicateur de remplacement, ce qui a conduit au fait que seule la deuxième occurrence du motif souhaité dans chaque ligne a été remplacée. Essayons maintenant le drapeau de remplacement global - g :
$ sed "s/test/un autre test/g" monfichier
Comme le montrent les résultats de sortie, une telle commande a remplacé toutes les occurrences du modèle dans le texte.
Remplacement global
L'indicateur de commande replace p vous permet d'imprimer les lignes où des correspondances sont trouvées, tandis que l'option -n spécifiée lors de l'appel de sed supprime la sortie normale :
$ sed -n "s/test/un autre test/p" monfichier
De ce fait, lorsque sed est lancé dans cette configuration, seules les lignes (dans notre cas, une ligne) dans lesquelles se trouve le fragment de texte spécifié sont affichées.

Utilisation de l'indicateur de commande de remplacement p
Utilisons le drapeau w, qui permet de sauvegarder les résultats du traitement de texte dans un fichier :
$ sed "s/test/autre test/w sortie" monfichier

Enregistrement des résultats du traitement de texte dans un fichier
On voit clairement que lors de l'exécution de la commande, les données sont sorties vers , tandis que les lignes traitées sont écrites dans le fichier dont le nom est indiqué après w .
Caractères séparateurs
Imaginez remplacer /bin/bash par /bin/csh dans le fichier /etc/passwd. La tâche n'est pas si difficile :$ sed "s/\/bin\/bash/\/bin\/csh/" /etc/passwd
Cependant, cela ne semble pas très bon. Le fait est que puisque les barres obliques sont utilisées comme caractères délimiteurs, les mêmes caractères dans les chaînes passées à sed doivent être échappés. En conséquence, la lisibilité de la commande en souffre.
Heureusement, sed nous permet de définir nos propres caractères délimiteurs à utiliser dans la commande replace. Le séparateur est le premier caractère qui apparaît après s :
$ sed "s!/bin/bash!/bin/csh!" /etc/mot de passe
Dans ce cas, un point d'exclamation est utilisé comme séparateur, ce qui rend le code plus facile à lire et semble beaucoup plus net qu'auparavant.
Sélection de fragments de texte à traiter
Jusqu'à présent, nous avons appelé sed pour traiter l'intégralité du flux de données transmis à l'éditeur. Dans certains cas, en utilisant sed, vous ne devez traiter qu'une partie du texte - une ligne ou un groupe de lignes spécifique. Pour atteindre cet objectif, vous pouvez utiliser deux approches :- Définissez une limite sur le nombre de lignes à traiter.
- Spécifiez le filtre dont les lignes correspondantes doivent être traitées.
$sed "2s/test/un autre test/" monfichier

Traitement d'une seule ligne, le numéro spécifié lors de l'appel de sed
La deuxième option est une plage de chaînes :
$ sed "2.3s/test/un autre test/" monfichier

Traitement d'une plage de lignes
De plus, vous pouvez appeler la commande replace pour que le fichier soit traité d'une certaine ligne jusqu'à la fin :
$ sed "2,$s/test/un autre test/" monfichier

Traitement du fichier de la deuxième ligne à la fin
Afin d'utiliser la commande replace pour traiter uniquement les lignes qui correspondent à un filtre donné, la commande doit être appelée comme ceci :
$sed "/likegeeks/s/bash/csh/" /etc/passwd
Par analogie avec ce qui a été discuté ci-dessus, le modèle est passé avant le nom de la commande s .
Traitement des lignes qui correspondent au filtre
Ici, nous avons utilisé un filtre très simple. Afin d'exploiter pleinement les capacités de cette approche, vous pouvez utiliser des expressions régulières. Nous en parlerons dans l'un des documents suivants de cette série.
Supprimer des lignes
L'utilitaire sed n'est pas seulement utile pour remplacer une séquence de caractères dans des chaînes par une autre. Avec son aide, notamment en utilisant la commande d, vous pouvez supprimer des lignes d'un flux de texte.L'appel de commande ressemble à ceci :
$sed "3d" monfichier
Nous souhaitons que la troisième ligne soit supprimée du texte. Veuillez noter qu'il ne s'agit pas d'un fichier. Le fichier restera inchangé, la suppression n'affectera que la sortie générée par sed.

Suppression de la troisième ligne
Si vous ne spécifiez pas le numéro de ligne à supprimer lors de l'appel de la commande d, toutes les lignes du flux seront supprimées.
Voici comment appliquer la commande d à une plage de chaînes :
$sed "2,3d" monfichier

Supprimer une plage de lignes
Voici comment supprimer des lignes à partir de celle donnée jusqu'à la fin du fichier :
$sed "3,$d" monfichier

Supprimer des lignes jusqu'à la fin du fichier
Les lignes peuvent également être supprimées en utilisant le modèle suivant :
$ sed "/test/d" monfichier

Supprimer des lignes à l'aide d'un modèle
Lorsque vous appelez d, vous pouvez spécifier une paire de modèles - les lignes dans lesquelles le modèle apparaît et les lignes qui les séparent seront supprimées :
$ sed "/second/,/quatrième/d" monfichier

Suppression d'une plage de lignes à l'aide de caractères génériques
Insérer du texte dans un flux
Avec sed, vous pouvez insérer des données dans un flux de texte à l'aide des commandes i et a :- La commande i ajoute une nouvelle ligne avant celle donnée.
- La commande a ajoute une nouvelle ligne après celle donnée.
$ echo "Un autre test" | sed "i\Premier test"

Équipe I
Examinons maintenant la commande a :
$ echo "Un autre test" | sed "un\Premier test"

Commandez un
Comme vous pouvez le constater, ces commandes ajoutent du texte avant ou après les données du flux. Et si vous deviez ajouter une ligne quelque part au milieu ?
Ici, nous serons aidés en indiquant le numéro de la ligne de référence dans le flux, ou modèle. Veuillez noter que l'adressage des chaînes sous forme de plage ne fonctionnera pas ici. Appelez la commande i en indiquant le numéro de ligne avant laquelle vous devez insérer une nouvelle ligne :
$ sed "2i\Ceci est la ligne insérée." mon fichier

