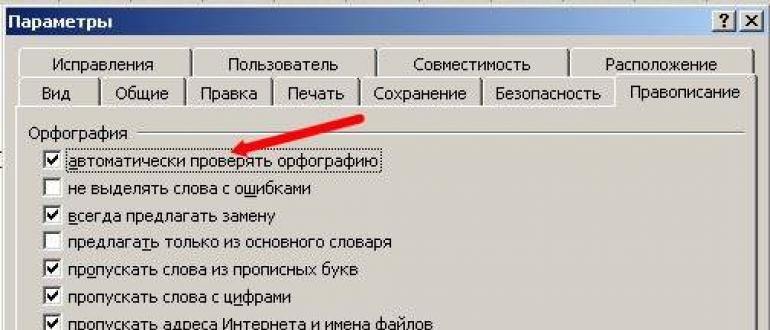
Bitiruvchi doktor Internetda ilmiy nomzodlik dissertatsiyasining adabiy sharhini, nomzodga minimal imtihonga tayyorgarlik ko'rish uchun xorijiy tilda maqolalarni, zamonaviy tadqiqot usullarining tavsifini va boshqa ko'p narsalarni topishi mumkin ...
Qanday qilib qidirish mexanizmlaridan foydalangan holda Internetda ma'lumot qidirish kerakligi ushbu maqolada muhokama qilinadi.
Sayt, server kabi tushunchalarni hali juda yaxshi bilmaganlar uchun men sizga Internet haqidagi dastlabki ma'lumotlar haqida xabar beraman.
Internet - bu aloqa kanallari (telefon, optik-tolali va sun'iy yo'ldosh tarmoqlari) orqali ulangan serverlarda joylashgan ko'plab saytlar.
Sayt - bu giperhavolalar bilan bog'langan html formatidagi hujjatlar to'plami (sayt sahifalari).
Katta sayt (masalan, "Medlink" - mavzuli tibbiy katalog - http://www.medlinks.ru - 30000 sahifadan iborat va serverda joylashgan disk maydoni 400 MB ni tashkil qiladi).
Kichkina sayt bir necha o'nlab - yuzlab sahifalardan iborat va 1 - 10 Mb ni tashkil qiladi (masalan, 2004 yil 25 iyulda "Mening aspirantura doktori" veb-saytim 280 .htm sahifadan iborat va serverda 6 Mbni egallagan).
Server Internetga ulangan va kun davomida ishlaydigan kompyuterdir. Serverdan bir vaqtning o'zida bir necha yuzdan bir necha minggacha saytlarga kirish mumkin.
Server kompyuterida joylashgan saytlarni Internet foydalanuvchilari ko'rishlari va nusxalashlari mumkin.
Saytlarga uzluksiz kirishni ta'minlash uchun server uzluksiz quvvat manbalari bilan ta'minlanadi va serverlar ishlaydigan xonada (ma'lumotlar markazi) avtomatik yong'in o'chirish tizimi bilan jihozlangan, tunu-kun texnik xodimlar navbatchilik qilmoqda.
O'zining 10 yildan ortiq vaqt davomida Runet (rus tilidagi Internet) tartibli tuzilishga aylandi va Internetda ma'lumot qidirish yanada aniqroq bo'ldi.
Internetda ma'lumot topishning asosiy vositasi qidiruv tizimlari.
Qidiruv mexanizmi Internet-saytlarni skanerlashtiradigan o'rgimchak dasturidan va ko'rib chiqilgan saytlar to'g'risidagi ma'lumotlarni o'z ichiga olgan ma'lumotlar bazasidan (indeks) iborat.
Veb-ustasining talabiga binoan o'rgimchak roboti saytga kiradi va sayt sahifalariga qidiruv mexanizmi indeksiga sayt sahifalari haqidagi ma'lumotlarni kiritadi. Qidiruv mexanizmining o'zi saytni topishi mumkin, hatto uning veb-ustasi ro'yxatdan o'tish uchun murojaat qilmagan bo'lsa ham. Agar saytga havola qidiruv tizimining yo'lida biron bir joyga kirsa (masalan, boshqa saytda), u darhol saytni indekslaydi.
O'rgimchak sayt sahifalarini qidiruv tizimining indeksiga ko'chirmaydi, lekin saytning har bir sahifasining tuzilishi haqida ma'lumotni saqlaydi - masalan, hujjatda qanday so'zlar va qanday tartibda, saytning giperhavolalari URL-manzillari, kilobaytlardagi hujjat hajmi, yaratilgan sana va boshqalar. Shuning uchun qidiruv tizimining indekslari indekslangan ma'lumotlarning miqdoridan bir necha baravar kichikdir.
Qidiruv mexanizmi Internetda nimani qidiradi?
Odamlar ularga ma'lumot topishga yordam berish uchun qidiruv tizimini taklif qilishdi. Bizning inson tushunchamiz va vizual tasvirimizdagi ma'lumotlar nima? Bu hidlar yoki tovushlar emas, sezgi emas va tasvirlar emas. Bu shunchaki so'zlar, matnlar. Internetda biron bir narsani qidirganimizda, biz so'zlarni so'raymiz - qidiruv so'rovi va bunga javoban biz aynan shu so'zlarni o'z ichiga olgan matnni olishga umid qilamiz. Biz bilamizki, qidirish tizimi ma'lumot qatorida biz so'ragan so'zlarni aniq qidiradi. Chunki u so'zlarni qidirishga tushdi.
Qidiruv mexanizmi Internetda so'zlarni izlamaydi, lekin uning indeksida. Qidiruv mexanizmi indeksida juda oz miqdordagi Internet-saytlar to'g'risidagi ma'lumotlar mavjud. Faqat ingliz tilidagi saytlarni indekslaydigan qidiruv tizimlari mavjud va ularning indeksiga faqat rus tilidagi saytlarni kiritadigan qidiruv tizimlari mavjud.
(indeksda ingliz, nemis va boshqa Evropa tillarida saytlar mavjud)
Runet qidiruv tizimlari (indeks rus tilidagi saytlarni o'z ichiga oladi)
Ba'zi Runet qidiruv tizimlarining xususiyatlari
Google qidiruv tizimi rus tilining morfologiyasini hisobga olmaydi. Masalan, Google "dissertatsiya" va "dissertatsiya" so'zlarini har xil deb hisoblaydi.
Siz nafaqat qidiruv so'rovi natijasining birinchi sahifasini, balki qolganlarini ham ko'rishingiz kerak.
Chunki ko'pincha foydalanuvchi tomonidan haqiqatan ham zarur bo'lgan ma'lumotlarni o'z ichiga olgan saytlar qidiruv so'rovi natijasining 4-10-sahifalarida joylashgan.
Nega bunday bo'lmoqda? Birinchidan, ko'plab sayt yaratuvchilar o'zlarining sayt sahifalarini qidiruv tizimlari uchun optimallashtirmaydilar, masalan, sayt sahifalarida meta teglarini kiritmaydilar.
Meta teglar veb-hujjatning xizmat ko'rsatish elementlari bo'lib, ular ekranda ko'rinmaydi, ammo saytingiz qidiruv tizimlari tomonidan qidirilganda muhimdir. Meta-teglar qidirish mexanizmlarini qidirishni osonlashtiradi, shunda ular hujjatga chuqurroq kirib borishlari va saytning butun matnini aniq rasmini tuzishlari kerak emas. Eng muhim meta teg bu meta NAME \u003d "kalit so'zlar" - sayt sahifasining kalit so'zlari. Agar hujjatning asosiy matnidan olingan so'z "qidirish spami" deb hisoblanmasa va birinchi "50" orasida bo'lsa, unda so'rovda ushbu so'zning og'irligi oshadi, ya'ni hujjat yanada muhim ahamiyat kasb etadi.
Ikkinchidan, qidiruv so'rovi natijasida birinchi pozitsiyalar uchun saytlarning veb-ustalari o'rtasida qattiq raqobat.
Statistikaga ko'ra, saytga tashrif buyuruvchilarning 80 foizi qidiruv tizimlaridan keladi. Ertami-kechmi, veb-ustalar buni tushunishadi va o'z saytlarini qidiruv tizimlarining qonunlariga moslashtirishni boshlaydilar.
Afsuski, ba'zi saytlarni yaratuvchilar qidiruv tizimlari orqali o'z saytlarini targ'ib qilishning noo'rin usulidan foydalanadilar - "qidiruv spam" deb nomlangan meta-teglar mazmuniga va saytning qolgan qismidagi matnga mos keladigan ko'rinishni yaratish uchun - saytdagi fonda yashirin so'zlarni joylashtiring, shunda ular Saytga tashrif buyuruvchilarga xalaqit bermang. Biroq, qidiruv tizimlarini yaratuvchilari bunday nayranglarni kuzatadilar va "qidirish spammer" sayti eng pastdan pastga tushadi.
