Каждый из нас считает себя уникальным. Каждый из нас думает, что прекрасно знает себя. Каждый ответ поисковой системы на любой наш запрос доказывает обратное
Мы не так уникальны, как думаем: миллионы людей до нас озадачивали и миллионы после нас озадачат поисковик почти одинаковыми вопросами. С другой стороны, мы слишком непредсказуемы: на формулировку нашего запроса влияет огромное количество неосознаваемых нами факторов. И хотя бы поэтому запрос каждого из нас, каким бы банальным он ни был, требует индивидуального подхода.
Фактически вся работа поисковика «Яндекс» сводится к двум простым вещам: понять, что на самом деле хочет узнать человек, и за несколько секунд найти для него среди миллиардов документов в Сети подходящие.
Снять отпечатки
Система работы поисковика чем-то похожа на «Матрицу», а поисковый робот (созданная ею сложная, самостоятельно принимающая решения программа) — на агента Смита.
В 1997 году, когда «Яндекс» только открылся, для работы хватало одного сервера. Через три года компания арендовала четыре стойки, где размещалось около 40 компьютеров. Эти несколько десятков и стали основой первого дата-центра. Сегодня у «Яндекса» разветвленная и независимая от офисов сеть центров, в которых размещено несколько тысяч серверов
. Фото: ЯНДЕКС
Чтобы не обыскивать весь Интернет каждый раз, когда кому-то что-то нужно узнать, поисковик делает часть работы заранее — проверяет, что есть в Сети и где это лежит, с помощью тысяч поисковых роботов. Они бывают двух типов: основной и быстрый. Основной обходит и обрабатывает Интернет в целом, а быстрый — документы, появившиеся минуту или даже пару секунд назад. Задача программ-роботов — отобрать годную и полезную для пользователей информацию, переработать ее, отсеяв все устаревшее и ненужное. В чем-то это напоминает сортировку мусора: бумага в один контейнер, стекло в другой, пластик в третий, пищевые отходы в четвертый...
Собранная роботами информация образует так называемый слепок Интернета. Он хранится на тысячах серверов «Яндекса» и постоянно обновляется. Слепок похож на список, в котором указано, в каком месте какую информацию можно найти. В этом списке у каждого ключевого слова указана не одна, а миллионы «страниц». Чтобы все обновления слепка были доступны пользователям, их переносят из хранилища на «базовый поиск». Данные от основного робота переносятся раз в несколько дней, а от быстрого робота — в реальном времени.
Вывести на чистую воду
Разыскивая ответ на заданный вопрос в подготовленной базе, машина сталкивается с двумя основными сложностями. Первая сложность — язык. Прежде чем искать ответ на вопрос, машине важно понять, на каком языке это делать. Например, для русскоязычного человека на запрос «дружина князя Игоря» поиск найдет документы с информацией о войске, а для украинца на «дружина князя Iгоря» выдаст также документы, упоминающие княгиню Ольгу, его супругу, так как по-украински «жена» — это «дружина». Да и в богатом русском языке одно и то же слово или его производные могут означать разные вещи. Например, слово «стали» — это одна из форм существительного «сталь» и глагола «стать». Вторая сложность — человеческая психология. Вводя запрос, мы ожидаем быстрого и точного ответа, не заботясь, естественно, о соответствии формулировки запроса принципам математического анализа, по которым работает мозг машины. Например, введя в поисковую строку слово «наполеон», что человек хочет получить: рецепт торта или биографию французского императора, купить коньяк или найти адрес психиатрической больницы?
В таких ситуациях в дело вступают сразу несколько технологий. Можно выдать вам под строкой поиска несколько подсказок, конкретизирующих запрос. Мол, выберите, что вам нужно: «наполеон — рецепты» или «Наполеон — Бонапарт». Если пользователь не реагирует на просьбу машины и не добавляет к «наполеону» слов, то делу помогает технология «Спектр»: не надеясь на помощь, машина сразу ищет информацию по нескольким категориям (и про торт, и про императора, и про коньяк...). Кроме того, понять пользователя помогают механизмы персонализации — знания машины о том, что этот пользователь искал со своего компьютера день-два-три-месяц назад: если вы часто задавали «Яндексу» вопросы про кулинарию, то машина вначале покажет вам результаты, говорящие, что наполеон — торт.