Commande i avec numéro de ligne de référence
Faisons de même avec la commande a :
$ sed "2a\Ceci est la ligne ajoutée." mon fichier

Commande a avec numéro de ligne de référence
Notez la différence dans le fonctionnement des commandes i et a. Le premier insère une nouvelle ligne avant celle spécifiée, le second après.
Remplacement des chaînes
La commande c vous permet de modifier le contenu d'une ligne entière de texte dans un flux de données. Lors de son appel, vous devez spécifier le numéro de ligne, au lieu duquel de nouvelles données doivent être ajoutées au flux :$ sed "3c\Ceci est une ligne modifiée." mon fichier

Remplacer une chaîne entière
Si vous utilisez un modèle sous forme de texte brut ou d'expression régulière lors de l'appel d'une commande, toutes les chaînes correspondant au modèle seront remplacées :
$ sed "/Ceci est/c Ceci est une ligne de texte modifiée." mon fichier

Remplacement de chaînes à l'aide d'un modèle
Remplacement de caractères
La commande y fonctionne avec des caractères individuels, en les remplaçant en fonction des données qui lui sont transmises lors de son appel :$sed "y/123/567/" monfichier

Remplacement de caractères
Lorsque vous utilisez cette commande, vous devez tenir compte du fait qu'elle s'applique à l'ensemble du flux de texte ; elle ne peut pas être limitée à des occurrences spécifiques de caractères.
Afficher les numéros de ligne
Si vous appelez sed à l'aide de la commande =, l'utilitaire imprimera les numéros de ligne dans le flux de données :$sed "=" monfichier

Afficher les numéros de ligne
L'éditeur de flux affichait les numéros de ligne avant leur contenu.
Si vous transmettez un modèle à cette commande et utilisez le commutateur sed -n, seuls les numéros de ligne correspondant au modèle seront imprimés :
$ sed -n "/test/=" monfichier

Impression des numéros de ligne correspondant à un motif
Lecture des données d'insertion à partir d'un fichier
Ci-dessus, nous avons examiné les techniques d'insertion de données dans un flux, en indiquant ce qui doit être inséré directement lors de l'appel de sed. Vous pouvez également utiliser un fichier comme source de données. Pour ce faire, utilisez la commande r, qui vous permet d'insérer les données d'un fichier spécifié dans un flux. Lors de son appel, vous pouvez spécifier le numéro de ligne après lequel vous souhaitez insérer le contenu du fichier, ou un modèle.Regardons un exemple :
$sed "3r nouveau fichier" monfichier

Insérer le contenu d'un fichier dans un flux
Ici, le contenu du fichier newfile a été inséré après la troisième ligne du fichier myfile.
Voici ce qui se passe si vous utilisez le modèle lors de l'appel de la commande r :
$ sed "/test/r nouveaufichier" monfichier

Utiliser un caractère générique lors de l'appel de la commande r
Le contenu du fichier sera inséré après chaque ligne correspondant au modèle.
Exemple
Imaginons une telle tâche. Il existe un fichier dans lequel se trouve une certaine séquence de caractères, qui en soi n'a aucun sens, qui doit être remplacée par des données extraites d'un autre fichier. À savoir, qu'il s'agisse d'un nouveau fichier dans lequel la séquence de caractères DATA joue le rôle d'espace réservé. Les données qui doivent être remplacées par DATA sont stockées dans le fichier de données.Vous pouvez résoudre ce problème en utilisant les commandes r et d de l'éditeur de flux sed :
$ Sed "/DATA>/ (r nouveaufichier d)" monfichier