Metafora va majoziy taqqoslashlar Internetda kam ishlatilgan. Ular haqiqatni buzib ko'rsatadilar, Internet foydalanuvchilarini aniq va aniq ma'lumotlardan uzoqlashtiradilar. Sayt muallifining uslubi qanchalik badiiyligi va aniqligi kam bo'lsa, qidiruv natijalarida sayt mavqei shunchalik yuqori bo'ladi.
O'z navbatida, agar siz qidiruv tizimidan Internetda maqolalar topishni istasangiz, xuddi shunday o'ylab ko'ring, mashinaga aylaning. Hech bo'lmaganda bir muddat. Qidiruv vaqtida.
Nima bu
DuckDuckGo juda mashhur bo'lgan ochiq manbali qidirish mexanizmi. Serverlar AQShda joylashgan. O'z robotiga qo'shimcha ravishda, qidiruv tizimi boshqa manbalarning natijalaridan foydalanadi: Yahoo, Bing, Wikipedia.
Yaxshisi
DuckDuckGo o'zini maksimal maxfiylik va maxfiylikni ta'minlaydigan qidiruv sifatida joylashtiradi. Tizim foydalanuvchi haqida hech qanday ma'lumot to'plamaydi, jurnallarni saqlamaydi (qidiruv tarixi yo'q), cookie-fayllardan foydalanish imkon qadar cheklangan.
DuckDuckGo foydalanuvchi ma'lumotlarini to'plamaydi yoki almashmaydi. Bu bizning maxfiylik siyosatimiz.
Gabriel Vaynberg, DuckDuckGo asoschisi
Sizga nima kerak?
Barcha yirik qidiruv tizimlari monitor oldida turgan odam to'g'risidagi ma'lumotlarga asoslanib shaxsiylashtirishga harakat qilishadi. Ushbu hodisa "filtr pufagi" deb nomlanadi: foydalanuvchi faqat uning afzalliklariga mos keladigan yoki tizim ularni hisobga olgan natijalarni ko'radi.
DuckDuckGo sizning Internetdagi oldingi harakatlaringizga bog'liq bo'lmagan ob'ektiv rasmni yaratadi va sizning so'rovlaringiz asosida Google va Yandex-ning tematik reklamasini yo'q qiladi. DuckDuckGo-dan foydalanib, ma'lumotni xorijiy tillarda qidirish juda oson: Google va Yandex, sukut bo'yicha, rus tilidagi saytlarni afzal ko'radi, hatto so'rov boshqa tilda bo'lsa ham.

Nima bu
evil emas - bu Tor tarmog'ini qidiradigan tizim. Foydalanish uchun siz ushbu tarmoqqa kirishingiz kerak, masalan, xuddi shu nomdagi ixtisoslashtirilgan tarmoqni ishga tushirish orqali.
emas Yomonlik o'z turidagi yagona qidiruv tizimi emas. LOOK (Tor brauzerida standart qidiruv, odatiy Internetdan foydalanish mumkin) yoki TORCH (Tor tarmog'idagi eng qadimgi qidiruv tizimlaridan biri) va boshqalar mavjud. Biz Google-ning aniq ko'rsatmasi tufayli Evolyutsiyaga emas (faqat boshlang'ich sahifaga qarang) asosida qaror qildik.
Yaxshisi
U Google, Yandex va boshqa qidiruv tizimlariga kirish taqiqlangan joylarni qidiradi.
Sizga nima kerak?
Tor tarmog'ida doimiy Internetda topib bo'lmaydigan ko'plab manbalar mavjud. Rasmiylar Tarmoq tarkibini nazorat qilishni kuchaytirishi bilan ularning soni ortadi. Tor - bu ijtimoiy tarmoqlar, torrent treylerlari, ommaviy axborot vositalari, bozor, bloglar, kutubxonalar va boshqalar bilan Tarmoq ichidagi o'ziga xos tarmoq.
3. YaCy

Nima bu
YaCy - P2P tarmoqlari printsipiga asoslangan markazlashtirilmagan qidiruv tizimi. Asosiy dasturiy modul o'rnatilgan har bir kompyuter Internetni mustaqil ravishda skanerdan o'tkazadi, ya'ni qidiruv robotining analogidir. Natijalar barcha YaCy foydalanadigan umumiy ma'lumotlar bazasida to'planadi.
Yaxshisi
Bu yaxshiroqmi yoki yomonmi, aytish qiyin, chunki YaCy - bu qidiruvlarni tashkil etishga mutlaqo boshqacha yondashuv. Yagona server va egalik qiluvchi kompaniyaning yo'qligi natijalarni istalgan narsadan mutlaqo mustaqil qiladi. Har bir tugunning avtonomligi tsenzurani yo'q qiladi. YaCy chuqur veb va indekslanmagan umumiy tarmoqlarni qidirishga qodir.
Sizga nima kerak?
Agar siz ochiq manbali dasturiy ta'minot va bepul Internetni qo'llab-quvvatlasangiz, davlat idoralari va yirik korporatsiyalar ta'siriga uchramasangiz, YaCy sizning tanlovingiz bo'ladi. Bundan korporativ yoki boshqa avtonom tarmoq ichidagi qidiruvlarni tashkil qilish uchun ham foydalanish mumkin. Va YaCy kundalik hayotda juda foydali bo'lmasa-da, qidiruv jarayoni nuqtai nazaridan Google-ga munosib alternativadir.
4. Pipl

Nima bu
Pipl - ma'lum bir odam haqida ma'lumot qidirish uchun yaratilgan tizim.
Yaxshisi
Pipl mualliflarining ta'kidlashicha, ularning ixtisoslashgan algoritmlari "odatiy" qidiruv tizimlariga qaraganda samaraliroq. Xususan, ijtimoiy tarmoqlar profillari, sharhlar, ishtirokchilar ro'yxati va odamlar to'g'risidagi ma'lumotlar nashr etiladigan turli xil ma'lumotlar bazalari, masalan, sud qarorlari kabi ustuvor ma'lumot manbalari. Pipl kompaniyasining ushbu sohada etakchilik qilishi Lifehacker.com, TechCrunch va boshqa nashrlar tomonidan tasdiqlangan.
Sizga nima kerak?
Agar siz AQShda yashayotgan odam haqida ma'lumot topishingiz kerak bo'lsa, u holda Pipl Google-ga qaraganda ancha samarali bo'ladi. Rossiya kemalarining ma'lumotlar bazalari, ehtimol, qidiruv tizimida mavjud emas. Shuning uchun u Rossiya fuqarolariga bu qadar yaxshi yordam bermaydi.

Nima bu
FindSounds yana bir ixtisoslashgan qidiruv tizimidir. Ochiq manbalarda turli xil tovushlarni (uy, tabiat, avtomobillar, odamlar va boshqalar) qidirish. Xizmat rus tilidagi so'rovlarni qo'llab-quvvatlamaydi, ammo rus tilidagi teglarning ta'sirchan ro'yxati bor, ularni qidirishingiz mumkin.
Yaxshisi
Faqat tovushlarni chiqarishda va boshqa hech narsa yo'q. Qidiruv sozlamalarida siz xohlagan format va ovoz sifatini o'rnatishingiz mumkin. Barcha topilgan tovushlarni yuklab olish mumkin. Naqshdagi tovushlarni qidirish mavjud.
Sizga nima kerak?
Agar siz mushk zarbasining ovozini, yog'och o'stirgichning zarbalarini yoki Gomer Simpsonning qichqirig'ini tezda topishingiz kerak bo'lsa, unda bu xizmat siz uchun. Va biz buni faqat rus tilidagi mavjud so'rovlardan tanladik. Ingliz tilida spektr yanada kengroq.
Ammo jiddiy, ixtisoslashgan xizmat ixtisoslashtirilgan auditoriyani o'z ichiga oladi. Ammo bu sizga yordam beradigan bo'lsa-chi?

Nima bu
Wolfram | Alfa qidiruv tizimi. Kalit so'zlarni o'z ichiga olgan maqolalarga havolalar o'rniga, foydalanuvchi so'roviga tayyor javob beradi. Masalan, agar siz "Nyu-York va San-Fransisko aholisini taqqoslash" ni ingliz tilidagi qidiruv shakliga kirsangiz, Wolfram | Alpha darhol taqqoslash bilan jadval va grafikalarni ko'rsatadi.
Yaxshisi
Ushbu xizmat faktlarni topish va ma'lumotlarni hisoblash uchun boshqalarga qaraganda yaxshiroqdir. Wolfram | Alpha Internetda turli sohalarda, jumladan fan, madaniyat va ko'ngilocharda mavjud bo'lgan ma'lumotlarni to'playdi va tashkil etadi. Agar ushbu ma'lumotlar bazasida qidirish so'roviga tayyor javob mavjud bo'lsa, tizim uni ko'rsatadi, agar bo'lmasa, natijani hisoblab chiqadi va ko'rsatadi. Bunday holda, foydalanuvchi faqat kerakli ma'lumotlarni ko'radi va boshqa hech narsa bo'lmaydi.
Sizga nima kerak?