Комбинации: клубы по интересам
Задача поисковой машины не сводится к тому, чтобы просто отобрать документы, в которых встречаются слова и словосочетания из поискового запроса. Машина должна понять, какие документы соответствуют нашим противоречивым требованиям и почему они им соответствуют. Хотим ли мы получить информацию о наполеоне-пирожном, или, может быть, мы пару лет посещали фитнес-клуб с пафосным названием, а то и вовсе озабочены комплексами людей невысокого роста. В любом случае решение задачи требует нетривиального подхода.
Создатели поисковой программы «Яндекс» нашли такой подход, делегировав право выбора машине. С одной стороны, бездушная, но очень быстрая и умная машина не знает и не хочет ничего знать о нас как о личностях, а с другой — она старается выяснить о каждом как можно больше.
Помимо географического положения пользователя и лингвистического анализа его запросов, поисковая машина использует несколько тысяч критериев, совершенно неочевидных для человека.
Фокус в том, что эти критерии машина разрабатывает и обновляет самостоятельно.
Она просто использует данные о предпочтениях и пользовательском поведении миллионов людей и связывает это «среднее арифметическое» с историей наших запросов. Принципы, которыми руководствуется «Матрица» внутри себя, сопоставляя тысячи разработанных ею категорий пользовательских интересов, часто не укладываются в традиционные человеческие представления о том, какими в принципе могут быть «интересы». Их десятки тысяч. Они создают друг с другом разные, порой забавные, комбинации. К примеру, одной из таких комбинаций может являться соответствие результатов поиска интересам человека, разводящего тритонов. При этом человек не просто интересуется тритонами, а уже разводит их, но только первый год.
Оценки. Руки помощи
«Матрица», конечно, сама решает (с помощью высшей математики), что и в какой последовательности нужно показать пользователям на основании десятков тысяч критериев. Но живых людей «Матрица» тоже использует — 1000 сотрудников «Яндекса», так называемых асессоров, оценивают результаты поиска по тому или иному запросу (конечно, не каждый запрос подвергается оценке, и делается это не в режиме реального времени) на предмет их соответствия ожиданиям обычного пользователя: не такого рационального, как машина, не такого точного в формулировках, противоречивого и эмоционального.
Продвижение сайта своими руками является одновременно простой и сложной задачей. Для человека опытного в этой теме раскрутка представляет собой набор простых и четких шагов, сводящихся, в большей степени, к механических действиям. Но для новичка, который только вчера узнал слово SEO и еще не разобрался в его значении, «победить» поисковые системы и конкурентов практически нереально.
Прежде чем приступить к продвижению, необходимо понять, как работают поисковые системы Яндекс и Google . Можете считать эту статью вводной для моего курса по продвижению сайтов «Бесплатный трафик с Поисковиков», поэтому рекомендую дочитать ее до конца, прежде чем начнете его изучать.
Задача поисковых систем
Интернет непрерывно растет и развивается, вместе с ним эволюционируют и , но их главная задача остается неизменной – они должны помочь пользователю найти самый лучший ответ на запрос, который он ввел в поле для поиска. Чем более качественные результаты в выдаче показывает поисковик, тем больше ему доверяют люди. Чем больше людей ему доверяют, тем больше денег он может заработать на контекстной рекламе, но это я уже пошел в сторону…
Поисковые системы постоянно анализируют терабайты информации, размещенной на миллионах web страниц, стараясь при этом определить какие сайты заслуживают попадания в ТОП выдачи, а какие являются лучшими кандидатами для попадания в бан.
Как действует поисковая система?
