Windows-1251 est un jeu de caractères et un codage qui constituent le codage standard sur 8 bits pour toutes les versions russes de Microsoft Windows. Ce codage est très populaire dans les pays d’Europe de l’Est. Windows-1251 se distingue avantageusement des autres encodages cyrilliques 8 bits (tels que CP866, KOI8-R et ISO 8859-5) par la présence de presque tous les caractères utilisés dans la typographie russe traditionnelle pour le texte brut (seule la marque d'accent manque) . Les caractères cyrilliques sont classés par ordre alphabétique.
Windows-1251 contient également tous les caractères des langues proches du russe : biélorusse, ukrainien, serbe, macédonien et bulgare.
En pratique, cela s'est avéré suffisant pour que le codage Windows-1251 s'implante sur Internet jusqu'à la diffusion de l'UTF-8.
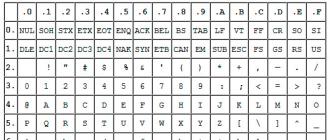
| Déc | Hex | Symbole | Déc | Hex | Symbole | |
|---|---|---|---|---|---|---|
| 000 | 00 | NON | 128 | 80 | Ђ | |
| 001 | 01 | SOH | 129 | 81 | Ѓ | |
| 002 | 02 | STX | 130 | 82 | ‚ | |
| 003 | 03 | ETX | 131 | 83 | ѓ | |
| 004 | 04 | EOT | 132 | 84 | „ | |
| 005 | 05 | ENQ | 133 | 85 | … | |
| 006 | 06 | ACCK | 134 | 86 | † | |
| 007 | 07 | BEL | 135 | 87 | ‡ | |
| 008 | 08 | BS. | 136 | 88 | € | |
| 009 | 09 | LANGUETTE | 137 | 89 | ‰ | |
| 010 | 0A | LF | 138 | 8A | Љ | |
| 011 | 0B | Vermont | 139 | 8B | ‹ | |
| 012 | 0C | FR | 140 | 8C | Њ | |
| 013 | 0D | CR | 141 | 8D | Ќ | |
| 014 | 0E | DONC | 142 | 8E | Ћ | |
| 015 | 0F | SI. | 143 | 8F | Џ | |
| 016 | 10 | DLE | 144 | 90 | ђ | |
| 017 | 11 | DC1 | 145 | 91 | ‘ | |
| 018 | 12 | DC2 | 146 | 92 | ’ | |
| 019 | 13 | DC3 | 147 | 93 | “ | |
| 020 | 14 | DC4 | 148 | 94 | ” | |
| 021 | 15 | N.A.K. | 149 | 95 | ||
| 022 | 16 | SYN | 150 | 96 | – | |
| 023 | 17 | ETB | 151 | 97 | — | |
| 024 | 18 | PEUT | 152 | 98 | ||
| 025 | 19 | E.M. | 153 | 99 | ™ | |
| 026 | 1A | SOUS | 154 | 9A | љ | |
| 027 | 1B | ÉCHAP | 155 | 9B | › | |
| 028 | 1C | FS | 156 | 9C | њ | |
| 029 | 1D | G.S. | 157 | 9D | ќ | |
| 030 | 1E | R.S. | 158 | 9E | ћ | |
| 031 | 1F | NOUS | 159 | 9F | џ | |
| 032 | 20 | PS | 160 | A0 | ||
| 033 | 21 | ! | 161 | A1 | Ў | |
| 034 | 22 | " | 162 | A2 | ў | |
| 035 | 23 | # | 163 | A3 | Ћ | |
| 036 | 24 | $ | 164 | A4 | ¤ | |
| 037 | 25 | % | 165 | A5 | Ґ | |
| 038 | 26 | & | 166 | A6 | ¦ | |
| 039 | 27 | " | 167 | A7 | § | |
| 040 | 28 | ( | 168 | A8 | Yo | |
| 041 | 29 | ) | 169 | A9 | © | |
| 042 | 2A | * | 170 | Les AA | Є | |
| 043 | 2B | + | 171 | UN B | « | |
| 044 | 2C | , | 172 | A.C. | ¬ | |
| 045 | 2D | - | 173 | ANNONCE | | |
| 046 | 2E | . | 174 | A.E. | ® | |
| 047 | 2F | / | 175 | UN F. | Ї | |
| 048 | 30 | 0 | 176 | B0 | ° | |
| 049 | 31 | 1 | 177 | B1 | ± | |
| 050 | 32 | 2 | 178 | B2 | І | |
| 051 | 33 | 3 | 179 | B3 | і | |
| 052 | 34 | 4 | 180 | B4 | ґ | |
| 053 | 35 | 5 | 181 | B5 | µ | |
| 054 | 36 | 6 | 182 | B6 | ¶ | |
| 055 | 37 | 7 | 183 | B7 | · | |
| 056 | 38 | 8 | 184 | B8 | e | |
| 057 | 39 | 9 | 185 | B9 | № | |
| 058 | 3A | : | 186 | B.A. | є | |
| 059 | 3B | ; | 187 | BB | » | |
| 060 | 3C | < | 188 | AVANT JC. | ј | |
| 061 | 3D | = | 189 | BD | Ѕ | |
| 062 | 3E | > | 190 | ÊTRE | ѕ | |
| 063 | 3F | ? | 191 | B.F. | ї | |
| 064 | 40 | @ | 192 | C0 | UN | |
| 065 | 41 | UN | 193 | C1 | B | |
| 066 | 42 | B | 194 | C2 | DANS | |
| 067 | 43 | C | 195 | C3 | g | |
| 068 | 44 | D | 196 | C4 | D | |
| 069 | 45 | E | 197 | C5 | E | |
| 070 | 46 | F | 198 | C6 | ET | |
| 071 | 47 | g | 199 | C7 | Z | |
| 072 | 48 | H | 200 | C8 | ET | |
| 073 | 49 | je | 201 | C9 | Oui | |
| 074 | 4A | J. | 202 | CALIFORNIE. | À | |
| 075 | 4B | K | 203 | C.B. | L | |
| 076 | 4C | L | 204 | CC | M. | |
| 077 | 4D | M. | 205 | CD | N | |
| 078 | 4E | N | 206 | C.E. | À PROPOS | |
| 079 | 4F | Ô | 207 | FC | P. | |
| 080 | 50 | P. | 208 | D0 | R. | |
| 081 | 51 | Q | 209 | D1 | AVEC | |
| 082 | 52 | R. | 210 | D2 | T | |
| 083 | 53 | S | 211 | D3 | U | |
| 084 | 54 | T | 212 | D4 | F | |
| 085 | 55 | U | 213 | J5 | X | |
| 086 | 56 | V | 214 | D6 | C | |
| 087 | 57 | W | 215 | J7 | H | |
| 088 | 58 | X | 216 | D8 | Ch | |
| 089 | 59 | Oui | 217 | D9 | SCH | |
| 090 | 5A | Z | 218 | D.A. | Kommersant | |
| 091 | 5B | [ | 219 | D.B. | Oui | |
