Par Mike Weiner
Co-auteur : Burzin Patel
Editeurs : Lubor Kollar, Kevin Cox, Bill Emmert, Greg Husemeier, Paul Burpo, Joseph Sack, Denny Lee, Sanjay Mishra, Lindsey Allen, Mark Souza
Microsoft SQL Server 2008 contient un certain nombre d'améliorations et de nouvelles fonctionnalités qui étendent les fonctionnalités des versions précédentes. L'administration et la maintenance des bases de données, le maintien de la gérabilité, de la disponibilité, de la sécurité et des performances relèvent de la responsabilité de l'administrateur de la base de données. Cet article décrit dix des nouvelles fonctionnalités les plus utiles de SQL Server 2008 (par ordre alphabétique) qui facilitent le travail de l'administrateur de base de données. En plus d'une brève description, pour chacune des fonctions, il existe des situations possibles d'utilisation et des recommandations d'utilisation importantes.
Moniteur d'activité
Lors du dépannage des problèmes de performances ou de la surveillance des performances du serveur en temps réel, un administrateur exécute généralement une série de scripts ou vérifie les sources d'informations pertinentes pour recueillir des informations générales sur les processus en cours d'exécution et identifier la cause première du problème. Le moniteur d'activité de SQL Server 2008 agrège ces informations pour fournir des informations visuelles sur les processus en cours d'exécution et récemment exécutés. Le DBA peut à la fois afficher des informations de haut niveau et analyser n'importe quel processus plus en détail et se familiariser avec les statistiques d'attente, ce qui facilite l'identification et la résolution des problèmes.
Pour ouvrir Activity Monitor, cliquez avec le bouton droit sur le nom du serveur enregistré dans l'Explorateur d'objets, puis sélectionnez Moniteur d'activité vous pouvez également utiliser l'icône de la barre d'outils standard dans SQL Server Management Studio. Activity Monitor offre à l'administrateur une section de présentation similaire en apparence au Dispatcher Tâches Windows, ainsi que les composants pour une vue détaillée des processus individuels, en attente de ressources, d'E/S vers des fichiers de données et de demandes récentes gourmandes en ressources, comme le montre la Fig. une.
Figure. une:Vue Moniteur d'activitéSQL Serveur2008 en mercrediLa gestion Studio

Noter. Activity Monitor utilise un paramètre de taux de rafraîchissement des données qui peut être modifié par un clic droit. Si vous choisissez d'actualiser les données fréquemment (toutes les moins de 10 secondes), les performances d'un système de production fortement chargé peuvent diminuer.
Avec le moniteur d'activité, l'administrateur peut également effectuer les tâches suivantes :
· Pause et reprendre Activity Monitor avec un clic droit. Cela permet à l'administrateur de "enregistrer" les informations d'état à un moment précis, elles ne seront ni mises à jour ni écrasées. Gardez à l'esprit, cependant, que si vous actualisez manuellement les données, développez ou réduisez une partition, les anciennes données seront mises à jour et perdues.
· Cliquez avec le bouton droit sur un élément de ligne pour afficher le texte complet de la requête ou un plan d'exécution graphique à l'aide de l'élément de menu Requêtes récentes de grande puissance.
· Tracez par Profiler ou terminez les processus dans la vue Processus. Les événements de l'application Profiler incluent des événements RPC: Complété, SQL: BatchStarting et SQL: Lot terminé, aussi bien que AuditConnexion et AuditSe déconnecter.
Activity Monitor vous permet également de surveiller l'activité de toute instance locale ou distante de SQL Server 2005 enregistrée auprès de SQL Server Management Studio.
Audit
La possibilité de suivre et de consigner les événements qui se produisent, y compris les informations sur les utilisateurs accédant aux objets et le calendrier et le contenu des modifications, aide l'administrateur à garantir la conformité avec les normes de sécurité réglementaires ou organisationnelles. En outre, la compréhension des événements dans l'environnement peut également aider à développer un plan pour atténuer les risques et maintenir la sécurité dans l'environnement.
Dans SQL Server 2008 (éditions Enterprise et Developer uniquement), SQL Server Audit implémente une automatisation qui permet à un administrateur et à d'autres utilisateurs de préparer, enregistrer et afficher les audits de divers composants de serveur et de base de données. La fonctionnalité fournit un audit avec une granularité au niveau du serveur ou de la base de données.
Il existe des groupes d'activités d'audit au niveau du serveur, tels que les suivants :
· FAILED_LOGIN_GROUP suit les tentatives de connexion échouées.
· BACKUP_RESTORE_GROUP indique quand la base de données a été sauvegardée ou restaurée.
· Audits DATABASE_CHANGE_GROUP lorsque la base de données a été créée, modifiée ou supprimée.
Les groupes d'actions d'audit de base de données sont les suivants :
· DATABASE_OBJECT_ACCESS_GROUP est appelé chaque fois qu'une instruction CREATE, ALTER ou DROP est exécutée sur un objet de base de données.
DATABASE_OBJECT_PERMISSION_CHANGE_GROUP est appelé lorsque vous utilisez des instructions GRANT, REVOKE ou DENY sur des objets de base de données.
Il existe d'autres actions d'audit telles que SELECT, DELETE et EXECUTE. Informations Complémentaires, y compris une liste complète de tous les groupes et activités d'audit, consultez Groupes et activités d'audit SQL Server.
Les résultats de l'audit peuvent être envoyés pour consultation ultérieure dans un fichier ou un journal des événements ( journal du système ou le journal des événements de sécurité Windows). Les données d'audit sont générées à l'aide Événements prolongés est une autre nouvelle fonctionnalité de SQL Server 2008.
Les audits SQL Server 2008 permettent à un administrateur de répondre à des questions auxquelles il était auparavant très difficile de répondre après coup, par exemple « Qui a supprimé cet index ? », « Quand la procédure stockée a-t-elle été modifiée ? ? » et même "Qui a exécuté l'instruction SELECT ou UPDATE sur la table [ dbo.Paie] ?».
Pour plus d'informations sur l'utilisation de l'audit SQL Server et des exemples de mise en œuvre, consultez le Guide de conformité SQL Server 2008.
Compression des sauvegardes
Les administrateurs de bases de données suggèrent depuis longtemps d'activer cette fonctionnalité dans SQL Server. C'est maintenant chose faite, et juste à temps ! Récemment, pour un certain nombre de raisons, par exemple en raison de la durée accrue de stockage des données et de la nécessité de stocker physiquement davantage de données, la taille des bases de données a commencé à croître de manière exponentielle. Lors de la sauvegarde d'une grande base de données, il est nécessaire d'allouer une quantité importante d'espace disque pour les fichiers de sauvegarde, ainsi qu'un temps important pour l'opération.
Avec la compression de sauvegarde SQL Server 2008, le fichier de sauvegarde est compressé au fur et à mesure de son écriture, ce qui nécessite non seulement moins d'espace disque, mais également moins d'E/S et prend moins de temps à sauvegarder. Lors de tests en laboratoire avec des données utilisateur réelles, une réduction de 70 à 85 % de la taille du fichier de sauvegarde a été observée dans de nombreux cas. De plus, des tests ont montré que les temps de copie et de restauration étaient réduits d'environ 45 %. Il convient de noter qu'un traitement supplémentaire lors de la compression augmente la charge sur les processeurs. Pour découpler le processus de copie gourmand en ressources des autres processus dans le temps et minimiser son impact sur leur travail, vous pouvez utiliser une autre fonction décrite dans ce document - Ressource Gouverneur.
La compression est activée en ajoutant la clause WITH COMPRESSION à la commande BACKUP (voir la documentation en ligne de SQL Server pour plus d'informations) ou en définissant cette option sur la page Paramètres boite de dialogue Sauvegarde de la base de données... Pour éliminer le besoin de modifier tous les scripts de sauvegarde existants, une option globale a été implémentée pour compresser toutes les sauvegardes créées sur l'instance de serveur par défaut. (Cette option est disponible sur la page Paramètres de la base de données boite de dialogue Propriétés du serveur; il peut également être installé en exécutant la procédure stockée sp_ configurer avec valeur de paramètre sauvegardecompressiondéfautégal à 1). La commande backup requiert un paramètre de compression explicite et la commande restore reconnaît automatiquement la sauvegarde compressée et la décompresse lors de la restauration.
La compression des sauvegardes est une fonctionnalité extrêmement utile qui permet d'économiser de l'espace disque et du temps. Pour plus d'informations sur la configuration de la compression de sauvegarde, consultez la note technique Réglage des performances de compression de sauvegarde dansSQL Serveur 2008 ... Noter. Les sauvegardes compressées ne sont prises en charge que dans les éditions Enterprise et Developer de SQL Server 2008 ; cependant, toutes les éditions de SQL Server 2008 vous permettent de restaurer des sauvegardes compressées.
Serveurs de gestion centralisés
Souvent, le DBA gère plusieurs instances de SQL Server à la fois. La possibilité de centraliser la gestion et l'administration de plusieurs instances SQL en un seul point permet d'économiser beaucoup d'efforts et de temps. L'implémentation du serveur de gestion centralisée disponible dans SQL Server Management Studio via la fonctionnalité Serveurs enregistrés permet à un administrateur d'effectuer diverses opérations administratives sur plusieurs serveurs SQL à partir d'une seule console de gestion.