Поисковик – это набор сложных программ и баз данных, которые действуют по определенному алгоритму. Упрощенно, этот алгоритм можно разбить на 3 этапа.
Этап 1. Поиск новых страниц
Вопреки заблуждению многих чайников, поисковые системы выдают информацию не о страницах, находящихся в интернете, а о страницах, находящихся в базе данных поисковой машины. То есть, если сайт неизвестен Яндексу или Goоgle, то и в выдаче он не появится.
Задача поисковика на этом этапе заключается в поиске всех возможных адресов страниц в интернете. Выполняет эту работу так называемый робот «паук». Интернет это ссылки, ссылки и еще раз ссылки и этот «паук» просто переходит по всевозможным ссылкам, записывая в свою базу адреса всех найденных страниц.
Попал на главную страницу сайта, на ней нашел ссылки на страницы рубрик, на страницах рубрик нашел ссылки на страницы со статьями, карточками товаров, ссылки на файлы или другой информацией. На каких-то из посещенных страниц одного сайта, он нашел ссылки на другие сайты – поисковая система переходит по ним и сканирует все, что нашла там.
Прекрасно помогают роботам для ориентирования файлы Robots.txt и карты сайта Sitemap.xml, их надо обязательно сделать, особенно, если сайт имеет много страниц. Тут смотрите, а про настройку Sitemap расскажу чуть позже.
Задача робота создать адресный справочник по типу — Город, Улица, Дом, Квартира.
Как я уже написал выше – в поисковую выдачу попадает информация не с сайтов, находящихся в интернете, а информация из базы данных поисковой системы. И следующая программка поисковика как раз занимается добавлением информации в базу. Она путешествует по всем известным адресам сайтов и страниц, копируя их содержимое на склады поисковой системы.
Называется этот процесс индексация – попадание информации в индекс поисковой системы.
Первый и второй процессы протекают непрерывно и, зачастую, одновременно. Постоянно пополняется база адресов страниц и база информации с этих страниц.
Кстати, в процессе индексации поисковые системы оценивают качество страниц, и информация некоторых из них не попадает в индекс. Как бы поисковик знает об их существовании, но по каким-то причинам считает их бесполезными для пользователя, поэтому не добавляет в выдачу — зачастую это не уникальный контент или служебные страницы. Как проверить тексты на .
Этап 3. Определение релевантности и ранжирование
Если то, что мы обсудили в предыдущих пунктах, работает непрерывно и независимо от внешних факторов (действий человека), то третий этап в алгоритме работы поисковых систем начинает действовать только под воздействием человека.
Когда в поисковике задается запрос, система начинает искать на него ответ в наполненной базе знаний по критериям, заданным человеком в этом запросе (как ).
Сначала, система делает выборку, определяя все релевантные запросу страницы из известных (Релевантные – значит соответствующие, подходящие. Как проверить релевантность страниц сайта я писал ). Например, для запроса «купить холодильник Норд» релевантными будут страницы содержащие слова «купить», «холодильник», «Норд». Все страницы, содержащие одно или несколько из этих слов, попадут в выдачу поисковой системы.
Следующая задача поисковика, определить в какой последовательности пользователь увидит все эти страницы – их необходимо ранжировать. Факторов, которые будут влиять на порядок выдачи много, но если по-простому, то сначала пользователь увидит страницы содержащие «купить холодильник Норд», если таких нет, то ему будет предложено «купить холодильник» или «холодильник Норд» и в самом конце будут страницы со словами «купить», «холодильник», «Норд».
Факторы, влияющие на ранжирование
Как я уже сказал выше, факторов, влияющие на порядок расстановки страниц сайтов в выдаче поисковой системы много, по словам руководителей Яндекс, их более 700. Цифра внушительная и раскрыть их все не представляется возможным. Более того, все эти факторы неизвестны ни одному сеошнику, так как поисковики держат их в тайне. Но в общих чертах эти факторы можно разделить на три группы.
