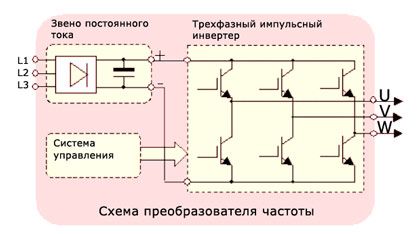
DBMS functions.
DBMS functions are high and low.
High level features:
1. Data definition - using this function, it is determined what information will be stored in the database (type, data properties and how they will be interconnected).
2. Data processing. Information can be processed in different ways: sampling, filtering, sorting, combining one information with another, calculating the total values.
3. Data management. Using this function, it is indicated who is allowed to get acquainted with the data, correct them or add new information, as well as determine the rules for shared access.
Low Level Functions:
1. Data management in external memory;
2. RAM buffer management;
3. Transaction management;
4. Introduction of a change log to the database;
5. Ensuring the integrity and security of the database.
Transaction called an indivisible sequence of operations, which is monitored by the DBMS from the beginning to the end, and in which if one operation is not performed, the entire sequence is canceled.
DBMS Magazine - a special database or part of the main database, inaccessible to the user and used to record information about all changes to the database.
Introduction to DBMS Magazine Designed to ensure the reliability of storage in the database in the presence of hardware failures and failures, as well as errors in the software.
Database integrity - This is a database property, meaning that it contains complete, consistent and adequately reflecting the subject area information.
DBMS classification.
DBMS can be classified:
1. By type of program:
a. Database servers (for example, MS SQL Server, InterBase (Borland)) - designed to organize data centers in computer networks and implement database management functions requested by client programs using SQL statements (i.e., programs that respond to requests);
b. DB Clients - programs that request data. As client programs can be used PFSUBD, spreadsheets, word processors, e-mail programs;
c. Full featured databases (MS Access, MS Fox Pro) - a program that has a developed interface that allows you to create and modify tables, enter data, create and format queries, develop reports and print them.
2. According to the DBMS data model (as well as the database):
a. Hierarchical - based on a tree-like structure of information storage and resemble a computer file system; the main disadvantage is the inability to realize the attitude of many - to - many;
b. Network - which replaced the hierarchical and did not last long because the main drawback is the complexity of developing serious applications. The main difference between a network and a hierarchical one is that in a hierarchical structure the “record - descendant” has only one ancestor, and in a network descendant it can have any number of ancestors;
c. Relational - the data of which are placed in tables between which there are certain relationships;
d. Object Oriented - they store data in the form of objects and the main advantage when working with them is that you can apply an object-oriented approach to them;
e. Hybrid, i.e., object - relational - combine the capabilities of relational and object-oriented databases. An example of such a database is Oracle (previously it was relational).
3. Depending on the location of the individual parts of the DBMS, there are:
a. local - all parts of which are located on one computer;
b. networked.
Network include:
- with file-server organization;
With such an organization, all the data is on one computer, which is called a file - server, and which is connected to the network. When finding the necessary information, the entire file is transferred, including, including a lot of redundant information. And only when creating a local copy the desired record is found.
- with a client-server organization;
The database server receives a request from the client, searches for the required record in the data and passes it to the client. The request to the server is formed in the language of structured SQL queries, so the database servers are called SQL - servers.
- distributed DBMS contain several tens and hundreds of servers located on a large territory.
The main provisions of the relational database model.
Relational database a database is called in which all data is organized in the form of tables, and all operations on this data are reduced to operations on tables.
Features of relational databases:
1. Data is stored in tables consisting of columns and rows;
2. At the intersection of each column and row is one value;
3. Each column - field has its own name, which serves as its name - an attribute, and all values \u200b\u200bin one column are of the same type;
4. Columns are arranged in a certain order, which is set when creating the table, in contrast to rows that are arranged in random order. There may not be a single row in the table, but there must be at least one column.
Relational database terminology:
| Relational Database Element | Presentation form |
| 1. Database | Table set |
| 2. Database schema | Table header set |
| 3. Attitude | Table |
| 4. Relationship Scheme | Table column heading row |
| 5. The essence | Description of object properties |
| 6. Attribute | Column heading |
| 7. Domain | Many valid attribute values |
| 8. Primary key | Unique identifier that uniquely identifies each entry in the table. |
| 9. Data Type | Type of item values \u200b\u200bin a table |
| 10. Tuple | String (record) |
| 11. Cardinality | The number of rows in the table |
| 12. The degree of attitude | Number of fields |
| 13. The body of the relationship | Many relationship tuples |
When designing a relational database, the data is placed in several tables. Between tables establish relationships using keys. When linking tables, the primary and secondary (subordinate) tables are distinguished.
