The prerequisite for the creation of his methodology was S.P. Nikanorov's diagnosis of the existing situation in the development of organizations: there is an accumulation of non-systemic decisions, momentary, situational thinking is spreading everywhere, which leads to the so-called phenomenon of folding - the process of arbitrary emergence of something under the influence of many factors that manifest themselves spontaneously. If something works ineffectively, then they often say: "It happened, no one is to blame." Folding results in uncontrolled areas of life and emerging problems that require action to resolve them.
Who is having problems? They can only be in subjects, that is, those who have opportunities and interests. The problem for the subject lies in the inconsistency of interests with opportunities. Subjects can perceive approximately the same what is happening, but they attribute it to their interests and capabilities, which do not rise above a certain level. Therefore, what is happening is not perceived by them as a single whole problem, which leads to non-systemic solutions.
What are the approaches to solving these problems? Some actors hope to cope with them using a problem-oriented approach, in which the identified deficiencies that hinder the achievement of the subject's goals are investigated. A refined form of this approach is systems analysis, which uses the ideology of purposeful systems. But it is impossible to eliminate the folding phenomenon with the help of problem-oriented methods, since not isolated problems arise, but a tangle of problems. And if you try to solve any one problem, then the tangle of problems only grows and gets tangled, like an ordinary ball of threads when pulling one thread. It is necessary to cut the tangle using a normative approach, which is based on assuming the desired class of systems. When designing systems, this approach should be coordinated with a problem-oriented approach. It is absurd to eliminate the shortcomings of an obsolete system. We must not solve problems, but build everything from scratch, subordinating our interests and our capabilities to this idea. The refined form of the normative approach is systems with an ideal to which they should strive.
The disadvantage of these approaches, which emerged in the 60s of the 20th century and are products of the arms race, is the lack of an understanding of development, in particular, of the transition from an obsolete quality to a new quality that is set by a sequence of goals.
In the early 1970s, long before wide circles of developers realized the futility of creating automated systems based on traditional methodologies, S.P. Nikanorov formed a new methodological approach, in which the object of computer-aided design was not an automated control system, but an organizational management system (SOU). These systems include any organizations in which production, management, design, training and other activities were carried out using computer information systems. The idea of \u200b\u200bthe necessity and problems of designing organizations is considered in the preface to the book by S. Young, translated under his editorship (in section 1).
On the basis of this approach, by 1978 the technical project of the computer-aided design system (ASP) of the SOU was released. This
The ASP had to solve the problem of ensuring the controllability of the design process in the face of continuous changes in the internal and the environment, both of the system being designed and its design system using the methods of mathematical conceptual modeling of the subject area. The theoretical control of the design processes was to be provided, from the formation of the initial concept to the detailed design and the creation of the organization.
The essence of the methodology. Before the direct design of the organizational management system, its general mathematical conceptual model is formed. The design process is reduced to the controlled concretization of the general model and its subsequent interpretation. This ensures the integrity of the system design, in contrast to traditional technology, when the design is a collection of autonomously developed parts. The deductive design is then matched against the original requirements. If inconsistencies are identified, the conceptual model is adjusted and then redesigned.
Thus, in this methodology, the process of mathematical conceptualization is iterative, and it is not reduced to an unambiguous formalization of the object and the design process, as is the case, for example, when designing a heat and power complex carried out by the MAVR system.
In the developed technical project of the ASP of the JMA, the modeling and design methods were focused on the logically directed and therefore controlled theoretical and instrumental-technological design. First of all, the completeness of the conceptual design space was ensured due to the logical formation of all kinds of combinations of elements of a conceptual structure using morphological and other methods. And the mathematical explication made it possible to operate with conceptual constructions, regardless of the applied content and sign design.
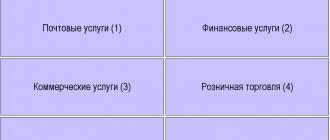
The functions of the ASPSOU system are shown in Table 7.1. Theorization of the subject area is based on identifying problems, establishing their systemic nature and possible solutions. When designing a sign system, the composition of databases, forms of documents, etc. is determined.
Table 7.1 Functions Output Input 1. Definition and implementation of the concept of theorizing the subject area
Operational interpretation of theoretical schemes. Defining control procedures with their inputs and outputs
Designing the symbolic implementation of the SOA and space-time reference.
Documenting the SDA project 1. Model (theory) of the subject area
Organizational Management System Project 1. Metamodels,
describing the concepts of organizational management systems and their elements
Metamodels of formalized theories
To implement this methodology, a set of theoretical schemes, called constructs, were developed, which are used to form the theory of the domain and the model of the design object using logical methods. The development of constructs and the subsequent synthesis of specific theories with the controlled formation of derived concepts were carried out using the mathematical apparatus of Bourbaki's theory of structures. Various technologies for operating with constructs have been created, allowing on their basis to form complex and at the same time easily changeable conceptual schemes.
From the description of the functional structure, it can be seen that, in contrast to the PRIZ system of conceptual programming (see Section 2), the theory of the subject area and the model of the design object are not the input, but the output of the ASP system of the SOU. And only then the JMA projects are formed as a derivative result of logical inference on the constructed models of the subject area and the subsequent interpretation of abstract mathematical constructions. The entrance to the design process is formed with the use of pre-created abstract metamathematical schemes (constructs), metamodels that describe the concepts of an SDA and their elements, and metamodels that describe the existing formalized theories necessary for modeling an SDA. These include the theory of technical systems, the theory of production systems, the theory of purposeful systems, etc. The use of the axiomatic representation of theories was also new here.
The functional structure of the AAS SOU
The versatility of this methodology is predetermined by the general metamodel of the designed system formed using
constructs that are in the memory of the system, and the possibilities of its concretization during design. If, when interpreting a concretized metamodel with the help of the concepts of the covered subject area, the SDA and its elements, its inadequacy is revealed, then either other methods of concretization are chosen, or the general conceptual model is corrected.
Mathematical models of concepts are formed using various theories such as structure theory, set theory, categorical system theory, etc., in different sign forms - texts, tables, formulas, graphs, etc., in different languages, fonts and with different placement on different media. This can be expressed with the help of the theoretical scheme proposed by S.P. Nikanorov in the 70s, called "logosinotopotech". In it, a logical entity ("log") was distinguished, representing its sign ("syn") and the location of the sign ("top") on the carrier ("tech"). The main thing in this scheme was the semantic relation: "log" reveals the meaning of the sign representation "syn".
In this approach, the design object is both the functional structure of the organization and the process of its design. The methodology includes deductive and inductive design stages. The deductive stage is carried out with the help of conceptual axiomatic descriptions of the necessary areas of knowledge in different mathematical forms, previously developed and stored in the memory of the metasystem - set-theoretical, categorical, system-theoretic constructs in N. Bourbaki's set scales. Then, for the formed metamodels of the system, the choice of methods is carried out and, ultimately, the choice of technologies using a base of different theories, models, methods and means.
The inductive stage begins with the control of the adequacy of the formed projects and the subsequent iterative correction of the initial theoretical schemes.
The applicability of the methodology under consideration for the design of organizations is limited by the focus on highly qualified specialists who own the tools for creating and using mathematical constructs, carried out over the past three decades by a research team headed by S.P. Nikanorov.
Currently, there are several hundred constructs and a set of methods for operating them. A relatively small team of specialists has developed an information and software toolkit for automated support for the formation of mathematical metamodels of subject areas using the accumulated base of constructs. An automated system was created that provided a query mode and the execution of operations of synthesis, generation, visualization, etc., syntactic and semantic analyzers, as well as a linguistic interpreter of the types of structures. Further development of the toolkit focused on supporting the design process of organizational procedures and document forms.