Les serveurs de gestion centralisée permettent à un administrateur d'enregistrer un groupe de serveurs et d'y effectuer les opérations suivantes comme s'il s'agissait d'un seul groupe :
· Exécution de requêtes multi-serveurs : vous pouvez désormais exécuter un script à partir d'une seule source sur de nombreux serveurs SQL, les données seront renvoyées à cette source et vous n'avez pas besoin de vous connecter à chaque serveur séparément. Cela peut être particulièrement utile lorsque vous devez afficher ou comparer des données de plusieurs serveurs SQL sans exécuter de requête distribuée. De plus, si la syntaxe de requête est prise en charge par les versions précédentes de SQL Server, une requête lancée à partir de l'éditeur de requêtes SQL Server 2008 peut s'exécuter sur des instances de SQL Server 2005 et SQL Server 2000. Pour plus d'informations, consultez le billet de blog groupe de travail Pour plus d'informations sur la gestion de SQL Server, consultez Exécution de requêtes sur plusieurs serveurs dans SQL Server 2008.
Importation et définition de politiques sur plusieurs serveurs : au sein de la fonctionnalité Gestion basée sur des politiques(autre nouvelle fonctionnalité de SQL Server 2008, également décrite dans cet article), SQL Server 2008 offre la possibilité d'importer des fichiers de stratégie dans des groupes spécifiques de serveurs de gestion centralisée et vous permet de définir des stratégies sur tous les serveurs enregistrés dans un groupe spécifique.
· Gérer les services et appeler le gestionnaire de configuration SQL Server : l'outil Management Central Servers vous aide à créer un centre de contrôle où le DBA peut afficher et même modifier (avec les autorisations appropriées) l'état des services.
· Importation et exportation de serveurs enregistrés : les serveurs enregistrés auprès de Central Management Servers peuvent être exportés et importés au fur et à mesure qu'ils sont transférés entre les administrateurs ou les différentes instances installées de SQL Server Management Studio. Cette capacité sert d'alternative à l'administrateur qui importe ou exporte ses propres groupes locaux dans SQL Server Management Studio.
Gardez à l'esprit que les autorisations sont appliquées à l'aide de l'authentification Windows, de sorte que les droits et les autorisations des utilisateurs peuvent différer sur différents serveurs enregistrés dans le groupe Management Central Server. Pour plus d'informations, consultez Administer Multiple Servers with Centralized Management Servers et le blog de Kimberly Tripp : Serveurs de gestion SQL centrauxServeur2008 - les connaissez-vous ?
Collecteur de données et entrepôt de données de gestion
Le réglage des performances et les diagnostics prennent du temps et peuvent nécessiter des compétences professionnelles en SQL Server et une compréhension de la structure interne des bases de données. L'Analyseur de performances Windows (Perfmon), SQL Server Profiler et les vues de gestion dynamique faisaient certaines de ces choses, mais ils avaient souvent un impact sur le serveur, étaient lourds à utiliser ou utilisaient des techniques de collecte de données dispersées qui rendaient difficile la combinaison et l'interprétation.
Pour fournir des informations significatives sur les performances du système afin que vous puissiez prendre des mesures spécifiques, SQL Server 2008 fournit une fonction de collecte et de stockage des données de performances entièrement extensible, le collecteur de données. Il contient plusieurs agents de collecte de données prêts à l'emploi, un référentiel centralisé de données de performance, le référentiel de données de gestion, et plusieurs rapports prédéfinis pour présenter les données collectées. Le collecteur de données est un outil évolutif qui collecte et agrège des données à partir de diverses sources, telles que les vues de gestion dynamique, le moniteur de performances Perfmon et les requêtes Transact-SQL, à un taux de collecte entièrement personnalisable. Le collecteur de données peut être étendu pour collecter des données sur tout attribut mesurable de l'application.
Une autre fonctionnalité utile de Management Data Warehouse est la possibilité de l'installer sur n'importe quel serveur SQL, puis de collecter des données à partir d'une ou plusieurs instances de SQL Server. Cela minimise l'impact sur les performances des systèmes de production et améliore l'évolutivité dans le contexte du suivi et de la collecte de données à partir de plusieurs serveurs. Lors des tests en laboratoire, la perte de débit observée lors de l'exécution des agents et de l'exécution de l'entrepôt de données de gestion sur un serveur occupé (en utilisant une charge de travail OLTP) était d'environ 4 %. La perte de performances peut varier en fonction de la fréquence de collecte des données (le test mentionné a été effectué sous une charge de travail étendue, avec un transfert de données vers le stockage toutes les 15 minutes), elle peut également augmenter considérablement pendant les périodes de collecte de données. Dans tous les cas, vous devez vous attendre à une certaine réduction des ressources disponibles, car le processus DCExec.exe utilise une certaine quantité de ressources mémoire et CPU, et l'écriture dans le magasin de données de gestion augmentera la charge sur le sous-système d'E / S et nécessitera de l'espace. pour les données et les fichiers journaux (Figure 2) montre un rapport type de collecteur de données.
Figure. 2:Vue du rapport du collecteur de donnéesSQL Serveur 2008

Le rapport montre l'activité de SQL Server pendant la période de collecte de données. Il collecte et rapporte des événements tels que les attentes, l'utilisation du processeur, des E/S et de la mémoire, ainsi que des statistiques sur les demandes gourmandes en ressources. Un administrateur peut également accéder à un aperçu détaillé des éléments du rapport, en se concentrant sur une seule demande ou opération pour enquêter, identifier et résoudre les problèmes de performances. Ces capacités de collecte, de stockage et de création de rapports de données permettent une surveillance proactive de l'intégrité des serveurs SQL dans votre environnement. Ils vous permettent de revenir aux données historiques si nécessaire pour comprendre et évaluer les changements qui ont affecté les performances au cours de la période surveillée. Le collecteur de données et l'entrepôt de données de gestion sont pris en charge dans toutes les éditions de SQLServer 2008, à l'exception de SQLServerExpress.
Compression de données
La facilité de gestion de la base de données facilite grandement l'exécution des tâches d'administration de routine. À mesure que la taille des tables, des index et des fichiers augmente et que la prolifération des très grandes bases de données (VLDB), la gestion des données et les fichiers encombrants deviennent plus complexes. De plus, les demandes croissantes de mémoire et de bande passante d'E/S physiques avec le volume de données demandées compliquent également les opérations des administrateurs et sont coûteuses pour les organisations. En conséquence, dans de nombreux cas, les administrateurs et les organisations doivent soit étendre la mémoire ou la bande passante E/S des serveurs, soit accepter une dégradation des performances.
La compression des données, introduite dans SQL Server 2008, permet de résoudre ces problèmes. Cette fonctionnalité permet à l'administrateur de compacter de manière sélective toutes les tables, partitions de table ou index, réduisant ainsi l'utilisation du disque et de la mémoire et la taille des E/S. La compression et la décompression des données sont gourmandes en ressources processeur ; cependant, dans de nombreux cas, la charge supplémentaire du processeur est plus que compensée par le gain d'E/S. Dans les configurations où les E/S constituent le goulot d'étranglement, la compression des données peut également apporter des gains de performances.
Dans certains tests en laboratoire, l'activation de la compression des données a permis d'économiser 50 à 80 % d'espace disque. Les économies d'espace variaient considérablement : si les données contenaient peu de valeurs en double, ou si les valeurs utilisaient tous les octets alloués pour le type de données spécifié, les économies étaient minimes. Cela n'a pas augmenté les performances de nombreuses charges de travail. Cependant, lorsque vous travaillez avec des données contenant de nombreuses données numériques et de nombreuses valeurs en double, des économies significatives d'espace disque et des gains de performances allant de quelques pour cent à 40 à 60 % ont été réalisées pour certains exemples de charges de travail de requête.
SQLServer 2008 prend en charge deux types de compression : la compression de ligne, qui compresse les colonnes de table individuelles, et la compression de page, qui compresse les pages de données à l'aide de la compression de chaîne, de préfixes et de la compression de dictionnaire. Le taux de compression atteint dépend fortement des types de données et du contenu de la base de données. En général, lors de l'utilisation de la compression de ligne, la surcharge sur les opérations d'application est réduite, mais le taux de compression est également réduit, ce qui signifie moins d'espace est gagné. Dans le même temps, la compression des pages entraîne une charge d'application et une charge de processeur supplémentaires, mais permet également d'économiser beaucoup plus d'espace. La compression de page est un sur-ensemble de compression de ligne, c'est-à-dire que si un objet ou une section d'un objet est compressé à l'aide de la compression de page, elle applique également la compression de ligne. De plus, SQLServer 2008 prend en charge le format de stockage vardécimalà partir de SQL Server 2005 SP2. Veuillez noter que ce format étant un sous-ensemble de la compression de chaîne, il est obsolète et sera supprimé des futures versions du produit.
La compression de ligne et la compression de page peuvent être activées pour une table ou un index dans mode de fonctionnement sans compromettre la disponibilité des données pour les applications. Dans le même temps, il est impossible de réduire ou de décompresser une partition individuelle d'une table partitionnée en ligne sans la désactiver. Des tests ont montré que l'approche combinée est la meilleure, car elle ne compresse que quelques-unes des plus grandes tables et permet d'obtenir un excellent rapport entre les économies d'espace disque (significatives) et les pertes de performances (minimum). Étant donné que l'opération de réduction, comme les opérations de création ou de reconstruction d'index, a également des exigences en matière d'espace disque disponible, la réduction doit être effectuée en tenant compte de ces exigences. Un minimum d'espace libre pendant le processus de compression est requis si vous démarrez la compression avec les objets les plus petits.
La compression des données peut être effectuée à l'aide d'instructions Transact-SQL ou de l'assistant de compression de données. Vous pouvez utiliser la procédure stockée système pour déterminer si un objet peut être redimensionné lorsqu'il est compressé. sp_estimation_Les données_compression_des économies ou l'assistant de compression de données. Le compactage de la base de données n'est pris en charge que dans les éditions SQLServer 2008 Enterprise et Developer. Il est implémenté exclusivement dans les bases de données elles-mêmes et ne nécessite aucune modification des applications.
