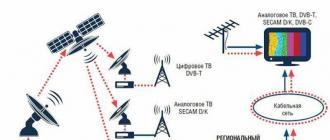
If you need to develop complex statistical or engineering analyzes, you can save steps and time with an analysis package. You provide data and parameters for each analysis, and the tool uses the appropriate statistical or engineering functions to calculate and display the results in an output table. Some tools create charts in addition to the output tables.
Data analysis functions can only be applied on one sheet. If the data analysis is carried out in a group consisting of several sheets, then the results will be displayed on the first sheet, on the remaining sheets empty ranges containing only formats will be displayed. To analyze the data on all sheets, repeat the procedure for each sheet separately.
The tools included in the analysis package are described below. To access them press the button Data analysis in a group Analysis in the tab Data... If the command Data analysis is not available, you must download the Analysis Pack add-in.
Note: To enable the Visual Basic for Applications (VBA) functionality for an analysis pack, you can load the Analysis Pack - VBA add-in in the same way as when you download the Analysis Pack. In the dialog box Available add-ins check the box Analysis Package - VBA .
Analysis of variance
There are several types of analysis of variance. The required option is selected taking into account the number of factors and available samples from the general population.
One-way analysis of variance
This tool performs simple variance analysis on data from two or more samples. Analysis is a test of the hypothesis that each sample is derived from the same underlying probability distribution as for an alternative hypothesis for which the underlying probability distributions are not the same. If there are only two examples, you can use the function on the sheet T. Check... In more than two samples, there is no convenient generalization with T. And the one-way dispersion model can be called checks.
Two-way analysis of variance with repetitions
This analysis tool is useful when the data can be classified according to two dimensions. For example, in an experiment to measure the height of plants, the latter were treated with fertilizers from different manufacturers (eg A, B, C) and kept at different temperatures (eg low and high). Thus, for each of the 6 possible pairs of conditions (fertilization, temperature), there is the same set of observations of plant growth. Using this analysis of variance, you can test the following hypotheses:
Are plant growth data extracted for different brands of fertilizers from the same population. Temperature is not included in this analysis.
Are plant growth data extracted for different temperature levels from the same population. Fertilizer grade is not included in this analysis.
Are six samples, representing all pairs of values \u200b\u200b(fertilizer, temperature) used to assess the effects of different brands of fertilizers (for the first item in the list) and temperature levels (for the second item in the list), from the same population? An alternative hypothesis assumes that the effect of specific pairs (fertilizer, temperature) exceeds the effect of separate fertilization and temperature separately.