Agar siz, masalan, talaba, tahlilchi, jurnalist yoki tadqiqotchi bo'lsangiz, Wolfram | Alpha-dan o'zingizning harakatlaringiz bilan bog'liq ma'lumotlarni qidirish va hisoblash uchun foydalanishingiz mumkin. Xizmat barcha so'rovlarni tushunmaydi, lekin doimiy ravishda rivojlanib, yanada oqilona bo'ladi.

Nima bu
Dogpile metasearch mexanizmi Google, Yahoo va boshqa mashhur tizimlarning qidiruv natijalari natijalarining birlashtirilgan ro'yxatini namoyish etadi.
Yaxshisi
Birinchidan, Dogpile kamroq reklama namoyish qiladi. Ikkinchidan, xizmat turli xil qidirish mexanizmlaridan eng yaxshi natijalarni topish va namoyish qilish uchun maxsus algoritmdan foydalanadi. Dogpile ishlab chiquvchilariga ko'ra, ularning tizimlari butun Internetda eng to'liq chiqishni tashkil qiladi.
Sizga nima kerak?
Agar siz Google yoki boshqa standart qidiruv tizimida ma'lumot topa olmasangiz, Dogpile-dan foydalanib, uni bir vaqtning o'zida bir nechta qidiruv tizimlarida qidirib toping.

Nima bu
BoardReader - bu forumlar, savol-javoblar xizmatlari va boshqa hamjamiyatlarning matn qidirish tizimi.
Yaxshisi
Xizmat sizga qidiruv maydonini ijtimoiy saytlarga toraytirish imkonini beradi. Maxsus filtrlar yordamida siz mezonlaringizga mos keladigan yozuvlarni va foydalanuvchi sharhlarini tezda topishingiz mumkin: til, nashr etilgan sana va sayt nomi.
Sizga nima kerak?
BoardReader PR-mutaxassislar va ommaviy axborot vositalarining ma'lum mavzular bo'yicha fikrlari bilan qiziqadigan boshqa OAV mutaxassislari uchun foydali bo'lishi mumkin.
Xulosa
Muqobil qidiruv tizimlarining hayoti tez-tez o'tib ketadi. Bunday loyihalarning uzoq muddatli istiqbollari haqida Lifehacker Yandeksning Ukraina filialining sobiq bosh direktori Sergey Petrenkodan so'radi.

Sergey Petrenko
Yandex.Ukraine sobiq bosh direktori.
Muqobil qidiruv tizimlarining taqdiriga kelsak, bu juda oddiy: kichik auditoriya bilan juda yaxshi loyihalar bo'lish, shuning uchun aniq tijorat istiqbolisiz yoki aksincha, ularning yo'qligini to'liq aniqlik bilan.
Agar siz maqoladagi misollarga qarasangiz, bunday qidiruv tizimlari tor yoki talab qilinadigan joylarga ixtisoslashganini ko'rishingiz mumkin, ehtimol ular Google yoki Yandex radarlarida ko'rinadigan darajada o'smagan yoki ular o'zlarining taxminlarini reytingda sinab ko'rishgan, odatiy qidiruvda hali qo'llanilmaydi.
Masalan, agar Tor qidiruviga to'satdan talab qilinsa, ya'ni Google auditoriyasining kamida foizi natijalarga muhtoj bo'lsa, unda oddiy qidiruv tizimlari ularni qanday topish va foydalanuvchiga ko'rsatish masalasini hal qila boshlaydi. Agar tomoshabinlarning xatti-harakati shuni ko'rsatadiki, foydalanuvchilarning sezilarli sonli so'rovlaridagi sezilarli ulushi natijalarga, ma'lumotlarga, foydalanuvchiga bog'liq bo'lgan omillarni hisobga olmagan holda ko'proq mos kelsa, Yandex yoki Google bunday natijalarni berishni boshlaydi.
Ushbu maqola kontekstida yaxshiroq bo'lish, hamma narsada yaxshiroq bo'lish degani emas. Ha, ko'p jihatdan bizning qahramonlarimiz Google va Yandex-dan juda uzoq (hatto Bing-dan ham uzoq). Ammo ushbu xizmatlarning har biri foydalanuvchiga qidiruv sohasidagi gigantlar taklif qila olmaydigan narsalarni beradi. Siz ham shunga o'xshash loyihalarni bilasiz. Biz bilan baham ko'ring - biz muhokama qilamiz.
Qidiruv motorlar
Qidiruv tizimlari sizga ma'lum mavzularga tegishli yoki kalit so'zlar yoki ularning kombinatsiyalari bilan jihozlangan WWW-hujjatlarni topishga imkon beradi. Qidiruv tizimlarida qidirishning ikki yo'li mavjud:
Kontseptsiyalar ierarxiyasiga muvofiq;
· Kalit so'zlar bo'yicha.
Qidiruv tizimlari avtomatik yoki qo'lda to'ldiriladi. Qidiruv serveri odatda boshqa qidiruv tizimlariga havolalarga ega va foydalanuvchining talabiga binoan ularga so'rov yuboradi.
Ikkita turdagi qidiruv tizimlari mavjud.
1. Veb-sahifadagi har bir so'zni indekslaydigan to'liq matnli qidiruv tizimlari, to'xtatish so'zlaridan tashqari.
2. Har bir sahifaning mavhumini yaratadigan "mavhum" qidiruv tizimlari.
Veb-ustalar uchun to'liq matnli mashinalar foydalidir, chunki veb-sahifada paydo bo'lgan har qanday so'z foydalanuvchi so'rovlariga mosligini aniqlash uchun tahlil qilinadi. Ammo mavhum mashinalar sahifalarni to'liq matnli sahifalarga qaraganda yaxshiroq indekslashlari mumkin. Bu ma'lumotni olish algoritmiga, masalan, xuddi shu so'zlarni ishlatish chastotasiga bog'liq.
Qidiruv tizimlarining asosiy xususiyatlari.
1. Qidiruv tizimining hajmi indekslangan sahifalar soni bilan belgilanadi. Shu bilan birga, har bir vaqtda, foydalanuvchi so'rovlariga javoban berilgan havolalar turli xil ko'rsatmalarga ega bo'lishi mumkin. Buning sabablari:
· Ba'zi bir qidiruv tizimlari foydalanuvchi so'roviga binoan sahifani darhol indekslaydi va keyin indekslanmagan sahifalarni indekslashni davom ettiradi.
· Boshqalar ko'pincha eng mashhur veb-sahifalarni indekslashadi.
2. Indekslash sanasi. Ba'zi qidiruv tizimlari hujjat indekslangan sanani ko'rsatadi. Bu foydalanuvchiga tarmoqdagi hujjat qachon paydo bo'lganligini aniqlashga yordam beradi.
3. Indekslash chuqurligi ko'rsatilgan qidiruv tizimidan keyin qancha sahifani indekslashni ko'rsatadi. Ko'pgina mashinalarda indeksatsiya chuqurligida hech qanday cheklovlar yo'q. Barcha sahifalarni indekslash mumkin emasligi sabablari:
· Ramka tuzilmalaridan noto'g'ri foydalanish.
Sayt xaritasini odatiy havolalar bilan takrorlanmasdan foydalanish
4. Ramkalar bilan ishlash. Agar qidiruv roboti ramka tuzilmalari bilan qanday ishlashni bilmasa, indekslashda ramkali ko'p tuzilmalar o'tkazib yuboriladi.
5. Bog'lanishlarning chastotasi. Katta qidiruv tizimlari hujjatning qanchalik mashhurligini uni qanchalik murojaat qilish orqali aniqlashi mumkin. Bunday ma'lumotlarga asoslangan ba'zi mashinalar hujjatni indeksatsiyalash kerakmi yoki yo'qmi degan xulosaga kelishadi.
6. Server yangilanishlarining chastotasi. Agar server tez-tez yangilanadigan bo'lsa, qidiruv mexanizmi uni tez-tez qayta joylashtiradi.
7. Indekslashni boshqarish. Qidiruv tizimini boshqarishingiz mumkinligini anglatadi.
8. Qayta yo'naltirish. Ba'zi saytlar tashrif buyuruvchilarni bitta serverdan boshqasiga yo'naltiradi va ushbu parametr bu topilgan hujjatlar bilan qanday bog'liqligini ko'rsatadi.
9. So‘zlarni to‘xtating. Ba'zi qidiruv tizimlari indekslarida ma'lum so'zlarni o'z ichiga olmaydi yoki foydalanuvchi so'rovlarida bu so'zlarni o'z ichiga olmaydi. Bunday so'zlar odatda old qo'shimchalar yoki tez-tez ishlatiladigan so'zlar deb hisoblanadi.
10.Spam jarimalari. Spamni blokirovka qilish imkoniyati.
11. Eski ma'lumotlarni o'chirib tashlang. Serverni yopish yoki uni boshqa manzilga o'tkazish paytida veb-ustaning xatti-harakatlarini aniqlaydigan parametr.
Qidiruv tizimlariga misollar.