Unfortunately, for the implementation of this methodology, when it appeared, a detailed technological design and a complete instrumental system were not developed. To obtain an industrial result, it was necessary to involve powerful organizations specializing in the development of information and software, which required serious government support. Once Academician V.M. Glushkov, director of the Kiev Institute of Cybernetics, said that the creation of a nationwide automated system (OGAS) should be financed in the same way as space programs or the nuclear industry. Unfortunately, this did not happen.
Considering this methodology from a modern standpoint, it is clear that it did not pay enough attention to direct, concrete modeling and development of operating organizations within the framework of theories of production and economic systems. It was focused on the development of new systems, which corresponded to the orientation that existed at that time on the creation of automated production, design and management systems.
Although formally then it was required to conduct a preliminary survey and analysis of existing systems, according to the existing regulatory documentation, and even detailed methods of diagnostic examination and modeling of organizations were developed, but in practice this was rarely done. In the absence of appropriate tools, this stage required enormous efforts and time, and the result of the designers' work was taken into account according to the project of the new system submitted to the state commission and its experimental implementation.
With the chosen method of deductive formation of the project, it becomes difficult to move to the existing variety of the content of real processes, in which model interpretation is carried out, when the elements of the model reflect specific elements of organizational management systems, denoted by the terms of the original field of knowledge. In the metamodel interpretation, the so-called linguistic variables are assigned to the terms of theoretical constructions. But how to move on to specific elements of the organizational management system, if its initial model has not been previously built? And how to form a mathematical model for it with a given set of certain restrictions and an objective function that is adequate to reality?
Such models had to be created during the development of existing organizations and accumulated prototype models for use in the design of new systems. But we must remember that the use of these models in a visual form became possible only after the advent of computers with high speed and huge memory, as well as tools that ensure the formation of such models. Without such models, it is impossible to make an operational comparison of theoretical results with the requirements set in the original field of knowledge and to determine the adequacy of the abstract schemes used.
On the other hand, if there is a specific meaningful model built in the concepts of the original area of \u200b\u200bknowledge, and the instrumental system can logically process non-mathematical concepts, then it is necessary to substantiate the advisability of using mathematical conceptual models in the conditions of using computer networks with large memory and speed.
When using the methodology under consideration, it should be borne in mind that, while reducing the diversity and keeping the development of the system within certain theoretical boundaries, the use of constructs simultaneously coarsens the subject area, limiting the possibilities of conceptual modeling of professionals. When a construct is created, then some aspect of the essence is considered and idealized. Once created, a construct can have many material and symbolic incarnations, but at the same time it displays only a mathematical analogue of a certain side of the essence, and not the meaningful side of the essence itself, which a professional in this field can adequately perceive. At the same time, the nature of knowledge in subject areas is often such that the phrases with the help of which professionals communicate are only a hint of the images of a real entity that arise in them during training and as a result of gaining experience. These images are activated when the phrase is perceived in the mind of a specialist, but in order to convey the meaning of the phrases to specialists from other areas of knowledge, the corresponding images require decoding of hints.
The problem is also the provision of theoretical control of the process of creating constructs, in particular, the substantiation of the choice of aspects of the essence that underlie the development of mathematical structures, and the correctness of its implementation. The mathematical constructs used should ensure the integration of methods and tools available in different subject areas, performing the function of their theoretical superstructure. Given the enormous scale and complexity of areas of knowledge that a modern developer needs to cover, these constructs can also perform an epistemological function.
In the analysis of this approach, it is noted that it is focused on direct support in the design of systems of their desired properties. But for its implementation, it is necessary to accumulate the required constructs that provide such capabilities, to test the necessary methods of synthesis, concretization and interpretation and their software, bringing it to the industrial level. The limited application of this approach may be associated with the problems of transition from general constructs to the existing conceptual diversity of the original field of knowledge, as well as the fact that it can be effectively implemented only by specialists who can work with constructs.
A complete bibliography of publications on conceptual analysis and design from 1967 to 2003 is given in. It presents 742 publications, grouped alphabetically by authors, by publication years and by topic. The author's index covers 189 authors, and the thematic index covers 83 headings.
Innovation potential is based on the results of the first two stages of the innovation cycle, i.e. on the results of fundamental and applied research. These results can be expressed in different forms - from an idea that characterizes the very possibility of practical application, to prototypes provided with technical drawings, production technology, tested and approved in production.
The approved result of research and development work (R&D) and research and development work (R&D) is preferable for use in enterprises, since it gives the opportunity for the development of an enterprise with certain risks. The first type of tested scientific results (the idea of \u200b\u200bresearch and development) is the basis of the innovative potential and is characterized by high risks, which are very difficult to assess in practice. Therefore, such results have a priority development on the basis of public administration, which acts as a venture capitalist.
The results of scientific research, which are planned for the transition to the stage of innovative diffusion, are the basis for a new stage of research, which is characterized by the relevance of performing scientific research in technical, technological and innovative research.
Innovative research determines the ways of transition from research results to innovative diffusion and includes organizational and economic research, the choice of enterprises and organizations for introducing innovations, innovations and innovations into production.
Thus, the peculiarities of innovative development include issues that are characteristic of the early stages of designing technical objects and systems in the techno-material development of the branches of society. The second component of innovative development is innovative research, determined by the choice of an enterprise and the formation of its partnership with a scientific organization, a university, i.e. with the developer of innovation, innovation, innovation.
This approach to organizing the management of innovative development in a region ensures the continuity of the innovation cycle as a necessary condition for the development of innovative activities.
Modeling in the early stages of design is designed to solve the problem of conceptual design, i.e. to determine and use such technical and technological solutions that in the future can provide competitive advantages to the created technical object, system, enterprise, industry and territory (region).
Conceptual modeling has features characteristic of the early stages of design activities (including the idea) and ending with sketch design, which determines the creation of new and promising technical and technological solutions that provide innovative potential with competitive advantages.
The resulting ideas can be: 1) a project; 2) the program; 3) the direction of scientific and experimental design work. Creation of the project based on the received technical and technological solution determines the possibilities of business planning, i.e. obtaining a substantiated organizational and economic work plan. The program includes a process of research, the result of which is a set of interrelated innovative projects. Achievement of organizational and economic efficiency under the program is carried out in stages based on the coordinated implementation of a set of projects. A distinctive feature of the innovation direction is a large proportion of scientific research aimed at finding such technical and technological solutions that can provide competitive advantages for the enterprise in its development. The direction includes programs and projects.
Conducting design work in each of the three areas relies on the intellectual potential of professionals using methods of scientific and technical creativity, and in modern conditions requires support on the basis of information technology to solve non-formalized scientific and technical problems.
Conceptual design, including the search for ideas, is distinguished by the planning of targets, parameters, indicators of the technical object or system being created. From the standpoint of design innovation, a negative result that even has scientific value is considered a failure. According to cognitive psychology, each designer, constructor has his own personal cognitive map, which determines the scheme of his vision of the image of the design object and the process of its implementation, therefore the task is to choose an innovative image of the technical design of the object.
The process of work is associated with the developer's presence of some mental model, which has a current state and is constantly changing in the process of cognition, which is the process of conceptual design with the instrumental use of cognitive models (lat. Cognition - knowledge, cognition). In technical studies, these models are used as simulation models, which are focused on predicting the operator's behavior when interacting with complex technical systems.