Two-way analysis of variance without repetitions
This analysis tool is useful if the data can be classified according to two dimensions, as in the case of two-way ANOVA. However, this analysis assumes that there is only one dimension for each pair of parameters (for example, for each pair of parameters (fertilizer, temperature) from the previous example).
Correlation
On the sheet CORREL and Pearson a correlation coefficient is calculated between two measurement variables if measurements for each variable are displayed for each of the N subjects. (Failure to observe for any of the topics causes the topic to be skipped in the analysis.) The correlation analyzer is especially useful when more than two dimension variables are used for N topics. It provides an output table, a correlation matrix that shows the value CORREL (or Pearson) applied to each possible pair of measurement variables.
A correlation coefficient, such as Covariance, is a measure of the extent at which two dimension variables are simultaneously distinguished. Unlike covariance, the correlation coefficient is scaled so that its value is independent of the units in which the two measurement variables are expressed. (For example, if the two measurement variables are weight and height, the value of the correlation coefficient does not change if weight is converted from kilograms to kilograms.) The value of any correlation coefficient must be in the range from -1 to +1 inclusive.
Correlation analysis makes it possible to establish whether datasets are associated in magnitude, i.e. large values \u200b\u200bfrom one dataset are associated with large values \u200b\u200bof another set (positive correlation), or vice versa, small values \u200b\u200bof one set are associated with large values \u200b\u200bof another (negative correlation), or the data of the two ranges are not related in any way (zero correlation).
Covariance
You can use the correlation and covariance tools on the same parameter if you have N different measurement variables spent on a set of individual users. Correlation and covariance tools provide an output table, a matrix that shows the correlation coefficient or covariance, respectively, between each pair of measurement variables. The difference is that the correlation coefficients are scaled with -1 and +1 inclusive. The corresponding covariances are not scaled. Both the correlation coefficient and the covariance are the magnitudes of the extents in which two variables are different from each other.
The Covariance tool calculates the value of a function Covariation on the sheet. Pfor each pair of measurement variables. (Direct use of covariance. The P function instead of the Covariance tool is a reasonable alternative if there are only two measurement variables, ie N \u003d 2.) The diagonal entry in the output table of the covariance tool in row i is the Covariance of the i-th dimension variable. This is just the population variance for this variable, calculated by the function on the sheet var. P.
Covariance analysis makes it possible to determine whether datasets are associated in magnitude, that is, large values \u200b\u200bfrom one dataset are associated with large values \u200b\u200bof another set (positive covariance), or vice versa, small values \u200b\u200bof one set are associated with large values \u200b\u200bof another (negative covariance), or data the two ranges are not related in any way (covariance is close to zero).
Descriptive statistics
The Descriptive Statistics analysis tool is used to generate a one-dimensional statistical report that contains information about the central trend and variability of the input data.
Exponential smoothing
The Exponential Smoothing analysis tool is used to predict a value based on a forecast for a previous period, adjusted for the errors in that forecast. The analysis uses the smoothing constant a, the value of which determines the degree of influence on forecasts of errors in the previous forecast.
Note: For the smoothing constant, values \u200b\u200bbetween 0.2 and 0.3 are most suitable. These values \u200b\u200bindicate that the error in the current forecast is set at 20 to 30 percent of the error in the previous forecast. Higher values \u200b\u200bof the constant speed up the response, but can lead to unpredictable outliers. Low values \u200b\u200bof the constant can lead to large gaps between the predicted values.
Two-sample t-test for variance
The two-sample F-test is used to compare the variances of two populations.
For example, you can use an F-test on samples of swim results for each of the two teams. This tool provides the results of comparing the null hypothesis that the two samples are from a distribution with equal variances, with the hypothesis assuming that the variances are different in the underlying distribution.
This tool calculates the f value of the F statistic (or F factor). An f value close to 1 indicates that the variances of the population are equal. In the results table, if f< 1, "P(F <= f) одностороннее" дает возможность наблюдения значения F-статистики меньшего f при равных дисперсиях генеральной совокупности и F критическом одностороннем выдает критическое значение меньше 1 для выбранного уровня значимости "Альфа". Если f > 1, "P (F<= f) одностороннее" дает возможность наблюдения значения F-статистики большего f при равных дисперсиях генеральной совокупности и F критическом одностороннем дает критическое значение больше 1 для "Альфа".
Fourier analysis
The Fourier Analysis tool is used to solve problems in linear systems and analyze periodic data based on the fast Fourier transform (FFT) method. This tool also supports inverse transformations, whereby inverting the transformed data returns the original data.