Remplacer l'espace réservé par des données réelles
Comme vous pouvez le voir, au lieu de l'espace réservé DATA, sed a ajouté deux lignes du fichier de données au flux de sortie.
Résultats
Aujourd'hui, nous avons examiné les bases du travail avec l'éditeur de flux sed. En fait, sed est un sujet très vaste. L'apprendre peut être comparé à l'apprentissage d'un nouveau langage de programmation, mais une fois que vous avez compris les bases, vous pouvez maîtriser sed à n'importe quel niveau dont vous avez besoin. En conséquence, votre capacité à traiter des textes avec celui-ci ne sera limitée que par votre imagination.C'est tout pour aujourd'hui. La prochaine fois, nous parlerons du langage de traitement de données awk.
Chers lecteurs! Utilisez-vous sed dans votre travail quotidien ? Si oui, partagez votre expérience.
Introduction
La commande sed est un Stream EDitor pour l'édition automatique de texte. "Éditeur de flux" - dans le sens où il peut éditer le flux de données entrant en continu, par exemple dans le cadre d'un canal de programme (pipe). Automatiquement - cela signifie que dès que vous définissez les règles d'édition, le reste se déroule sans votre fastidieuse participation. En d'autres termes, l'éditeur sed n'est pas interactif.
Le programme sed est plus complexe que les commandes dont nous avons déjà parlé dans les articles précédents de la série HuMan. Il comprend un arsenal de ses propres commandes, donc, afin d'éviter toute tautologie et confusion, dans cet article la commande sed sera désormais appelée « programme » ou « éditeur », et les commandes de l'éditeur sed seront simplement appelées commandes.
Le programme sed peut effectuer des tâches complexes et il faut du temps pour apprendre à formuler ces tâches.
Mais outre des actions complexes, la commande sed possède des capacités simples mais très utiles, qui ne sont pas plus difficiles à maîtriser que les autres commandes Unix. Ne vous laissez pas submerger par la complexité de maîtriser l'ensemble du programme.
Nous allons commencer du simple au complexe, afin que vous puissiez toujours savoir où vous arrêter.
Commande s - substitution (remplacement)
Le programme sed possède de nombreuses commandes qui lui sont propres. La plupart des utilisateurs ne connaissent que la commande s, et cela suffit pour travailler avec l'éditeur sed. La commande s remplace PATTERN par REPLACE :
sed s/ÉCHANTILLON/REMPLACEMENT/
$ jour d'écho | sed s/jour/nuit/ (Entrer) nuit
Cela ne pourrait pas être plus simple. Et voici un exemple avec l'entrée du fichier zar.txt :
Le matin, il faisait des exercices. La foudre est une charge électrique. $ sed s/charge/discharge/ zar.txt Le matin, il effectuait une décharge. La foudre est une décharge électrique.
Je n'ai pas mis s/SAMPLE/REPLACE/ entre guillemets car cet exemple n'a pas besoin de guillemets, mais s'il avait des métacaractères, alors des guillemets seraient nécessaires. Afin de ne pas vous casser la tête à chaque fois, et de ne pas vous tromper accidentellement, mettez toujours des guillemets, de préférence les plus « forts », c'est une bonne habitude. Vous ne pouvez pas gâcher la bouillie avec de l'huile. Moi non plus, je ne lésinerai pas sur les guillemets dans tous les exemples suivants.
Comme nous pouvons le voir, la commande de remplacement s comporte quatre composants :
S la commande elle-même /.../.../ séparateur PATTERN modèle pour la recherche et le remplacement ultérieur REPLACE expression qui remplacera le PATTERN s'il en est trouvé.
La barre oblique (/) est utilisée comme séparateur par tradition, puisque l'ancêtre de sed, l'éditeur ed, les utilise (tout comme l'éditeur vi). Dans certains cas, un tel séparateur est très gênant, par exemple lorsque vous devez modifier les chemins vers des répertoires contenant également une barre oblique (/usr/local/bin). Dans ce cas, vous devez séparer les barres obliques par des barres obliques inverses :
Sed "s/\/usr\/local\/bin/\/common\/bin/"
C'est ce qu'on appelle une « palissade » et cela semble très laid et, surtout, incompréhensible.
Ce qui est unique avec sed, c'est qu'il vous permet d'utiliser n'importe quel délimiteur, tel que le trait de soulignement :
$ jour d'écho | sed s_day_night_nuit
ou deux points :
$ jour d'écho | sed s:jour:nuit:nuit
Si, en recherchant un délimiteur que vous aimez, vous obtenez le message "commande incomplète", alors ce caractère n'est pas un bon séparateur, ou vous avez simplement oublié de mettre un ou deux délimiteurs.
Dans cet article, je dois utiliser le séparateur traditionnel (/) pour éviter de dérouter le lecteur, mais si nécessaire, j'utiliserai le tilde (~) comme séparateur.
Expressions régulières (RE)
(Expressions régulières, expression rationnelle, RE)
Le sujet des expressions régulières est si vaste que des livres entiers y sont consacrés (voir liens en fin d'article). Cependant, parler sérieusement de l'éditeur sed sans utiliser d'expressions régulières est aussi contre-productif que de parler de trigonométrie en utilisant des bâtons d'ajout. Par conséquent, il est nécessaire de parler au moins des expressions régulières qui sont souvent utilisées avec le programme sed.
Avec Ou toute autre lettre. La plupart des lettres, chiffres et autres caractères non spéciaux sont considérés comme des expressions régulières qui se représentent eux-mêmes.
* Un astérisque suivant un symbole ou une expression régulière signifie tout nombre (y compris zéro) de répétitions de ce symbole ou de cette expression régulière.
\+ Indique une ou plusieurs répétitions d'un caractère ou d'une expression régulière.
\? Signifie aucun ou une répétition.
\(je\) Cela signifie exactement que je répète.
\(je,j\) Le nombre de répétitions est compris entre i et j inclus.
\(je,\) Le nombre de répétitions est supérieur ou égal à i.
\(,j\) Le nombre de répétitions est inférieur ou égal à j.
\(CONCERNANT\) N'oubliez pas l'expression régulière ou une partie de celle-ci pour une utilisation future dans son ensemble. Par exemple, \(a-z\)* recherchera n'importe quelle combinaison de n'importe quel nombre (y compris zéro) de lettres minuscules.
. Correspond à n'importe quel caractère, y compris la nouvelle ligne.
^ Indique une expression nulle au début d'une ligne. Autrement dit, tout ce qui est précédé de ce signe doit apparaître en début de ligne. Par exemple, ^#include recherchera les lignes commençant par #include.
$ La même chose que la précédente ne s’applique qu’à la fin de la ligne.
[LISTER] Désigne n'importe quel caractère de la LISTE. Par exemple, il recherchera n’importe quelle lettre de voyelle anglaise.
[^LISTE] Désigne n'importe quel caractère sauf ceux de la liste. Par exemple, [^aeiou] recherchera n'importe quelle consonne. Remarque : LISTE peut être un intervalle, par exemple [a-z], ce qui signifie n'importe quelle lettre minuscule. Si vous devez inclure ] (crochet) dans la LISTE, indiquez-le en premier dans la liste ; si vous devez inclure - (trait d'union) dans la LISTE, indiquez-le en premier ou en dernier dans la liste.