Pour plus d'informations sur l'utilisation de la compression, consultez Création de tables et d'index compressés.
Gestion basée sur des politiques
Dans de nombreux scénarios commerciaux, il est nécessaire de maintenir des configurations spécifiques ou d'appliquer des stratégies sur un serveur SQL spécifique ou plusieurs fois sur un groupe de serveurs SQLServer. Un administrateur ou une organisation peut avoir besoin d'un schéma de nommage spécifique pour toutes les tables personnalisées ou procédures stockées qui sont créées, ou exiger que des modifications de configuration spécifiques soient appliquées sur de nombreux serveurs.
La gestion basée sur les politiques (PBM) fournit à l'administrateur un large éventail d'options pour la gestion de l'environnement. Les politiques peuvent être créées et vérifiées par rapport à celles-ci. Si la cible d'analyse (par exemple, le moteur de base de données, la base de données, la table ou l'index SQLServer) ne répond pas aux exigences, l'administrateur peut la reconfigurer automatiquement en fonction de ces exigences. Il existe également un certain nombre de modes de stratégie (dont beaucoup sont automatisés) qui permettent de vérifier facilement la conformité aux stratégies, de consigner les violations de stratégie et d'envoyer des notifications, et même d'annuler les modifications pour garantir la conformité aux stratégies. Pour plus d'informations sur les modes de définition et leur correspondance avec les aspects (le concept de gestion basée sur les stratégies (PBM), également abordé dans ce blog), consultez le blog sur la gestion basée sur les stratégies SQL Server.
Les politiques peuvent être exportées et importées sous forme de fichiers XML pour être définies et appliquées sur plusieurs instances de serveur. De plus, dans SQLServerManagement Studio et dans la vue des serveurs enregistrés, vous pouvez définir des stratégies sur de nombreux serveurs enregistrés dans un groupe de serveurs locaux ou dans un groupe de serveurs Management Central.
DANS Versions précédentes Toutes les fonctionnalités de gestion basées sur des stratégies peuvent ne pas être implémentées dans SQL Server. Cependant, la fonction faire un rapport les stratégies peuvent être utilisées à la fois sur SQL Server 2005 et SQL Server 2000. Pour plus d'informations sur l'utilisation de la gestion basée sur des stratégies, consultez Administration de serveurs à l'aide de la gestion basée sur des stratégies dans la documentation en ligne de SQLServer. Pour plus d'informations sur la technologie de stratégie elle-même, avec des exemples, consultez le Guide de conformité SQL Server 2008.
Performances prévues et simultanéité
De nombreux administrateurs ont des difficultés considérables à maintenir les serveurs SQL avec des charges de travail en constante évolution et à fournir des niveaux de performances prévisibles (ou à minimiser les écarts dans les plans de requête et de performance). Les modifications de performances inattendues lors de l'exécution de la requête, les modifications des plans de requête et/ou les problèmes généraux liés aux performances peuvent être causés par un certain nombre de raisons, notamment une charge accrue des applications exécutées sur le serveur SQL ou une mise à niveau de version de la base de données elle-même. La prévisibilité des requêtes et des opérations sur SQLServer facilite grandement l'atteinte et le maintien de vos objectifs de disponibilité, de performances et/ou de continuité d'activité (SLA et accords de support opérationnel).
Dans SQLServer 2008, plusieurs fonctionnalités ont été modifiées pour améliorer la prévisibilité des performances. Ainsi, certaines modifications ont été apportées aux structures de plan de SQLServer 2005 ( regroupement de régimes) et a ajouté la possibilité de gérer l'escalade des verrous au niveau de la table. Les deux améliorations contribuent à une communication plus prévisible et ordonnée entre l'application et la base de données.
Tout d'abord, le Guide du plan :
SQL Server 2005 a apporté des améliorations à la stabilité et à la prévisibilité des requêtes avec une nouvelle fonctionnalité appelée « guides de plan » qui contenait des instructions pour l'exécution de requêtes qui ne pouvaient pas être modifiées directement dans l'application. Pour plus d'informations, consultez le livre blanc Application du plan de requête. Bien que l'astuce de la requête USE PLAN soit très puissante, elle ne prenait en charge que les opérations SELECT DML et était souvent difficile à utiliser en raison de la sensibilité de mise en forme des repères de plan.
Dans SQL Server 2008, le mécanisme de guide de plan a été étendu de deux manières : premièrement, la prise en charge des conseils dans la requête USE PLAN a été étendue, qui est désormais compatible avec toutes les instructions DML (INSERT, UPDATE, DELETE, MERGE) ; deuxièmement, introduit nouvelle fonction consolidation des plans qui vous permet de créer directement une structure de plan (épingler) tout plan de requête existant dans le cache de plan SQL Server, comme illustré dans l'exemple suivant.
sp_create_plan_guide_from_handle
@name = N'MyQueryPlan ',
@plan_handle = @plan_handle,
@statement_start_offset = @offset;
Un guide de plan créé de quelque manière que ce soit a une zone de base de données; il est stocké dans une table sys.plan_guides... Les guides de plan n'influencent que le processus de sélection d'un plan de requête par l'optimiseur, mais n'éliminent pas la nécessité de compiler la requête. Fonction également ajoutée sys.fn_validate_plan_guide pour valider les guides de plan SQL Server 2005 existants et s'assurer qu'ils sont compatibles avec SQL Server 2008. L'épinglage de plan est disponible dans les éditions SQL Server 2008 Standard, Enterprise et Developer.
Deuxièmement, l'escalade des verrous :
L'escalade des verrous causait souvent des problèmes de verrouillage et parfois même des blocages. L'administrateur devait résoudre ces problèmes. Dans les versions précédentes de SQLServer, l'escalade de verrous pouvait être contrôlée (indicateurs de trace 1211 et 1224), mais cela n'était possible que pour la granularité au niveau de l'instance. Pour certaines applications, cela a résolu le problème, tandis que pour d'autres, cela a causé des problèmes encore plus importants. Un autre inconvénient de l'algorithme d'escalade de verrou dans SQL Server 2005 était que les verrous sur les tables partitionnées étaient escaladés directement au niveau de la table, plutôt qu'au niveau de la partition.
SQLServer 2008 offre une solution aux deux problèmes. Il introduit une nouvelle option pour contrôler l'escalade des verrous au niveau de la table. Avec la commande ALTERTABLE, vous pouvez choisir de désactiver l'escalade ou d'escalader au niveau de la partition pour les tables partitionnées. Ces deux fonctionnalités améliorent l'évolutivité et les performances sans effets secondaires indésirables affectant les autres objets de l'instance. L'escalade de verrouillage est définie au niveau de l'objet de la base de données et ne nécessite aucune modification de l'application. Il est pris en charge dans toutes les éditions de SQLServer 2008.
Gouverneur des ressources
Maintenir un niveau de service cohérent en empêchant les demandes malveillantes et en veillant à ce que les charges de travail critiques soient provisionnées a été un défi dans le passé. Il n'y avait aucun moyen de garantir l'allocation d'une certaine quantité de ressources à un ensemble de requêtes, il n'y avait aucun contrôle des priorités d'accès. Toutes les demandes avaient des droits égaux pour accéder à toutes les ressources disponibles.
Nouveau Fonction SQL Server 2008 - "Resource Governor" - aide à résoudre ce problème en donnant la possibilité de différencier les charges de travail et d'allouer les ressources en fonction des besoins des utilisateurs. Les limites du gouverneur de ressources sont facilement reconfigurables en temps réel avec un impact minimal sur les charges de travail en cours d'exécution. La répartition des charges de travail sur le pool de ressources est configurable au niveau de la connexion, et ce processus est totalement transparent pour les applications.
Le schéma ci-dessous montre le processus d'allocation des ressources. Dans ce scénario, trois pools de charges de travail (charges de travail Admin, OLTP et Rapport) sont configurés et le pool de charges de travail OLTP reçoit la priorité la plus élevée. Dans le même temps, deux pools de ressources (pool et pool d'applications) sont configurés avec des limites spécifiées de temps de mémoire et de processeur (CPU). Dans la dernière étape, la charge de travail Admin est affectée au pool Admin, et les charges de travail OLTP et Rapport sont affectées au pool d'applications.

Les éléments suivants sont à prendre en compte lors de l'utilisation de Resource Governor.
- Resource Governor utilise les identifiants de connexion, le nom d'hôte ou le nom de l'application comme « identifiant du pool de ressources », donc l'utilisation du même identifiant pour une application avec un certain nombre de clients par serveur peut compliquer la mise en commun.
- Le regroupement d'objets au niveau de la base de données, dans lequel l'accès aux ressources est régulé en fonction des objets de base de données auxquels on accède, n'est pas pris en charge.
- Seule l'utilisation du processeur et de la mémoire peut être configurée. La gestion des ressources d'E/S n'est pas implémentée.
- Il n'est pas possible de basculer dynamiquement les charges de travail entre les pools de ressources une fois connecté.
- Le gouverneur de ressources n'est pris en charge que dans les éditions SQL Server 2008 Enterprise et Developer et ne peut être utilisé que pour le moteur de base de données SQL Server ; La gestion de SQL Server Analysis Services (SSAS), SQL Server Integration Services (SSIS) et SQL Server Reporting Services (SSRS) n'est pas prise en charge.