| 092 | 5C | \ | 220 | CC | b | |
| 093 | 5D | ] | 221 | DD | E | |
| 094 | 5E | ^ | 222 | DE | YU | |
| 095 | 5F | _ | 223 | DF | je | |
| 096 | 60 | ` | 224 | E0 | UN | |
| 097 | 61 | un | 225 | E1 | b | |
| 098 | 62 | b | 226 | E2 | V | |
| 099 | 63 | c | 227 | E3 | g | |
| 100 | 64 | d | 228 | E4 | d | |
| 101 | 65 | e | 229 | E5 | e | |
| 102 | 66 | F | 230 | E6 | et | |
| 103 | 67 | g | 231 | E7 | h | |
| 104 | 68 | h | 232 | E8 | Et | |
| 105 | 69 | je | 233 | E9 | ème | |
| 106 | 6A | j | 234 | E.A. | À | |
| 107 | 6B | k | 235 | E.B. | je | |
| 108 | 6C | je | 236 | C.E. | m | |
| 109 | 6D | m | 237 | ED | n | |
| 110 | 6E | n | 238 | E.E. | Ô | |
| 111 | 6F | o | 239 | E.F. | P. | |
| 112 | 70 | p | 240 | F0 | R. | |
| 113 | 71 | q | 241 | F1 | Avec | |
| 114 | 72 | r | 242 | F2 | T | |
| 115 | 73 | s | 243 | F3 | à | |
| 116 | 74 | t | 244 | F4 | F | |
| 117 | 75 | toi | 245 | F5 | X | |
| 118 | 76 | v | 246 | F6 | ts | |
| 119 | 77 | w | 247 | F7 | h | |
| 120 | 78 | X | 248 | F8 | w | |
| 121 | 79 | oui | 249 | F9 | sch | |
| 122 | 7A | z | 250 | FA. | ъ | |
| 123 | 7B | { | 251 | s | ||
| 124 | 7C | | | 252 | F.C. | b | |
| 125 | 7D | } | 253 | FD | euh | |
| 126 | 7E | ~ | 254 | F.E. | Yu | |
| 127 | 7F | DEL | 255 | FR | je |
Description des caractères spéciaux (de contrôle)
À l'origine, les caractères de contrôle de table ASCII (plage 00-31, plus 127) étaient conçus pour contrôler les périphériques matériels tels que les téléscripteurs, la saisie de données sur bande perforée, etc.
Les caractères de contrôle (à l'exception de la tabulation horizontale, du saut de ligne et du retour chariot) ne sont pas utilisés dans les documents HTML.
| Code | Description |
|---|---|
| NUL, 00 | Nulle, vide |
| SOH, 01 | Début du titre |
| STX, 02 | Début de TeXt, début du texte |
| ETX, 03 | Fin de TeXt, fin du texte |
| EOT, 04 | Fin de transmission, fin de transmission |
| ENQ, 05 | Renseigner. Veuillez confirmer |
| ACCK, 06 | Reconnaissance. je confirme |
| BEL, 07 | Cloche, appelle |
| BS, 08 | Retour arrière, recule d'un caractère |
| ONGLET, 09 | Onglet, onglet horizontal |
| BF, 0A | Saut de ligne, saut de ligne De nos jours, dans la plupart des langages de programmation, il est noté \n |
| VT, 0B | Onglet vertical, tabulation verticale |
| FR, 0C | Fil de formulaire, fil de page, nouvelle page |
| CR, 0D | Retour chariot De nos jours, dans la plupart des langages de programmation, il est noté \r |
| SO,0E | Shift Out, change la couleur du ruban encreur dans le périphérique d'impression |
| SI, 0F | Shift In, renvoie la couleur du ruban encreur dans le périphérique d'impression |
| DLE, 10 | Data Link Escape, passage du canal à la transmission de données |
| DC1, 11 DC2, 12 DC3, 13 DC4, 14 | Contrôle des appareils, symboles de contrôle des appareils |
| NAK, 15 ans | Accusé de réception négatif, je ne confirme pas |
| SYN, 16 | Synchronisation. Symbole de synchronisation |
| ETB, 17 | Fin du bloc de texte, fin du bloc de texte |
| CAN, 18 | Annuler, annulation d'un message précédemment transmis |
| EM, 19 | Fin du Médium |
| SUB, 1A | Remplacer, remplacer. Placé à la place d'un symbole dont la signification a été perdue ou corrompue lors de la transmission |
| ESC, 1B | Séquence de contrôle d'évacuation |
| FS, 1C | Séparateur de fichiers, séparateur de fichiers |
| GS, 1D | Séparateur de groupe |
| RS, 1E | Séparateur d'enregistrements, séparateur d'enregistrements |
| États-Unis, 1F | Séparateur d'unités |
| DEL, 7F | Supprimer, effacer le dernier caractère. |
1.8 Algorithmes de protection réalisés par BMRZ
1.8.1 Protection contre les surintensités à trois niveaux (MTZ) contre les défauts entre phases avec contrôle du courant en deux ou trois phases(Code ANSI ) 50 ). Possibilité de sélectionner l'une des quatre caractéristiques temps-courant dépendantes. Possibilité d'effectuer du MTZ directionnel(Code ANSI 67 ), MTZ avec démarrage à tension combinée ) (Code ANSI 51 V), avec correction pour tension directe, protection contre les surintensités pour tension fantôme. Entrée automatique de l'accélération MTZ chaque fois que l'interrupteur est allumé. Deux programmes MTZ pour les paramètres et les touches de programme.