1. Внутренние факторы
К этой группе относятся факторы, на которые способен повлиять сам вебмастер. В их число входит сам текст, размещенный на странице, его оформление (абзацы, заголовки и другая разметка) — читайте . К ним же относятся картинки внутри текста и оформление самого сайта. Ссылки, которые размещаются внутри сайта на различные страницы (внутренняя перелинковка) также относятся к внутренним факторам.
2. Внешние факторы
В целом, эта группа факторов определяет популярность конкретного сайта по мнению других ресурсов интернета. Определяется эта популярность количеством и качеством сайтов, на которых проставлены ссылки на различные страницы вашего сайта, а также упоминания о нем в тексте. Поисковые системы оценивают эту авторитетность по сложной схеме, учитывающей очень большое количество факторов.
Кроме того, ко внутренним факторам поисковые системы причисляют различные социальные сигналы, типа ретвиты, лайки, Фейсбук или Одноклассники (Про то, как бесплатно накрутить лайки в ВК я писал ).
3. Поведенческие факторы
Поведение пользователей в интернете поисковые системы умели отслеживать не всегда. Популярность эта группа факторов начала набирать сравнительно недавно. Различные счетчики статистики и специальные бары в браузерах собирают массу информации о поведении людей на сайтах. По этим данным Яндекс и Google определяют степень значимости сайтов для живых людей. Если на страницах вашего сайта низкий показатель отказов — надолго задерживаются посетители, внимательно читают качественные статьи, переходят по внутренним ссылкам и делают разные другие вещи, значит он людям нравится и достоин размещения на более высоких позициях поисковой выдачи.
Почему Яндекс долго индексирует сайты
Многие из вас обращали внимание на то, что индексация новых страниц Яндексом, как правило, занимает больше времени, чем у Google. Связано это с тем, что новые страницы, найденные поисковыми роботами попадают сначала в общую базу страниц и только после обработки и фильтрации она оказывается в пользовательской выдаче.
Гугл старается проводить процесс переноса новых документов в выдачу непрерывно. В свою очередь Яндекс накапливает новый страницы, обрабатывает их и потом одной общей пачкой отправляет в пользовательскую выдачу. Происходит это один раз в несколько дней (в среднем неделя) и называется эта процедура апдейт (АП). Почти всегда, апдейты проходят ночью, когда нагрузка на сервера поисковой системы минимальна.
По такому алгоритму новая страница попадает в базу данных поисковика (на это может уйти несколько дней), дальше эта страница ждет своей очереди пока информация на ней будет обработана и пройдет ранжирование по релевантным запросам (проходит еще один апдейт) и только на следующий апдейт выдачи новый документ появляется в основном индексе.
Таким образом, некоторые страницы могут ждать своей очереди довольно долго.
Теперь вы знаете, как функционируют поисковые системы и можете приступать к работе над вашими сайтами. Создайте релевантную нужному запросу страницу, дайте поисковику ее проиндексировать и помогите ранжировать ваши страницы выше конкурентов.
Другие полезные статьи блога:

Каждый из нас считает себя уникальным. Каждый из нас думает, что прекрасно знает себя. Каждый ответ поисковой системы на любой наш запрос доказывает обратное.
Мы не так уникальны, как думаем: миллионы людей до нас озадачивали и миллионы после нас озадачат поисковик почти одинаковыми вопросами. С другой стороны, мы слишком непредсказуемы: на формулировку нашего запроса влияет огромное количество неосознаваемых нами факторов. И хотя бы поэтому запрос каждого из нас, каким бы банальным он ни был, требует индивидуального подхода.
Фактически вся работа поисковика «Яндекс» сводится к двум простым вещам: понять, что на самом деле хочет узнать человек, и за несколько секунд найти для него среди миллиардов документов в Сети подходящие.
Система работы поисковика чем-то похожа на Матрицу, а поисковый робот (созданная ею сложная, самостоятельно принимающая решения программа) - на агента Смита.