Conceptual design is characterized by the expediency of using methods of indirect cognition, i.e. modeling. Characterizing the models used in the early stages of design, we note the priority of attention to the peculiarities of constructing hierarchical structures of modeling, existing information processes, as well as to decision-making.
The study of the problem of structural and parametric synthesis in the design process at early stages from a cognitive standpoint in complex technical systems shows two clearly expressed stages: 1) the stage of structural synthesis and 2) the stage of parametric synthesis describing functioning. The stages include essential links in the cognitive orientation. Computer-aided cognitive modeling improves design efficiency. Structuring, product layout and parameterization tasks seem to be the most promising from the standpoint of cognitive modeling.
For example, when creating a diesel engine, the structure of a product may change insignificantly and the main difficulties will be associated with parametric synthesis. The opposite situation is in the creation of new generation food products and the approximately equivalent importance of structural and parametric syntheses for the construction industry. At the same time, there may be exceptions for each of these industries in terms of the ratio of the problems of structural and parametric synthesis, which is determined by the creation of a flexible production system.
The formation of the structure is carried out heuristically (methods of scientific and technical creativity), or the structure is selected from a set of solutions. Simulating structural and parametric (functional) stages in a single model is both very difficult and can be partially solved only with computer support in the "man-machine" system. At the same time, the parametric stage (functioning) is distinguished by the use of the theory of analysis and similarity. The creation of a theory of functioning for complex technical systems is possible only for certain aspects.
In the early stages of design, rough intermediate layout drawings and similar models (verbal, successive approximation) are used.
Content models are verbal statements of the problem, programs and plans for the development of systems, "trees" of goals, management, design, etc., which widely use a systematic approach based on the concepts of a system, subsystem, structural element, hierarchy, properties (parameters), goals , functions, etc. This allows you to identify the specifics and patterns of complex systems, break down into subsystems and organize their interaction taking into account the influence of the external environment. Further, the possibility of transition to the use of formalized methods appears.
Considering the models used in solving design problems, we can distinguish:
Hierarchical description and strategies for its formation;
Set-theoretic models;
Knowledge representation models: for example: products as a form of knowledge provision; frames; scripts; predicate models; data presentation models.
When designing, a scenario is understood as a system of assumptions about the course of the process under study, on the basis of which one of the possible forecast options is developed, a plan (also a scenario) for the implementation of something is built. First, a baseline scenario is developed, which shows the most likely impact of all events on indicators of well-being, and in parallel a pessimistic scenario is built. Further, to help the manager make an adequate decision, two strategies for proactive action are developed:
With regard to events amenable to control, actions are planned to ensure that desirable events occur and undesirable events do not;
For uncontrollable events, actions are planned to enhance the beneficial effects and mitigate the adverse ones.
The result of this elaboration is the so-called "forced scenario". There are examples of good design scenarios for describing user actions with multiple levels of visual explanation. The results demonstrate how detailed information should be presented for use in responsive interfaces. Scenarios are a way of presenting information and are convenient for presenting stereotyped knowledge that defines typical situations in a particular subject area. In intelligent systems, scripts are used in the procedures for understanding natural language texts, planning behavior, making decisions, and increasing the effectiveness of learning.
This approach to design in the early stages from the standpoint of cognitive modeling provides the very possibility of conducting an innovative development strategy. At the same time, it is possible to push aside the development strategy according to the imitation model, which is developed in Russian society. When creating computer support for the conceptualization process, it is necessary to actively use the intellectual potential of professionals from different fields of knowledge, scientific organizations, enterprises, and industries.
Cognitive modeling of technical and technological objects and systems determines the possibility of an integrated linkage in information technology of three components: 1) conceptualization; 2) structuring and 3) parameterization. Conceptualization should be purposeful, which implies the application of categorical analysis and paradigm theory.
With the cognitive orientation of structuring, the possibility of generating new invariant structures is determined.
On the basis of verbal models, through the creation of flowcharts, the design process enters the layout, which is performed by a specialist, and it must be provided with a personalized support system. For the parameterization of product components, integration work is characteristic, which determines the appropriateness of the use of cognitive computer graphics. Conceptual design is of a collective nature, which determines the features of information technology to support this activity.
It should be noted that the earlier the design stage (idea stage) is considered, the more competitive the created product, technical object or system, technology can be.
The approaches and models used in the creation of technical systems can be used in the analytical management system not only for the development of technical and technological solutions, but also for the development of solutions for systemic management of the innovative development of an organization, enterprise, industry, region.
The development of innovative potential is characterized by the "university - industry" system, since it is necessary to combine the knowledge of these two spheres of knowledge.
Basic concepts, classification
7.2. Conceptual design using IDEF1X methodology
Concept design goal - creation of a conceptual data schema based on ideas about the subject area of \u200b\u200beach separate type of user. Conceptual diagram is a description of the main entities (tables) and the relationships between them without taking into account the adopted database model and the syntax of the target DBMS. Often, such a diagram displays only the names of entities (tables) without specifying their attributes. User view includes data required by a specific user to make decisions or perform some task.
Below is the sequence of steps in conceptual design [,].
1. Selection of entities.
The first step in building a conceptual data schema is to identify the main objects (entities) that may be of interest to the user and, therefore, should be stored in the database. In the presence of a functional model, the prototypes of such objects are inputs, controls and outputs. It is even better to use for these purposes. In this case, the prototypes of objects will be data storage devices. As noted above, the data collector is a collection of tables (a set of objects) or directly a table (an object). For a more detailed definition of the set of basic objects, it is also necessary to analyze the data flows and all the methodological material required to solve the problem. For example, for the problem of determining the permissible speeds, the main objects (sets of objects) are: regulatory and reference information, information about road sections, calculation tasks, lists of permissible speeds, etc. During the analysis and design of the information model, the sets of objects should be detailed. For example, a composite object "information about road sections", taking into account the specifics of the problem being solved, requires a breakdown into separate components: sections, tracks, separate points, mileage, plan, superstructure, etc.
Possible difficulties in identifying objects are associated with the use of the task by the task managers:
Examples and analogies when describing objects (for example, instead of the generalizing concept of "employee", they can mention his functions or position: "manager", "responsible", "controller", "deputy");
Synonyms (eg "allowable speed" and "set speed", "development" and "project", "barrier location" and "speed limit");
Homonyms (for example, “program” can mean a computer program, a work plan or a TV program).
It is not always obvious what a particular object is - an entity, a relationship or an attribute. For example, how should “married marriage” be classified? In practice, this concept can reasonably be attributed to any of the above categories. Analysis is a subjective process, so different developers can create different but perfectly valid interpretations of the same fact. The choice of an option is largely dependent on the common sense and experience of the designer.
Each entity must have some properties:
Must have a unique name and the same interpretation must always apply to the same name;
Have one or more attributes that either belong to an entity or are inherited through a relationship;
Have one or more attributes (primary key) that uniquely identify each instance of the entity, i.e. make each row of the table unique;
It can have any number of connections with other entities.
The IDEF1X graphic notation uses the notation shown in the following figure to represent an entity.
 |
||
| a) independent | b) dependent |
Figure: 7.1. Entities
The essence of the IDEF1X methodology is independent (strong, parental, dominant, owner) if an entity does not depend on the existence of another entity (in other words, each instance of an entity can be uniquely identified without defining its relationships with other entities, or the uniqueness of an instance is determined only by its own attributes). The entity is called dependent (weak, child, subordinate) if its existence depends on the existence of other entities. The terminology "parent" - "child" and "owner" - "subordinate" can also be used in relation to two dependent entities, if instances of one of them (child, subordinate) can be uniquely determined using instances of the other (parent, owner), despite to the fact that the second essence, in turn, depends on the third essence.