1.8.2 Protection directionnelle rapide(Code ANSI 67 ) de tous types de courts-circuits avec blocage via un canal haute fréquence ou une ligne de communication à fibre optique sur les lignes aériennes ne disposant pas de commande par interrupteur phase par phase.
1.8.3 Protection directionnelle ou non directionnelle contre les défauts à la terre monophasés (OSF)(Code ANSI 64 ), agissant sur l'arrêt et/ou la signalisation avec deux temporisations. Enregistrement des composants haute fréquence dans le courant homopolaire. Deux programmes de réglage(Code ANSI 50 g/ N).
1.8.4 Protection contre l'asymétrie et la perte de phase du départ d'alimentation (ZOF) ( Code ANSI 46 ).
1.8.5 Protection contre la tension minimale (MVP) ( Code ANSI 27 ).
1.8.6 Protection logique des bus 6-10 kV (LZSh) ( Code ANSI 68 ).
1.8.7 Sauvegarde longue portée (DR) en cas de défaillance des protections ou des interrupteurs.
1.8.8 Protection contre les sous-tensions (LOP) lorsque l'interrupteur est allumé ( Code ANSI 27 ).
1.8.9 Protection contre les surtensions (OVP) ( Code ANSI 59 ).
1.8.10 Protection de distance (DP)( Code ANSI 21 ).
1.8.11 Protection de courant minimum des moteurs électriques (Min TZ) ( Code ANSI 37 ).
1.8.12 Protection contre le courant homopolaire (ZCP) ( Code ANSI 51 N).
1.8.13 Protection contre le mode phase ouverte (LPFR).
1.8.14 Protection différentielle du transformateur ( Code ANSI87T), y compris:
Protection contre le courant différentiel avec freinage (DZT) ;
Coupure de courant différentiel (DTO).
1.8.15 Protection différentielle du moteur ( Code ANSI87M), y compris:
Coupure de courant différentiel (DTO);
Protection différentielle avec freinage (DZT) ;
Coupure de phase différentielle (DPC).
1.8.16 Protection différentielle des pneus (TIP) ( Code ANSI87ВВ).
1.8.17 Protection contre les pertes de puissance (PLP) ( Code ANSI 27 / 59 ).
1.8.18 Protection contre les surcharges ( Code ANSI 49 ).
1.8.19 Surveillance de tension (circuits de transformateurs de tension ; sur jeu de barres ou en ligne)
(Code ANSI 27 / 59 ).
1.8.20 Contrôle du synchronisme de tension ( Code ANSI 25 ).
1.8.21 Protection rotor bloqué(Code ANSI 48 )et démarrage retardé du moteur (ZBR) ( Code ANSI 14 ).
1.8.22 Modèle thermique du moteur électrique (TM) ( Code ANSI 49 ).
1.8.23 Protection contre les retours de puissance ( Code ANSI 32 P.) et/ou puissance réactive ( Code ANSI 32 Q).
1.8.24 Protection des électroaimants de commande des disjoncteurs.
1.8.25 Contrôle de l'enroulement du ressort.
1.8.26 Exécuter des commandes de protection contre les arcs à partir de dispositifs externes.
1.8.27 Exécution de commandes de protection contre les gaz à partir d'appareils externes ( Code ANSI 63 ).
1.8.28 Exécution des commandes de contrôle de la pression du gaz SF6 à partir d'appareils externes.
1.9 Algorithmes d'automatisation
1.9.1 Détermination de la direction de puissance (POD) ( Code ANSI67/50/51R) pour MT directionnel ou
pour la commutation automatique entre les programmes MTZ et OZZ.
1.9.2 Réenclenchement automatique (AR) double ou simple ( Code ANSI 79 ).
1.9.3 Redondance en cas de panne de disjoncteur (panne de disjoncteur) ( Code ANSI 50 B.F.).
1.9.4 Mise en marche automatique d'une réserve (ATS).
1.9.5 Détermination de la localisation des dommages (ADM).
1.9.6 Exécution des commandes de délestage automatique de fréquence (AFS) et de redémarrage automatique
fréquence (FAA) à partir d’un dispositif de déchargement de fréquence externe.
1.9.7 Délestage automatique de fréquence (AFS).
1.9.8 Limitation du nombre de démarrages du moteur (EKP) ( Code ANSI 66 ).
1.9.10 Contrôle des entraînements électriques des dispositifs de régulation de tension des transformateurs en charge.
1.9.11 Contrôle du court-circuit et du séparateur.
1.10 Algorithmes de contrôle
1.10.1 Allumer et éteindre l'interrupteur à l'aide de commandes externes et de boutons sur le panneau avant.
1.10.2 Entrée/sortie en ligne des fonctions de protection et d'automatisation basées sur des signaux externes.
1.10.3 Modification des paramètres à distance.
Il convient de noter que toutes les désignations de classe de pression ANSI ont une certaine signification, à savoir la valeur de pression, mais uniquement dans des unités autres que celles auxquelles nous sommes habitués. Tous les chiffres après ANSI indiquent la valeur de la pression conditionnelle (nominale) : ANSI 150, ANSI 300, ANSI 600, ANSI 900, ANSI 1500, ANSI 2500 et ANSI 4500. Par exemple, ANSI 150 signifie que la pression nominale est de 150 livres par pouce carré. En anglais, il s’écrit Pound-force per Square Inch ou PSI en abrégé.