В 1997 году, когда «Яндекс» только открылся, для работы хватало одного сервера. Через три года компания арендовала четыре стойки, где размещалось около 40 компьютеров. Эти несколько десятков и стали основой первого дата-центра. Сегодня у «Яндекса» разветвленная и независимая от офисов сеть цент ров, в которых размещено несколько тысяч серверов. Фото: ЯНДЕКС
Чтобы не обыскивать весь Интернет каждый раз, когда кому-то что-то нужно узнать, поисковик делает часть работы заранее - проверяет, что есть в Сети и где это лежит, с помощью тысяч поисковых роботов. Они бывают двух типов: основной и быстрый. Основной обходит и обрабатывает Интернет в целом, а быстрый - документы, появившиеся минуту или даже пару секунд назад. Задача программ-роботов - отобрать годную и полезную для пользователей информацию, переработать ее, отсеяв все устаревшее и ненужное. В чем-то это напоминает сортировку мусора: бумага в один контейнер, стекло в другой, пластик в третий, пищевые отходы в четвертый...
Собранная роботами информация образует так называемый слепок Интернета. Он хранится на тысячах серверов «Яндекса» и постоянно обновляется. Слепок похож на список, в котором указано, в каком месте какую информацию можно найти. В этом списке у каждого ключевого слова указана не одна, а миллионы «страниц». Чтобы все обновления слепка были доступны пользователям, их переносят из хранилища на «базовый поиск». Данные от основного робота переносятся раз в несколько дней, а от быстрого робота - в реальном времени.
Вывести на чистую воду
Разыскивая ответ на заданный вопрос в подготовленной базе, машина сталкивается с двумя основными сложностями. Первая сложность - язык. Прежде чем искать ответ на вопрос, машине важно понять, на каком языке это делать. Например, для русскоязычного человека на запрос «дружина князя Игоря» поиск найдет документы с информацией о войске, а для украинца на «дружина князя Iгоря» выдаст также документы, упоминающие княгиню Ольгу, его супругу, так как по-украински «жена» - это «дружина». Да и в богатом русском языке одно и то же слово или его производные могут означать разные вещи. Например, слово «стали» - это одна из форм существительного «сталь» и глагола «стать». Вторая сложность - человеческая психология. Вводя запрос, мы ожидаем быстрого и точного ответа, не заботясь, естественно, о соответствии формулировки запроса принципам математического анализа, по которым работает мозг машины. Например, введя в поисковую строку слово «наполеон», что человек хочет получить: рецепт торта или биографию французского императора, купить коньяк или найти адрес психиатрической больницы?

В таких ситуациях в дело вступают сразу несколько технологий. Можно выдать вам под строкой поиска несколько подсказок, конкретизирующих запрос. Мол, выберите, что вам нужно: наполеон-рецепты или Наполеон - Бонапарт. Если пользователь не реагирует на просьбу машины и не добавляет к «наполеону» слов, то делу помогает технология «Спектр»: не надеясь на помощь, машина сразу ищет информацию по нескольким категориям (и про торт, и про императора, и про конь як...). Кроме того, понять пользователя помогают механизмы персонализации - знания машины о том, что этот пользователь искал со своего компьютера день-два-три-месяц назад: если вы часто задавали «Яндексу» вопросы про кулинарию, то машина вначале покажет вам результаты, говорящие, что наполеон - торт.
Комбинации: клубы по интересам
Задача поисковой машины не сводится к тому, чтобы просто отобрать документы, в которых встречаются слова и словосочетания из поискового запроса. Машина должна понять, какие документы соответствуют нашим противоречивым требованиям и почему они им соответствуют. Хотим ли мы получить информацию о наполеоне - пирожном, или, может быть, мы пару лет посещали фитнес-клуб с пафосным названием, а то и вовсе озабочены комплексами людей невысокого роста. В любом случае решение задачи требует нетривиального подхода.