2. Definition of attributes.
Typically, attributes are specified only for entities. If the relationship has attributes, then this indicates the fact that the relationship is an entity. The easiest way to define attributes is after identifying an entity or a relationship, asking yourself the question "What information needs to be stored about ...?" Various paper and electronic forms and documents used in the organization to solve a problem can significantly help in defining attributes. These can be forms containing both initial information (for example, "List of elevations of the outer rail in curves"), and the results of data processing (for example, "Form No. 1").
The identified attributes can be of the following types:
Simple (atomic, indivisible) - consists of one component with independent existence (for example, "employee position", "salary", "rate of unredeemed acceleration", "curve radius", etc.);
Composite (pseudo-atomic) - consists of several components (for example, “full name”, “address”, etc.). The degree of atomicity of attributes, embedded in the model, is determined by the developer. If the system is not required to sample all clients with the surname Ivanov or those living on Komsomolskaya Street, then the composite attributes can not be divided into atomic;
Unambiguous - contains only one value for one instance of the entity (for example, a curve in plan can have only one value for the radius, angle of rotation, elevation of the outer rail, etc.);
Multiple - contains several values \u200b\u200b(for example, one branch of the company may have several contact phones);
Derived (calculated) - the value of an attribute can be determined by the values \u200b\u200bof other attributes (for example, "age" can be determined by the "date of birth" and the current date set on the computer);
Key - serves to uniquely identify an entity instance (included in the primary key), quickly search for entity instances, or set a relationship between instances of parent and child entities;
Non-key (descriptive);
Mandatory - when entering a new instance in an entity or editing, a valid attribute value must be specified, i.e. after these actions, it cannot be NOT NULL. The attributes included in the entity's primary key are required.
After defining the attributes, set them domains (ranges) , eg:
Site name - a set of letters of the Russian alphabet, no more than 60 characters long;
Curve rotation - allowable values \u200b\u200b"L" (left) and "P" (right);
Curve radius - positive number, no more than 4 digits.
Defining domains defines the set of valid values \u200b\u200bfor an attribute (multiple attributes), and the type, size, and format of the attribute (attributes).
Based on the selected set of attributes for an entity, a set of keys is determined. Key - one or more attributes of an entity that serve to unambiguously identify its instances, quickly find them, or set a relationship between instances of parent and child entities. Keys used to uniquely identify instances are of the following types:
- superkey - an attribute or set of attributes that uniquely identifies an entity instance. The superkey can contain "extra" attributes that are not required to uniquely identify the instance. With the correct design of the database structure, the superkey in each entity (table) will be the full set of its attributes;
- potential key - a superkey that does not contain a subset that is also a superkey of this entity, i.e., a superkey that contains the minimum required set of attributes that uniquely identify an entity instance. An entity can have multiple potential keys. If a key consists of several attributes, then it is called a composite key. Among the entire set of potential keys for the unique identification of instances, one is selected, the so-called primary key, which is subsequently used to establish relationships with other entities;
- primary key - a potential key that is chosen to uniquely identify instances within an entity;
- alternative keys - potential keys that are not selected as the primary key.
Let's look at an example. Suppose you have a table containing student details with the following columns:
Surname;
Middle name;
Date of Birth;
Place of Birth;
Group number;
Pension insurance certificate number (NPS);
Passport ID;
Date of issue of the passport;
Organization that issued the passport.
For each instance (record), the entire set of attributes can be selected as a superkey. Potential keys (unique identifiers) can be:
Pension insurance certificate number;
Passport ID.
The set of attributes "Surname" + "First name" + "Patronymic" could be selected as a unique identifier, if the probability of two full namesakes studying at a university would be equal to zero.
If in essence there is no combination of attributes suitable for the role of a potential key, then a separate attribute is added to the entity - surrogate key (artificial key, surrogate key) ... As a rule, the type of such an attribute is chosen either symbolic or numeric. Some DBMSs have built-in tools for generating and maintaining surrogate key values \u200b\u200b(for example, MS Access). It is also worth noting that some developers, instead of searching for potential keys and choosing the primary one from them, add an artificial attribute to each entity, which is later used as the primary key.
If there are several potential keys, then it is recommended to adhere to the following rules for choosing a primary key:
The number of attributes included in the key should be minimal (it is desirable that the key is atomic, i.e., it consists of one attribute);
The key size in bytes should be as short as possible;
Key domain type is numeric. When choosing character attributes in a key, problems often arise with entering erroneous values \u200b\u200b(they confuse the case of letters; add extra spaces; use letters written in different languages \u200b\u200bthe same). Numeric attributes are less likely to enter a value error;
The probability of changing the key values \u200b\u200bwas the smallest (for example, "Pension insurance certificate number" is a more constant parameter than "INN" or "Passport number");
The easiest way to work with the key is for users (for example, "Pension insurance certificate number" is a set of 11 digits, and "Passport number" depends on its type: a citizen of the USSR, a citizen of the Russian Federation or foreign).
If a certain attribute (set of attributes) is present in several entities, then its presence usually reflects the presence of a relationship between instances of these entities. In each relationship, one entity acts as a parent, and the other as a child. This means that one instance of the parent entity can be associated with multiple instances of the child. To support these relationships, both entities must contain sets of attributes by which they are related. In the parent entity, this is the primary key. To model a relationship in a child entity, there must be a set of attributes corresponding to the primary key of the parent. This set of attributes in a child entity is usually called foreign key .
In IDEF1X notation, attributes are displayed as a list of names within an entity block. The attributes defining the primary key are placed at the top of the list and separated from other attributes by a horizontal bar. The preliminary identification of attributes using the example of two entities is shown in the following figure.

Figure: 7.2. Examples of entities
The independent entity "Plots" has a surrogate key assigned as the primary key, while the dependent entity "Plan" has a composite primary key consisting of five attributes.
3. Definition of connections.
The most typical types of relationships between entities are:
Relations of the "part-whole" type, usually defined by the verbs "consists of", "includes", etc .;
Classifying relationships (for example, "type - subtype", "set - element", "general - particular", etc.);
Industrial relations (for example, "boss-subordinate");
Functional connections, usually defined by the verbs "produces", "influences", "depends on", "calculated by", etc.
Among them, only those links are distinguished that are necessary to meet the requirements for database development.
Communication is characterized by the following set of parameters:
Name - indicated as a verb and determines the semantics (semantic background) of the relationship;
Multiplicity (cardinality, cardinality): one-to-one (1: 1), one-to-many (1: N) and many-to-many (N: M, N \u003d M or N<> M). The multiplicity shows how many instances of one entity are determined by the instance of another. For example, on one site (described by the "Sites" table row) there can be one, two or more paths (each path is described by a separate line in the "Paths" table). In this case, the relationship is 1: N. Another example: one path passes through several separate points and several paths can pass through one separate point - N: M relationship;
By type: identifying (attributes of one entity, called a foreign key, are part of the child and serve to identify its instances, i.e. are included in its primary key) and non-identifying (the foreign key is present in the child entity, but is not included in the primary key );
Mandatory: mandatory (when entering a new instance in a child entity, filling in the foreign key attributes is mandatory and the entered values \u200b\u200bmust match the values \u200b\u200bof the primary key attributes of any instance of the parent entity) and optional (filling in foreign key attributes in the child entity instance is optional or the entered values \u200b\u200bdo not match with the values \u200b\u200bof the primary key attributes of no instance of the parent entity);
The degree of participation is the number of entities participating in the relationship. Basically, there are binary links between entities, i.e. associations linking two entities (the degree of participation is 2). For example, a Parcel consists of Paths. At the same time, according to the degree of participation, the following types of connections are possible:
o unary (recursive) - an entity can be associated with itself. For example, the table "Employees" may contain records for both subordinates and their superiors. Then the relationship "boss" - "subordinate", defined on one table, is possible;
o ternary - connects three entities. For example, “Student” at “Session” received a “Discipline Assessment”;
o quaternary, etc.