En conséquence, vous pouvez ainsi effectuer votre propre conversion de psi en bar (100 kPa) ou MPa. Pour calculer indépendamment celui exact, vous devrez savoir que 1 PSI = 6894,76 Pa. Tous les calculs de pression ANSI en bar et en Pascal peuvent être effectués lorsque le temps et le besoin de données précises sont nécessaires, tandis que la plupart des classes de pression ANSI standard ont déjà des valeurs standard en bar et en MPa. Pour vous faciliter la tâche, nous avons compilé un petit tableau à votre usage :
Tableau des classes de pression ANSI avec conversion en Bar et MPa
Classe de pression ANSI | ||
Reg.ru : domaines et hébergement
Le plus grand registraire et fournisseur d'hébergement en Russie.
Plus de 2 millions de noms de domaine en service.
Promotion, messagerie de domaine, solutions d'affaires.
Plus de 700 000 clients dans le monde ont déjà fait leur choix.
* Passez la souris pour suspendre le défilement.
Retour avant
Encodages : informations utiles et brève rétrospective
J'ai décidé d'écrire cet article comme une brève revue de la question des encodages.
Nous découvrirons ce qu'est le codage en général et aborderons un peu l'histoire de leur apparition en principe.
Nous parlerons de certaines de leurs fonctionnalités et examinerons également les points qui nous permettent de travailler plus consciemment avec les encodages et d'éviter l'apparition de ce qu'on appelle Krakozyabrov, c'est à dire. caractères illisibles.
Alors allons-y...
Qu’est-ce que l’encodage ?
Pour faire simple, codage- il s'agit d'un tableau de mappages de caractères que l'on peut voir à l'écran avec certains codes numériques.
Ceux. Chaque caractère que nous saisissons à partir du clavier ou que nous voyons sur l'écran du moniteur est codé avec une certaine séquence de bits (zéros et uns). 8 bits, comme vous le savez probablement, équivalent à 1 octet d'information, mais nous y reviendrons plus tard.
L'apparence des caractères eux-mêmes est déterminée par les fichiers de polices qui sont installés sur votre ordinateur. Par conséquent, le processus d'affichage du texte à l'écran peut être décrit comme une comparaison constante de séquences de zéros et de uns avec certains caractères spécifiques faisant partie de la police.
L'ancêtre de tous les codages modernes peut être considéré ASCII.
Cette abréviation signifie Code américain normalisé pour l'échange d'information(Jeu de caractères standard américain pour les caractères imprimables et certains codes spéciaux).
Ce codage sur un seul octet, qui ne contient initialement que 128 caractères : lettres de l'alphabet latin, chiffres arabes, etc.

Plus tard, il a été étendu (au départ, il n'utilisait pas les 8 bits), il est donc devenu possible d'utiliser non pas 128, mais 256 (2 à la puissance 8) caractères différents qui peuvent être codés dans un octet d'information.
Cette amélioration a permis d'ajouter à l'ASCII symboles des langues nationales, en plus de l'alphabet latin déjà existant.
Il existe de nombreuses options pour le codage ASCII étendu car il existe également de nombreuses langues dans le monde. Je pense que beaucoup d'entre vous ont entendu parler d'un codage tel que KOI8-R est également un codage ASCII étendu, conçu pour fonctionner avec les caractères de la langue russe.
La prochaine étape dans le développement des codages peut être considérée comme l'émergence de ce qu'on appelle Encodages ANSI.
En gros, c'étaient les mêmes versions étendues d'ASCII Cependant, divers éléments pseudo-graphiques en ont été supprimés et des symboles typographiques ont été ajoutés pour lesquels il n'y avait auparavant pas assez d'« espaces libres ».
Un exemple d'un tel codage ANSI est le célèbre Windows-1251. Outre les symboles typographiques, ce codage comprenait également des lettres des alphabets de langues proches du russe (ukrainien, biélorusse, serbe, macédonien et bulgare).

Le codage ANSI est un nom collectif. En réalité, le codage réel lors de l'utilisation d'ANSI sera déterminé par ce qui est spécifié dans le registre de votre système d'exploitation Windows. Dans le cas du russe, ce sera Windows-1251, cependant, pour les autres langues, ce sera une version ANSI différente.
Comme vous le comprenez, un tas de codage et l'absence d'une norme unifiée n'ont abouti à rien de bon, ce qui a motivé les réunions fréquentes avec ce qu'on appelle krakozèbres- un ensemble de caractères illisibles et dénués de sens.
La raison de leur apparition est simple : c'est tenter d'afficher des caractères codés avec un jeu de caractères à l'aide d'un autre jeu de caractères.
Dans le cadre du développement web, nous pouvons rencontrer des bugs lorsque, par exemple, Le texte russe est enregistré par erreur dans un codage différent de celui utilisé sur le serveur.
Bien sûr, ce n'est pas le seul cas où nous pouvons obtenir du texte illisible - il y a beaucoup d'options ici, surtout si l'on considère qu'il existe également une base de données dans laquelle les informations sont également stockées dans un certain codage, il existe un mappage de connexion à la base de données, etc.
L’émergence de tous ces problèmes a incité à créer quelque chose de nouveau. Il devait s'agir d'un codage capable de coder n'importe quelle langue dans le monde (après tout, avec l'aide de codages sur un octet, peu importe vos efforts, vous ne pouvez pas décrire tous les caractères, disons, de la langue chinoise, où il y a il y en a clairement plus de 256), les éventuels caractères spéciaux et typographies supplémentaires.
En un mot, il fallait créer un codage universel qui résoudrait une fois pour toutes le problème des crackers.
Unicode - Codage de texte universel (UTF-32, UTF-16 et UTF-8)
La norme elle-même a été proposée en 1991 par l'organisation à but non lucratif "Consortium Unicode"(Unicode Consortium, Unicode Inc.), et le premier résultat de son travail fut la création de l'encodage UTF-32.
À propos, l'abréviation elle-même UTF représente Format de transformation Unicode(Format de conversion Unicode).