Создатели поисковой программы «Яндекс» нашли такой подход, делегировав право выбора машине. С одной стороны, бездушная, но очень быстрая и умная машина не знает и не хочет ничего знать о нас как о личностях, а с другой - она старается выяснить о каждом как можно больше.
Помимо географического положения пользователя и лингвистического анализа его запросов поисковая машина использует несколько тысяч критериев, совершенно не очевидных для человека.
Фокус в том, что эти критерии машина разрабатывает и обновляет самостоятельно.
Она просто использует данные о предпочтениях и пользовательском поведении миллионов людей и связывает это «среднее арифметическое» с историей наших запросов. Принципы, которыми руководствуется Матрица внутри себя, сопоставляя тысячи разработанных ею категорий пользовательских интересов, часто не укладываются в традиционные человеческие представления о том, какими в принципе могут быть «интересы». Их десятки тысяч. Они создают друг с другом разные, порой забавные, комбинации. К примеру, одной из таких комбинаций может являться соответствие результатов поиска интересам человека, разводящего тритонов. При этом человек не просто интересуется тритонами, а уже разводит их, но только первый год.
Оценки. Руки помощи
Матрица, конечно, сама решает (с помощью высшей математики), что и в какой последовательности нужно показать пользователям на основании десятков тысяч критериев. Но живых людей Матрица тоже использует - 1000 сотрудников «Яндекса», так называемых асессоров, оценивают результаты поиска по тому или иному запросу (конечно, не каждый запрос подвергается оценке, и делается это не в режиме реального времени) на предмет их соответствия ожиданиям обычного пользователя: не такого рационального, как машина, не такого точного в формулировках, противоречивого и эмоционального.
Тогда мы затронули только сам процесс добавления и я упомянул вам о важности указания поисковым системам главного зеркала вашего блога, давайте сегодня рассмотрим это более подробно.
Во первых, что-же такое зеркало блога или сайта? В поисковых системах зеркалом сайта считается, как полное так и частичное отображение или проще говоря копия того или иного сайта.
Теперь давайте рассмотрим, как это может коснуться вашего сайта. К примеру адрес вашего сайта имеет вот такой вид , при его наборе в адресную строку браузера посетитель попадает на главную страницу вашего сайта и тоже самое произойдёт если набрать . Но поисковики это считают двумя разными сайтами, но с полностью одним и тем-же содержимым, то-есть полное копирование друг друга (дубль). Думаю всем понятно во-что это всё может вылиться.
И по этому при добавлении сайта в поисковую систему очень важно обязательно указать главное его зеркало, то есть с www или без.
Никакого преимущества www перед адресом вашего сайта не даёт и идёт из глубин создания всемирной сети. Расшифровывается, как всемирная паутина. Поэтому сегодня нет никакого смысла его использовать, но выбор конечно за вами.
И так если вы определились с тем, какое главное зеркало будет у вашего сайта. Вам нужно сообщить его поисковым системам Яндекс и Google. Давайте начнём с первого.
Как указать Яндексу на главное зеркало сайта
Как видите ничего сложного нет.
Теперь проведём эту-же операцию для Google.
И вот тут можно столкнуться с трудностью, давайте подробней.

То-есть мы должны пройти всю процедуру добавления сайта в Google. Что мы делали в уже упомянутой мной прошлой статье.
То-есть, как-бы добавить новый сайт и если я в прошлый раз добавлял сайт с адресом: сайт то теперь его нужно указать при добавлении, как сайт с : www..
И так проходим всю процедуру снова. При этом также подтверждаем права на пользования доменом с www. Конечно вам не нужно будет загружать на новый файл подтверждения, так-как мы это сделали в прошлый раз, поэтому сразу нажимаем подтвердить.
И если в прошлый раз у нас было сообщение такого вида.
Теперь оно будет вот таким:

Теперь возвращаемся на главную страницу «инструменты веб-мастера», выбираем сайты по очереди, версию с www и без. В каждом случае кликаем по картинке в виде шестерёнке, как показано на картинке выше и выбираем настройки сайта. Где указываем желаемое зеркало.