RE1\|RE2 Signifie PB1 ou PB2.
RE1RE2 Désigne l'union des expressions régulières РВ1 et РВ2.
\n Indique un caractère de nouvelle ligne.
\$; \*; \.; \[; \\; \^ Signifie en conséquence : $; *; .; [; \; ^
Attention: Les autres conventions de barre oblique inverse (\) du langage C ne sont pas prises en charge par sed.
\1 \2 \3 \4 \5 \6 \7 \8 \9 Indique la partie correspondante de l'expression régulière, stockée à l'aide des signes \(et \).
Quelques exemples :
a B c d e F Signifie abcdef
un B Représente zéro ou n’importe quel nombre de a et un b. Par exemple, aaaaaab ; un B; ou b.
un B Signifie b ou ab
a\+b\+ Représente un ou plusieurs a et un ou plusieurs b. Par exemple : ab ; aaaab; abbbbb; ou aaaaaabbbbbbb.
.* Désigne tous les caractères d'une ligne, sur toutes les lignes, y compris les lignes vides.
.\+ Correspond à tous les caractères d'une ligne, mais uniquement aux lignes contenant au moins un caractère. Les chaînes vides ne correspondent pas à cette expression régulière.
^principal.*(.*) Il recherchera les lignes commençant par le mot main et contenant également des crochets ouvrants et fermants, et il peut y avoir n'importe quel nombre de caractères avant et après le crochet ouvrant (ou il peut n'y en avoir aucun).
^# Recherchera les lignes commençant par un signe # (par exemple les commentaires).
\\$ Recherchera les lignes se terminant par une barre oblique inverse (\).
Des lettres ou des chiffres
[^ ]\+ (Le crochet, en plus du symbole ^, contient également un espace et une tabulation) -- Désigne un ou plusieurs caractères, à l'exception d'un espace et d'une tabulation. Habituellement, cela signifie un mot.
^.*A.*$ Indique un A majuscule exactement au milieu d’une ligne.
R.\(9\)$ Indique une lettre majuscule A, exactement la dixième lettre à partir de la fin de la ligne.
^.\(,15\)A Indique une lettre majuscule A, exactement la seizième depuis le début de la ligne.
Maintenant que nous avons vu quelques expressions régulières, revenons à la commande s de sed.
En utilisant le symbole & lorsque le MOTIF est inconnu « Comment est-il inconnu ? », vous demandez : « Vous ne savez pas ce que vous voulez remplacer ? Je répondrai : je souhaite mettre entre parenthèses tous les chiffres trouvés dans le texte. Comment faire? Réponse : utilisez le symbole &.
Le symbole & (esperluette), lorsqu'il est placé dans le cadre d'un REMPLACEMENT, désigne tout MOTIF trouvé dans le texte. Par exemple:
$ écho 1234 | sed "s/*/(&)/" (1234)
Un astérisque (astérisque) après l'intervalle est nécessaire pour que tous les nombres trouvés dans l'échantillon soient remplacés. Sans cela, cela aurait été :
$ écho 1234 | sed "s//(&)/" (1)234
Autrement dit, le premier chiffre trouvé a été pris comme échantillon.
Voici un exemple avec une charge tout à fait significative : créons un fichier formula.txt :
A+432-10=n
et appliquez-y la commande :
$ sed "s/*-*/(&)/" formule.txt a+(432-10)=n
La formule mathématique a acquis un sens sans ambiguïté.
Un autre symbole d'esperluette peut être utilisé pour doubler le MOTIF :
$ écho 123 | sed "s/*/& &/" 123 123
Il y a une subtilité ici. Si nous compliquons un peu l’exemple :
$ écho "123 abc" | sed "s/*/& &/" 123 123 abc
comme on peut s'y attendre, seuls les chiffres sont doublés puisqu'il n'y a pas de lettres dans le MOTIF. Mais si on échange des parties du texte :
$ écho "abc 123" | sed "s/*/& &/" abc 123
alors aucun doublement des nombres ne fonctionnera. Il s'agit d'une fonctionnalité de l'expression régulière * : elle correspond uniquement au premier caractère de la chaîne. Si nous voulons doubler les chiffres, peu importe où ils se trouvent, nous devons modifier l'expression régulière dans REPLACE :
$ echo "abc defg 123" | sed "s/*/& &/" abc defg 123 123
alors les nombres doubleront, quel que soit le nombre de « mots » précédents.
Utilisation des parenthèses d'échappement \(, \) et \1 pour traiter une partie d'un PATTERN Les parenthèses d'échappement \(et \) sont utilisées pour stocker une partie d'une expression régulière.
Le symbole \1 signifie la première partie mémorisée, \2 signifie la seconde, et ainsi de suite, jusqu'à neuf parties mémorisées (le programme n'en prend pas en charge plus). Regardons un exemple :
$ écho abcd123 | sed "s/\(*\).*/\1/" abcd
Ici, \(*\) signifie que le programme doit mémoriser tous les caractères alphabétiques, quelle que soit leur quantité ; .* signifie n'importe quel nombre de caractères après la première partie mémorisée ; et \1 signifie que nous voulons seulement voir la première partie mémorisée. C'est vrai : dans la sortie du programme, nous ne voyons que des lettres et aucun chiffre.
Afin d'échanger des mots, vous devez mémoriser deux sous-MODÈLES, puis les échanger :
$ echo pingouin stupide |sed "s/\([a-z]*\) \([a-z]*\)/\2 \1/" pingouin stupide
Ici, \2 signifie le deuxième sous-MODÈLE et \1 signifie le premier. Notez l'espacement entre la première expression \([a-z]*\) et la deuxième expression \([a-z]*\). Il faut trouver deux mots.
Le signe \1 ne doit pas nécessairement être présent uniquement dans REPLACEMENT ; il peut également être présent dans SAMPLE, par exemple, lorsque l'on souhaite supprimer les mots en double :
$ echo pingouin pingouin | sed "s/\([a-z]*\) \1/\1/" pingouin
Modificateurs de substitution de commande s
Les modificateurs de remplacement sont placés après le dernier délimiteur. Ces modificateurs déterminent ce que le programme fera s'il y a plus d'une correspondance avec le PATTERN dans la chaîne, et comment effectuer le remplacement.
Modificateur /g
Remplacement global
Le programme sed, comme la plupart des utilitaires Unix, lit une ligne à la fois lorsque vous travaillez avec des fichiers. Si nous ordonnons le remplacement d'un mot, le programme remplacera uniquement le premier mot qui correspond au MOTIF sur la ligne donnée. Si nous voulons changer chaque mot qui correspond au modèle, nous devons alors entrer le modificateur /g.
Sans le modificateur /g :
$ echo ce chat était le chat le plus ordinaire | sed "s/cat/kitten/" ce chaton était le chat le plus ordinaire
L'éditeur a remplacé uniquement le premier mot correspondant.
Et maintenant avec le modificateur de remplacement global :
$ echo ce chat était le chat le plus ordinaire | sed "s/cat/kitten/g" ce chaton était le chaton le plus ordinaire
Toutes les correspondances de cette chaîne ont été remplacées.
Et si vous avez besoin de changer tous les mots, disons, mettez-les entre parenthèses ? Ensuite, les expressions régulières viendront à nouveau à la rescousse. Pour sélectionner tous les caractères alphabétiques, majuscules et minuscules, vous pouvez utiliser la construction [A-Ya-Ya], mais elle n'inclura pas de mots comme « quelque chose » ou « s » ezd. » La construction [^] est bien plus pratique ]*, qui correspond à tous les caractères sauf l'espace, donc :