bar graph
The Histogram tool is used to calculate the sampled and integral frequencies of data falling into specified ranges of values. This calculates the number of hits for a given range of cells.
For example, you can get the distribution of performance on a grade scale in a group of 20 students. The histogram table is composed of grading scale boundaries and student groups whose performance is between the lowest grade and the current grade. The most common level is the data range mode.
Moving average
The Moving Average analysis tool is used to calculate values \u200b\u200bin a forecast period based on the average of a variable for a specified number of prior periods. A moving average, as opposed to a simple average for the entire sample, contains information about trends in data. This method can be used to forecast sales, stocks, and other trends. Predicted values \u200b\u200bare calculated using the following formula:
![]()
N - the number of previous periods included in the moving average;
A j - the actual value at the time j;
F j - predicted value at time j.
Generating random numbers
The Random Number Generator tool is used to fill a range with random numbers drawn from one or more distributions. Using this procedure, it is possible to simulate objects of a random nature using a known probability distribution. For example, you can use the normal distribution to model a population of data on the height of people, or use the Bernoulli distribution for two probabilities to describe the population of coin tossing results.
Rank and percentile
The Rank and Percentile tool generates a table containing the ordinal and percentage ranks for each value in the dataset. You can analyze relative values \u200b\u200bin a dataset. This tool uses the functions ranking on the sheet. EQand PERCENTRANK. INC... If you want to account for the bound values \u200b\u200buse rank. EQ which processes bound values \u200b\u200baccording to the same rank or uses rank.Function AVG that returns the average rank of the bound values.
Regression
The Regression analysis tool is used to fit a graph for a set of observations using the least squares method. Regression is used to analyze the effects on an individual dependent variable of the values \u200b\u200bof one or more explanatory variables. For example, several factors affect the athletic performance of an athlete, including age, height, and weight. You can calculate the impact of each of these three factors on the performance of an athlete, and then use the data to predict the performance of another athlete.
The regression tool uses a worksheet function LINEST.
The Sample analysis tool creates a sample from a population by treating the input range as a population. If the population is too large to process or chart, you can use a representative sample. In addition, if the periodicity of the input data is assumed, then you can create a selection containing values \u200b\u200bonly from a separate part of the cycle. For example, if the input range contains data for quarterly sales, sampling with period 4 will place sales values \u200b\u200bfrom the same quarter in the output range.
The two-sample t-test tests the equality of the population means for each sample. The three types of this test admit the following conditions: equal variances of the general distribution, variances of the general population are not equal, and the presentation of two samples before and after observation for the same subject.
For all three tools listed below, the t-value is calculated and displayed as a "t-statistic" in the output table. Depending on the data, this t value can be negative or non-negative. If we assume that the average of the general population are equal, at t< 0 "P(T <= t) одностороннее" дает вероятность того, что наблюдаемое значение t-статистики будет более отрицательным, чем t. При t >\u003d 0 "P (T<= t) одностороннее" делает возможным наблюдение значения t-статистики, которое будет более положительным, чем t. "t критическое одностороннее" дает пороговое значение, так что вероятность наблюдения значения t-статистики большего или равного "t критическое одностороннее" равно "Альфа".
"P (T<= t) двустороннее" дает вероятность наблюдения значения t-статистики, по абсолютному значению большего, чем t. "P критическое двустороннее" выдает пороговое значение, так что значение вероятности наблюдения значения t- статистики, по абсолютному значению большего, чем "P критическое двустороннее", равно "Альфа".
Paired two-sample t-test for means
The paired test is used when there is a natural pairing of observations in the samples, for example, when the general population is tested twice - before and after the experiment. This analysis tool is used to test the hypothesis about the difference between the means for two data samples. It does not assume that the variances of the populations from which the data are selected are equal.
Note: One test result is cumulative variance (the cumulative measure of the distribution of data around the mean), calculated using the following formula:
![]()
Two-sample t-test with equal variances
This analyzer performs a two-sample t-test on the student. In this form of t-test, it is assumed that two datasets come from a distribution with the same variances. It is called the homoscedastic t-test. You can use this t-test to determine if two examples can be obtained from distributions with the same filling.
Two-sample t-test with different variances
This analyzer performs a two-sample t-test on the student. This form of t-test assumes that the two datasets come from a distribution with unequal variances. It is called the heteroscedastic t-test. As in the previous case with the same variances, you can use this t-test to determine if two examples should come from a distribution with the same filling. Use this test if the two examples have separate topics. Use the paired test described in the example below when there is one set of topics and the two samples have measurements for each topic before and after processing.
To determine the test value t the following formula is used.

The following formula is used to calculate the degrees of freedom, DF. Since the result of the calculation is usually not an integer, the df value is rounded to the nearest integer to get the critical value from the t-table. Excel worksheet function - T. Test uses the calculated DF value without rounding, since it is possible to calculate the value for T. Check with non-integer DF. Due to different approaches to determining the degrees of freedom, the results in T. Testing and this t-test means will differ in the case of unequal variation.

A two-sample z-test for means is a two-sample z-test for means and known variances. This tool is used to hypothesize that there is a difference between the two padding units in two or two-sided variants. If the variability is unknown, then the sheet function Z. You should use instead check .
When using this tool, you should carefully review the result. "P (Z<= z) одностороннее" на самом деле есть P(Z >\u003d ABS (z)), the probability of a z-score distant from 0 in the same direction as the observed z-score given the same population mean. "P (Z<= z) двустороннее" на самом деле есть P(Z >\u003d ABS (z) or Z<= -ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. Двусторонний результат является односторонним результатом, умноженным на 2. Инструмент "z-тест" можно также применять для гипотезы об определенном ненулевом значении разницы между двумя средними генеральных совокупностей. Например, этот тест можно использовать для определения разницы выступлений на соревнованиях двух автомобилей разных марок.
Note: This page has been automatically translated and may contain inaccuracies and grammatical errors. It is important for us that this article is useful to you. Was the information helpful? For convenience also (in English).
Microsoft Excel is one of the most indispensable software products. Excel has such broad functionality that, without exaggeration, it can be used in absolutely any area. With the skills in this program, you can easily solve a very wide range of problems. Microsoft Excel is often used for engineering or statistical analysis. The program provides the ability to set a special setting, which will significantly help to facilitate the task and save time. In this article, we'll talk about how to enable data analysis in Excel, what it includes, and how to use it. Let's get started. Go!
To get started, you need to activate an additional analysis package
The first thing to start with is to install the add-on. Let's consider the whole process using the example of Microsoft Excel 2010. This is done as follows. Go to the File tab and click Options, then select the Add-Ins section. Next, find "Excel Add-ins" and click on the "Go" button. In the window of available add-ons that opens, select the "Analysis package" item and confirm your choice by clicking "OK". If the required item is not in the list, you will have to find it manually using the "Browse" button.