Dans cet encodage, pour encoder un caractère, il était censé en utiliser autant 32 bits, c'est à dire. 4 octets d'informations. Si l'on compare ce nombre avec des encodages sur un octet, nous arriverons à une conclusion simple : pour encoder 1 caractère dans cet encodage universel il vous faut 4 fois plus de bits, ce qui rend le fichier 4 fois plus lourd.
Il est également évident que le nombre de caractères potentiellement décrits à l'aide de cet encodage dépasse toutes les limites raisonnables et est techniquement limité à 2 à la puissance 32. Il est clair que c'était clairement excessif et inutile en termes de poids des fichiers, donc cet encodage n'était pas répandu.
Il a été remplacé par un nouveau développement - UTF-16.
Comme son nom l'indique, dans cet encodage, un caractère est codé non plus 32 bits, mais seulement 16(c'est-à-dire 2 octets). Évidemment, cela rend n'importe quel caractère deux fois plus « léger » qu'en UTF-32, mais aussi deux fois plus « plus lourd » que n'importe quel caractère codé à l'aide d'un codage sur un seul octet.
Le nombre de caractères disponibles pour l'encodage en UTF-16 est d'au moins 2 puissance 16, c'est-à-dire 65536 caractères. Tout semble aller bien et, de plus, l'espace de code final en UTF-16 a été étendu à plus d'un million de caractères.
Cependant, cet encodage n’a pas pleinement satisfait aux besoins des développeurs. Par exemple, si vous écrivez en utilisant exclusivement des caractères latins, après être passé de la version étendue du codage ASCII à UTF-16, le poids de chaque fichier a doublé.
Par conséquent, une autre tentative a été faite pour créer quelque chose d'universel, et ce quelque chose est devenu le célèbre encodage UTF-8.
UTF-8- Ce codage multi-octets à longueur variable. En regardant le nom, on pourrait penser, par analogie avec UTF-32 et UTF-16, que 8 bits sont utilisés ici pour coder un caractère, mais ce n'est pas le cas. Plus précisément, pas tout à fait comme ça.
Le fait est que UTF-8 offre la meilleure compatibilité avec les anciens systèmes utilisant des caractères 8 bits. Encoder un caractère en UTF-8 est réellement utilisé de 1 à 4 octets(hypothétiquement, jusqu'à 6 octets sont possibles).
En UTF-8, tous les caractères latins sont codés sur 8 bits, tout comme en ASCII.. En d'autres termes, la partie de base du codage ASCII (128 caractères) est passée à UTF-8, ce qui permet de « consacrer » seulement 1 octet à leur représentation, tout en conservant l'universalité du codage, pour lequel tout a été commencé.
Ainsi, si les 128 premiers caractères sont codés sur 1 octet, alors tous les autres caractères sont codés sur 2 octets ou plus. En particulier, chaque caractère cyrillique est codé sur exactement 2 octets.
Ainsi, nous avons obtenu un encodage universel qui nous permet de couvrir tous les caractères possibles à afficher, sans alourdir inutilement les fichiers.
Avec nomenclature ou sans nomenclature ?
Si vous avez travaillé avec des éditeurs de texte (éditeurs de code), par ex. Bloc-notes++, phpDesigner, PHP rapide etc., alors vous avez probablement remarqué qu'en spécifiant l'encodage dans lequel la page sera créée, vous pouvez généralement choisir 3 options :
ANSI
- UTF-8
- UTF-8 sans nomenclature



Je dirai tout de suite que vous devriez toujours choisir la dernière option - UTF-8 sans nomenclature.
Alors, qu’est-ce que la nomenclature et pourquoi n’en avons-nous pas besoin ?
Nomenclature représente Marque d’ordre des octets. Il s'agit d'un caractère Unicode spécial utilisé pour indiquer l'ordre des octets d'un fichier texte. Selon le cahier des charges, son utilisation n'est pas obligatoire, mais si Nomenclature est utilisé, il doit être défini au début du fichier texte.
Nous n'entrerons pas dans les détails des travaux Nomenclature. Pour nous, la principale conclusion est la suivante : l'utilisation de ce caractère de service avec UTF-8 empêche les programmes de lire normalement l'encodage, entraînant des erreurs dans les scripts.
ANSI correspond aux systèmes Windows 95 et Windows, avant de commencer à installer les caractères par défaut.
ANSI est également connu sous le nom de Windows-1252.
important
ANSI et ISO-8859-1 sont très similaires, la seule différence étant 32 caractères.
En ANSI, et 128 à 159 caractères pour certains symboles utiles, symboles comme l'euro.
Dans ISO-8859-1, ces caractères apparaissent en HTML et ne fonctionnent pas dans les caractères de contrôle.
De nombreux développeurs Web déclarent ISO-8859-1 et utilisent ces 32 valeurs comme s'ils utilisaient Windows-1252.
Pour cette raison, une idée fausse courante est que lorsque ISO-8859-1 est déclaré, le navigateur passe à Windows-1252. Cela s'applique aux types de documents suivants : HTML4, HTML5 et XHTML.
ANSI et ASCII
La première partie ANSI (numéro d'entité 0-127) est le jeu de caractères ASCII d'origine. Il contient des chiffres, des majuscules et des caractères spéciaux.
Pour comprendre l’ASCII, veuillez consulter le lien complet du manuel ASCII.