$ echo le stupide pingouin se cache timidement | sed "s/[^ ]*/(&)/g" (stupide) (pingouin) (timide) (se cache)
Comment choisir la bonne correspondance parmi plusieurs
Si vous n'appliquez pas de modificateurs, le programme sed remplacera uniquement le premier mot correspondant au PATTERN. Si vous appliquez le modificateur /g, le programme remplacera chaque mot correspondant. Comment sélectionner l’une des correspondances s’il y en a plusieurs en jeu ? - À l'aide des symboles conventionnels \(et \) que nous connaissons déjà, retenez les sous-ÉCHANTILLONS et sélectionnez celui dont vous avez besoin à l'aide des symboles \1 - \9.
$ echo stupide pingouin | sed "s/\([a-z]*\) \([a-z]*\)/\2 /" pingouin
Dans cet exemple, nous avons mémorisé les deux mots et, en mettant le deuxième (pingouin) à la première place, nous avons supprimé le premier (stupide) en mettant un espace à sa place dans la section REMPLACEMENT. Si on remplace l'espace par un mot, il remplacera le premier (stupide) :
$ echo stupide pingouin | sed "s/\([a-z]*\) \([a-z]*\)/\2 smart /" pingouin intelligent
Modificateur numérique
Il s'agit d'un nombre à un/deux/trois chiffres placé après le dernier séparateur et indiquant quelle correspondance doit être remplacée.
$ echo pingouin très stupide | sed "s/[a-z]*/good/2" très bon pingouin
Dans cet exemple, chaque mot correspond à une correspondance et nous avons indiqué à l'éditeur quel mot nous souhaitons remplacer en plaçant un modificateur 2 après la section REPLACE.
Vous pouvez combiner le modificateur numérique avec le modificateur /g. Si vous devez laisser le premier mot inchangé et remplacer le deuxième et les suivants par le mot « (supprimé) », alors la commande ressemblera à ceci :
$ echo pingouin très stupide | sed "s/[a-z]*/(supprimé)/2g" very (supprimé) (supprimé)
Si vous souhaitez vraiment supprimer toutes les correspondances suivantes à l'exception de la première, vous devez alors mettre un espace dans la section REPLACE :
$ echo pingouin très stupide | sed "s/[a-z]*/ /2g" très
Ou ne rien mettre du tout :
$ echo pingouin très stupide | sed "s/[^ ]*//2g" est très
Le modificateur numérique peut être n'importe quel entier compris entre 1 et 512. Par exemple, si vous devez mettre deux points après le 80ème caractère de chaque ligne, la commande vous aidera :
$ sed "s/./&:/80" nom de fichier
Modificateur /p - sortie vers la sortie standard (impression)
Le programme sed affiche déjà le résultat sur la sortie standard (par exemple, l'écran du moniteur) par défaut. Ce modificateur est utilisé uniquement avec l'option sed -n, qui bloque simplement la sortie du résultat à l'écran.
Modificateur /w
Vous permet d'écrire les résultats du traitement de texte dans le fichier spécifié :
$ sed "s/SAMPLE/REPLACE/w nom de fichier
modificateur /e (extension GNU)
Vous permet de spécifier une commande shell (pas un programme sed) comme REMPLACEMENT. Si une correspondance avec le PATTERN est trouvée, elle sera remplacée par le résultat de la commande spécifiée dans la section REPLACE. Exemple:
$ nuit d'écho | sed "s/nuit/echo jour/e" jour
Modificateurs /I et /i (extension GNU)
Rend le processus de remplacement insensible à la casse.
$ echo Nuit | sed "s/nuit/jour/je" jour
Combinaisons de modificateurs
Les modificateurs peuvent être combinés lorsque cela a du sens. Dans ce cas, le modificateur w doit être placé en dernier.
Conventions (extension GNU) Il n'y en a que cinq :
\L convertit les caractères REPLACE en minuscules \l convertit le prochain caractère REPLACE en minuscule \U convertit les caractères REPLACE en majuscules \u convertit le prochain caractère REPLACE en majuscule \E annule une traduction commencée par \L ou \U Pour des raisons évidentes, ces conventions sont utilisées seules. Par exemple:
$ echo stupide pingouin | sed "s/stupide/\u&/" Pingouin stupide
$ echo petit chiot | sed "s/[a-z]*/\u&/2" petit chiot
Nous avons couvert presque tous les aspects de la commande sed. Il est maintenant temps d'examiner les options de ce programme.
options du programme sed
Le programme a étonnamment peu d'options. (Ce qui compense quelque peu l'excès de commandes, modificateurs et autres fonctions). En plus des options bien connues --help (-h) et --version (-V), que nous ne considérerons pas, il n'y en a que trois :
Option -e--expression=ensemble_commande
Une façon d’exécuter plusieurs commandes consiste à utiliser l’option -e. Par exemple:
Sed -e "s/a/A/" -e "s/b/B/" nom de fichier
Tous les exemples précédents de cet article ne nécessitaient pas l’option -e simplement parce qu’ils contenaient une seule commande. Nous aurions pu utiliser l'option -e dans les exemples, cela n'aurait rien changé.
Option -f Si vous devez exécuter un grand nombre de commandes, il est plus pratique de les écrire dans un fichier et d'utiliser l'option -f :
Sed -f nom de fichier sedscript
Sedscript voici le nom du fichier contenant les commandes. Ce fichier est appelé script de programme sed (ci-après simplement un script). Chaque commande de script doit occuper une ligne distincte. Par exemple:
# commentaire - Ce script changera toutes les voyelles minuscules en voyelles majuscules s/a/A/g s/e/E/g s/i/I/g s/o/O/g s/u/U/g
Vous pouvez nommer le script comme vous le souhaitez, il est important de ne pas confondre le fichier script avec le fichier en cours de traitement.
Option -n Le programme sed -n n'imprime rien sur la sortie standard. Pour recevoir un retrait, vous avez besoin d’une instruction spéciale. Nous connaissons déjà le modificateur /p, qui peut être utilisé pour donner une telle indication. Rappelons le fichier zar.txt :
$ sed "s/1-9/&/p" zar.txt Le matin, il faisait des exercices. La foudre est une charge électrique.
Puisqu'aucune correspondance n'a été trouvée avec le PATTERN (il n'y a pas de nombres dans le fichier), la commande s avec le modificateur /p et le signe & en REMPLACEMENT (rappelez-vous que l'esperluette signifie le PATTERN lui-même) fonctionne comme la commande cat.
Si PATTERN est trouvé dans le fichier, alors les lignes contenant PATTERN seront doublées :
$ sed "s/exercise/&/p" zar.txt Le matin, il faisait des exercices. Le matin, il faisait des exercices. La foudre est une charge électrique.
Ajoutons maintenant l'option -n :
$ sed -n "s/exercise/&/p" zar.txt Le matin, il faisait des exercices.
Maintenant, notre programme fonctionne comme la commande grep - il renvoie uniquement les lignes contenant PATTERN.
Sélection des éléments souhaités du texte édité
En utilisant une seule commande, nous avons pu constater les incroyables capacités de l’éditeur sed. Mais tout ce qu’il fait se résume à chercher et à remplacer. De plus, pendant le fonctionnement, sed édite chaque ligne une à une, sans prêter attention aux autres. Il serait pratique de limiter les lignes à modifier, par exemple :
- Sélectionner des lignes par numéros
- Sélectionnez des lignes dans une certaine plage de nombres
- Sélectionnez uniquement les lignes contenant une certaine expression