Cryptage transparent des données (TDE)
De nombreuses organisations accordent une grande importance aux questions de sécurité. Il existe de nombreuses couches différentes qui protègent l'un des actifs les plus précieux d'une organisation - ses données. Le plus souvent, les organisations protègent avec succès les données qu'elles utilisent avec des mesures de sécurité physique, des pare-feu et des politiques de restriction d'accès strictes. Cependant, en cas de perte support physique avec des données, telles qu'un disque ou une bande avec une sauvegarde, toutes les mesures de sécurité ci-dessus sont inutiles, car un attaquant peut simplement restaurer la base de données et obtenir un accès complet aux données. SQL
Server 2008 offre une solution à ce problème avec Transparent Data Encryption (TDE). Avec le cryptage TDE, les données d'E/S sont cryptées et décryptées en temps réel ; les données et les fichiers journaux sont cryptés à l'aide d'une clé de cryptage de base de données (DEK). DEK est une clé symétrique protégée par un certificat stocké dans la base de données du serveur > maître, ou une clé asymétrique protégée par le module Advanced Key Management (EKM).
TDE protège les données "inactives", de sorte que les données des fichiers MDF, NDF et LDF ne peuvent pas être visualisées avec un éditeur de données hexadécimal ou autrement. Cependant, les données actives, telles que les résultats d'une instruction SELECT dans SQL Server Management Studio, resteront visibles pour les utilisateurs autorisés à afficher la table. De plus, comme TDE est implémenté au niveau de la base de données, la base de données peut utiliser des index et des clés pour optimiser les requêtes. TDE ne doit pas être confondu avec le chiffrement au niveau des colonnes - il s'agit d'une fonctionnalité autonome qui permet de chiffrer même les données actives.
Le chiffrement de la base de données est un processus unique qui peut être démarré par une commande Transact - SQL ou à partir de SQL Server Management Studio, puis exécuté dans un thread d'arrière-plan. L'état du chiffrement ou du déchiffrement peut être surveillé à l'aide de la vue de gestion dynamique sys.dm_database_encryption_keys... Lors des tests en laboratoire, une base de données de 100 Go a été chiffrée à l'aide d'un algorithme Cryptage AES _128 a pris environ une heure. Bien que la surcharge TDE soit principalement due à la charge de travail de l'application, dans certains des tests effectués, la surcharge était inférieure à 5 %. Une chose à garder à l'esprit qui peut affecter les performances est que si TDE est utilisé dans l'une des bases de données de l'instance, la base de données système est également chiffrée. base de données temporaire... Enfin, lorsque vous utilisez différentes fonctions en même temps, les éléments suivants doivent être pris en compte :
- Lors de l'utilisation de la compression de sauvegarde pour compresser une base de données chiffrée, la taille de la sauvegarde compressée sera plus grande que sans chiffrement, car les données chiffrées ne sont pas correctement compressées.
- Le chiffrement de la base de données n'affecte pas la compression des données (ligne ou page).
TDE permet à une organisation de se conformer aux normes réglementaires et à un niveau global de protection des données. TDE est uniquement pris en charge dans les éditions SQL Server 2008 Enterprise et Developer ; son activation ne nécessite aucune modification des applications existantes. Pour plus d'informations, consultez Chiffrement des données dans SQL Server 2008 Enterprise Edition ou la discussion dans Cryptage transparent des données.
En résumé, SQL Server 2008 offre des fonctionnalités, des améliorations et des capacités pour faciliter le travail de l'administrateur de base de données. Les 10 plus populaires sont décrits ici, mais SQL Server 2008 possède de nombreuses autres fonctionnalités pour faciliter la vie des administrateurs et des autres utilisateurs. Pour les listes des « 10 principales fonctionnalités » pour d'autres domaines d'utilisation de SQL Server, consultez les autres articles sur les 10 principales ... dans SQL Server 2008 sur ce site. Liste complète fonctions et leurs Description détaillée consultez la documentation en ligne de SQL Server et le site Web de présentation de SQL Server 2008.
SQL Server fournit un certain nombre de constructions de contrôle différentes qui sont essentielles à l'écriture d'algorithmes efficaces.
Regrouper deux ou plusieurs équipes en bloc unique s'effectue à l'aide des mots clés BEGIN et END :
<блок_операторов>::=
Les commandes groupées sont traitées comme une seule commande par l'interpréteur SQL. Un tel regroupement est requis pour les constructions de ramifications polyvariantes, les constructions conditionnelles et cycliques. Les blocs BEGIN ... END peuvent être imbriqués.
Certaines commandes SQL ne doivent pas être exécutées conjointement avec d'autres commandes (telles que les commandes de sauvegarde, la modification de la structure des tables, les procédures stockées, etc.), elles ne peuvent donc pas être incluses ensemble dans la clause BEGIN ... END.
Souvent, une certaine partie du programme ne doit être exécutée que lorsqu'une condition logique est réalisée. La syntaxe de l'instruction conditionnelle est indiquée ci-dessous :
<условный_оператор>::=
SI expression_journal
(sql_operator | statement_block)
(sql_operator | statement_block)]
Les boucles sont organisées selon la construction suivante :
<оператор_цикла>::=
WHILE expression_journal
(sql_operator | statement_block)
(sql_operator | statement_block)
Une boucle peut être forcée à s'arrêter en exécutant une commande BREAK dans son corps. Si vous devez recommencer le cycle sans attendre que toutes les commandes du corps s'exécutent, vous devez exécuter la commande CONTINUER.
Pour remplacer plusieurs instructions conditionnelles simples ou imbriquées, la construction suivante est utilisée :
<оператор_поливариантных_ветвлений>::=
CASE valeur_entrée
QUAND (valeur_comparée |
expression_log) ALORS
expression_sortie [, ... n]
[ELSE else_out_expression]
Si la valeur d'entrée et la valeur à comparer sont identiques, la construction renvoie la valeur de sortie. Si la valeur du paramètre d'entrée n'est trouvée dans aucune des lignes WHEN ... THEN, la valeur spécifiée après le mot-clé ELSE sera renvoyée.
Objets de base de la structure de la base de données du serveur SQL
Considérons la structure logique de la base de données.
La structure logique définit la structure des tables, les relations entre elles, une liste d'utilisateurs, des procédures stockées, des règles, des valeurs par défaut et d'autres objets de base de données.
Les données sont organisées logiquement dans SQL Server en tant qu'objets. Les principaux objets d'une base de données SQL Server incluent les objets suivants.
Un aperçu rapide des principaux objets de la base de données.
les tables
Toutes les données en SQL sont contenues dans des objets appelés les tables... Les tableaux sont une collection d'informations sur des objets, des phénomènes, des processus dans le monde réel. Aucun autre objet ne stocke de données, mais ils peuvent accéder aux données de la table. Les tables en SQL ont la même structure que les tables de tous les autres SGBD et contiennent :
· Cordes ; chaque ligne (ou enregistrement) est une collection d'attributs (propriétés) d'une instance spécifique d'un objet ;
· Colonnes; chaque colonne (champ) représente un attribut ou une collection d'attributs. Le champ de ligne est le plus petit élément du tableau. Chaque colonne d'une table a un nom, un type de données et une taille spécifiques.
Représentation
Les vues (vues) sont des tables virtuelles dont le contenu est déterminé par une requête. Comme les vraies tables, les vues contiennent des colonnes et des lignes de données nommées. Pour les utilisateurs finaux, une vue ressemble à une table, mais elle ne contient pas réellement de données, mais représente uniquement des données situées dans une ou plusieurs tables. Les informations que l'utilisateur voit à travers la vue ne sont pas stockées dans la base de données en tant qu'objet indépendant.
Procédures stockées
Les procédures stockées sont un groupe de commandes SQL combinées en un seul module. Ce groupe de commandes est compilé et exécuté comme une unité.
Déclencheurs
Les déclencheurs sont une classe spéciale de procédures stockées qui sont automatiquement lancées lorsque des données sont ajoutées, modifiées ou supprimées d'une table.
Les fonctions
Les fonctions dans les langages de programmation sont des constructions qui contiennent du code fréquemment exécutable. La fonction exécute une action sur les données et renvoie une valeur.
Index
Index - une structure associée à une table ou à une vue et conçue pour accélérer la recherche d'informations dans celles-ci. Un index est défini sur une ou plusieurs colonnes, appelées colonnes indexées. Il contient les valeurs triées de la ou des colonnes indexées avec des références à la ligne correspondante dans la table ou la vue source. Le gain de performance est obtenu en triant les données. L'utilisation d'index peut améliorer considérablement les performances de recherche, mais un espace supplémentaire est requis dans la base de données pour stocker les index.
© 2015-2019 site
Tous les droits appartiennent à leurs auteurs. Ce site ne revendique pas la paternité, mais fournit une utilisation gratuite.
Date de création de la page : 2016-08-08
Mon entreprise vient de passer par son processus de révision annuelle et je les ai finalement convaincus qu'il était temps de trouver la meilleure solution pour gérer nos schémas/scènes SQL. Nous n'avons actuellement que quelques scripts de mise à jour manuelle.
J'ai travaillé avec VS2008 Database Edition dans une autre entreprise et c'est un produit incroyable. Mon patron m'a demandé de jeter un œil à SQL Compare de Redgate et de rechercher d'autres produits qui pourraient être meilleurs. La comparaison SQL est également un excellent produit. Cependant, il semble qu'ils ne prennent pas en charge Perforce.
Avez-vous utilisé une variété de produits pour cela?
Quels outils utilisez-vous pour gérer SQL ?
Qu'est-ce qui doit être inclus dans les exigences avant que mon entreprise ne fasse un achat ?
10 réponses
Je ne pense pas qu'il existe un outil qui puisse gérer toutes les pièces. VS Database Edition ne fournit pas un moteur de publication décent. L'exécution de scripts individuels à partir du navigateur de solutions n'est pas adaptée aux grands projets.
Au moins tu as besoin
- IDE / éditeur
- dépôt code source qui peut être lancé depuis votre IDE
- convention de nommage et organisation de divers scripts dans des dossiers
- le processus de gestion des modifications, de gestion des versions et d'exécution des déploiements.