Как видите всё получилось.
Для окончательного перенаправления на вашего сайта, вам необходимо ещё сделать с помощью файл.htaccess. Это мы так-же обсудим в ближайших статьях подписывайтесь обязательно на обновления и до новых встреч!
Здравствуйте уважаемые читатели . Сегодня я расскажу, как указать поисковикам Яндекс и Google на главное зеркало сайта.
Что такое зеркало сайта? По мнению Яндекса, зеркало является частично или полной копией сайта. Есть и другие трактования, но суть одна — это очень плохо отражается на поисковом продвижении.
В чем же заключается эдакая зеркальность? Если вы попробуете набрать домен своего сайта например: www.сайт.com и просто сайт.com, то попадете в обоих случаях на главную страницу. Так вот, для поисковой машины это два совершенно разных сайта с полностью идентичным содержимый.
То есть, это полный дубль сайта. О различных дублях контента я подробно писал в статьях: » и « «.
Дело в том, что надо определится по поводу главного зеркала, будет сайт с www или без него. Кстати по этому поводу мнения сильно разнятся, но если почитать историю возникновения www, то становится понятно, что www это уже в прямом и переносном смысле — прошлый век. Беру на себя смелость посоветовать своим читателя отказаться от пресловутой аббревиатуры создателей всемирной паутины.
Аббревиатура WWW расшифровывается, как World Wide Web и переводится просто — «Всемирная паутина».
Теперь когда мы определились с основным зеркалом, самое время сообщить об этом крупным поисковым системам.
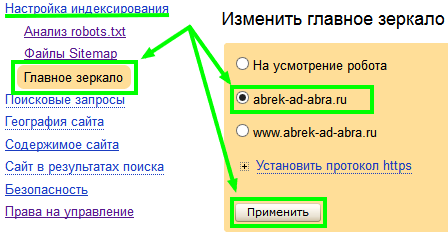
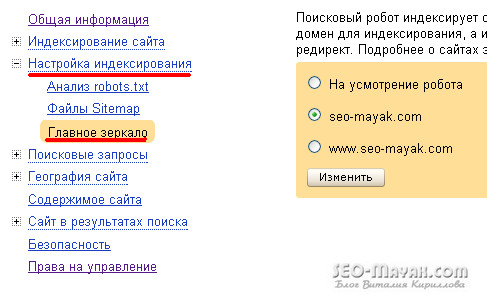
Как указать Яндексу на главное зеркало
Указать Яндексу на главное зеркало можно перейдя по этой ссылке . Следуем — «Мои сайты «, выбираем свой сайт или один из своих сайтов, — «Настройка индексирования » — «Главное зеркало «:
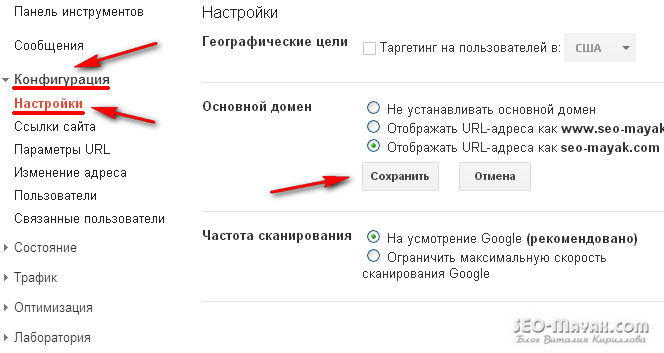
Как указать Google на главное зеркало
Чтобы указать Google на главное зеркало, я пошел уже протоптанной другими веб-мастерами дорожкой, инструменты для веб-мастеров — «Конфигурация » — «Настройки »