1. Altavista. Tizim 1995 yil dekabrda ochilgan. DEC egasi. 1996 yildan beri Yahoo bilan hamkorlik qiladi. AltaVista - bu maxsus qidiruv uchun eng yaxshi variant . Biroq, natijalarni toifalarga qarab saralashkovaklar bajarilmaydi va siz taqdim etilgan ma'lumotlarni qo'lda ko'rishingiz kerak. AltaVista-da faol saytlar ro'yxati, yangiliklar yoki boshqa tarkib qidirish qobiliyatini olish uchun vositalar mavjud emas.
2.Ekscite qidirish. 1995 yil oxirida ishga tushirilgan. 1996 yil sentyabr oyida - WebCrawler tomonidan sotib olingan. Ushbu tugun kuchli qidirish mexanizmiga ega.nizm, avtomatik sozlash qobiliyatitaqdim etilgan ma'lumotlar, shuningdek malakali tomonidan tuzilganbir nechta tugunlarni tavsiflash uchun xodimlar.Hayajonlaning bunda boshqa qidirish tugunlaridan farq qiladiyangiliklar xizmatlarini qidirish va sharhlarni nashr etishga imkon beradiVeb-sahifalar. Qidiruv tizimida vositalar qo'llaniladistandart kalit so'z qidirish va evristiktarkib qidirish usullari. Ushbu kombinatsiya tufayli,siz mazmunli sahifalarni topishingiz mumkinInternet agar ularda foydalanuvchi kaliti bo'lmasatashqarida so'zlar. Qo'zg'alishning noqulayligi biroz tartibsiz interfeys.
3.HotBot. 1996 yil mayda ishga tushirilgan. Simli egalik qiladi. Berkeley Inktomi qidiruvi texnologiyasiga asoslangan. HotBot - bu to'liq matn bilan indekslangan hujjatlar va Internetdagi eng keng qamrovli qidiruv tizimlaridan biri bo'lgan ma'lumotlar bazasi. Uning mantiqiy shartlari va qidiruvni istalgan sohada yoki veb-sayt orqali cheklash vositalarida izlash vositasi foydalanuvchiga keraksiz ma'lumotlarni filtrlab, kerakli ma'lumotlarni topishga yordam beradi. HotBot ochiladigan ro'yxatlardan kerakli qidiruv parametrlarini tanlash imkoniyatini beradi.
4.InfoSeek. 1995 yil oldin sotuvga chiqarildi, osonlik bilan kirish mumkin. Hozirda 50 millionga yaqin URL-manzil mavjud. Infoseek-da yaxshi qidiruv vositalari bilan bir qatorda yaxshi mo'ljallangan interfeys mavjud. Ko'pgina so'rovlarga javoblar "tegishli mavzular" havolalari bilan birga keladi va har bir javobdan keyin "o'xshash sahifalar" havolalari mavjud. To'liq matnda indekslangan sahifalar uchun qidiruv tizimining ma'lumotlar bazasi. Javoblar ikkita ko'rsatkich bo'yicha tartiblanadi: har bir sahifada so'zlashuvlar yoki iboralar chastotasi sax, shuningdek sahifalardagi so'zlar yoki iboralarning joylashishi. Qidiruvni amalga oshirish mumkin bo'lgan yuzlab pastki kategoriyalarga ega bo'lgan 12 ta toifaga bo'lingan veb-katalog mavjud. Katalogning har bir sahifasida ro'yxat mavjud tavsiya etilgan tugunlar.
5. Likolar. 1994 yil may oyidan beri ishlaydi. Keng tarqalgan va ishlatilgan. Tuzilma juda ko'p miqdordagi URL-manzillarga ega bo'lgan katalogni o'z ichiga oladi. To'liq matnli indeksatsiyadan farqli o'laroq va sahifa tarkibini statistik tahlil qilish texnologiyasi bilan Point qidiruvi. Lycos yangiliklar, sayt sharhlari, mashhur saytlarga havolalar, shahar xaritalari va manzillarni qidirish vositalarini o'z ichiga oladi miltiq va ovoz va videokliplar.Likolar muvofiqlik darajasi bo'yicha javoblarni tashkil qiladibir nechta mezonlarga ko'ra so'rovlar, masalan, raqam bo'yichahujjatga izohda topilgan qidirish so'zlaricop, orasidagi vaqthujjatning ma'lum bir jumlasida so'zlarni qiling, joyhujjatdagi atamalar.
6. WebCrawler. 1994 yil 20 aprelda Vashington universitetining loyihasi sifatida ochildi. Veb-brauzer imkoniyatlar beradiso'rovlarni tezlashtirish uchun sintaksis, shuningdek katta tanlov oddiy interfeys bilan tugun izohlari.
Har bir javobning yonida, WebCrawler so'rovga qanday mos kelishini taxmin qiladigan kichik belgi bilan to'sib qo'yiladi. Shuningdek, u har bir javob uchun qisqacha xulosaga ega sahifani, uning to'liq URL-manzilini, muvofiqlikni aniq baholashni, shuningdek foydalanishni ko'rsatadi so'rovda ushbu javob uning kalit so'zlari sifatida modellashtirilgan.Kirish so'rovlarini sozlash uchun GUIVeb Crawler no. N e ruxsat berilganuniversal belgilardan foydalanish, shuningdek mumkin emaskalit so'zlarga vazn tayinlash. Qidiruv maydonini cheklash imkoniyati yo'qo'ziga xos maydon.
7. Yahoo. Yahoo-ning eng eski katalogi 1994 yil boshida ishga tushirildi. Keng tarqalgan, tez-tez ishlatiladigan va eng hurmatga sazovor. 1996 yil mart oyida bolalar uchun Yahooligans katalogi ishga tushirildi. Yahoo-ning mintaqaviy va eng yaxshi kataloglari paydo bo'ladi. Yahoo foydalanuvchi obunasiga asoslangan. Bu Internetda har qanday qidiruv uchun boshlang'ich nuqtasi bo'lib xizmat qilishi mumkin, chunki uning tasniflash tizimi yordamida foydalanuvchi yaxshi tashkil etilgan ma'lumotlarga ega sayt topadi. Yahoo! veb-sahifasida veb-tarkib 14 umumiy toifaga bo'linadi. Foydalanuvchi so'rovining o'ziga xos xususiyatlariga qarab, ushbu kategoriyalar bilan ish olib borish mumkin, ular pastki kategoriyalar va tugunlarning ro'yxatlari bilan tanishishlari yoki ma'lumotlar bazasida aniq so'zlar va atamalarni qidirishlari mumkin. Foydalanuvchi shuningdek Yahoo! ning istalgan bo'limi yoki bo'linmasida qidirishni cheklashi mumkin. Tugunlarni tasniflash odamlar tomonidan amalga oshirilganligi sababli vakompyuter orqali emas, aloqa sifati odatda juda yuqori. Ammo, muvaffaqiyatsiz bo'lsa, qidiruvingizni aniqlashtirish juda qiyin ish. Yahoo tarkibi ! qidiruv tizimi kiritilganAltaVista, shuning uchun Yahoo-da qidirishda muvaffaqiyatsiz bo'lsa. u avtomatik ravishda sodir bo'ladi qidirish mexanizmini takrorlashAltavista . Keyin natijalar uzatiladiYahoo! Yahoo! elektron pochta manzillarini bilish uchun Usenet va Fourl 1-ga qidiruvlarni yuborish imkoniyatini beradi.
Rossiya qidiruv tizimlariga quyidagilar kiradi:
1. Rambler.Bu rus tilidagi qidiruv tizimi. Ramblerning bosh sahifasida keltirilgan bo'limlar rus tilidagi veb-resurslarni qamrab oladi. Axborot klassifikatori mavjud. Ishning qulay usuli - har biri uchun eng ko'p tashrif buyurilgan saytlarning ro'yxatini taqdim etish taklif etilgan mavzular.
2. Aport qidirish. Aport etakchi sertifikatlangan qidiruv tizimlaridan biriMicrosoft mahalliy qidiruv kabirus versiyasi uchun tizimlarMicrosoft Internet Explorer Aport-ning afzalliklaridan biri bu onlayn-so'rovlar va qidiruv natijalarining inglizcha-ruscha va ruscha-inglizcha tarjimasi, shuning uchun siz rus internet-manbalarida qidirishingiz mumkin. rus tilini bilmasdan ham. Bundan tashqari ma'lumotlarni qidirishingiz mumkin iboralarni ishlatib, hatto jumlalar uchun ham.Aport qidiruv tizimining asosiy xususiyatlari orasida siz mumkinquyidagini baham ko'ring:
So'rov va qidiruv natijalarini rus tilidan ingliz tiliga tarjima qilishosmon tili va aksincha;
So'rovda imlo xatolarini avtomatik tekshirish;
Topilgan saytlar bo'yicha qidiruv natijalarining informatsion chiqishi;
Har qanday grammatik shaklda qidirish qobiliyati;
 |
kasblar uchun ilg'or so'rovlar tili haqiqiy foydalanuvchilar.