La dernière balle est l'endroit où les choses se cassent habituellement. Voilà pourquoi. Pour une meilleure gestion et un suivi des versions, vous souhaitez stocker chaque objet de base de données dans son propre propre fichier scénario. C'est-à-dire que chaque table, procédure stockée, vue, index, etc. a son propre fichier.
Lorsque quelque chose change, vous mettez à jour le fichier et vous avez une nouvelle version dans votre référentiel avec information nécessaire... Lorsqu'il s'agit de regrouper plusieurs modifications dans une version, la gestion fichiers individuels peut être encombrant.
2 options que j'ai utilisées :
En plus de stocker tous les objets de base de données individuels dans leurs fichiers, vous disposez de scripts de version, qui sont une concaténation de scripts individuels. Inconvénient de ceci : Vous avez du code à 2 endroits avec tous les risques et inconvénients. Potentiel : exécuter une version est aussi simple que d'exécuter un seul script.
écrivez un petit outil qui peut lire les métadonnées du script à partir du manifeste de version et exécuter le script eadch spécifié dans le manifeste sur le serveur cible. Il n'y a aucun inconvénient à cela, sauf que vous devez écrire du code. Cette approche ne fonctionne pas pour les tables qui ne peuvent pas être supprimées et recréées (une fois que vous vivez et que vous avez des données), donc pour les tables, vous aurez des scripts de modification. Donc, en fait, ce sera une combinaison des deux approches.
Je suis dans le camp du "script it yourself" car les produits tiers ne vous guideront que pour gérer le code de votre base de données. Je n'ai pas un script pour chaque objet car les objets changent au fil du temps et neuf fois sur dix, il ne suffirait pas de mettre à jour mon script "créer une table" pour avoir trois nouvelles colonnes.
La création de base de données est généralement triviale. Configurez un tas de scripts CREATE, ordonnez-les correctement (créez la base de données devant les schémas, les schémas devant les tables, les tables devant les procédures, appelez les procédures avant les appels, etc.) et faites-le. La gestion des changements de base de données n'est pas facile :
- Si vous ajoutez une colonne à une table, vous ne pouvez pas simplement supprimer la table et la créer avec une nouvelle colonne, car cela détruirait toutes vos précieuses données de production.
- Si Fred ajoute une colonne à la table XYZ et que Marie ajoute une autre colonne à la table XYZ, quelle colonne est ajoutée en premier ? Oui, l'ordre des colonnes dans les tables n'a pas d'importance [parce que vous n'utilisez jamais SELECT *, n'est-ce pas ?] À moins que vous n'essayiez de gérer la base de données et de suivre la gestion des versions, vous avez alors deux bases de données "valides" qui ne On dirait que l'autre devient un vrai casse-tête. Nous utilisons la comparaison SQL non pas pour la gestion, mais pour la vue d'ensemble et le suivi des choses, en particulier pendant le développement, et les quelques situations "ils sont différents (mais pas magnifier)" que nous pouvons nous empêcher de remarquer les différences qui comptent.
- De même, lorsque plusieurs projets (développeurs) travaillent simultanément et séparément dans socle commun données, cela peut devenir très délicat. Peut-être que tout le monde travaille sur le projet Next Big Thing lorsque soudainement quelqu'un doit commencer à corriger des bogues dans le projet Last Big Thing. Comment gérez-vous les modifications de code nécessaires lorsque l'ordre de sortie est variable et flexible ? (Des moments vraiment amusants.)
- Changer les structures des tables signifie changer les données, et cela peut devenir extrêmement difficile lorsque vous devez faire face à la compatibilité descendante. Vous ajoutez la colonne "DeltaFactor", d'accord, alors que faites-vous pour remplir cette valeur ésotérique pour toutes vos données existantes (lire : périmées) ? Vous ajoutez nouveau tableau colonne de recherche et de correspondance, mais comment la remplir pour les lignes existantes ? Ces situations peuvent ne pas arriver souvent, mais quand elles le font, vous devez le faire vous-même. Les outils tiers ne peuvent tout simplement pas anticiper les besoins de votre logique métier.
Fondamentalement, j'ai un script CREATE pour chaque base de données suivi d'une série de scripts ALTER à mesure que notre base de code change au fil du temps. Chaque script vérifie s'il peut être exécuté : c'est la "vue" correcte de la base de données, les pré-scripts nécessaires ont été exécutés, ce script est déjà en cours d'exécution. Ce n'est que lorsque les contrôles sont passés que le script exécutera ses modifications.
En tant qu'outil, nous utilisons SourceGear Fortress pour gérer le code source sous-jacent, Redgate SQL Compare pour le support général et le dépannage, et une gamme de scripts d'accueil basés sur SQLCMD pour déployer des scripts "en masse" avec des modifications sur plusieurs serveurs et bases de données et suivre qui a postulé quels scripts aux bases de données à quel moment. Résultat final : Toutes nos bases de données sont stables et stables, et nous pouvons facilement prouver quelle version est ou était à un moment donné.
Nous exigeons que toutes les modifications de base de données ou insertions dans des éléments tels que les tables de recherche soient effectuées dans un script et enregistrées dans le contrôle de source. Ils sont ensuite déployés de la même manière que tout autre code de déploiement de version logicielle. Comme nos développeurs n'ont pas de droits de déploiement, ils n'ont d'autre choix que de créer des scripts.
J'utilise généralement MS Server Management Studio pour gérer SQL, travailler avec des données, développer des bases de données et les déboguer, si je dois exporter des données vers un script SQL ou créer une sorte d'objet complexe dans la base de données, j'utilise EMS SQL Management Studio pour SQL Server car là, je peux voir plus clairement que les sections étroites de mon code et la conception visuelle dans cet environnement me permettent de
J'ai un projet open source (sous licence LGPL) qui essaie de résoudre les problèmes avec la version correcte du schéma de base de données pour (et plus) SQL Server (2005/2008 / Azure), bsn ModuleStore. L'ensemble du processus est très proche du concept expliqué par le post de Philip Kelly ici.
Fondamentalement, une partie distincte de la boîte à outils scripte les objets de base de données SQL Server du schéma de base de données dans des fichiers avec un formatage standard, de sorte que le contenu du fichier ne change que si l'objet a réellement changé (par opposition aux scripts créés par VS, qui crée également scripts, etc., en notant tous les objets modifiés, même s'ils sont pratiquement identiques).
Mais la boîte à outils va au-delà de cela si vous utilisez .NET : elle vous permet d'intégrer des scripts SQL dans une bibliothèque ou une application (en tant que ressources intégrées), puis de comparer les scripts intégrés comparés à l'état actuel de la base de données. Les modifications non liées aux tables (celles qui ne sont pas des « modifications destructives » telles que définies par Martin Fowler) peuvent être appliquées automatiquement ou à la demande (par exemple, créer et supprimer des objets tels que des vues, des fonctions, des procédures stockées, des types, des index) et des scripts de modification (qui doit être enregistré manuellement) peut être appliqué dans le même processus; de nouvelles tables sont également créées, ainsi que leurs données de paramétrage. Après la mise à niveau, le schéma de la base de données est à nouveau comparé aux scripts pour garantir une mise à niveau réussie de la base de données avant que les modifications ne soient validées.
Notez que tous les scripts et codes de comparaison fonctionnent sans SMO, vous n'avez donc pas la douloureuse dépendance SMO lors de l'utilisation du bsn ModuleStore dans les applications.
Selon la façon dont vous souhaitez accéder à la base de données, la boîte à outils offre encore plus - elle implémente certaines des capacités de l'ORM et offre une approche frontale très agréable et utile pour appeler des procédures stockées, y compris un support XML transparent avec des classes XML .NET natives, et aussi pour TVP (Table-Valued Parameters) comme IEnumerable
Voici mon script pour garder une trace des proc et udf et des déclencheurs stockés dans une table.
Créer une table pour contenir votre code source proc existant
Injecter une table avec toutes les données de déclencheur et de script existantes
Créer un déclencheur DDL pour suivre les changements sur eux
/ ****** Objet : Tableau. Date du script : 17/09/2014 11:36:54 AM ****** / SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE. (IDENTITY (1, 1) NOT NULL, (1000) NULL, (1000) NULL, (1000) NULL, (1000) NULL, NULL, NTEXT NULL, CONSTRAINT PRIMARY KEY CLUSTERED (ASC) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON) ON GO ALTER TABLE. AJOUTER LA CONTRAINTE PAR DÉFAUT ("") POUR ALLER INSÉRER DANS. (,,,,,) SELECT "sa", "loginitialdata", r.ROUTINE_NAME, r.ROUTINE_TYPE, GETDATE (), r.ROUTINE_DEFINITION FROM INFORMATION_SCHEMA.ROUTINES r UNION SELECT "sa", "loginitialdata", v.TABLE_NAME " view", GETDATE (), v.VIEW_DEFINITION FROM INFORMATION_SCHEMA.VIEWS v UNION SELECT "sa", "loginitialdata", o.NAME, "trigger", GETDATE (), m.DEFINITION FROM sys.objects o JOIN sys.sql_modules m ON o.object_id = m.object_id O o.type = "TR" GO CREATE TRIGGER SUR LA BASE DE DONNÉES POUR CREATE_PROCEDURE, ALTER_PROCEDURE, DROP_PROCEDURE, CREATE_INDEX, ALTER_INDEX, DROP_INDEX, CREATE_TRIGGER, ALTER_TRIGGER, ALTER_TRIGGER, DROP_TRIGGER_VIEW, ALTER_TABLE, B NOCOUNT ON DECLARE @data XML SET @data = Eventdata () INSERT INTO sysupdatelog VALUES (@ data.value ("(/ EVENT_INSTANCE / LoginName)", "nvarchar (255)"), @ data.value ("(/ EVENT_INSTANCE / EventType) "," nvarchar (255) "), @ data.value (" (/ EVENT_INSTANCE / ObjectName) "," nvarchar (255) "), @ data.value ("(/ EVENT_INSTANCE / ObjectType)", "nvarchar (255)"), getdate (), @ data.value ("(/ EVENT_INSTANCE / TSQLCommand / CommandText)", "nvarchar (max)")) SET NOCOUNT OFF END GO SET ANSI_NULLS OFF GO SET QUOTED_IDENTIFIER OFF GO ACTIVER LE DÉCLENCHEUR SUR LA BASE DE DONNÉES GO
Parfois, vous voulez vraiment mettre de l'ordre dans vos pensées, les mettre sur les étagères. Et encore mieux dans l'ordre alphabétique et thématique, pour qu'enfin il y ait une clarté de pensée. Imaginez maintenant quel genre de chaos se produirait dans " cerveaux électroniques» Tout ordinateur sans structuration claire de toutes les données et Microsoft SQL Server :
Serveur MS SQL
Ce produit logiciel est un système de gestion de base de données relationnelle (SGBD) développé par Microsoft Corporation. Un langage Transact-SQL spécialement développé est utilisé pour la manipulation des données. Les commandes de langage pour récupérer et modifier la base de données sont basées sur des requêtes structurées :

Les bases de données relationnelles sont construites sur l'interconnexion de tous éléments structurels, y compris en raison de leur nidification. Les bases de données relationnelles prennent en charge les types de données les plus courants. Par conséquent, SQL Server intègre la prise en charge de la structuration par programme des données à l'aide de déclencheurs et de procédures stockées.