The following types of relationships between tables exist:
1. Communication of the form 1: 1 (one to one) means that each record in the main table corresponds to one record in the additional table and, conversely, each record in the additional table corresponds to one record in the main table.
2. A relationship of the form 1: M (one to many) means that each record in the main table corresponds to several records in the additional table and, conversely, each record in the additional table corresponds to only one record in the main table.
3. The relationship of the form M: 1 (many to one) means that one or more records in the main table corresponds to only one record in the additional table.
4. A relationship of the form M: M (many to many) - this is when several records of the main table correspond to several additional records and vice versa.
5. The main components of MS Access.
The main components (objects) of MS Access are:
1. Tables;
3. Forms;
4. Reports;
5. Macros:
Modules
Table Is an object designed to store data in the form of records (rows) and fields (columns). Each field contains a separate part of the record, and each table is used to store information on one specific issue.
Request - a question about the data stored in the tables, or an instruction to select the records to be changed.
The form - this is an object in which you can place controls designed to enter, image and change data in the fields of tables.
Report - This is an object that allows you to present user-defined information in a specific form, view and print it.
Macro - One or more macros that can be used to automate a specific task. A macro is the main building block of a macro; A stand-alone instruction that can be combined with other macros to automate the task.
Module - a set of descriptions, instructions and procedures stored under one name. There are three types of modules in MS Access: the form, report module, and the general module. Form and report modules contain a local program for forms and reports.
6. Tables in MS Access.
In MS Access, the following table creation methods are available:
1. Table mode;
2. Constructor;
3. Table wizard;
4. Import tables
5. Relationship with tables.
AT table mode data is entered into an empty table. A table with 30 fields is provided for data entry. After saving it, MS Access decides which data type to assign to each field.
Constructor Provides the ability to independently create fields, select data types for fields, field sizes and set field properties.
To define a field in mode Constructor are set:
1. Field name , which in each table must have a unique name, which is a combination of letters, numbers, spaces and special characters, with the exception of " .!” “ ". The maximum length of the name is 64 characters.
2. Data type determines the type and range of acceptable values, as well as the amount of memory allocated for this field.
MS Access Data Types
| Data type | Description |
| Text | Text and numbers, such as names and addresses, phone numbers, zip codes (up to 255 characters). |
| Memo field | Long text and numbers, such as comments and explanations (up to 64,000 characters). |
| Numerical | A general data type for numerical data that allows mathematical calculations, with the exception of monetary calculations. |
| Date Time | Date and time values. The user can choose standard forms or create a special format. |
| Monetary | Cash values. For monetary calculations, it is not recommended to use numerical data types, as they can be rounded off when calculating. Values \u200b\u200bof type "money" are always displayed with the specified number of decimal places. |
| Counter | Automatically set sequential numbers. The numbering starts with 1. The counter field is convenient for creating a key. This field is compatible with a numeric type field for which the Long property is specified in the Size property. |
| Logical | Values \u200b\u200bYes / No, True / False, On / Off, one of two possible values. |
| OLE Object Field | Objects created in other programs that support the OLE protocol. |
3. The most important field properties:
- Field size sets the maximum size of data stored in the field.
- Field format It is a display format for a given data type and sets the rules for presenting data when it is displayed or printed.
- Field signature sets the text that is displayed in tables, forms, reports.
- Value Condition allows you to control input, sets restrictions on the input values; if the conditions are violated, it prohibits input and displays the text specified by the Error message property;
- Error message sets the text of the message displayed on the screen in violation of the restrictions specified by the Value Condition.
Control type - a property that is set on the Substitution tab in the table designer window. This property determines whether the field will be displayed in the table and in what form - as a field or a combo box.
Unique (primary) key tables can be simple or compound, including several fields.
To determine the key, the fields that make up the key are selected, and the button is pressed on the toolbar key fieldor the command is executed Edit / Key Field.
© 2015-2019 website
All rights belong to their authors. This site does not claim authorship, but provides free use.
Page Created Date: 2016-02-16
language tools and software systems that ensure their high performance, and the creation of the fundamentals of database design theory. However, for the general user of relational DBMSs, one can successfully apply informal equivalents of these concepts:
“Relation” is “table” (sometimes a file), “tuple” is “row” (sometimes record), “attribute” is “column”, “field”.
It is hereby accepted that “record” means “record instance”, and “field” means “field name and type”.