Boshqa qidiruv xususiyatlariga quyidagilar kiradibeshta asosiy kod sahifalari (turli xil ishlaydigan)tizimlari) rus tili uchun, qidiruv texnologiyalaridan foydalanishmenda cheklovlar mavjudURL manzili va hujjatlarning sanasi, qidiruvni amalga oshirish sarlavhalar, sharhlar va sarlavhalar orqalito'g'ridan-to'g'ri rasmlarga va hokazo, qidiruv parametrlarini tejash va aniqlasholdingi foydalanuvchi so'rovlarining soni, uyushma turli xil serverlarda joylashgan hujjatning nusxalari.
3. Ro'yxat. ru ( http://www.list.ru) Uni amalga oshirish bilan ushbu server juda ko'p narsalarga egaingliz tizimi bilan umumiyYahoo! Serverning asosiy sahifasida eng mashhur qidiruv toifalariga havolalar mavjud.
 |
Katalogning asosiy toifalariga havolalar ro'yxati asosiy hisoblanadi. Katalogda qidirish shunday amalga oshiriladi, shunda so'rov natijasida har ikkala sayt va toifani topish mumkin. Muvaffaqiyatli qidiruvda URL, ism, tavsif, kalit so'zlar ko'rsatiladi. Foydalanishga ruxsat berilgan yandex so'rovi tili. Bilanbog'lanish tarkibikatalog "alohida oynada kata to'liq toifasi ochiladijurnallar. Rubrikatordan istalgan tanlangan pastki kategoriyaga o'tish qobiliyati amalga oshirildi. Batafsil batafsil tematik bo'limjoriy bo'limda havolalar ro'yxati keltirilgan. Katalog quyidagicha tashkil etilgan barcha saytlar strukturaning quyi darajalarida joylashganligiturlar sarlavhalarda keltirilgan.Ko'rsatilgan manbalar ro'yxati alifbo tartibida tartiblangan, ammo siz saralashni tanlashingiz mumkin: vaqt bo'yichaqo'shimcha orqali o'tish orqali katalogga qo'shish tartibi, tomonidankatalogga tashrif buyuruvchilar orasida mashhurlik.
4. Yandeks. Yandex seriyali dasturiy mahsulotlar rus tilining morfologiyasini hisobga olgan holda to'liq matnli indeksatsiya va matn ma'lumotlarini qidirish vositalarining to'plamidir. Yandex tarkibiga morfologik tahlil va sintez, indeksatsiya va qidirish modullari, shuningdek, hujjat analizatori, belgilash tillari, format o'zgartirgichlari va o'rgimchak kabi yordamchi modullar to'plami kiradi.
Asosiy lug'atga asoslangan morfologik tahlil va sintez algoritmlari so'zlarni normallashtirishi, ya'ni ularning boshlang'ich shaklini topishi, shuningdek, asosiy lug'atda mavjud bo'lmagan so'zlar uchun gipotezalarni tuzishi mumkin. To'liq matnli indeksatsiya tizimi sizga ixcham indeks yaratish va mantiqiy operatorlar yordamida tezda qidirishga imkon beradi.
Yandex mahalliy va global tarmoqlardagi matnlar bilan ishlashga mo'ljallangan va boshqa tizimlarga modul sifatida ulanishi mumkin.
Qidiruv mexanizmi yoki oddiygina "qidiruv mexanizmi" bu foydalanuvchi so'roviga binoan veb-sahifalarni qidiradigan vositadir. Dunyodagi eng mashhur qidiruv tizimi Google, Rossiyada eng mashhuri Yandex, Yahoo esa eng qadimgi qidiruv tizimlaridan biri. Qidiruv tizimining arxitekturasini ajratib ko'rsatish mumkin qidiruv tizimi - dasturiy modullar to'plami bilan ifodalanadigan tizimning yadrosi; ma'lumotlar bazasi yoki indeksbarcha Internet qidiruv manbalari haqidagi ma'lumotlarni saqlaydigan; va bir qator saytlar kirish joylari tizimga foydalanuvchilar (www.google.com, www.yandex.ru, ru.yahoo.com va boshqalar). Bularning barchasi axborot tizimlarining klassik uch darajali arxitekturasiga mos keladi: bu erda qidirish algoritmlari va ma'lumotlar bazasi bilan ta'minlangan foydalanuvchi interfeysi, biznes-mantiq mavjud.
Internetda qidirish xususiyatlari
Bir qarashda, Internetda qidirish odatiy ma'lumotni qidirishdan, masalan, ma'lumotlar bazasiga ishlov berishdan yoki fayllarni qidirish vazifasidan farq qilmaydi. Shunday qilib, Internetdagi birinchi qidiruv tizimlarini ishlab chiquvchilar o'yladilar, ammo vaqt o'tishi bilan ular xato qilishganini tushunishdi ...
Internetdagi odatiy qidiruv o'rtasidagi birinchi farq shundan iboratki, bitta ma'lumotlar bazasidagi qidirish algoritmi uning tuzilishi qidiruv tizimi va so'rov muallifiga oldindan ma'lum bo'ladi. Internetda, aniq sabablarga ko'ra, bunday emas. Veb-sahifalar katalog tuzilishini yaratmaydi, balki qidiruv algoritmlariga ta'sir qiluvchi tarmoq ham mavjud va Internet-resurslarda joylashtirilgan ma'lumotlarning formati hech kim tomonidan boshqarilmaydi.
Ikkinchi farq, birinchisining oqibatlaridan biri sifatida, so'rov parametrlar to'plami (qidirish mezonlari) sifatida emas, balki odam tomonidan unga tabiiy bo'lgan tilda yozilgan matn sifatida taqdim etiladi. Shunday qilib, qidirishni boshlashdan oldin, siz hali ham so'rov muallifi nimani xohlayotganini aniq tushunishingiz kerak. E'tibor beraman, boshqa odamni emas, balki kompyuterni tushuning.
Uchinchi farq allaqachon ravshan, ammo ahamiyatsiz: katalog yoki ma'lumotlar bazasida barcha elementlar tengdir. Internetda raqobat mavjud va shuning uchun ko'proq "ishonchli ma'lumot etkazib beruvchilar" va "axborot axlati" maqomiga yaqin manbalarga bo'linish mavjud. Shunday qilib, odamlar resurslarni qanday tasniflashadi va qidirish mexanizmlari ularga ham tegishli.
Va nihoyat, shuni qo'shimcha qilish kerakki, qidiruv maydoni milliardlab sahifalar, har biri bir necha kilobayt yoki undan ko'p. Har kuni o'n millionga yaqin sahifalar qo'shiladi va shuncha ko'pi yangilanadi. Bularning barchasi turli xil raqamli formatlarda keltirilgan. Afsuski, hatto Internet-qidiruv xizmatlari bozori rahbarlari uchun mavjud bo'lgan zamonaviy texnologiyalar va manbalar ham ushbu xilma-xillikni to'liq va to'liq qayta ishlashga imkon bermaydi.
Izlash mexanizmi nimadan iborat
Avvalo, yana bir narsani va Internetda qidiruv tizimining ishlashi va turli xil katalog va ma'lumotlar bazalarida qidiruvni amalga oshiradigan boshqa har qanday axborot tizimining ishlashi o'rtasidagi farqni tushunish muhimdir. Internetda qidirish mexanizmi so'rov paytida Internetdagi narsalar orasida ma'lumot qidirmaydi, lekin o'z ma'lumot do'koni - indeks deb nomlangan ma'lumotlar bazasi asosida ma'lumot yaratishga harakat qiladi, u erda hamma ma'lumotlar ma'lum bo'lgan ma'lumotlarni saqlaydi va vaqti-vaqti bilan yangilab turadi. Boshqacha qilib aytganda, qidiruv tizimi asl nusxasi bilan emas, balki haqiqiy qidiruv qiymatlari mintaqasini proektsiyalash bilan ishlaydi. Internetdagi so'nggi barcha o'zgarishlar qidiruv natijalarida tegishli sahifalar mavjud bo'lgandan keyingina aks ettirilishi mumkin indekslangan - qidiruv indeksiga qo'shildi. Shunday qilib, birinchi taxminiy qidiruv tizimi qidiruv mexanizmi, ma'lumotlar bazasi yoki indeks (indeks) va tizimga kirish nuqtalaridan iborat.
Endi qidiruv tizimi nimadan iboratligi haqida qisqacha ma'lumot:
- O'rgimchak yoki o'rgimchak. Internet-resurslarning sahifalarini yuklab oladigan dastur. O'rgimchak hech qayerga “o'tirmaydi” - faqat Internetdagi oddiy brauzer singari, HTTP serveriga so'rov yuborib va \u200b\u200bundan javob olishni talab qiladi. Sahifaning tarkibi yuklab olingandan so'ng, u keyinchalik tavsiflangan indeksator va tarashchiga yuboriladi.