Présentation des fonctionnalités de MS SQL Server

Le SGBD fait partie d'une longue chaîne de logiciels spécialisés que Microsoft a créés pour les développeurs. Cela signifie que tous les maillons de cette chaîne (application) sont profondément intégrés les uns aux autres.
Autrement dit, leurs outils interagissent facilement les uns avec les autres, ce qui simplifie grandement le processus de développement et d'écriture de code logiciel. Un exemple d'une telle relation est l'environnement de programmation MS Visual Studio. Son package d'installation comprend déjà SQL Server Express Edition.
Bien sûr, ce n'est pas le seul SGBD populaire sur le marché mondial. Mais c'est elle qui est plus acceptable pour les ordinateurs fonctionnant sous Contrôle des fenêtres, en raison de l'accent mis sur ce système d'exploitation particulier. Et pas seulement à cause de cela.
Avantages de MS SQL Server :
- Possède un haut degré de performance et de tolérance aux pannes ;
- C'est un SGBD multi-utilisateurs et fonctionne sur le principe « client-serveur » ;
La partie client du système prend en charge la création de demandes personnalisées et leur envoi pour traitement au serveur.
- Intégration étroite avec le système d'exploitation Windows ;
- Prise en charge des connexions à distance ;
- Prise en charge des types de données courants, ainsi que la possibilité de créer des déclencheurs et des procédures stockées ;
- Prise en charge intégrée des rôles d'utilisateur ;
- Fonction de sauvegarde de base de données étendue ;
- Haut degré de sécurité ;
- Chaque numéro comprend plusieurs éditions spécialisées.
Évolution de SQL Server
Les particularités de ce SGBD populaire sont plus faciles à retracer en considérant l'historique de l'évolution de toutes ses versions. Plus en détail, nous nous attarderons uniquement sur les versions auxquelles les développeurs ont apporté des modifications importantes et fondamentales :
- Microsoft SQL Server 1.0 - Sorti en 1990. Même alors, les experts ont noté la grande vitesse de traitement des données, démontrée même à charge maximale dans un mode de fonctionnement multi-utilisateurs ;
- SQL Server 6.0 - Publié en 1995. Cette version introduit le premier support au monde pour les curseurs et la réplication de données ;
- SQL Server 2000 - Dans cette version, le serveur a reçu un tout nouveau moteur. La plupart des changements n'affectaient que le côté utilisateur de l'application ;
- SQL Server 2005 - L'évolutivité du SGBD a augmenté, les processus de gestion et d'administration ont été considérablement simplifiés. Une nouvelle API a été introduite pour prendre en charge la plate-forme de programmation .NET ;
- Les versions ultérieures visaient à développer l'interaction du SGBD au niveau technologies cloud et des outils de veille économique.
Le package de base du système comprend plusieurs utilitaires pour la configuration de SQL Server. Ceux-ci inclus:

Panneau de configuration. Vous permet de gérer tout le monde paramètres réseau et les services de serveur de base de données. Utilisé pour configurer SQL Server sur le réseau.
- Rapports d'erreur et d'utilisation de SQL Server:

L'utilitaire est utilisé pour configurer l'envoi de rapports d'erreurs au support Microsoft.

Utilisé pour optimiser les performances du serveur de base de données. C'est-à-dire que vous pouvez personnaliser le fonctionnement de SQL Server en fonction de vos besoins en activant ou en désactivant certaines fonctionnalités et composants du SGBD.
L'ensemble d'utilitaires inclus dans Microsoft SQL Server peut différer selon la version et l'édition du progiciel. Par exemple, dans la version 2008, vous ne trouverez pas Configuration de la surface d'exposition du serveur SQL.
Exécution de Microsoft SQL Server
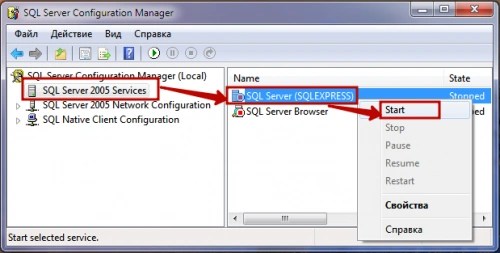
La version 2005 du serveur de base de données sera utilisée comme exemple. Le serveur peut être démarré de plusieurs manières :
- Grâce à l'utilitaire Gestionnaire de configuration de serveur SQL... Dans la fenêtre de l'application à gauche, sélectionnez "Services SQL Server 2005" et à droite - l'instance de serveur de base de données dont nous avons besoin. Nous le marquons et sélectionnons « Démarrer » dans le sous-menu du bouton droit de la souris.
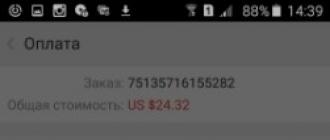
- Utilisation de l'environnement SQL Server Management Studio Express... Il n'est pas inclus dans le package d'installation de l'édition Express. Par conséquent, il doit être téléchargé séparément à partir du site Web officiel de Microsoft.
Pour démarrer le serveur de base de données, nous lançons l'application. Dans la boîte de dialogue " Connexion serveur"Dans le champ" Nom du serveur ", sélectionnez l'instance dont nous avons besoin. Dans le champ " Authentification"Laisser la valeur" Authentification Windows". Et cliquez sur le bouton "Connecter":

Principes de base de l'administration de SQL Server
Avant de démarrer MS SQL Server, vous devez vous familiariser brièvement avec les fonctionnalités de base de sa configuration et de son administration. Commençons par un aperçu plus détaillé de plusieurs utilitaires du SGBD :
- Configuration de la surface d'exposition du serveur SQL- vous devez contacter ici si vous souhaitez activer ou désactiver une fonctionnalité du serveur de base de données. Au bas de la fenêtre, il y a deux éléments : le premier est responsable de paramètres réseau, et dans le second, vous pouvez activer un service ou une fonction qui est désactivé par défaut. Par exemple, activez l'intégration avec le framework .NET via des requêtes T-SQL :
Si vous avez déjà écrit des schémas de verrouillage dans d'autres langages de base de données pour surmonter le manque de verrouillage (comme je l'ai fait), vous aurez peut-être encore l'impression de devoir gérer vous-même le verrouillage. Laissez-moi vous assurer que vous pouvez faire entièrement confiance au gestionnaire de serrure. Cependant, SQL Server propose plusieurs méthodes de gestion des verrous, que nous aborderons en détail dans cette section.
N'appliquez pas de paramètres de verrouillage et ne modifiez pas les niveaux d'isolement de manière aléatoire. Faites confiance au gestionnaire de verrouillage SQL Server pour équilibrer les conflits et l'intégrité des transactions. Seulement si vous êtes absolument sûr que le schéma de la base de données est bien configuré et code de programme littéralement poli, vous pouvez légèrement ajuster le travail du gestionnaire de verrouillage pour résoudre un problème spécifique. Dans certains cas, la définition des requêtes sélectionnées pour ne pas bloquer peut résoudre la plupart des problèmes.
Définition du niveau d'isolement d'une connexion
Le niveau d'isolement détermine la durée d'un verrou partagé ou exclusif sur une connexion. La définition du niveau d'isolement affecte toutes les requêtes et toutes les tables utilisées tout au long de la connexion ou jusqu'à ce que vous remplaciez explicitement un niveau d'isolement par un autre. L'exemple suivant définit une isolation plus stricte que la valeur par défaut et empêche les lectures non en double :
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ Les niveaux d'isolement valides sont :
Lire sans engagement ? sérialisable
Lire engagé? instantané
Lecture répétable
Le niveau d'isolement actuel peut être vérifié à l'aide de la commande Database Integrity Check (DBCC) :
OPTIONS UTILISATEUR DBCC
Les résultats seront les suivants (en abrégé) :
Définir la valeur de l'option
niveau d'isolement lecture répétable
Les niveaux d'isolement peuvent également être définis au niveau de la requête ou de la table à l'aide de paramètres de verrouillage.
Utilisation de l'isolement au niveau de l'instantané de base de données
Il existe deux options pour le niveau d'isolement des instantanés de base de données : instantané et instantané validé en lecture. L'isolation d'instantané fonctionne comme une lecture reproductible sans traiter les problèmes de blocage. L'isolement d'instantané validé en lecture imite le niveau de validation en lecture par défaut de SQL Server, tout en supprimant également les problèmes de blocage.