In the IDEF1X methodology, the degree of participation can only be unary or binary. Connections are mostly reduced to a binary form.
The appearance of a link in IDEF1X diagrams indicates its strength, type, and obligation.
Table 7.1. Link types
| Appearance | Communication type and required | Communication power right |
| 1 | ||
| Mandatory, identifying | 0 .. ∞ | |
Z |
Mandatory, identifying | 0 or 1 |
P |
Mandatory, identifying | 1 .. ∞ |
<число> |
Mandatory, identifying | <число> |
| Mandatory, non-identifying | 0 .. ∞ | |
| Optional, non-identifying | 0 .. ∞ |
Notes.
1. An identifying link is displayed with a solid line, a non-identifying one - with a dashed line.
2. Optional is indicated by a diamond.
The following figure shows examples of how links are displayed.
a) identifying

b) non-identifying

c) recursive

Figure 7.3. Link examples
In fig. 7.3b communication is optional, since some employees do not have to be included in any department (for example, the director of an enterprise), and non-identifying, since the personnel number is unique for each employee.
4. Definition of superclasses and subclasses.
In cases where two or more entities differ insignificantly from each other in terms of the set of attributes, you can use a construction in the model - an inheritance (category) hierarchy, which includes superclasses and subclasses.
Super class - an entity that includes subclasses.
Inheritance hierarchy is a special type of association of entities that share common characteristics. For example, an organization has full-time employees (permanent employees) and part-time employees. From their common properties, you can form a generic entity (generic ancestor) "Employee" (Figure 7.4) to represent information common to all types of employees. Information specific to each type can be located in additional entities (descendants) "Permanent employee" and "Part-time employee".

Figure: 7.4. Inheritance Hierarchy (Incomplete Category)
Usually, a hierarchy of inheritance is created when several entities have common attributes, or when entities have common relationships (for example, if "Permanent Employee" and "Part-Timer" would have a similar relationship "works in" with the entity "Organization" ).
Each category requires specifying discriminator - a generic ancestor attribute that shows how to distinguish one entity from another. In the given example, the discriminator is the "Type" attribute.

AT full category one instance of a generic ancestor necessarily corresponds to an instance in some descendant, that is, in the example, the employee is necessarily either a part-time employee, or a consultant, or a permanent employee.
When building a model, various combinations of full and incomplete categories are possible. For example, the first level of a category is incomplete, the individual entities of which are supplemented by a second level - a complete category.
7.3. An example of building a conceptual diagram
The following figure shows a fragment of the conceptual diagram of an information model for the problem of determining allowable speeds, built using ERwin v9.2.

Figure: 7.6. Fragment of the conceptual diagram of the information model
The following logical data blocks are highlighted in the conceptual diagram:
Regulatory reference information;
Information about road sections;
Calculation task;
Statement of permissible speeds;
Draft Order "N" (not shown in Fig. 7.6);
Forms No. 1, 1a and 2 (not shown in Fig. 7.6).
All entities included in the blocks (except for the "Regulatory reference information" block) are represented in the fragment only by their names. The entities included in the "Reference information" block are shown expanded, ie including all attributes and primary keys. In this block there are two entities ("Guidelines for mating curves" and "Allowable speeds on the slope of the elevation retraction in curves"), which are not associated with any other entity. This is not an error, since there is an opinion that the database schema should be a connected graph (all entities should be interconnected). For most tasks, where various operational information is accumulated in the database, and then various reports and summaries are formed on the basis of it, such a statement really takes place. But for engineering, optimization and some other tasks, there may be unrelated tables. In this example, two unrelated entities participate in each calculation of allowable speeds, that is, they affect the results displayed in the lists of allowable speeds. But given the specifics of the problem, changing the contents of these tables should not lead to a change in the results already obtained. Therefore, the tables are not associated with either calculation tasks or calculation results.
The main activity of the Method Company from the moment of its foundation to the present time is the development of inventing computer programs based on conceptual design methods technical systems.
Conceptual design is a separate type of project activity. Its result is the variants of the concepts of the designed technical system (TS) as a whole, and its individual parts.
The TS concept has various forms of presentation, differing in the level of elaboration (specificity). It:
Functional diagram, which indicates a set of TS elements that perform a particular technical function, and the way of their interaction.
Operating principle, which determines the relationship between physical (chemical, etc.) phenomena occurring in the vehicle at different stages of its life cycle.
The principle of change, indicating how to change materials, design, modes of operation and interaction of the device with the environment in order to improve its performance.
Structural scheme, which determines the composition of the vehicle, the relative position and relationship between its elements, features of their design, materials used, the optimal ratio of the parameters of the elements and other essential features. Usually, for the sake of brevity, the design scheme of the vehicle is presented in the form distinctive formula... It lists only those design features that distinguish the designed vehicle from its prototype.
The main volume of conceptual design tasks has to be solved at the early stages of the vehicle development: during the development of a concept - project and preliminary design. In other words, when the appearance of the future product is determined. However, in the future, at the stages of detailed design, testing, and launching into production, developers are faced with complex technical problems. Eliminating them also requires conceptual design techniques.
The place and scope of conceptual design as a separate search procedure is explained by the following diagram.
Conceptual design is an essential part of the new product creation process. Ultimately, it is the number of developed concepts of the future product that determines its novelty and quality, and therefore its competitiveness and sales volume.
Practical application of conceptual design methods has shown that they are indispensable in solving problems such as:
- development of new devices and technologies;
- improving quality and reducing production costs;
- forecast of the development of a specific field of technology;
- obtaining priority in a given technical field;
- management of knowledge and intellectual property of the enterprise.
Invention and Concept Design
Invention and conceptual design are related activities, differing mainly in their objectives.
Invention is an individual initiative activity. The aim of the inventor is to create an invention, i.e. technical solution with world novelty... Invention, as a form of human activity, is akin to art. Therefore, very often the creation of an invention carries element of chance... Many remarkable inventions appear "neither then" and "not there", as required by real production. This is one of the main reasons for the difficulties in putting the invention into practice.
The random nature of invention can delay the development of technology not for years, but for millennia! For example, the ancient Greeks knew all the elementary technical devices that Edison used in his phonograph to record and reproduce sound. They knew about the properties of strings to vibrate when the wind blows, about the vibration of drum membranes, used levers to increase strength, and used wax-coated tablets to write words. However, they could not combine all this knowledge together in one device. By the way, Edison also owes a lucky break to the invention of the phonograph.
Unlike invention, conceptual design is planned production activities... Its goal is to solve a technical problem that was presented to the developers within a given time frame. In this case, usually, the task is not set to find a fundamentally new technical solution, i.e. invention.
If a technical solution is found after the specified period, then, as a rule, it is practically impossible to implement it. The use of such a solution in the current project is impossible, since lost time. In the next project of a similar product, this solution also usually does not have a place, because new requirements and new solutions appear.