- Indeksator Indeksator yuklab olingan sahifaning tarkibiy qismlarini dastlabki tahlilini o'tkazadi, asosiy qismlarni (sahifa nomi, tavsifi, havolalar, sarlavhalar va hk) tanlaydi va ularni qidiruv ma'lumotlar bazasining bo'limlariga joylashtiradi - qidiruv indeksiga kiritadi. Ushbu jarayon deyiladi indekslash Internet manbalari, demak, quyi tizimning o'zi. Dastlabki tahlil natijalariga ko'ra, indeksator, shuningdek, sahifaning indeksda bo'lishiga "yaroqsiz" ekanligi to'g'risida qaror qabul qilishi mumkin. Ushbu qarorning sabablari boshqacha bo'lishi mumkin: sahifaning nomi yo'q, bu sahifa indeksidagi boshqasining aniq nusxasi yoki qonunda taqiqlangan manbalarga havolalar mavjud.
- Paxtakor Ushbu "hayvon" o'rgimchak yuklab olgan sahifadagi havolalardan foydalanib, "emaklash" uchun mo'ljallangan. O'tkazgich joriy sahifadan saytning boshqa qismlariga yoki tashqi Internet-resurslar sahifalariga olib boradigan yo'llarni tahlil qiladi va o'rgimchakning butun dunyo bo'ylab Internet tarmog'ini chetlab o'tish tartibini belgilaydi. Bu qidiruv tizimida yangi sahifalarni topib, ularni o'rgimchakka topshirishni o'rgimchidir. Crawler ishi kenglik va chuqurlikdagi grafiklarda qidirish algoritmlariga asoslanadi.
- Natijalarni qayta ishlash va etkazib berish quyi tizimi (Search Engine and Results Engine). Har qanday qidiruv tizimining eng muhim qismi. Ishlab chiquvchilar kompaniyaning ushbu quyi tizimining algoritmlarini qat'iy maxfiylikda saqlaydilar, chunki ular tijorat siridir. Aynan ushbu qidiruv tizimining foydalanuvchining so'roviga javobining etarliligi uchun javob beradigan qismi. Bu erda ikkita asosiy tarkibiy qismni ajratish mumkin:
- Quyi tizim reytingi. Saralash - bu Internet-saytlarning ma'lum bir so'rovga muvofiqligi bo'yicha sahifalar. Sahifaning dolzarbligi - bu, o'z navbatida, sahifadagi tarkib so'rovning ma'nosiga qanchalik mos keladi va qidiruv mexanizmi juda ko'p parametrlarga asoslanib, ushbu qiymatni o'zi belgilaydi. Saralash - bu qidiruv tizimidagi "sun'iy aql" ning eng sirli va munozarali qismidir. Tarkibi va tarkibi (tarkibi) bilan bir qatorda, sahifalar reytingiga quyidagilar ta'sir qiladi: boshqa saytlardan ushbu sahifaga olib boradigan havolalar soni va sifati; saytning o'zi domenining yoshi; sahifani ko'rayotgan foydalanuvchilarning xatti-harakati va boshqa ko'plab omillar.
- Natijalarni berish uchun quyi tizim. Ushbu kichik tizimning vazifalariga foydalanuvchi so'rovini sharhlash, uni indeksga tuzilgan so'rovlar tiliga tarjima qilish va qidiruv natijalari sahifalarini shakllantirish kiradi. So'rov matnini tahlil qilishdan tashqari, qidiruv mexanizmi quyidagilarni ko'rib chiqishi mumkin:
- Matn mazmunihosil bo'lgan ilgari qilingan foydalanuvchi so'rovlarining ma'nosiga asoslangan. Masalan, agar foydalanuvchi avtomobil mavzulari bo'yicha veb-saytlarga tez-tez tashrif buyuradigan bo'lsa, "Volga" yoki "Oka" so'zlari bilan so'rov qilish uchun, ehtimol u xuddi shu nomdagi ruslar qayerdan oqishi haqida emas, balki ushbu rusumdagi avtomobillar to'g'risida ma'lumot olishni xohlaydi. daryolari. Bu deyiladi shaxsiy qidiruvturli xil foydalanuvchilar uchun bir xil so'rovni yuborish juda farq qiladi.
- Foydalanuvchi sozlamalariu (qidiruv tizimi) "taxmin qilishi" mumkin, foydalanuvchi tanlab olinadigan havolalarni tahlil qilish qidiruv natijalari sahifalarida. Bu so'rov kontekstini o'zgartirishning yana bir usuli: foydalanuvchi o'z hatti-harakatlari bilan go'yo mashinaga aynan nimani topishni xohlayotganini aytadi. Qoida tariqasida, qidiruv tizimlari so'rovga mos keladigan, ammo hayotning mutlaqo boshqa sohalariga tegishli sahifalarni qidirish natijalariga qo'shishga harakat qilishadi. Aytaylik, foydalanuvchi kinoga qiziqadi va shuning uchun ko'pincha ushbu sahifalar asl so'rovga mutlaqo aloqasi bo'lmagan taqdirda ham film yangiliklari haqidagi sahifalarga havolalarni tanlaydi. Keyingi so'roviga javobni tuzishda tizim filmlar tavsifiga ega sahifalarni afzal ko'rishi mumkin, ularning nomi so'rov matnidan so'zlar mavjud.
- Viloyat, bu mahalliy etkazib beruvchilardan tovarlar va xizmatlarni sotib olish bilan bog'liq tijorat so'rovlarini ko'rib chiqishda juda muhimdir. Agar siz savdo-sotiq va chegirmalar bilan qiziqsangiz va Moskvada bo'lsangiz, unda siz so'rov matnida aniq ko'rsatmaguningizcha, ushbu mavzudagi aktsiyalar Sankt-Peterburgda qanday o'tkazilishi sizga umuman qiziqmaydi. Avvalo, Moskvadagi sotuvlar haqidagi ma'lumotlar qidiruv natijalarida paydo bo'lishi kerak. Shunday qilib, zamonaviy qidiruv tizimlari so'rovlarni quyidagilar bilan bo'lishadilar geoga bog'liq va geo-mustaqil. Ehtimol, agar qidirish tizimi sizning so'rovingiz geologik jihatdan bog'liq deb qaror qilsa, u avtomatik ravishda unga mintaqangizning belgisini qo'shib qo'yadi, bu sizning Internet-provayderingiz to'g'risidagi ma'lumot bilan aniqlashga harakat qiladi.
- Vaqt. Ba'zida sahifada tasvirlangan voqealar mavjud bo'lganda qidirish mexanizmlari tahlil qilishlari kerak. Axir, ma'lumotlar doimiy ravishda eskirmoqda va foydalanuvchiga birinchi navbatda hali tugallanmagan yoki kelajakda kelishi kerak bo'lgan so'nggi yangiliklar, hozirgi prognozlar va voqealar e'lonlariga havolalar kerak. Sahifaning dolzarbligi vaqtga bog'liqligini va uni so'rov bajarilgan vaqt bilan taqqoslashni qidirish mexanizmidan etarli darajada ma'lumot talab qiladi.
Qidiruv tizimining umumiy tamoyillari
Internetda qidirish xizmatlari juda foydali biznes ekanligini tushunishingiz kerak. Google va Yandex kabi kompaniyalar qaerda yashashi haqida tafsilotlarni bilib bo'lmaydi, chunki ularning asosiy qismi kontekstual reklama daromadidir. Va Internetda qidirish juda foydali bo'lganligi sababli, bunday kompaniyalar o'rtasidagi raqobat juda jiddiy. Internetda qidirish bozorining raqobatdoshligini nima aniqlaydi? Javob - qidiruv tizimining sifati. Mantiqan, bu qanchalik yuqori bo'lsa, tizimda yangi foydalanuvchilar paydo bo'ladi va ushbu savol sahifalarida joylashtirilgan kontekstual reklama shunchalik qimmatlidir. Qidiruv mexanizmlarini ishlab chiquvchilar o'zlarining qidiruv natijalarini barcha spam axborotlaridan, ya'ni spam deb ataladigan barcha axlatlardan "tozalash" uchun ko'p kuch sarflashadi. Bu qanday amalga oshirilganligi haqida batafsil ma'lumot alohida maqolada aytib o'tiladi va bu erda men yuqorida aytilganlarning barchasi bo'yicha xulosalar shaklida tuzilgan qidiruv tizimining umumiy ishlash tamoyillarini beraman.
- O'rgimchak va ayg'oqchilar oldida qidiruv tizimi Internetni doimiy ravishda yangi va yangilangan sahifalarni qidirmoqda, chunki ahamiyatsiz ma'lumotlar quyida qadrlanadi.
- Qidiruv mexanizmi vaqti-vaqti bilan resurslarning reytingini ularning asosiy so'rovlarga bog'liqligiga qarab yangilab turadi, chunki indeksda yangi sahifalar doimiy ravishda paydo bo'ladi. Ushbu jarayon qidirish natijalarini yangilash deb nomlanadi.
- Butunjahon Internet tarmog'iga joylashtirilgan ma'lumotlarning ko'pligi va qidiruv tizimining cheklangan manbalari tufayli, qidiruv tizimi har doim eng zarur bo'lgan (o'z fikriga ko'ra) yuklab olishga harakat qiladi. Uning arsenalida qidiruv natijalarini yangilash natijasida indekslash bosqichida keraksiz bo'lgan yoki indeksdan spamni chiqarib tashlaydigan turli xil filtrlar mavjud.