- Sélectionnez uniquement les lignes entre certaines expressions
- Sélectionnez uniquement les lignes du début du fichier vers une expression
- Sélectionnez uniquement les lignes d'une expression jusqu'à la fin du fichier
Le programme sed fait tout cela et bien plus encore. Toute commande de l'éditeur sed peut être utilisée par adresse, dans une certaine plage d'adresses ou avec les restrictions ci-dessus sur la plage de lignes. L'adresse ou la contrainte doit précéder immédiatement la commande :
Sed "commande d'adresse/restreint"
Sélection de lignes par numéros
C'est le cas le plus simple. Indiquez simplement le numéro de la ligne souhaitée avant la commande :
$ sed "4 s/[a-z]*//i" gumilev.txt Quel étrange bonheur Au petit crépuscule du matin, Dans la fonte des neiges printanières, pour tout ce qui périt et est sage.
$ sed "3 s/В/(В)/" gumilev.txt Quel étrange bonheur Au petit crépuscule du matin, (Dans) la fonte des neiges printanières, Dans tout ce qui périt et est sage.
Sélection de lignes dans une plage de nombres
La plage est indiquée, sans surprise, séparée par des virgules :
$ sed "2.3 s/В/(В)/" gumilev.txt Quel étrange bonheur (Dans) le crépuscule tôt du matin, (Dans) la fonte des neiges printanières, Dans tout ce qui périt et est sage.
Si vous devez spécifier une plage allant jusqu'à la dernière ligne d'un fichier, mais que vous ne savez pas combien de lignes il y a, utilisez le signe $ :
$ sed "2,$ s/in/(in)/i" gumilev.txt Quel étrange bonheur (dans) le crépuscule tôt du matin, (dans) la fonte des neiges printanières, (dans) tout ce qui périt et est sage.
Sélection de lignes contenant une expression
L'expression de recherche est entourée de barres obliques (/) et placée avant la commande :
$ sed "/morning/ s/in/(in)/i" gumilev.txt Quel étrange bonheur (dans) le crépuscule tôt du matin, Dans la fonte des neiges printanières, Dans tout ce qui périt et est sage.
Sélection de lignes dans la plage entre deux expressions
Tout comme dans le cas des numéros de ligne, la plage est spécifiée séparée par des virgules :
$ sed "/morning/,/wise/ s/in/(in)/i" gumilev.txt Quel étrange bonheur (dans) le crépuscule du matin, (dans) la fonte des neiges printanières, (dans) tout qui périt et sagement.
Sélection de lignes depuis le début du fichier jusqu'à une certaine expression
$ sed "1,/snow/ s/in/(in)/i" gumilev.txt Quel étrange bonheur (dans) le crépuscule tôt du matin, (dans) la fonte des neiges printanières, Dans tout ce qui périt et est sage.
Sélection de lignes d'une certaine expression jusqu'à la fin du fichier
$ sed "/snow/,$ s/in/(in)/i" gumilev.txt Quel étrange bonheur Au petit crépuscule du matin, (dans) la fonte des neiges printanières, (dans) tout ce qui périt et est sage.
Autres commandes de l'éditeur sed
commande d (supprimer)
Supprime les lignes suivantes de la sortie standard :
$ sed "2 d" gumilev.txt Quel étrange bonheur Dans la fonte des neiges printanières, Dans tout ce qui périt et est sage.
Et le plus souvent ils l'écrivent plus simplement (sans espace) :
Sed "2d" gumilev.txt
Tout ce qui a été dit dans la section précédente sur l'adressage des chaînes s'applique également à la commande d (ainsi qu'à presque toutes les commandes de l'éditeur sed).
À l'aide de la commande d, il est pratique de supprimer « l'en-tête » inutile de certains messages électroniques :
$ sed "1,/^$/d" nom de fichier
(Supprimez les lignes de la première à la première ligne vide).
Débarrassez-vous des commentaires dans le fichier de configuration :
$ sed "/^#/d" /boot/grub/menu.lst
Et vous ne savez jamais où supprimer des lignes supplémentaires !
commande p (imprimer)
Le mot anglais « print » est traduit par « print », qui en russe est associé à une imprimante, ou du moins à un clavier. En fait, dans le contexte anglais, ce mot signifie souvent simplement une sortie sur un écran de contrôle. Ainsi, la commande p n'imprime rien, mais affiche simplement les lignes spécifiées.
Lorsqu'elle est utilisée seule, la commande p double les lignes dans la sortie (après tout, le programme sed imprime une ligne à l'écran par défaut, mais la commande p imprime la même ligne une seconde fois).
$ echo J'ai un chat | sed "p" j'ai un chat j'ai un chat
Il existe des utilisations pour cette propriété, comme doubler les lignes vides pour améliorer l'apparence du texte :
$ sed "/^$/ p nom de fichier
Mais la commande p révèle ses vraies couleurs en combinaison avec l'option -n, qui, comme vous vous en souvenez, empêche l'impression de lignes à l'écran. En combinant l'option -n avec la commande p, vous pouvez obtenir uniquement les lignes requises dans la sortie.
Par exemple, regardez les lignes un à dix :
$ sed -n "1.10 p" nom de fichier
Ou juste des commentaires :
$ sed -n "/^#/ p" /boot/grub/menu.lst # Fichier de configuration GRUB "/boot/grub/menu.lst". # généré par "grubconfig". Dim 23 mars 2008 21:45:41 # # Démarrer la section globale GRUB # Fin de la section globale GRUB # La configuration de la partition de démarrage Linux commence # La configuration de la partition de démarrage Linux se termine # La configuration de la partition de démarrage Linux commence # La configuration de la partition de démarrage Linux se termine
Cela rappelle beaucoup le programme grep, que nous avons déjà rencontré lorsque nous parlions de l'option -n avec le modificateur /p. Mais contrairement à la commande grep, l'éditeur sed permet non seulement de retrouver ces lignes, mais aussi de les modifier, en remplaçant par exemple partout Linux par Unix :
$ sed -n "/^#/ p" /boot/grub/menu.lst | sed "s/Linux/Unix/" # Fichier de configuration GRUB "/boot/grub/menu.lst". # généré par "grubconfig". Dim 23 mars 2008 21:45:41 # # Démarrer la section globale GRUB # Fin de la section globale GRUB # La configuration de la partition de démarrage Unix commence # La configuration de la partition de démarrage Unix se termine # La configuration de la partition de démarrage Unix commence # La configuration de la partition de démarrage Unix se termine
Équipe!
Parfois, vous devez modifier toutes les lignes, sauf celles qui correspondent au MOTIF ou à la sélection. Le caractère point d'exclamation (!) inverse la sélection. Par exemple, supprimons toutes les lignes sauf la seconde du quatrain de Gumilyov :
$ sed "2 !d" gumilev.txt Au petit crépuscule du matin,
Ou sélectionnez toutes les lignes, à l'exception des commentaires, dans le fichier /boot/grub/menu.lst :
$ sed -n "/^#/ !p" /boot/grub/menu.lst par défaut 1 timeout 20 gfxmenu (hd0,3)/boot/message title SuSe sur (/dev/hda3) racine (hd0,2) noyau /boot/vmlinuz root=/dev/hda3 ro vga=773 acpi=off title Linux sur (/dev/hda4) racine (hd0,3) noyau /boot/vmlinuz root=/dev/hda4 ro vga=0x317
Commande q (quitter)
La commande q termine le programme sed après la ligne spécifiée. C'est pratique si vous devez arrêter l'édition après avoir atteint un certain point dans le texte :
$sed "11 q" nom de fichier
Cette commande se terminera lorsqu'elle atteindra la 11ème ligne.