The goal of conceptual design - to ensure the systematic solution of a technical problem - is achieved through the use of modern information technologies. Unlike invention, which is dominated by human creativity, conceptual design is, first of all, technology. It is she who allows guarantee the desired result in a timely manner.
TRIZ and conceptual design
TRIZ - the theory of inventive problem solving - was developed by G.S. Altshuler. and his students in the USSR during the 50s - 80s of the last century. This methodology is being successfully developed at the present time. TRIZ methods are used by both individual inventors and consulting firms in many countries of the world.
TRIZ and conceptual design are related methodologies. They have the same goal - a planned, purposeful solution to technical problems, but different methods.
The main arsenal of TRIZ is heuristic methods, consisting of special algorithms, instructions, guidelines, etc., which are focused on human use. TRIZ methods help an inventor to analyze a technical problem, come up with a solution and expand its scope.
The wider use of TRIZ methods in engineering practice is limited by the need pre-training... It is possible to master these methods at the proper level only after long-term training in special courses from an experienced teacher.
The corresponding response to the problem of learning was the creation of computer programs that implement the TRIZ methods. However, this does not completely avoid pre-training. In these programs, the computer is used as an aid. With its help, the inventor mainly records the results of solving a technical problem and also finds suitable heuristics and technical examples. When working with such computer programs, the inventor must perform the entire scope of creative operations himself.
Conceptual design uses formal methods and large knowledge base, which can only be implemented in the form of computer programs. The user does not need to know what methods (algorithms) are used in these programs. It is enough for him to indicate a technical problem, press the "Solve" button and choose the best solution from the found solutions. Thus, conceptual design methods allow any engineer to purposefully solve technical problems without prior methodological training.
Despite these differences, the TRIZ approaches and conceptual design do not exclude, but complement each other. TRIZ methods are irreplaceable when looking for directions for solving a technical problem. They help the engineer move from a complex technical problem to typical inventive problems. After that, you can apply conceptual design techniques. Even now, inventive programs based on conceptual design methods can solve some inventive problems of moderate complexity. This is provided by extensive databases specific engineering knowledge and complex formal algorithms that are used in these programs.
In addition, as our experience shows, the best results when working with modern inventive programs are achieved by engineers who know TRIZ.
To this we must add that it will never be possible to fully formalize the entire process of solving technical problems. Obviously, over time, the scope of application of inventive computer programs will expand, but they will never completely replace humans in this matter. And this is not caused by the fact that some mathematical problems have not yet been solved or that existing computers lack speed and memory. There is only one problem: the computer doesn't invent because it doesn't want to!
Send your good work in the knowledge base is simple. Use the form below
Students, graduate students, young scientists using the knowledge base in their studies and work will be very grateful to you.
Posted on http://www.allbest.ru/
Introduction
1. Conceptual design
1.1 Defining entity types
1.2 Defining attributes and associating them with entity types
1.3 Defining Attribute Domains
1.4 Understanding Alternate and Primary Keys
2. Logical design
2.1 Converting a Locally Conceptual Data Model to a Local Logical Model
2.2 Validating Models Using Normalization Rules
2.3 Model Validation for User Transactions and Query Execution
2.4 Building the final entity relationship diagram
Conclusion
List of used literature
Introduction
Database is a set of independent materials (articles, calculations, regulations, court decisions and other similar materials) presented in an objective form, systematized in such a way that these materials can be found and processed using an electronic computer (computer).
The DBMS hides sequential table scans from the user and performs them in the most efficient way. A very important feature of relational systems is that the result of executing any query to database tables is also a table that can be saved in the database and / or against which new queries can be executed. design concept key
The main purpose of information systems is to store information about the surrounding world and the processes occurring in it, which are ultimately provided to users. Since for various groups of people only certain parts of the real world are of interest, then the data of each information system will refer to a certain area. The part of a real system that is subject to research in order to describe it is called a subject area.
Distinguish between a complete subject area and its fragments, while each fragment can represent its own subject area. For example, the following fragments can be distinguished for a university: educational department, accounting department, personnel department, schedule bureau, etc.
The information required to describe the subject area may include information about people, objects, documents, events, concepts, etc.
Each subject area is characterized by a multitude of objects - elements of real systems and processes that use objects, as well as a multitude of users, characterized by a single view of the subject area. In particular, for accounting, objects are all kinds of documents. Accounting processes - payroll accounting, material accounting, accounting of banking operations, etc. Finally, the users of this fragment are accounting employees, employees of financial authorities, company managers, etc.
Each object has a certain set of properties that are stored in the information system. When processing data, you often have to deal with a set of homogeneous objects, for example, such as students or faculties, and record information about the same properties for each of them. A collection of objects that have the same set of properties is called an object class. For objects of the same class, the set of properties will be the same, although the values \u200b\u200bof these properties for each object may be different.
An entity class is often referred to as an entity. Each entity has attributes. An attribute is a property of an object that characterizes its instance. The entity "student" can have the attributes "name", "year of birth", "date of admission", etc. Thus, an entity can be defined as a set of individual objects of the same type (instances), and all these objects are different, that is The set of attributes is the same, but their values \u200b\u200bare different.
The goal of my work is to develop a database for accounting of sales and deliveries of goods of sets and PC components. It will also be used to record the movement of goods between the supplier and the recipient.
Work tasks:
Define entity types
Define link types
Define attributes and associate them with entities
Define attribute domains
Define alternate keys (attributes)
Create an entity relationship diagram
Convert a Locally Conceptual Model to a Local Logical Data Model
Validate Models Using Normalization Rules
Validate the model against user transactions and execute queries
Build the final entity relationship diagram
1. Conceptual design
Conceptual (infological) design is the construction of a semantic model of the subject area, that is, an information model of the highest level of abstraction. Such a model is created without focusing on any specific DBMS and data model. The terms "semantic model", "conceptual model" and "infological model" are synonymous. In addition, in this context, the words "database model" and "domain model" (for example, "conceptual database model" and "conceptual domain model") can be used equally, since such a model is both an image of reality and an image a projected database for this reality.
The specific type and content of the conceptual database model is determined by the formal apparatus chosen for this. Graphical notations similar to ER diagrams are commonly used.
Most often, the conceptual database model includes:
Description of information objects or concepts of the subject area and the connections between them.
Description of integrity constraints, i.e. requirements for admissible data values \u200b\u200band relationships between them.
1.1 Defining entity types
An entity is any distinguishable object (an object that we can distinguish from another), information about which needs to be stored in a database. Entities can be people, places, airplanes, flights, taste, color, etc. It is necessary to distinguish between concepts such as entity type and entity instance.
Essence is a collective concept, some abstraction of an actually existing object, process, phenomenon, or some idea of \u200b\u200ban object, information about which needs to be stored in a database.
It is necessary to distinguish between concepts such as entity type and entity instance. Entity type refers to a set of homogeneous individuals, objects, events, or ideas that act as a whole. An entity instance refers to a specific thing in a collection. For example, an entity type can be CITY, and an instance can be Moscow, Kiev, etc.
There are three types of entities: core, associative (association) and characteristic (characteristic). In addition, a subset of designations is also defined in the set of associative entities. Let us now define the types of entities.
Core essence.
Core (strong) entity is an entity independent of others. The core entity cannot be an association, characteristic or designation (see below).
Association.
An associative entity (or association) expresses a many-to-many relationship between two entities. It is a completely independent entity. For example, between the entities MAN and WOMAN, there is an associative relationship expressed by the associative entity MARRIAGE.