Relational database
A relational database is a collection of relationships containing all the information that must be stored in the database. However, users can perceive such a database as a collection of tables. It should be noted:
Each table consists of the same type of rows and has a unique name; Rows have a fixed number of fields (columns) and values \u200b\u200b(many
duplicate fields and duplicate groups are not allowed). In other words, in each position of the table at the intersection of the row and column there is always exactly one value or nothing;
Rows of the table necessarily differ from each other by at least a single value, which allows you to uniquely identify any row of such a table;
The columns of the table are uniquely assigned names, and each of them contains homogeneous data values \u200b\u200b(dates, last names, integers or monetary amounts);
The full informational content of the database is presented in the form of explicit data values \u200b\u200band this method of presentation is the only one; When performing operations with a table, its rows and columns can be processed in any order, regardless of their information content. This is facilitated by the availability of table names and their columns, as well as the ability to select any row or any set of rows with the specified attributes (for example, flights with the destination “Paris” and the time of arrival
tiya up to 12 hours).
Manipulating Relational Data
By proposing a relational data model, E.F. Codd also created a tool for convenient work with relationships - relational algebra. Each operation of this algebra uses one or more tables (relations) as its operands and as a result produces a new table, i.e. allows you to "cut" or "glue" the table (Fig. 1.5).
Fig. 1.5. Some operations of relational algebra
Created data manipulation languages \u200b\u200bthat allow you to implement all the operations of relational algebra and almost any combination of them. Among them, the most common are SQL (Structured Query Language).
query language) and QBE (Quere-By-Example - sample queries). Both from-
rush to languages \u200b\u200bof a very high level, with the help of which the user indicates what data needs to be obtained without specifying the procedure for obtaining them.
Using a single query in any of these languages, you can join several tables into a temporary table and cut out the required rows and columns from it (selection and projection).
Relational database design, design goals
Only small organizations can share data in one fully integrated database. Most often, it is practically impossible to cover and comprehend all the information requirements of the organization’s employees (i.e. future users of the system). Therefore, the information systems of large organizations contain several dozen databases, often distributed between several interconnected computers of various departments. (So \u200b\u200bin large cities, not one, but several vegetable bases are created located in different areas.)
Separate databases can combine all the data necessary to solve one or more applied problems, or data related to any subject area (for example, finance, students, teachers, cooking, etc.). The former are usually referred to as applied databases, while the latter are referred to as subject databases (related to the objects of the organization, and not to its information applications). The former can be compared with the bases of material and technical supply or leisure, and the latter with vegetables and clothing stores.
Subject databases can provide support for any current and future applications, since the set of their data elements includes sets of data elements of applied databases. As a result, subject databases
provide a basis for processing informal, changing and unknown requests and applications (applications for which it is impossible to determine data requirements in advance). Such flexibility and adaptability allows creating fairly stable information systems on the basis of subject databases. systems in which most of the changes can be made without having to rewrite old applications.
Based on the same database design on current and foreseeable applications, it is possible to significantly accelerate the creation of a highly efficient information system, i.e. a system whose structure takes into account the most common data access paths. Therefore, applied design still attracts some developers. However, as the number of applications of such information systems grows, the number of applied databases increases rapidly, the level of data duplication increases sharply, and the cost of maintaining them increases.
Thus, each of the considered design approaches affects the design results in different directions. The desire to achieve both flexibility and efficiency led to the formation of a design methodology that uses both substantive and applied approaches. In the general case, the objective approach is used to build the initial information structure, and the applied approach is to improve it in order to increase the efficiency of data processing.
When designing an information system, it is necessary to analyze the goals of this system and identify the requirements for it of individual users (employees of the organization). Data collection begins with a study of the entities of the organization and the processes using these entities. Entities are grouped by “similarity” (the frequency of their use to perform certain actions) and by the number of associative connections between them (airplane - passenger, teacher - discipline, student - session, etc.). Entities or groups of entities that have the greatest similarity and (or) with the highest frequency of associative connections are combined into objective databases. (Often, entities are combined into subject databases without the use of formal techniques - according to “common sense”).
The main goal of designing a database is to reduce the redundancy of stored data, and therefore, save the amount of memory used, reduce the cost of multiple operations to update redundant copies and eliminate the possibility of inconsistencies due to the storage of information about the same object in different places. The so-called “clean” database design (“Every fact in one place”) can be created using the methodology of normalizing relations.
Normalization is breaking up a table into two or more that have better properties when you turn on, change, or delete data.
The final goal of normalization is to obtain a database design in which each fact appears in only one place, i.e. redundancy of information is excluded. This is done not so much to save memory, but to eliminate the possible inconsistency of stored data.
Each table in a relational database satisfies the condition that there is always a single atomic value in the position at the intersection of each row and column of the table, and there can never be many such values. Any table satisfying this condition is called normalized. In fact, unnormalized tables, i.e. tables containing duplicate groups are not even allowed in a relational database.
Any normalized table is automatically considered a table in first normal form, abbreviated 1NF. Thus, strictly speaking, “normalized” and “located in 1NF” mean the same thing. However, in practice, the term “normalized” is often used in a narrower sense.