- So'rovni tahlil qilish jarayonida zamonaviy qidiruv tizimlari nafaqat so'rovning matnini, balki uning atrofini: avval aytib o'tilgan kontekst va foydalanuvchi imtiyozlarini, shuningdek so'rov vaqtini, mintaqani va boshqalarni ham hisobga olishga harakat qilishadi.
- Muayyan sahifaning dolzarbligi nafaqat uning ichki parametrlari (tuzilishi, tarkibi), balki tashqi parametrlar, masalan, boshqa saytlardagi sahifaga havolalar va uni ko'rishda foydalanuvchi harakati kabi ta'sir qiladi.
Qidiruv tizimlarining ishi doimiy ravishda takomillashtirilmoqda. Qidiruv mexanizmining ideal ishlashi (bir kishi uchun) faqat indeksatsiya va reytingga oid barcha qarorlar inson faoliyatining barcha sohalari va sohalarida ko'plab mutaxassislardan iborat komissiya tomonidan qabul qilingan taqdirdagina mumkin. Bu haqiqiy emasligi sababli, bunday komissiya ekspert tizimlari, evristik qidiruv algoritmlari va boshqa sun'iy intellekt elementlari bilan almashtiriladi. Ehtimol, agar Internetda ommaviy ravishda taqdim etiladigan barcha ma'lumotlarni qayta ishlash imkoni bo'lsa, ushbu quyi tizimlarning ishi yanada munosib natijalar berishi mumkin, ammo bu deyarli imkonsizdir. Nomukammal sun'iy intellekt va cheklangan manbalar - bu qidiruv natijalari natijalari har doim ham foydalanuvchilarni xushnud etmasligining ikkita asosiy sababi, ammo bularning barchasi vaqt o'tishi bilan davolanadi. Bugungi kunda, mening fikrimcha, eng taniqli va yirik qidiruv tizimlarining ishi foydalanuvchilarning ehtiyojlari va kutganlariga mos keladi.
Izlash mashinalari qanday ishlaydi? Internetning ajoyib xususiyatlaridan biri shundaki, yuzlab millionlab veb-resurslar bizni kutib olishga tayyor. Ammo yomon tomoni shundaki, o'sha millionlab sahifalar mavjud, ular bizga kerak bo'lsa ham, ular bizning oldimizda ko'rinmaydi, chunki bizga faqat noma'lum. Internetda nimani va qaerdan topish mumkinligini qanday aniqlash mumkin? Odatda buning uchun biz qidiruv tizimlarining yordamiga murojaat qilamiz.
Internetda qidirish motorlari bu global tarmoqdagi maxsus saytlar bo'lib, ular odamlar uchun Internet tarmog'ida kerakli ma'lumotlarni topishga yordam beradi. Qidiruv tizimlari o'z funktsiyalarini bajarishda farqlar mavjud, ammo umuman olganda uchta asosiy va bir xil funktsiyalar mavjud:
Ularning barchasi Internetni (yoki ba'zi Internet tarmog'ini) "qidirishadi" - berilgan kalit so'zlarga asoslanib;
- Barcha qidiruv tizimlari qidirayotgan so'zlarni va ularni topadigan joylarni indekslaydi;
- Barcha qidiruv tizimlari foydalanuvchilarga indekslangan va o'z ma'lumotlar bazalariga kiritilgan veb-sahifalar asosida so'zlar yoki kalit so'z birikmalarini qidirishga imkon beradi.
Eng birinchi qidiruv tizimlari bir necha yuz ming sahifalarni indeksatsiya qildi va kuniga 1000 - 2000 ta so'rovlarni qabul qildi. Bugungi kunda eng yaxshi qidiruv tizimlari yuzlab million sahifalarni doimiy ravishda indekslashdi va indekslashdi, kuniga o'nlab millionlab so'rovlarni qayta ishlaydilar. Quyida biz qidiruv tizimlari qanday ishlashi va ular bizni qiziqtirgan har qanday savolga javob bera oladigan tarzda barcha topilgan ma'lumotlarni qanday qilib "to'plashi" haqida suhbatlashamiz.
Internetga nazar tashlang
Odamlar Internetdagi qidiruv tizimlari haqida gapirganda, ular haqiqatan ham qidiruv tizimlarini anglatadi Dunyo bo'ylab Internet. Internet Internetning eng ko'zga ko'rinadigan qismiga aylanishidan oldin, odamlarga Internetda ma'lumot topishga yordam beradigan qidiruv tizimlari mavjud edi. "Gopher" va "Archie" deb nomlangan dasturlar Internet Internetga ulangan turli xil serverlarda joylashgan fayllarni indekslashni amalga oshirdi va kerakli dastur yoki hujjatlarni topishga sarflangan vaqtni bir necha bor kamaytirdi. O'tgan asrning 80-yillari oxirida "Internet qobiliyatlari" sinonimi gopher, Archie, Veronika va boshqalardan foydalanish qobiliyati edi. qidirish dasturlari. Bugungi kunda ko'pgina Internet foydalanuvchilari o'zlarining qidiruvlarini butunjahon Internet yoki WWW-da cheklashadi.
Kichik boshlang'ich
Kerakli hujjat yoki faylni qaerdan topish kerakligi haqida javob berishdan oldin, ushbu fayl yoki hujjat allaqachon topilgan bo'lishi kerak. Yuz millionlab mavjud veb-sahifalar haqida ma'lumot topish uchun qidiruv tizimi maxsus robot dasturidan foydalanadi. Ushbu dastur shuningdek o'rgimchak ("o'rgimchak", o'rgimchak) deb nomlanadi va sahifada topilgan so'zlar ro'yxatini tuzishga xizmat qiladi. Bunday ro'yxatni tuzish jarayoni deyiladi veb-qidiruv (Veb-qidiruv). Keyinchalik "foydali" (mazmunli) so'zlar ro'yxatini tuzish va yozib olish uchun qidiruv o'rgimchak bir necha boshqa sahifalarni "ko'rib chiqishi" kerak.
Kim qanday boshlaydi o'rgimchak (o'rgimchak) to'r bo'ylab sayohat qilyapsizmi? Odatda boshlang'ich nuqtasi dunyodagi eng katta serverlar va juda mashhur veb-sahifalardir. O'rgimchak o'z sayohatini shunday saytdan boshlaydi, topilgan so'zlarning barchasini indekslaydi va boshqa saytlarga bog'langan holda keyingi harakatini davom ettiradi. Shunday qilib, o'rgimchak roboti veb-makonning barcha katta "qismlarini" qamrab olishga kirishadi. Google.com akademik qidiruv tizimidan boshlandi. Ushbu qidiruv mexanizmi qanday yaratilganligi haqida maqolada Sergey Brin va Laurens Peyj (Google asoschilari va egalari) Google o'rgimchaklari qanchalik tez ishlashi to'g'risida misol keltirdilar. Ulardan bir nechtasi bor va odatda 3 o'rgimchak yordamida qidirish boshlanadi. Har bir o'rgimchak veb-sahifalarga bir vaqtning o'zida 300 tagacha ochiq ulanishlarni qo'llab-quvvatlaydi. Eng yuqori yuklamada, 4 ta o'rgimchidan foydalangan holda, Google tizimi sekundiga 100 sahifani qayta ishlashga qodir, bu esa taxminan 600 kilobayt / sekund trafikni hosil qiladi.
O'rgimchaklarni qayta ishlash uchun zarur bo'lgan ma'lumotlar bilan ta'minlash uchun Google oldin o'rgimchaklarga ko'proq va ko'proq URL-larni tashlash bilan shug'ullanadigan serverga ega edi. URL-manzilni IP-manzilga o'tkazadigan domen nomi serverlari (DNS) uchun Internet-provayderlarga bog'liq bo'lmaslik uchun, Google sahifani indekslashga sarf qilingan barcha vaqtni minimallashtirib, o'zining DNS-serverini sotib oldi.
Googlebot HTML-sahifaga kirganda, ikkita narsani hisobga oladi:
Sahifadagi so'zlar (matn);
- ularning joylashuvi (sahifa tanasining qaysi qismida).
Xizmat bo'limlarida joylashgan so'zlar sarlavha, subtitrlar, meta-teglar va boshqalar alohida qidiruv so'rovlari uchun ayniqsa muhim deb belgilandi. Google O'rgimchak sahifadagi har bir o'xshash so'zni indekslash uchun tuzilgan, "a", "a" va "." Kabi so'zlar bundan mustasno. Boshqa qidirish mexanizmlarida indekslashga biroz boshqacha yondashuv mavjud.
Qidiruv tizimlarining barcha yondoshuvlari va algoritmlari oxir-oqibat o'rgimchak robotlarining ishlashini tez va samaraliroq qilishga qaratilgan. Masalan, ba'zi qidiruv robotlari sarlavha, havolalar va sahifadagi eng ko'p ishlatiladigan 100 tagacha so'zlarni va hatto sahifadagi matn tarkibidagi dastlabki 20 qatordagi so'zlarni indekslashda kuzatadilar. Bu indekslash algoritmi, xususan Lycos bilan.