Jeu de caractères ANSI
| personnage | nombre | nom de la propriété | description |
|---|---|---|---|
| 32 | (Espace) | ||
| ! | 33 | Point d'exclamation (point d'exclamation) | |
| " | 34 | & | Citations (citations) |
| # | 35 | Numéro de signe (numéro de signe) | |
| $ | 36 | Signe dollar (signe dollar) | |
| % | 37 | Signe de pourcentage (signe de pourcentage) | |
| & | 38 | & | Esperluette (esperluette) |
| " | 39 | Apostrophe (apostrophe) | |
| ( | 40 | Parenthèse gauche (parenthèse gauche) | |
| ) | 41 | Parenthèse droite (parenthèse droite) | |
| * | 42 | Pignon (astérisque) | |
| + | 43 | Signe plus (signe plus) | |
| , | 44 | Virgules (virgule) | |
| - | 45 | Trait d'union (trait d'union moins) | |
| , | 46 | Période (point final) | |
| / | 47 | Dissection (solidus) | |
| 0 | 48 | Numérique 0 (chiffre zéro) | |
| 1 | 49 | Numérique 1 (chiffre un) | |
| 2 | 50 | Numérique 2 (chiffre deux) | |
| 3 | 51 | Numérique 3 (trois chiffres) | |
| 4 | 52 | Numérique 4 (quatre chiffres) | |
| 5 | 53 | Numérique 5 (chiffre cinq) | |
| 6 | 54 | Numérique 6 (six chiffres) | |
| 7 | 55 | Numérique 7 (sept chiffres) | |
| 8 | 56 | Numérique 8 (chiffre huit) | |
| 9 | 57 | Numérique 9 (numéro neuf) | |
| : | 58 | Côlon (côlon) | |
| ; | 59 | Point-virgule (point-virgule) | |
| < | 60 | &Lt ; | Moins que le signe (moins que le signe) |
| = | 61 | Signe égal (signe égal) | |
| > | 62 | > | Supérieur au signe (supérieur au signe) |
| ? | 63 | Point d'interrogation (point d'interrogation) | |
| @ | 64 | @Symbol (publicité en) | |
| 65 | Lettre latine A majuscule | ||
| DANS | 66 | Lettre majuscule latine B | |
| AVEC | 67 | Lettre latine C | |
| D | 68 | Lettre latine D | |
| E | 69 | Lettres latines E | |
| F | 70 | Lettre latine F | |
| g | 71 | Lettre latine G | |
| H | 72 | Lettre latine H | |
| je | 73 | Lettre majuscule latine I | |
| J. | 74 | Lettre latine J | |
| À | 75 | Lettre latine K | |
| L | 76 | Lettre latine L | |
| M. | 77 | Lettre latine M | |
| N | 78 | Lettre latine N | |
| À PROPOS | 79 | Lettre majuscule latine O | |
| P. | 80 | Lettre latine P | |
| Q | 81 | Lettre majuscule latine Q | |
| R. | 82 | Lettre latine R majuscule | |
| S | 83 | Lettre latine S | |
| T | 84 | Lettre latine T | |
| U | 85 | Lettre latine U | |
| V | 86 | Lettre latine V majuscule | |
| W | 87 | Lettre latine W | |
| X | 88 | Lettre latine X | |
| Oui | 89 | Lettre latine Y | |
| Z | 90 | Lettre latine Z majuscule | |
| [ | 91 | Support gauche (crochet gauche) | |
| \ | 92 | Barre oblique inverse (solidus inversé) | |
| ] | 93 | Support droit (support droit) | |
| ^ | 94 | Caret (accent d'enveloppe) | |
| _ | 95 | Souligner (ligne du bas) | |
| ` | 96 | Accents (apostrophe) | |
| 97 | Lettre latine a | ||
| b | 98 | Lettre minuscule latine b | |
| Avec | 99 | Lettre minuscule latine s | |
| d | 100 | Latin petit D | |
| e | 101 | Lettre latine e | |
| e | 102 | Lettre minuscule latine e | |
| g | 103 | Lettre minuscule latine g | |
| heure | 104 | Lettre minuscule latine h | |
| je | 105 | Lettre de l'alphabet latin en minuscule i | |
| J. | 106 | Petit J latin | |
| À | 107 | Lettre minuscule latine k | |
| L | 108 | Lettre minuscule latine l | |
| m | 109 | Lettre minuscule latine m | |
| N | 110 | Petit p latin | |
| Ô | 111 | Lettre latine O | |
| R. | 112 | Latin petit R | |
| Q | 113 | Lettre minuscule latine Q | |
| R. | 114 | Lettre minuscule latine g | |
| s | 115 | Lettre minuscule latine s | |
| T | 116 | Petit T latin | |
| U | 117 | Lettre latine U | |
| v | 118 | Lettre minuscule latine v | |
| poids | 119 | Lettre minuscule latine ch | |
| X | 120 | Lettre minuscule latine x | |
| Oui | 121 | Lettre latine Y | |
| Z | 122 | Lettre minuscule latine g | |
| { | 123 | Accolade gauche (accolade gauche) | |
| | | 124 | Ligne verticale (ligne verticale) | |
| } | 125 | Accolade droite (accolade droite) | |
| ~ | 126 | Tilde (tilde) | |
| 127 | |||
| € | 128 | & Euro; | Symbole de l'euro (signe de l'euro) |
| 129 | Inutilisé (non utilisé) | ||
| , | 130 | & Sbquo; | Guillemets simples (simples avec un faible 9 QUOTE) |
| ƒ | 131 | &Fnof; | Passionné latin petit E |
| " | 132 | & Bdquo; | Guillemets doubles (double low-9 QUOTE) |
| ... | 133 | & Hellip; | Points de suspension horizontaux (points de suspension horizontaux) |
| † | 134 | & Dague; | Dague (Dague) |
| ‡ | 135 | & Dague; | Double croix (double croix) |
| 136 | & CO; | Accent d'enveloppe de lettre modifié (Accent d'enveloppe de lettre modifié) | |
| ‰ | 137 | &Permil; | Symbole Permill (signe pour mille) |