Since the Visual Basic functions may still be useful to you, it is advisable to also install the "VBA Analysis Pack". This is done in the same way, the only difference is that you have to select another add-in from the list. If you know for sure that you don't need Visual Basic, then you don't need to download anything else.

The installation process for the Excel 2013 version is exactly the same. For the 2007 version of the program, the only difference is that instead of the "File" menu, you must click the Microsoft Office button, then follow the steps as described for Excel 2010. Also, before starting the download, make sure that the latest version of NET is installed on your computer. Framework.
Now let's look at the structure of the installed package. It includes several tools that you can apply depending on your tasks. The list below shows the main analysis tools included in the package:

As you can see, using the data analysis add-in in Microsoft Excel gives you much wider possibilities of working in the program, making it easier for the user to perform a number of tasks. Write in the comments if the article was useful for you and if you have any questions, be sure to ask them.
Excel is not just a spreadsheet editor, but also a powerful tool for various mathematical and statistical calculations. The application has a huge number of functions designed for these tasks. True, not all of these features are activated by default. These are the hidden functions of the toolbox. "Data analysis"... Let's find out how you can enable it.
To take advantage of the opportunities provided by the function "Data analysis", you need to activate the tool group "Analysis package"by following certain steps in Microsoft Excel settings. The algorithm for these actions is almost the same for the 2010, 2013 and 2016 versions of the program, and has only minor differences from the 2007 version.
Activation
- Go to the tab "File"... If you are using Microsoft Excel 2007, instead of the button "File" click the icon Microsoft Office in the upper left corner of the window.
- Click on one of the items presented on the left side of the window that opens - "Parameters".
- In the Excel settings window that opens, go to the subsection "Add-ons" (penultimate in the list on the left side of the screen).
- In this subsection, we will be interested in the lower part of the window. There is a parameter "Control"... If the drop-down form related to it contains a value other than Excel Add-ins, then you need to change it to the specified one. If this particular item is set, then simply click on the button "Go ..." to the right of him.
- A small window of available add-ins opens. Among them you need to select the item "Analysis package" and put a tick next to it. After that, click on the button "OK"located at the very top of the right side of the window.





After completing these steps, the specified function will be activated, and its tools are available on the Excel ribbon.
Launching the functions of the "Data Analysis" group
Now we can launch any of the group tools "Data analysis".