Characteristic.
A characteristic entity is also called a weak entity. It is associated with a stronger entity with one-to-many and one-to-one relationships. A characteristic entity describes or clarifies another entity. She is completely dependent on her and disappears with the disappearance of the latter.
Designation.
A designation is an entity with which other entities are related on a many-to-one or one-to-one basis. Designation, in contrast to characteristics, is an independent entity. For example, the entity Faculty denotes the student's belonging to this department of the institute, but it is completely independent.
Determining communication types
Communication is a graphically depicted association established between two types of entities. Like an entity, a relationship is a typical concept; all instances of both associated entity types obey the established binding rules. Therefore, it is more correct to talk about the type of relationship established between entity types, and about instances of the relationship type established between instances of the entity type. In the variant of the ER model discussed here, this association is always binary and can exist between two different types of entities or between an entity type and itself (recursive relationship). In any relationship, two ends are distinguished (in accordance with the existing pair of linked entities), each of which indicates the name of the end of the relationship, the degree of the end of the relationship (how many instances of a given type of entity must be present in each instance of a given type of relationship), the obligatory relationship (i.e. . whether any instance of a given entity type should participate in some instance of a given relationship type).
The connection is represented as. In this case, in the place of "docking" of the relationship with the entity, the following are used:
A three-point entry into the entity rectangle if multiple entity instances can (or should) be used for this entity in the relationship;
A single point entry if only one instance of an entity can (or should) participate in a relationship.
The required end of the link is shown with a solid line, and the optional end with a broken line.
The connection between the entities TICKET and PASSENGER, connects tickets and passengers. The end of the link with the name "for" allows you to associate more than one ticket with one passenger, and each ticket must be associated with a passenger. The end of the connection with the name "has" indicates that each ticket can belong to only one passenger, and the passenger is not required to have at least one ticket.
Figure: 1. Link type example
· Each TICKET is for one and only one PASSENGER;
· Each PASSENGER can have one or more TICKETS.
Recursive link
The following example (Fig. 2) shows a recursive relationship connecting the MAN entity to itself. The end of the connection with the name "son" defines the fact that several people can be sons of the same father. The end of the connection with the name "father" means that not every man should have sons.
Figure: 2. An example of a recursive link type
The laconic oral interpretation of the diagram shown is as follows:
Every MAN is the son of one and only one MAN;
Each MAN can be the father of one or more MEN.
Types of relationships between tables
Communication allows you to model relationships between objects in the domain.
There are 4 types of links:
1. " One to one" - any instance of entity A corresponds to only one instance of entity B, and vice versa.
Any particular student can only have one characteristic, and that characteristic refers to a single student.
2. " One-to-many" - any instance of entity A corresponds to 0, 1 or several instances of entity B, but to any instance of entity B there corresponds only one instance of entity A.
The student is given many grades; only one student has a given grade.
3. " Many-to-one" - any instance of entity A corresponds to only one instance of entity B, but any instance of entity B corresponds to 0, 1, or several instances of entity A.
The teacher works only in one office, however, the office can be assigned to several teachers.
4. " Many-to-many" - any instance of entity A corresponds to 0, 1 or several instances of entity B, and any instance of entity B corresponds to 0, 1 or several instances of entity A.
Pupil Ivanov is studying with several teachers. And each teacher works with many students.
1.2 Defining attributes and linking them to entity types
An attribute of an entity is any detail that serves to clarify, identify, classify, quantify, or express the state of an entity. Attribute names are written in the entity box under the entity name and are displayed in small letters, possibly with examples.
An example of the HUMAN entity type with the specified attributes is shown in (Fig. 3) From a technical point of view, the entity type attributes in the ER model are similar to the relationship attributes in the relational data model. In both cases, the introduction of named attributes introduces some generic data structure, the name of which is the same as the name of the entity type in the case of the ER model or the name of the relation variable in the case of the relational model. This generic structure must be followed by all instances of an entity type or all tuples of a relation.
Figure: 3. Example of an entity type with attributes
When defining attributes of an entity type in the ER model, specifying the domain of the attribute is optional, although it is possible (see below). Let us discuss the reason for this possibility of a "relaxed" attribute definition. First of all, semantic data models are used to build conceptual database schemas, and these schemas are converted into relational database schemas that are supported by a particular DBMS.
As noted above, when defining the type of an entity, you must ensure that each instance of an entity is distinguishable from any other instance of the same entity. Since an entity is an abstraction of a real or represented object of the external world, this requirement must be borne in mind when choosing a candidate for entity types. The unique identifier of an entity can be an attribute, a combination of attributes, a relationship, a combination of relationships, or a combination of relationships and attributes that uniquely distinguishes any instance of an entity from other instances of the same type of entity. Here are some examples. Figure 4 shows the BOOK entity type suitable for use in the bookstore database. When publishing any book in any publishing house, it is assigned a unique number - ISBN. It is understood that the value of the isbn attribute will uniquely identify the batch of books in stock. In addition, of course, the combination of attributes is also suitable as a unique identifier<автор, название, номер издания, издательство, год издания>.
Figure: 4 An entity type whose instances are identified by attributes
In Figure 5, the diagram includes two related entity types. Each adult has one and only one, and each passport can only belong to one adult. Then the person's connection with his passport uniquely identifies the adult, that is, roughly speaking, the passport defines the adult. Since there may be passports that have not yet been issued to any person, this relationship is not a unique identifier for the PASSPORT entity.
Figure: five The type of entity whose instances are identified by the relationship
In Figure 6, the diagram includes three related entity types. Professors have knowledge in several academic disciplines. The teaching of each discipline is available to several professors. In other words, a many-to-many relationship is defined between the entities PROFESSOR and DISCIPLINE. Each professor can prepare courses in any discipline available to him. Several training courses can be devoted to each discipline. But each professor can prepare only one course in any discipline available to him, and each course can be devoted to only one discipline. Thus, each instance of the COURSE entity type is uniquely identified by the PROFESSOR entity instance and the DISCIPLINE entity instance, i.e., by a pair of relationships with the names of the ends PREPARED and DEDICATED on the COURSE entity side. Note that the entities PROFESSOR and DISCIPLINE are not identified by links.
Figure: 6. An entity type whose instances are identified by a combination of relationships
Finally, Figure 7 shows an example of an entity type whose unique identifier is a combination of attributes and relationships. Every person can have children, and every person has a father. Then, if we assume that twins born at the same time are not given the same names, then a combination of attributes can be a unique identifier of the HUMAN entity type.
Figure: 7. An entity type whose instances are identified by a combination of attributes and relationships
1.3 Defining Attribute Domains
Domain in a relational data model, a data type, that is, a valid set of values.
The concept of a data type is fundamental; every value, every variable, every parameter, every read statement, and especially every relational attribute is of one type or another.
Examples are integer (set of all integers), string (set of all strings), part number (set of all part numbers), etc. Thus, when we say that the attribute of type "whole", we mean that all values \u200b\u200bof this attribute belong to the set "whole" and no other.
By analogy with mathematics, data types are divided by scalar and non-scalar... A non-scalar value (non-scalar value) has many user-visible components, but a scalar value (scalar value) does not. Examples of non-scalar types are relation type and tuple type; an example of a scalar type is the integer type.
The limitations of the implementation of database systems on computers impose some convention on the definition of types. So, theoretically, the INTEGER type is a set all possible integers, however, in fact, INTEGER is the set of all integers that can be represented in the considered computer system (since, of course, there are integers that exceed the representability of any computer system).