| Š | 138 | & Scaron ; | Lettre latine S avec carona |
| < | 139 | & Lsaquo; | Citation d'angle à signe unique gauche (signe unique à gauche indiquant la citation d'angle) |
| IL | 140 | Œ | Ligatures latino-américaines majuscules O.E. |
| 141 | Inutilisé (non utilisé) | ||
| Ž | 142 | Ž | Lettre majuscule latine Z caron |
| 143 | Inutilisé (non utilisé) | ||
| 144 | Inutilisé (non utilisé) | ||
| " | 145 | & Lsquo; | Guillemet simple gauche (guillemet simple gauche) |
| " | 146 | & rsquo; | Citation simple droite (Citation simple droite) |
| " | 147 | « | Guillemets doubles gauches (guillemets doubles gauches) |
| " | 148 | & Rdquo; | Guillemets doubles droits (guillemets doubles droits) |
| 149 | & Taureau; | Balle (balle) | |
| - | 150 | - | Tiret/trait d'union (tiret anglais) |
| - | 151 | &Mdash; | Tiret Em (tiret EM) |
| ~ | 152 | & Tilda; | Petites lignes ondulées (petit tilde) |
| ™ | 153 | & Commerce; | Symbole Marque déposée (signe de marque) |
| š | 154 | & Scaron ; | Lettre latine s de carona |
| > | 155 | &Rsaquo; | Signe de guillemet à coin unique droit (coin unique à droite indiquant les guillemets) |
| œ | 156 | & Oelig; | Ligatures latines O.E. |
| 157 | Inutilisé (non utilisé) | ||
| ž | 158 | Ž | Lettre latine g avec carona |
| Ÿ | 159 | & Miam; | Lettre latine Y avec tréma (tréma) de |
| 160 | & Nbsp; | Espace incassable (pas de coupure dans l'espace) | |
| 161 | &Iexcl; | Point d'exclamation inversé (point d'exclamation inversé) | |
| ¢ | 162 | ¢ | Cent (signe cent) |
| £ | 163 | &kg; | Signe dièse (signe dièse) |
| 164 | & Curren ; | Symbole monétaire (signe monétaire) | |
| ¥ | 165 | & Yens ; | symbole du yen (signe du yen) |
| | | 166 | &Brvbar; | Bande verticale brisée (barre en pointillés) |
| § | 167 | & Secte; | Numéro de section (la section est marquée) |
| ¨ | 168 | &UYAM; | Ttréma (tréma) |
| © | 169 | & Copie; | Copyright (signe de copyright) |
| ª | 170 | &Ordf; | Signe négatif du nombre ordinal (indicateur ordinal féminin) |
| << | 171 | & LAQUO; | Double coin gauche du guillemet (gauche indiquant le double coin du guillemet) |
| 172 | & Pas; | Tilda (ne signe pas) | |
| 173 | & Timide; | Tirets souples (traits d'union souples) | |
| ® | 174 | &Rég; | Marque déposée (marque déposée) |
| ¯ | 175 | &Macr; | Macron (macron) |
| ° | 176 | &Deg; | Symbole Degré (degré de signe) |
| ± | 177 | &Plusmn; | Signe moins/signe (signe plus-moins) |
| ² | 178 | &Sup2; | Exposant 2 (exposant deux) |
| ³ | 179 | &Sup3; | Exposant 3 (exposant trois) |
| " | 180 | Et épicé ; | Aigu (accent aigu) |
| μ | 181 | & Micro; | Symbole M (micro-signe) |
| ¶ | 182 | &Para; | Symbole de paragraphe (marque de paragraphe) |
| · | 183 | & Middot; | Point intermédiaire (milieu) |
| ¸ | 184 | &Cédil; | Diacritiques (cédilem) |
| ¹ | 185 | & MOINS DE 1 ; | Exposant 1 (exposant un) |
| º | 186 | & Ordm; | Numéro de signe ordinal masculin (indicateur ordinal masculin) |
| » | 187 | & RAQUO; | Guillemet à double angle droit (à droite indiquant un guillemet à double angle) |
| ¼ | 188 | &Frac14; | 1/4 Score (fraction vulgaire un quart) |
| ½ | 189 | &Frac12; | 1/2 Score (fraction vulgaire de la moitié) |
| ¾ | 190 | &Frac34; | 3/4 Note totale (fraction vulgaire trois quarts) |
| ¿ | 191 | ? | Point d'interrogation inversé (point d'interrogation inversé) |
| À | 192 | &Une tombe; | Lettre majuscule latine A avec accent (sérieux) de |
| Á | 193 | &Aigu; | Lettre majuscule latine A avec accent aigu (aigu) de |
| Â | 194 | &ACIRC; | Lettre majuscule latine A avec accent enveloppant (enveloppe) de |
| M | 195 | Ã | Lettre majuscule latine A avec tilde |
| Ä | 196 | &AUML; | Lettre majuscule latine A avec tréma (tréma) de |
| Å | 197 | &Un anneau; | Lettre majuscule latine A avec cercle |
| Æ | 198 | & AElig; | Lettres latines AE |
| BZ | 199 | &Ccédil; | Lettre majuscule latine C avec cédille (cédille) de |
| È | 200 | &Égrave; | Lettre majuscule latine E avec accent (sérieux) de |
| É | 201 | É | Lettre majuscule latine E avec accent aigu (aigu) de |
| Ê | 202 | &Écirc; | Lettre majuscule latine E circonflexe |
| Ë | 203 | & Euml; | Lettre majuscule latine E avec tréma (tréma) de |
| Ì | 204 | Ì | |
| N | 205 | &Iaigu; | Lettre latine avec accent aigu (aigu) du I |
| Î | 206 | Î | |
| Ï | 207 | ï | Lettre latine avec tréma (tréma) de I |
| Ð | 208 | Ð | Lettre latine Eth |
| DH | 209 | ñ | Lettre majuscule latine N avec tilde |
| T | 210 | Ò | Lettre majuscule latine O avec accents (sérieux) de |
| Ó | 211 | é | Lettre majuscule latine O avec accent aigu (aigu) de |