AltaVista kabi boshqa qidiruv tizimlari sahifaning har bir so'zini, shu jumladan "a", "an", "" "va boshqa ahamiyatsiz so'zlarni indeksatsiyalashda boshqa yo'nalishda harakat qilishadi.
Meta Teglar
Meta teglar veb-sahifa egasiga tarkibining mohiyatini belgilaydigan kalit so'zlar va tushunchalarni belgilashga imkon beradi. Bu juda foydali vositadir, ayniqsa ushbu kalit so'zlarni sahifa matnida 2-3 martagacha takrorlash mumkin bo'lgan hollarda. Bunday holda, meta-teglar qidiruv robotini sahifani indekslash uchun kerakli kalit so'zlarni tanlashga "yo'naltirishi" mumkin. Eski sahifaning o'zi bilan hech qanday aloqasi bo'lmagan mashhur qidiruv so'rovlari va tushunchalarga meta teglarini "o'rash" ehtimoli mavjud. Qidiruv robotlari, masalan, meta-teglar va veb-sahifalar tarkibining o'zaro bog'liqligini tahlil qilib, sahifalar tarkibiga mos kelmaydigan meta-teglarni (tegishli ravishda kalit so'zlarni) «chiqarib yuborish» orqali hal qilishlari mumkin.
Bularning barchasi veb-resurs egasi haqiqatan ham kerakli qidiruv so'zlarini qidirish natijalariga kiritishni istagan holatlarga taalluqlidir. Ammo ko'pincha egasi umuman indekslangan robot bo'lishni xohlamasligi ko'pincha sodir bo'ladi. Ammo bunday holatlar bizning maqolamiz mavzusi bilan bog'liq emas.
Indekslarni qurish
O'rgimchaklar yangi veb-sahifalarni qidirish bo'yicha ishlarni tugatishi bilan, qidiruv tizimlari topilgan barcha ma'lumotlarni keyinchalik foydalanish uchun qulay bo'lishi uchun joylashtirishlari kerak. Bu erda ikkita asosiy komponent muhim:
Ma'lumotlar saqlanadigan ma'lumotlar;
- Ushbu ma'lumotni indekslash usuli.
Eng oddiy holatda, qidiruv tizimi shunchaki so'zni va URL manzilini u joylashgan joyga joylashtirishi mumkin edi. Ammo bu qidiruv tizimini juda sodda vositaga aylantiradi, chunki ushbu so'z hujjatning qaysi qismida (meta-teglar yoki oddiy matnda) joylashganligi, ushbu so'z bir marta yoki bir necha bor ishlatilganligi va u ushbu havolada mavjudligi to'g'risida ma'lumot yo'q. yana bir muhim va tegishli mavzu. Boshqacha qilib aytganda, ushbu usul saytlarni saralashga yo'l qo'ymaydi, foydalanuvchilarga tegishli natijalarni bermaydi va hokazo.
Bizni foydali ma'lumotlar bilan ta'minlash uchun, qidirish mexanizmlari nafaqat so'z va uning URL manzilini ma'lumotlarini saqlaydi. Qidiruv mexanizmi sahifadagi so'z havolalarining soni (chastotasi) bo'yicha ma'lumotlarni saqlashi, uni "og'irlik" so'ziga qo'shishi mumkin, bu esa joylashuvini hisobga olgan holda (berilgan havolalarda, meta-teglar, sahifa sarlavhalari) berilgan so'z uchun vazn reytingi asosida qidiruv ro'yxatlarini (natijalarini) chiqarishga yordam beradi. va h.k.). Har bir tijorat qidiruv tizimida indeksatsiya paytida kalit so'zlarning "og'irligi" ni hisoblash uchun o'z formulasi mavjud. Bu qidiruv tizimlari bir xil qidirish so'rovi uchun mutlaqo boshqa natijalarni qaytarishining sabablaridan biridir.
Topilgan ma'lumotni qayta ishlashning navbatdagi muhim jihati - uni saqlash uchun diskdagi bo'sh joyni kamaytirish uchun uni kodlash. Masalan, Google-ning asl maqolasida so'zlarning vaznli ma'lumotlarini saqlash uchun 2 bayt (har biri 8 bit) ishlatilganligi tasvirlangan - bu so'z turini (katta yoki kichik harflarda), harflarning kattaligini (Shrift o'lchami) va boshqa ma'lumotlarni hisobga oladi. bu saytni saralashga yordam beradi. Har bir bunday "ma'lumot" to'liq 2 baytlik to'plamda 2-3 bit ma'lumotni talab qiladi. Natijada juda katta miqdordagi ma'lumot juda ixcham shaklda saqlanishi mumkin. Ma'lumotlar "siqilgan" bo'lgandan so'ng, indekslashni boshlash vaqti keldi.
Indekslashning maqsadi bitta: kerakli ma'lumotlarni tezkor qidirish. Indekslarni tuzishning bir necha yo'li mavjud, ammo eng samarali bu qurilishdir hash jadvallari (hash jadvali). Xeshlashda ma'lum bir formuladan foydalaniladi, ularning yordami bilan har bir so'zga ma'lum miqdordagi qiymat beriladi.
Har qanday tilda, alfavitning qolgan harflariga qaraganda ko'proq so'zlarni boshlaydigan harflar mavjud. Masalan, inglizcha lug'at qismidagi "M" harflaridagi so'zlar "X" harfiga qaraganda ko'proq. Bu shuni anglatadiki, eng mashhur harf bilan boshlanadigan so'zni topish boshqa so'zlarga qaraganda ko'proq vaqt talab etadi. Hashing (Hashing) bu farqni tenglashtiradi va o'rtacha qidirish vaqtini qisqartiradi, shuningdek indeksni haqiqiy ma'lumotlardan ajratib turadi. Xesh jadvalda ushbu qiymatga mos keladigan ma'lumotlarga ishora bilan birga hash qiymatlari mavjud. Samarali indeksatsiya + samarali joylashtirish birgalikda foydalanuvchi juda murakkab qidiruv so'rovini so'rasa ham yuqori qidiruv tezligini ta'minlaydi.
Qidiruv tizimlarining kelajagi
Boolean operatorlariga asoslangan qidirish ("va", "yoki", "emas") so'zma-so'z qidiruvdir - qidiruv mexanizmi qidiruv so'zlarini ular kiritilganidek qabul qiladi. Masalan, kiritilgan so'z juda ko'p ma'noga ega bo'lsa, bu muammoga olib kelishi mumkin. Masalan, "kalit", "eshikni ochish vositasi" yoki serverga kirish uchun "parol" ni anglatishi mumkin. Agar siz so'zning faqat bitta ma'nosi bilan qiziqsangiz, unda sizga uning ikkinchi ma'nosi to'g'risida ma'lumot kerak bo'lmaydi. Siz, shubhasiz, keraksiz so'z qiymati bilan ma'lumotlarning chiqishini istisno qilishga imkon beradigan so'zma-so'z so'rovni yaratishingiz mumkin, ammo qidiruv tizimi sizga yordam berishi mumkin bo'lsa yaxshi bo'lar edi.
Kelajakdagi qidiruv tizimlarining algoritmlari sohasidagi tadqiqot yo'nalishlaridan biri ma'lumotni kontseptual izlashdir. Bular shunday algoritmlar bo'lib, unda kerakli ma'lumotlarni qidirish uchun qidiruv kaliti yoki iborani o'z ichiga olgan sahifalarni statistik tahlil qilish qo'llaniladi. Bunday "kontseptual qidirish mexanizmi" har bir sahifa haqidagi ma'lumotlarni saqlash uchun ko'proq joy talab qilishi va har bir so'rovni ko'rib chiqish uchun ko'proq vaqt talab qilishi aniq. Hozirda ko'plab tadqiqotchilar ushbu masala ustida ishlamoqdalar.
Qidiruvga asoslangan qidirish algoritmlarini ishlab chiqish sohasida ham jadal ish olib borilmayapti tabiiy til (Tabiiy tillarga oid so'rov).
Tabiiy so'rovlarning g'oyasi shundaki, siz o'zingizning yoningizda o'tirgan hamkasbingizdan so'ragandek so'rov yozishingiz mumkin. Boolean operatorlari haqida tashvishlanmaslik yoki murakkab so'rovni bajarish uchun zo'rlash kerak emas. Tabiiy so'rovlar tiliga asoslangan eng mashhur qidiruv tizimi bugungi kunda AskJeeves.com. U so'rovni saytlarni indekslashda foydalanadigan kalit so'zlarga aylantiradi. Ushbu yondashuv faqat oddiy so'rovlar bilan ishlaydi. Ammo, taraqqiyot hali ham to'xtamayapti, yaqin orada biz qidiruv tizimlari bilan o'zimizning "inson tilida" gaplashamiz.