La commande q est l'une des rares commandes sed qui n'accepte pas les plages de chaînes. La commande ne peut pas arrêter de fonctionner 10 fois de suite si l'on saisit :
Sed "1.10 q" Absurde !
commande w (écrire)
Comme le modificateur w de la commande s, cette commande vous permet d'écrire la sortie du programme dans un fichier :
$ sed -n "3,$ w gum.txt" gumilev.txt
Nous recevrons un fichier gum.txt contenant les deux dernières lignes du quatrain de Gumilyov du fichier gumilev.txt. De plus, si un tel fichier existe déjà, il sera écrasé. Si vous n'entrez pas l'option -n, le programme, en plus de créer le fichier gum.txt, affichera également l'intégralité du contenu du fichier gumilev.txt.
Pour travailler en ligne de commande, il est plus pratique d'utiliser la redirection de sortie régulière (> ou >>), mais dans les scripts sed, la commande w trouvera probablement son utilité.
commande r (lire)
Cette commande lira non seulement le fichier spécifié, mais collera également son contenu à l'emplacement souhaité dans le fichier modifié. Pour sélectionner le « bon endroit », on utilise un adressage qui nous est déjà familier (par numéros de ligne, par expressions, etc.). Exemple:
$ echo Extrait du poème de Gumilyov : | sed "r gumilev.txt"
Extrait du poème de Gumilyov :
Quel étrange bonheur Au petit crépuscule du matin, Dans la fonte des neiges printanières, Dans tout ce qui périt et est sage.
Équipe =
Donnera le numéro de la ligne spécifiée :
$ sed "/snow/=" gumilev.txt Quel étrange bonheur Au petit crépuscule du matin, 3 Dans la fonte des neiges printanières, Dans tout ce qui périt et est sage.
$ sed -n "/snow/=" gumilev.txt 3
La commande n'accepte qu'une seule adresse, n'accepte pas les intervalles.
Commande y
Cette commande remplace les caractères de la section PATTERN par les caractères de la section REPLACE, fonctionnant comme un programme tr.
$ echo Car - un héritage du passé | sed "y/Auto/Paro/" Voiture à vapeur - un héritage du passé
Équipe oui ne fonctionne que si le nombre de caractères du MOTIF est égal au nombre de caractères du REMPLACEMENT.
scripts du programme sed
Afin d'utiliser l'éditeur sed comme éditeur de texte à part entière, vous devez maîtriser l'écriture de scripts sed. Le programme sed possède son propre langage de programmation simple qui vous permet d'écrire des scripts qui peuvent faire des merveilles.
Cet article ne peut pas contenir de descriptions de scripts sed, tout comme son auteur ne se donne pas pour tâche de maîtriser le langage de programmation sed. Dans cet article, je me suis concentré sur l'utilisation de l'éditeur sed sur la ligne de commande, en vue de l'utiliser comme filtre dans les tuyaux. Pour cette raison, j'ai omis de nombreuses commandes sed qui ne sont utilisées que dans les scripts sed.
Il existe de nombreux fans de l'éditeur sed et de nombreux articles sur le thème des scripts, y compris sur RuNet. Ainsi, pour ceux qui sont intéressés par ce merveilleux programme, il ne sera pas difficile d'élargir leurs connaissances.
Le programme sed et les caractères cyrilliques
Comme le montrent les exemples de cet article, le programme sed sur un système correctement russifié parle couramment le langage « grand et puissant ».
Résumé du programme sed
Le programme sed est un éditeur de flux de données multifonctionnel, indispensable pour :
- Modification de grands tableaux de texte
- Modification de fichiers de toute taille lorsque la séquence d'actions d'édition est trop complexe
- Modifier les données au fur et à mesure qu'elles deviennent disponibles, y compris en temps réel, c'est-à-dire dans les cas où il est difficile, voire totalement impossible, d'utiliser des éditeurs de texte interactifs.
Pour maîtriser pleinement le programme sed, il faudra des semaines voire des mois de travail, car cela nécessite :
- Apprendre les expressions régulières
- Apprenez à écrire des scripts sed en maîtrisant le langage de programmation simple utilisé dans ces scripts
D'un autre côté, maîtriser plusieurs des commandes les plus courantes de l'éditeur sed n'est pas plus difficile que n'importe quelle commande Unix ; J'espère que cet article vous aidera.
Épilogue
Jusqu'à présent, dans les articles de la série HuMan, j'ai essayé de divulguer au moins brièvement chaque option, chaque paramètre de la commande étant décrit, afin que l'article puisse remplacer le mana. À l’avenir, je continuerai à adhérer à ce principe.
Cet article constitue une exception, car il ne décrit pas toutes les fonctionnalités du programme. Leur description complète ne nécessiterait pas un article, mais un livre. Cependant, l'article vous permet de vous faire une idée de l'éditeur sed et de démarrer avec cet étonnant programme en utilisant ses commandes les plus courantes.
Beaucoup d'entre vous ont probablement utilisé l'éditeur de texte en streaming sed pour certains de leurs propres besoins, sinon, je serai heureux de vous en parler, j'essaierai d'être plus détaillé. Pourquoi s’appelle-t-on streaming ? La réponse est simple : imaginez un document texte d'entrée qui passe par le programme et le résultat est une autre forme de ce fichier traité par le programme. Une sorte de hachoir à viande - vous mettez la viande de la grille - vous obtenez soit de la viande hachée, soit autre chose.
Donc, par défaut, il semble que cet utilitaire devrait déjà être sur votre système (dans mon cas, dans Debian 7.6, je l'avais déjà), sinon, alors -
Avec texte :
le paramètre « s » au début indique que le texte doit être remplacé, g - à la fin du texte remplacé - qu'il doit être fait globalement (sur l'ensemble du fichier)
Par exemple, nous voulons remplacer le mot Sergey par Andrey dans notre fichier text.txt et télécharger tout cela dans le fichier textout.txt, procédez :
sed "s/Sergey/Andrey/g" texte . txt > sortie texte . SMS |
Résultat:
Si vous souhaitez effectuer des remplacements avec des caractères spéciaux - par exemple, avec le symbole &, vous devez alors précéder le spécial. utilisez une barre oblique inverse « \ » comme symbole ; si vous devez indiquer que sed doit être placé au début de la ligne, utilisez le caractère spécial « ^ ». De plus, vous pouvez écrire 2 modifications ou plus sur une seule ligne, en les séparant par un point-virgule - « ; ». Par exemple, nous torturons le fichier textout.txt déjà modifié. Tout d’abord, je vais afficher à nouveau le contenu actuel du fichier textout.txt :
root @ testhostname : ~ # cat textout.txt Test pour Andrey Test 2 pour Andrey Test 3 pour Andrey |
Entrez maintenant la commande :
sed "s/for/\&/g;s/^Test/Sergey/g" texte . txt > textout2 . SMS |
Ainsi, à la place du mot pour, on met le signe & (un caractère spécial est saisi avec le symbole « \ » avant le caractère spécial), puis un signe de séparation (pour que tous les changements soient écrits sur une seule ligne de sed -> « ;", au lieu du mot au début de la ligne "Test", mettez le mot Sergey, le résultat de ce qui s'est passé :