It is necessary to distinguish between the type as such (logical concept) and the format of the physical representation of values \u200b\u200bof this type in a particular computer system; types refer to level logical model, and the physical representation of the values \u200b\u200b- to the level implementation... For example, operations defined for type "string" do not make sense for type "number", even if numbers in a particular implementation are physically represented as strings. Values \u200b\u200bof type "date" are often physically represented by a real number, but most of the operations that make sense for the type "number" are meaningless for the type "date".
The relational data model does not prescribe the mandatory support of any predefined types, with the exception of the boolean type (BOOLEAN), which is impossible to do without when performing operations. Usually a certain set of types is supported by the system, other types can be designed additionally by the user.
1.4 Understanding Alternate and Primary Keys
Firstprivate key - in the relational data model, one of the potential keys of the relationship, selected as the primary key (or the default key).
If a relationship has a single candidate key, that is also the primary key. If there are several potential keys, one of them is chosen as the primary, and the others are called " alternative".
From the point of view of theory, all potential keys of the relation are equivalent, that is, they have the same properties uniqueness and minimality... However, one of the potential keys is usually chosen as the primary one, which is most convenient for certain practical purposes, for example, for creating foreign keys in other respects or for creating a clustered index. Therefore, as the primary key, as a rule, the one that has the smallest size (of physical storage) and / or includes the smallest number of attributes is chosen.
1.6 Building an entity-relationship diagram
2. Logical design
Logical database design It is the process of constructing models of the information structure of an enterprise, which can be performed in accordance with the requirements of the selected information organization scheme. However, the created logical model does not depend on the features of specific DBMS and other physical conditions of implementation.
2.1 Converting a Locally Conceptual Data Model to a Local Logical Model
1. The first step is to remove the many-to-many relationship. Such a relationship exists between the entities "Set" and "Company customer". Let's break these connections by introducing an intermediate entity "List"
2. Removing complex links. Complex relationships are relationships in which three or more types of entities participate. There are no such connections in my work.
3. Removing recursive links. Recursive links are links in which entities interact themselves with failure. There are no such connections in my work.
4. Removing links with attributes.
5. Removing multiple attributes in my work there is one multiple attribute - phone. Let's divide "recipient's phone" into "recipient's home phone" and "recipient's mobile phone". "Supplier phone" to "supplier mobile phone" and "supplier home phone".
6. Removal of redundant links. There are no such connections in my work.
2.2 Validating Models Using Normalization Rules
Relational database design technology is associated with the theory of normalization based on the analysis of functional dependencies between the attributes of relations. The concept of functional dependency is fundamental to relational database normalization theory. Functional dependencies define stable relationships between objects and their properties in the considered subject area. That is why the process of supporting functional dependencies specific to a given domain is fundamental to the design process.
In the theory of relational databases, the following sequence of normal forms is usually distinguished:
1.1 normal form
2.2 normal form
3.3 normal form
First Normal Form (1NF)
A relation variable is in first normal form (1NF) if and only if, in any valid value of the relation, each of its tuples contains only one value for each of the attributes.
In a relational model, a relationship is always in first normal form by the definition of a relationship. As for the various tables, they may not be correct representations of relations and, accordingly, may not be in 1NF.
Second normal form (2NF)
A relation variable is in second normal form if and only if it is in first normal form, and each non-key attribute is irreducibly (functionally complete) dependent on its potential key.
Third normal form (3NF)
A relation variable is in third normal form if and only if it is in second normal form, and there are no transitive functional dependencies of non-key attributes on key ones.
2.3 Model Validation for User Transactions and Query Execution
1. Information about the available components of the specified source;
SELECT accessories. component name, supplier. supplier name, accessories, supplier number
FROM accessories, supplier
WHERE supplier company, supplier name "AMD"
AND supplier company, supplier company number \u003d components, supplier company number;
2. Information about the kits ordered by a specific customer with an index of the recipient's name;
SELECT kit, kit name, list, kit number, customer's company number, customer's company, customer's company name, recipient, recipient's full name
FROM kit, list, customer, recipient
WHERE customer company, customer company name - "Intercom"
AND list is kit-kit number. set number AND list, ordering company number \u003d ordering company, ordering company number AND recipient, recipient number \u003d package number of recipient;
2.4 Building the final diagram" Essence connection"
Conclusion
In this course work, I developed a database for automating the work of a computer salon. At the initial stage, I made a domain model, which needs to identify the objects that are of the greatest interest to users. To do this, I compiled a detailed description of the domain and the relationships that exist between these objects, checked my model for the presence of such types of relationships as complex, recursive, relationship with attributes, separated many to many relationships, and also defined entity types and attribute types, and based on this data, I built an entity-relationship diagram
At level 2, I did link checking and model checking using normalization rules. My data model was in the first and second normal forms, I brought the model into 3 normal form by finding transitive dependencies and transferring them to another entity (list). I validated the model for user transactions and query execution, and then built the final entity-relationship diagram. Based on the work I have done, I can say that my database will be of great help in the work of a computer salon.
List of used literature
1. Databases. Textbook A.D. Khomonenko
2. Veiskos J. Effective work with MS Access 2000
3. Wikipedia
4. Date CJ. Introduction to the Database System
Posted on Allbest.ru
...Similar documents
Initial data for the design of a complex of production of paints and varnishes and solvents with a total capacity of 7000 t / y. Basis for the development of initial data and general information about the technology. Description of the principal technological schemes of production.
term paper, added 02/17/2009
Description of the stages of computer-aided design. Methodology and algorithm for calculating the consumption rates of basic materials for a women's demi-season coat using Basiq Norma 1 and Norma 2. Features of data processing automation using a computer.
term paper added 05/06/2010
Selection of an electric motor and design of a two-stage worm gear. Design criteria: selection of gearbox sizes and materials. Calculation of high-speed and low-speed transmission. Construction of worms and worm wheels. Gearbox layout.
term paper added 01/12/2012
Compilation of initial data for designing a poultry house. Determination of the required thermal resistance to heat transfer. Calculation of the areas of individual floor zones. Calculation of heat loss through the enclosing structures. Calculation of the warm-air regime and air exchange.
term paper, added 09/10/2010
Basic information about silicate brick. Production of a lime-silica binder. Silo for slaking the raw mixture. The process of autoclaving materials. Calculation of the need for raw materials. Incoming control of materials. Calculation of the design of warehouses.
thesis, added 01/27/2014
Rules for the design and reconstruction of mechanical production workshops: general information on the design of mechanical assembly production, a description of the working project and working documentation, the interior of the designed section for manufacturing a part.
test, added 12/28/2008
Characteristics of the products of the plant of reinforced concrete products and concrete mixtures. Calculation of the performance of the program for the preparation of concrete mixtures. Selection of technological equipment. Determination of stocks of materials storage and selection of warehouse types.
term paper added 06/11/2015
Functions of the computer-aided design of clothing. Artistic design of clothing models. Anthropometric analysis of figures. Methods for designing model structures. Development of a family of models, development of patterns and determination of consumption rates.
thesis, added 06/26/2009
Operating conditions of a machine unit serving as a drive for an oscillating hoist. Engine for its design, kinematic calculation of the drive. Selection of worm gear materials and determination of permissible stresses. Calculation of shafts and bearings.
term paper added 06/16/2011
Justification of the choice of the system and water supply scheme, hydraulic calculation of the network and selection of the meter. Determination of the required head. Sewerage system design standards, calculation of the internal and yard network. Specification of materials and equipment.