Alors que l'isolement des transactions est généralement établi au niveau de la connexion, l'isolement des instantanés doit être configuré au niveau de la base de données car il est
suit efficacement la gestion des versions des lignes dans la base de données. La gestion des versions de ligne est une technologie qui crée des copies de lignes dans la base de données TempDB à mettre à jour. En plus du chargement principal de la base de données TempDB, la gestion des versions de ligne ajoute également un identifiant de ligne de 14 octets.
Utilisation de l'isolement d'instantané
L'extrait de code suivant active le niveau d'isolement de l'instantané. Aucune autre connexion ne doit être établie à la base de données pour mettre à jour la base de données et activer le niveau d'isolement des instantanés.
ALTER DATABASE Aesop
SET ALLOW_SNAPSHOT_ISOLATION ON
| Pour vérifier si l'isolement d'instantané est activé dans la base de données, exécutez la requête SVS suivante : SELECT name, snapshot_isolation_state_desc FROM [* sysdatabases.
La première transaction commence maintenant à lire et reste ouverte (c'est-à-dire non validée) : USE Aesop
BEGIN TRAN SELECT Title FROM FABLE WHERE FablelD = 2
Vous obtiendrez la sortie suivante :
À ce stade, la deuxième transaction commence à mettre à jour la même ligne qui a été ouverte par la première transaction :
FIXER LE NIVEAU D'ISOLEMENT DE LA TRANSACTION Instantané ;
COMMENCER LA MISE À JOUR TRAN Fable
SET Titre = « Basculer avec des instantanés »
O FablelD = 2;
SÉLECTIONNER * À PARTIR DE FABLE O FablelD = 2
Le résultat est le suivant :
Basculer avec des instantanés
N'est-ce pas incroyable? La deuxième transaction a pu mettre à jour la ligne même si la première transaction est restée ouverte. Revenons à la première transaction et voyons les données initiales :
SELECTIONNER LE Titre FROM FABLE WHERE FablelD = 2
Le résultat est le suivant :
Si vous ouvrez les troisième et quatrième transactions, elles verront la même valeur d'origine de The Bald Knight :
Même après que la deuxième transaction ait confirmé les modifications, la première verra toujours la valeur d'origine et toutes les transactions suivantes en verront une nouvelle, Rocking with Snapshots.
Utilisation d'ISOLATION Read Commited Snapshot
L'isolation d'instantané en lecture validée est activée à l'aide d'une syntaxe similaire :
ALTER DATABASE Aesop
SET READ_COMMITTED_SNAPSHOT ON
Comme l'isolement d'instantané, ce niveau utilise également la gestion des versions de ligne pour résoudre les problèmes de verrouillage. Sur la base de l'exemple décrit dans la section précédente, dans ce cas, la première transaction verra les modifications apportées par la seconde dès qu'elles seront validées.
Étant donné que Read Commited est le niveau d'isolement par défaut dans SQL Server, il vous suffit de définir les paramètres de la base de données.
Résolution des conflits d'écriture
Les transactions qui écrivent des données lorsque le niveau d'isolement de l'instantané est défini peuvent être bloquées par des transactions d'écriture non validées précédentes. Un tel verrou ne forcera pas une nouvelle transaction à attendre - il générera simplement une erreur. Utilisez une instruction try pour gérer des situations comme celle-ci. ... ... catch, attendez quelques secondes et réessayez la transaction.
Utilisation des options de verrouillage
Les paramètres de blocage vous permettent d'apporter des ajustements temporaires à la stratégie de blocage. Alors que le niveau d'isolement affecte la connexion globale, les paramètres de verrouillage sont spécifiques à chaque table dans une requête particulière (Table 51.5). L'option WITH (lock_option) est placée après le nom de la table dans la clause FROM de la requête. Plusieurs paramètres peuvent être spécifiés pour chaque table, séparés par des virgules.
|
Tableau 51.5. Options de blocage |
Paramètre blocage |
La description |
Niveau d'isolement. N'acquiert ni ne maintient un verrou. Équivalent à aucun blocage |
Niveau d'isolement par défaut pour les transactions |
Niveau d'isolement. Détient des verrous partagés et exclusifs jusqu'à ce que la transaction soit confirmée |
Niveau d'isolement. Détient un verrou partagé jusqu'à la fin de la transaction |
Sauter les lignes verrouillées au lieu d'attendre |
Activation du verrouillage au niveau de la ligne au lieu du niveau de la page, de l'étendue ou de la table |
Activer le verrouillage au niveau de la page au lieu du niveau de la table |
Escalade automatique des verrous de ligne, de page et d'étendue jusqu'à la granularité au niveau de la table |
Paramètre blocage |
La description |
Non-application et non-rétention des verrous. Identique à ReadUnCommited |
Active le verrouillage exclusif de la table. Empêcher d'autres transactions de fonctionner avec la table |
Maintenir un verrou partagé jusqu'à ce que la transaction soit confirmée (similaire à Serializable) |
Utiliser un verrou de mise à jour au lieu d'un verrou partagé et le maintenir. Verrouillage d'autres écritures sur les données entre les lectures et les écritures initiales |
Détenir un verrou de données exclusif jusqu'à ce que la transaction soit confirmée |
L'exemple suivant utilise une option de verrouillage dans la clause FROM d'une instruction UPDATE pour empêcher le répartiteur d'augmenter la granularité du verrouillage :
UTILISER LA MISE À JOUR OBXKites
À PARTIR du produit AVEC (RowLock)
SET ProductName = ProductName + 'Mise à jour 1
Si la requête contient des sous-requêtes, n'oubliez pas que l'accès à la table de chacune des requêtes génère un verrou, qui peut être contrôlé à l'aide de paramètres.
Limitations de verrouillage au niveau de l'index
Les niveaux d'isolement et les paramètres de blocage sont appliqués au niveau de la connexion et de la requête. La seule façon de gérer les verrous au niveau de la table est de limiter la granularité des verrous en fonction d'index spécifiques. À l'aide de la procédure stockée du système sp_indexoption, les verrous de ligne et/ou de page peuvent être désactivés pour un index spécifique à l'aide de la syntaxe suivante : sp_indexoption 'nom_index 1,
AllowRowlocks ou AllowPagelocks,
Cela peut être utile dans un certain nombre de cas particuliers. Si une table a des attentes fréquentes en raison de verrous de page, la définition de allowpagelocks sur off définira le verrouillage au niveau de la ligne. Une granularité de verrouillage réduite aura un effet positif sur la concurrence. De plus, si la table est rarement mise à jour mais fréquemment lue, les verrous au niveau des lignes et des pages ne sont pas souhaitables ; dans ce cas, le verrouillage au niveau de la table est optimal. Si les mises à jour sont peu fréquentes, les verrous de table exclusifs ne sont pas un gros problème.
La procédure stockée Sp_indexoption est conçue pour réglage fin schémas de données ; c'est pourquoi il utilise le verrouillage au niveau de l'index. Pour restreindre les verrous sur la clé primaire d'une table, utilisez sp_help nom_table pour rechercher le nom d'index de la clé primaire.
La commande suivante configure la table ProductCategory en tant que classificateur rarement mis à jour. La commande sp_help affiche d'abord le nom de l'index de clé primaire de la table : sp_help ProductCategory
Le résultat (tronqué) est :
index index index
clés de description de nom
PK_____________ ProductCategory 79A814 03 non groupé, ProductCategorylD
clé primaire unique située sur PRIMARY
Avec le vrai nom de la clé primaire disponible, la procédure stockée système peut définir les paramètres de verrouillage d'index :
EXEC sp_indexoption
'ProductCategory.РК__ ProductCategory_______ 7 9А814 03 ′,
'AllowRowlocks', FALSE EXEC sp_indexoption
'ProductCategory.PK__ ProductCategory_______ 79A81403 ′,
'Autoriser les verrouillages de page', FAUX
Verrouiller la gestion du délai d'attente
Si une transaction attend un verrou, cette attente se poursuivra jusqu'à ce que le verrou devienne possible. Il n'y a pas de limite de délai d'attente par défaut - théoriquement, cela peut durer éternellement.
Heureusement, vous pouvez définir le délai d'expiration du verrouillage à l'aide du paramètre de connexion set lock_timeout. Définissez ce paramètre sur le nombre de millisecondes ou, si vous ne souhaitez pas limiter le temps, définissez-le sur -1 (c'est la valeur par défaut). Si ce paramètre est défini sur 0, la transaction sera immédiatement rejetée s'il y a un verrou. Dans ce cas, l'application sera extrêmement rapide, mais inefficace.
La requête suivante définit le délai d'expiration du verrouillage sur deux secondes (2000 millisecondes) :
SET Lock_Timeout 2 00 0
Si la transaction dépasse le délai d'expiration spécifié, un numéro d'erreur 1222 est généré.
Il est fortement recommandé de définir une limite de délai de verrouillage au niveau de la connexion. Cette valeur est sélectionnée en fonction des performances de base de données typiques. Je préfère régler le temps d'attente à cinq secondes.
Évaluation des performances de contention de la base de données
Il est très facile de créer une base de données qui ne résout pas les problèmes de conflit et de conflit de verrouillage lors des tests sur un groupe d'utilisateurs. Le vrai test est lorsque plusieurs centaines d'utilisateurs mettent à jour les commandes en même temps.
Les tests de compétition doivent être correctement organisés. À un certain niveau, il devrait contenir l'utilisation simultanée du même formulaire final par de nombreux utilisateurs. Un programme .NET qui imite continuellement
visualisation et mise à jour des données par l'utilisateur. Bon test doit exécuter 20 instances du script qui charge constamment la base de données, puis laisser l'équipe de test utiliser l'application. Le nombre de verrous vous aidera à voir le moniteur de performances décrit au chapitre 49.