Tout ce que nous voulions !
Ainsi, sed est un bon assistant lors de la visualisation des journaux. Par exemple, nous devons télécharger toutes les lignes de la date d'aujourd'hui (que ce soit le 10 octobre dans notre cas) du fichier journal /var/log/messages dans le fichier testlog.txt, procédons :
sed - n "/^10 octobre/ p" / var / log / messages > testlog . SMS |
ici nous avons ajouté le paramètre -n, puis - '/^Oct 10/ - signifiant que la ligne doit commencer par la date du 10 octobre, puis le paramètre p - signifiant imprimer (imprimer le contenu dans cette condition), puis le fichier source et le fichier dans lequel nous jetons les résultats en fonction de notre condition de filtre, exécutons-le et voyons ce que contient notre fichier testlog.txt exclusivement le 10 octobre :

Super! Si vous n'avez pas besoin de beaucoup de lignes, mais qu'il est conditionnellement nécessaire de ne prendre que la première à la cinquième ligne, nous séparons notre requête actuelle par le signe « | » supprimer le téléchargement dans le fichier testlog.txt et écrire sed -n 1.5p - ce qui signifie que nous devons afficher (p - imprimer à la fin de l'expression) du premier « 1 » au cinquième (séparé par des virgules) « Ligne de 5 pouces. Au total, nous obtenons quelque chose comme ceci :
sed - n "/^10 octobre/ p" / var / log / messages | sed - n 1 , 5p > testlog - 5strok.txt |
Encore une fois, je voudrais attirer votre attention sur le fait que le fichier où nous téléchargeons les résultats a été déplacé vers la fin (testlog-5strok.txt), on voit le résultat de nos actions :