Почитам немного справочник Google я понял, что для прохождения данной процедуры надо попасть в сервис Google Apps для бизнеса

Проходим регистрацию и попадаем на панель администратора. Далее выбираем — «Подтвердить право собственности на домен»

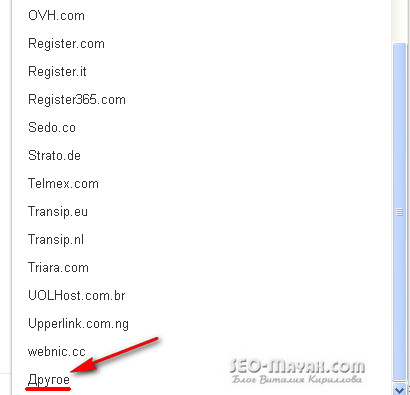
В всплывающем окне нажимаем — «Продолжить» и попадаем на страницу, где нам предлагается выбрать регистратора домена или провайдера:

Если Вы не нашли в предложенном списке своего регистратора домена, то в самом конце выбираем — «Другое»
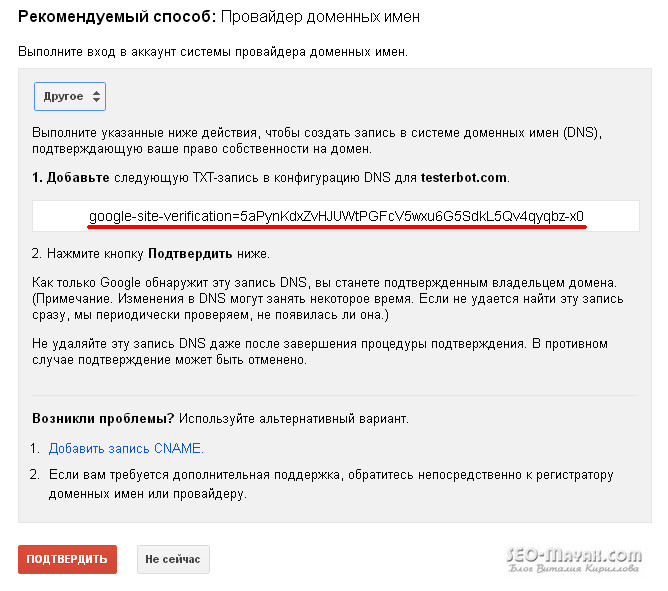
Задачка! Но не все так страшно как может показаться на первый взгляд. Копируем предложенный код и идем в панель управления своего хостинг-провайдера, заходим в настройки DNS и в поле TXT-запись вставляем скопированный код. На моем хостинге поле TXT-запись выглядит так:
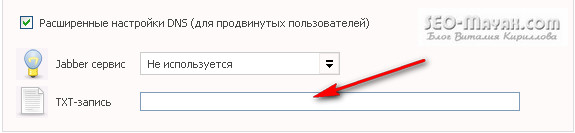
Если там уже есть какие-то символы, то просто заменяем их скопированным кодом от Google. Теперь возвращаемся в панель управления и нажимаем кнопку — «Подтвердить» и если мы все сделали правильно появится такое сообщение:
Также Google предлагает альтернативные способы подтверждения и я попытался воспользовался одним из них для моего тестового домена:

Но как я не старался получить файл googleb1c540918a6ec845.html Гугл настойчиво слал мне совершенно другой файл, точно такой же, что я закачал в корень сайта при регистрации в поисковой системе Google и потом упорно не хотел его видеть. Тогда я пошел другим путем, методом добавления метатега файл header.php. и на этот раз подтверждение прошло успешно.
Каким из предложенный вариантов воспользоваться конечно решать Вам, но наверно лучше идти по рекомендованному пути, ведь не зря же он — «рекомендованный».
Чтобы окончательно завершить перенаправление, кроме всего вышесказанного, необходимо
Если возникли сложности, то расскажите об них в комментариях.
На сегодня у меня все. Как Вам моя статья?
Вот такие дороги в Сибири, но и машины…
С уважением, Виталий Кириллов