La compétition multijoueur est mieux testée plusieurs fois au cours du développement. Comme le dit le manuel de l'examen MCSE, « ne laissez pas le test du monde réel passer en premier. »
Verrouillage des applications
SQL Server utilise un schéma de verrouillage très complexe. Parfois, un processus ou une ressource autre que les données nécessite un verrou. Par exemple, il peut être nécessaire d'exécuter une procédure nuisible si un autre utilisateur exécute une autre instance de la même procédure.
Il y a plusieurs années, j'ai écrit un programme de routage de câbles pour des projets de centrales nucléaires. Lorsque la géométrie de l'usine a été conçue et testée, les ingénieurs ont saisi la composition de l'équipement de câble, son emplacement et les types de câbles utilisés. Après avoir inséré plusieurs câbles, le programme a formé le tracé de leur pose de manière à ce qu'il soit le plus court possible. La procédure a également pris en compte les problèmes de sécurité du câblage et a séparé les câbles incompatibles. Dans le même temps, si plusieurs procédures de routage étaient exécutées en même temps, chaque instance tentait de router les mêmes câbles, entraînant des résultats incorrects. Le blocage des applications a été une excellente solution à ce problème.
Le verrouillage des applications ouvre tout un monde de verrous SQL conçus pour être utilisés dans les applications. Au lieu d'utiliser les données en tant que ressource verrouillable, les verrous d'application verrouillent l'utilisation de toutes les ressources personnalisées déclarées dans la procédure stockée sp__GetAppLock.
Le verrouillage des applications peut être appliqué dans les transactions ; le mode de blocage peut être Partagé, Mise à jour, Exclusif, IntentExclusice ou IntentShared. La valeur de retour de la procédure indique si le verrou a été appliqué avec succès.
0. Le verrou a été défini avec succès.
1. Le verrou a été activé lorsqu'une autre procédure a libéré son verrou.
999. Le verrou n'a pas été activé pour une autre raison.
La procédure stockée sp_ReleaseApLock libère le verrou. L'exemple suivant montre comment le verrouillage d'application peut être utilisé dans un package ou une procédure : DECLARE @ShareOK INT EXEC @ShareOK = sp_GetAppLock
@Resource = 'CableWorm',
@LockMode = 'Exclusif'
SI @PartagerOK< 0
... Code de gestion des erreurs
... Code de programme ...
EXEC sp_ReleaseAppLock @Resource = 'CableWorm'
Lorsque les verrous d'application sont affichés à l'aide de Management Studio ou de sp_Lock, ils sont affichés en tant que type APP. La liste suivante montre la sortie abrégée de sp_Lock s'exécutant simultanément avec le code ci-dessus : spid dbid Objld Indld Type Resource Mode Status
57 8 0 0 APP Cabllf 94cl36 X GRANT
Il y a deux petites différences à noter dans la façon dont les verrous d'application sont gérés dans SQL Server :
Les interblocages ne sont pas automatiquement détectés ;
Si une transaction acquiert le verrou plusieurs fois, elle doit le libérer exactement le même nombre de fois.
Blocages
Un blocage est une situation spéciale qui se produit uniquement lorsque des transactions avec plusieurs tâches sont en concurrence pour les ressources de l'autre. Par exemple, la première transaction a acquis un verrou sur la ressource A et doit verrouiller la ressource B, et en même temps, la deuxième transaction, qui a verrouillé la ressource B, doit verrouiller la ressource A.
Chacune de ces transactions attend que l'autre libère son verrou et aucune d'entre elles ne peut se terminer tant qu'elle ne le fait pas. S'il n'y a pas d'influence extérieure ou si l'une des transactions sera conclue par certaine raison(par exemple, en termes de temps d'attente), alors cette situation peut perdurer jusqu'à la fin du monde.
Les blocages étaient un problème sérieux, mais maintenant SQL Server peut le résoudre avec succès.
Créer une impasse
Le moyen le plus simple de créer une situation de blocage dans SQL Server consiste à utiliser deux connexions dans l'éditeur de requête de Management Studio (Figure 51.12). Les première et deuxième transactions tentent de mettre à jour les mêmes lignes, mais dans l'ordre inverse. En utilisant la troisième fenêtre pour démarrer la procédure pGetLocks, vous pouvez surveiller les verrous.
1. Créez une deuxième fenêtre dans l'éditeur de requêtes.
2. Placez le code de bloc Étape 2 dans la deuxième fenêtre.
3. Dans la première fenêtre, placez le code de bloc Étape 1 et appuyez sur la touche
4. Dans la deuxième fenêtre, exécutez de la même manière le code Étape 2.
5. Revenez à la première fenêtre et exécutez le code de bloc Étape 3.
6. Après une courte période, SQL Server détecte le blocage et le résout automatiquement.
Vous trouverez ci-dessous le code de programme de l'exemple.
- Transaction 1 - Étape 1 UTILISER OBXKites COMMENCER LA MISE À JOUR DE LA TRANSACTION
SET Nom = 'Jorgenson'
O ContactCode = 401 ′
Puc. 51.12. Créer une situation de blocage dans Management Studio à l'aide de deux connexions (leurs fenêtres sont en haut)
La première transaction a maintenant défini un verrou d'écriture exclusif avec une valeur de 101 dans le champ ContactCode. La deuxième transaction acquerra un verrou exclusif sur la ligne avec la valeur 1001 dans le champ ProductCode, puis essaiera de verrouiller exclusivement l'enregistrement déjà verrouillé par la première transaction (ContactCode = 101).
- Transaction 2 - Étape 2 USE OBXKites BEGIN TRANSACTION UPDATE Product SET ProductName
= 'Kit de réparation DeadLock'
O Code Produit = '1001'
SET Prénom = 'Neals'
O ContactCode = '101'
ENGAGER LA TRANSACTION
Il n'y a pas encore de blocage car la transaction 2 attend la fin de la transaction 1, mais la transaction 1 n'attend pas encore la fin de la transaction 2. Dans cette situation, si la transaction 1 se termine et exécute une instruction COMMIT TRANSACTION, la ressource de données sera libérée et la transaction 2 est sûre aura la possibilité de la bloquer si nécessaire et de poursuivre ses actions.
Le problème se produit lorsque la transaction 1 essaie de mettre à jour la ligne avec ProductCode = l. Cependant, il ne recevra pas le verrou exclusif nécessaire pour cela, puisque cet enregistrement est verrouillé par la transaction 2 :
- Transaction 1 - Étape 3 UPDATE Product SET ProductName
= 'Testeur d'identification DeadLock'
O Code Produit = '1001'
ENGAGER LA TRANSACTION
La transaction 1 renverra le message d'erreur de texte suivant après quelques secondes. Le blocage résultant peut également être vu dans SQL Server Profiler (Figure 51.13) :
Serveur : Msg 1205, niveau 13,
L'état 50, transaction de ligne 1 (ID de processus 51) était
bloqué sur les ressources de verrouillage avec un autre processus et a été choisi comme victime du blocage. Réexécutez la transaction.
La transaction 2 terminera son travail comme si le problème n'existait pas :
(1 rangée(s) affectée(s))
(1 rangée(s) affectée(s))

Figure. 51.13. SQL Server Profiler vous permet de surveiller les blocages à l'aide de l'événement Locks: Deadlock Graph et d'identifier la ressource qui a provoqué le blocage
Détection automatique des blocages
Comme le montre le code ci-dessus, SQL Server détecte automatiquement une situation de blocage en recherchant les processus de blocage et en annulant les transactions.
ceux qui ont effectué le moins de travail. SQL Server vérifie en permanence l'existence de verrous croisés. La latence de détection de blocage peut aller de zéro à deux secondes (en pratique, le temps le plus long que j'ai dû attendre est de cinq secondes).
Gestion des blocages
Lorsqu'un blocage se produit, la connexion sélectionnée comme victime du blocage doit retenter sa transaction. Étant donné que le travail doit être refait, il est bon que la transaction qui a réussi à terminer le moins de travail soit annulée - ce sera la même transaction qui sera répétée depuis le début.
Le code d'erreur 12 05 doit être intercepté par l'application cliente, qui doit redémarrer la transaction. Si tout se passe comme il se doit, l'utilisateur ne soupçonnera même pas qu'un blocage s'est produit.
Plutôt que de laisser le serveur décider quelle transaction choisir en tant que victime, la transaction elle-même peut être un jeu gratuit. Le code suivant, lorsqu'il est placé dans une transaction, informe SQL Server d'annuler la transaction en cas de blocage :
SET DEADLOCKJRIORITY LOW
Minimiser les blocages
Même si les blocages sont faciles à détecter et à gérer, il est préférable de les éviter. Les directives suivantes vous aideront à éviter les blocages.
Essayez de garder vos transactions courtes et sans code. Si un code n'a pas besoin d'être présent dans la transaction, il doit en être dérivé.
Ne jamais faire dépendre un code de transaction de la saisie de l'utilisateur.
Essayez de créer des packages et des verrous dans le même ordre. Par exemple, la table A est traitée en premier, puis les tables B, C, etc. Ainsi, une procédure attendra la seconde et les interblocages ne peuvent pas se produire par définition.
Planifiez la disposition physique pour garder les données échantillonnées simultanément aussi proches que possible dans les pages de données. Pour ce faire, utilisez la normalisation et choisissez judicieusement les index clusterisés. Réduire la propagation des écluses aidera à éviter leur escalade. De petites serrures peuvent vous aider à éviter la concurrence.
N'augmentez pas le niveau d'isolement sauf si nécessaire. Un niveau d'isolement plus strict augmente la durée des verrouillages.