| F | 212 | Ô | Lettre majuscule latine O avec accent enveloppant (enveloppe) de |
| Õ | 213 | Õ | Lettre majuscule latine O tilde |
| Ö | 214 | Ö | Lettre majuscule latine O avec tréma (tréma) de |
| × | 215 | & Horaires ; | Multiplication (signe de multiplication) |
| Ø | 216 | & Oslash ; | Lettre majuscule latine O barrée |
| Ù | 217 | Ù | Lettres majuscules latines avec accents (sérieux) en U |
| Ú | 218 | Ú | Lettre latine avec accent aigu (aigu) de U |
| Û | 219 | Û | Lettre latine avec accent d'enveloppe (enveloppe) de U |
| Ü | 220 | Ü | Lettre latine avec tréma (tréma) de U |
| Ý | 221 | Ý | Lettre majuscule latine Y avec accent aigu (aigu) de |
| Þ | 222 | & ÉPINE; | Lettre majuscule latino-américaine Épine |
| ß | 223 | &Szlig; | Lettre latine s dièse |
| à | 224 | &Une tombe; | Lettre latine a avec accents (sérieux) de |
| á | 225 | &Aigu; | Lettre latine a avec accent aigu (aigu) de |
| â | 226 | &ACIRC; | Lettre latine a avec un accent enveloppant (enveloppe) de |
| ã | 227 | Ã | Lettre latine a avec tilde |
| ä | 228 | &AUML; | Lettre latine a avec tréma (tréma) de |
| å | 229 | &Un anneau; | Lettre minuscule latine A avec cercle dessus |
| æ | 230 | & Aelig; | Lettres minuscules latines ae |
| ç | 231 | &Ccédil; | Lettre latine c avec cédille (cedilla) de |
| è | 232 | &Égrave; | Lettre latine e avec accents (sérieux) de |
| é | 233 | É | Lettre latine e avec accent aigu (aigu) de |
| ê | 234 | &Écirc; | Lettre latine e avec un accent enveloppant (enveloppe) de |
| Mobile | 235 | & Euml; | Lettre latine e avec tréma (tréma) de |
| ì | 236 | Ì | Lettre latine I avec accents (sérieux) de |
| í | 237 | &Iaigu; | Lettre latine I avec accent aigu (aigu) de |
| î | 238 | Î | Lettre latine I avec accent enveloppant (enveloppe) de |
| ï | 239 | ï | Lettre latine I avec tréma (tréma) de |
| ð | 240 | &Eth; | Lettre latine ETH |
| ñ | 241 | ñ | Lettre latine N avec tilde |
| Équant | 242 | Ò | Lettre latine O avec accent (sérieux) de |
| développement des capacités musicales | 243 | é | Lettre latine O avec accent aigu (aigu) de |
| Gandalf | 244 | Ô | Lettre latine O avec un accent enveloppant (enveloppe) de |
| õ | 245 | Õ | Lettre latine O avec tilde |
| ö | 246 | Ö | Lettre latine O avec tréma (tréma) de |
| ÷ | 247 | & Diviser; | Diviser |
| ø | 248 | & Oslash ; | Lettre latine O barrée |
| ù | 249 | Ù | Lettres latines minuscules avec accent (rugueux) de et |
| ú | 250 | Ú | Petit cas latin avec accent aigu (aigu) de et |
| û | 251 | Û | Lettres latines minuscules avec accent de métacaractère (enveloppe) de et |
| ü | 252 | Ü | Lettres latines minuscules avec tréma (tréma) de et |
| ý | 253 | Ý | Petit cas latin avec accent aigu (aigu) de y |
| þ | 254 | & Épine ; | Lettre latine épine |
| ÿ | 255 | & Miam; | Lettre latine y avec tréma (tréma) de |
Caractères de contrôle ANSI
Les caractères de contrôle ANSI (00-31, plus 127) ont été initialement conçus pour contrôler des périphériques matériels tels que des imprimantes, des lecteurs de bande, etc.
Les caractères de contrôle (à l'exception des tabulations horizontales, des sauts de ligne et des carets extérieurs) n'ont aucun effet dans un document HTML.
| 字符 | 编号 | 描述 |
|---|---|---|
| NUL | 00 | 空字符(caractère nul) |
| SOH | 01 | 标题开始(début de l'en-tête) |
| STX | 02 | 正文开始(début du texte) |
| ETX | 03 | 正文结束(fin du texte) |
| EOT | 04 | 传输结束 (fin de la transmission) |
| ENQ | 05 | 请求(enquête) |
| ACCK | 06 | 收到通知/响应(reconnaître) |
| BEL | 07 | 响铃(cloche) |
| BS. | 08 | 退格(retour arrière) |
| HT | 09 | 水平制表符(onglet horizontal) |
| LF | 10 | 换行(saut de ligne) |
| Vermont | 11 | 垂直制表符(onglet vertical) |
| FR | 12 | 换页(saut de page) |
| CR | 13 | 回车 (retour chariot) |
| DONC | 14 | 不用切换(déplacement) |
| SI. | 15 | 启用切换(shift in) |
| DLE | 16 | 数据链路转义 (échappement de liaison de données) |
| DC1 | 17 | 设备控制 1(contrôle de l'appareil 1) |
| DC2 | 18 | 设备控制 2 (contrôle de l'appareil 2) |
| DC3 | 19 | 设备控制 3(contrôle de l'appareil 3) |
| DC4 | 20 | 设备控制 4 (contrôle de l'appareil 4) |
| N.A.K. | 21 | 拒绝接收/无响应(accusé de réception négatif) |
| SYN | 22 | 同步空闲 (synchroniser) |
| ETB | 23 | 传输块结束 (fin du bloc de transmission) |
| PEUT | 24 | 取消(annuler) |
| E.M. | 25 | 已到介质末端/介质存储已满(fin du support) |
| SOUS | 26 | 替补/替换(substitut) |
| ÉCHAP | 27 | 溢出/逃离/取消(évasion) |
| FS | 28 | 文件分隔符(séparateur de fichiers) |
| G.S. | 29 | 组分隔符(séparateur de groupe) |
| R.S. | 30 | 记录分隔符(séparateur d'enregistrement) |
| NOUS | 31 | 单元分隔符(séparateur d'unité) |
| DEL | 127 | Supprimer(supprimer) |