Work in each function has its own algorithm of actions. Using some group tools "Data analysis" described in separate lessons.
As you can see, although the toolbox "Analysis package" and is not activated by default, the process of enabling it is quite simple. At the same time, without knowing a clear algorithm of actions, the user is unlikely to be able to quickly activate this very useful statistical function.
If you need to develop complex statistical or engineering analyzes, you can save steps and time with an analysis package. You provide data and parameters for each analysis, and the tool uses the appropriate statistical or engineering functions to calculate and display the results in an output table. Some tools create charts in addition to the output tables.
Data analysis functions can only be applied on one sheet. If the data analysis is carried out in a group consisting of several sheets, then the results will be displayed on the first sheet, on the remaining sheets empty ranges containing only formats will be displayed. To analyze the data on all sheets, repeat the procedure for each sheet separately.
Note: To enable a Visual Basic for Applications (VBA) feature for an analysis package, you can download the add-in " Analysis Package - VBA "in the same way as when loading an analysis package. Available add-ins check the box Analysis Package - VBA .
To download an analysis package in Excel for Mac, follow these steps:
If the add-in Analysis package not in the field list Available add-ons, press the button Overviewto find her.
If a message appears stating that the analysis package is not installed on your computer, click Yes to install it.
Exit Excel and restart it.
Now in the tab Data command available Data analysis.
On the menu Service select add-ons Excel.
In the window Available add-ons check the box Analysis packageand then click OK.
I cannot find an analysis package in Excel for Mac 2011
There are several third-party add-ins that provide Analysis Pack functionality for Excel 2011.
Option 1. Download the statistical software KSLSTAT for Mac and use it in Excel 2011. KSLSTAT contains over 200 basic and advanced statistical tools that include all the features of the analysis suite.
Select the version of KSLSTAT that matches your Mac OS and download it.
Open the Excel file that contains the data and click the XLSTAT icon to open the XLSTAT toolbar.
Within 30 days you will have access to all KSLSTAT functions. After 30 days, you can use the free version, which includes the functions of the analysis package, or order one of the more complete KSLSTAT solutions.
Option 2. Download Statplus: Mac LE for free from Analystsoft and then use Statplus: Mac LE with Excel 2011.
You can use Statplus: Mac LE to perform many of the functions that were previously available in analysis packages, such as regression, histograms, variance analysis (Two-way ANOVA), and t-tests.
Go to the analystsoft website and follow the instructions on the download page.
After downloading and installing Statplus: Mac LE, open the workbook containing the data you want to analyze.
TASK number 1
Statistical data analysis in MS Excel
Purpose of work: to learn how to process statistical data using built-in MS Excel functions; explore the capabilities of the Analysis Package and its tools: “ Generating random numbers ", "Bar graph" , " Descriptive statistics "on the example of processing measurements of the speed of movement.
In accordance with the guidelines for the laboratory work "Measuring the speed of vehicles" (in the discipline "Search and design of highways"), process the experimental measurement data by methods of mathematical statistics in Excel. For what:
1. Calculate statistical characteristics using the built-in functions: - the minimum value of the movement speed Vmin;
Maximum value of movement speed Vmax; - the average value of the speed of movement Vav;
Standard deviation S;
Standard deviation of the mean Sav;
Student's coefficient (to determine the confidence interval) t; - confidence interval for P \u003d 0.95.
2. Get statistical characteristics using the tool "Descriptive statistics"From the additional package" Data Analysis ".
3. Construct a histogram of the movement speed distribution.
4. Build a cumulative curve (cumulative frequency curve).
5. Construct a theoretical curve of the distribution of the speed of movement.
To obtain a sufficient amount of initial data (speed measurement results), use a simulation experiment using the tool " Generating random numbers"Data Analysis" add-on.
When performing p. 3 and 4 to select the interval of speeds ("pocket" - in Excel terminology), allowing to obtain the most symmetric histogram showing the normal distribution law.
An example of execution is given in the attached file BasicsPK1-Student.xls.
Methodical instructions
Suppose that we have performed a series of 10 experiments, measuring a certain value of X. Table 1. Approximate view of the "Processing experiment" sheet
The entries in columns D and E are hints that will help you figure out what characteristics we will calculate. Column F should be empty for now, our formulas will be placed in it.
We start processing the results by calculating the number of experiments n.
A special function called COUNT is used to determine the number of values. To enter a formula with functions, use the Function Wizard, which is launched by the "Insert Function" command through the "Insert" - "Function" menu or by the button on the toolbar with the designation f x.
Let's click on cell F6, where the result should be located and launch the Function Wizard.

The first step of work (Figure 1) serves to select the desired function.
Statistical functions are used to process experimental data. Therefore, first of all, in the list of categories, select the "Statistical" category. A list of statistical functions appears in the second window.
The list of functions is sorted alphabetically, which makes it easy to find the COUNT function we need ("Counts the number of numbers in the list of arguments").
Having selected this function by clicking, press the Ok button and go to step 2.
The second step (Figure 2) is used to set the function arguments.
The COUNT function needs to indicate which numbers it needs to recalculate, or in which cells these numbers are located. The next two stages of processing a series of experiments are carried out in a similar way.
In cell F7, using the AVERAGE function, the average value of the sample is calculated, in cell F8, the standard deviation of the sample, using the STDEV function. ...
The arguments of these functions are all the same range of cells.
To calculate the confidence interval, it is necessary to determine the Student's coefficient. It depends on the probability of error (with a generally set reliability of 95%, the probability of error is 5%), and on the number of degrees of freedom n-1).
To find the Student's coefficient, the Excel statistical function STYUDRASPONV is used (“Student's distribution is inverse”). A feature of this function is that the first argument, the number 5% (or 0.05), is entered into the corresponding window from the keyboard. For the second, specify the address of the cell where the value of n is, then add “-1” in the window. We get the record “F6-1”.
The usual multiplication formula is used to find the confidence interval. Of course, instead of letters, there should be the addresses of the cells where the Student's coefficient and the standard deviation of the mean are located. As a rule, the value of the confidence interval is rounded to one significant digit, the same order of the environment should be in the mean. Therefore, the final result can be written as follows: with 95% reliability X \u003d 14.80 ± 0.05. In conclusion, let's calculate the relative error in determining X: \u003d CI / X cf (formula: “\u003d F11 / F7”). The value of the relative error is usually expressed as a percentage, we have 0.3%.
To perform tasks 2 and 3, the "Analysis Package" add-in is used (from the menu Tools Data Analysis Histogram).
To install an add-on, open the Tools Add-ins menu and select "Analysis package" from the list of available add-ons available for installation (see. Installing add-ons
Excel on computer.doc).