- “fully normalized”, which means that the project does not violate any principles of normalization.
Now, in addition to 1NF, further levels of normal
malization - the second normal form (2NF), the third normal form
(3NF), etc. Essentially, a table is in 2NF if it is in 1NF
and satisfies, in addition, some additional condition, the essence of which will be discussed below. A table is in 3NF if it is in 2NF and, in addition, satisfies another additional condition
etc.
Thus, each normal form is in a sense more limited, but also more desirable than the previous one. This is due to the fact that the “(N + 1) th normal form” does not have some unattractive features inherent in the “Nth normal form”. The general meaning of the additional condition imposed on the (N + 1) -th normal form with respect to the N-th normal form is to exclude these unattractive features.
Normalization theory is based on the presence of one or another dependence between the fields of the table. Two types of such dependencies are defined:
national and multi-valued.
Functional dependence.Field B of the table functionally depends on field A of the same table if and only if at any given moment for each of the different values \u200b\u200bof field A there is necessarily only one of the different values \u200b\u200bof field B. Note that it is assumed here that fields A and B may be compound.
Full functional dependency. Field B is in full function.
national dependence on the composite field A, if it is functionally dependent on A and does not functionally depend on any subset of field A.
Multi-valued dependence. Field A defines the field B
All modern databases use CBO (Cost Based Optimization), cost optimization. Its essence is that for each operation its “cost” is determined, and then the total cost of the request is reduced by using the most “cheap” chains of operations.For a better understanding of cost optimization, we’ll look at three common ways to join two tables and see how even a simple join query can turn into a nightmare for the optimizer. In our consideration, we will focus on time complexity, although the optimizer calculates the “cost” in processor resources, memory, and I / O operations. Just time complexity is an approximate concept, and to determine the necessary processor resources, you need to count all operations, including addition, if statements, multiplication, iterations, etc.
Besides:
- To perform each high-level operation, the processor performs a different number of low-level operations.
- The cost of processor operations (in terms of cycles) is different for different types of processors, that is, it depends on the specific architecture of the CPU.
We talked about them when we looked at B-trees. As you remember, indexes are already sorted. By the way, there are other types of indices, for example, bitmap indexes. But they do not give a gain in terms of the use of the processor, memory and disk subsystem in comparison with the index of B-trees. In addition, many modern databases can dynamically create temporary indexes for current queries, if this helps reduce the cost of implementing the plan.
4.4.2. Contact methods
Before applying union operators, you must first obtain the necessary data. You can do this in the following ways.
- Full scan. The database simply reads the whole table or index. As you understand, for a disk subsystem an index is cheaper to read than a table.
- Range scan. Used, for example, when you use predicates like WHERE AGE\u003e 20 AND AGE< 40. Конечно, для сканирования диапазона индекса вам нужно иметь индекс для поля AGE.
In the first part of the article, we already found out that the time complexity of a range query is defined as M + log (N), where N is the amount of data in the index, and M is the estimated number of rows within the range. The values \u200b\u200bof both of these variables are known to us thanks to statistics. When scanning a range, only a part of the index is read, so this operation costs less than a full scan.
- Scan by unique values. It is used in cases where you need to get only one value from the index.
- Access by row ID. If the database uses an index, then most of the time it will search for rows associated with it. For example, we make the following request:
SELECT LASTNAME, FIRSTNAME from PERSON WHERE AGE \u003d 28
If we have an index for the age column, then the optimizer will use the index to search for all 28-year-olds, and then request the ID of the corresponding rows of the table, since the index contains information only about age.Let's say we have another request:
SELECT TYPE_PERSON.CATEGORY from PERSON, TYPE_PERSON WHERE PERSON.AGE \u003d TYPE_PERSON.AGE
To combine with TYPE_PERSON, the index on the PERSON column will be used. But since we did not request information from the PERSON table, no one will access it by row ID.This approach is only good for a small number of hits, as it is expensive in terms of I / O. If you often need to contact by ID, then it is better to use a full scan.
- other methods. You can read about them in the Oracle documentation. Different names may be used in different databases, but the principles are the same everywhere.
So, we know how to get the data, it's time to combine them. But first, let's define new terms: internal dependencies and external dependencies. Dependence may be:
- table,
- index,
- an intermediate result of a previous operation (for example, a previous join).
Most often, the value of A JOIN B is not equal to the value of B JOIN A.
Suppose that the external dependence contains N elements, and the internal one contains M. As you recall, these values \u200b\u200bare known to the optimizer due to statistics. N and M are cardinal numbers of dependencies.
- Combining using nested loops. This is the easiest way to combine.

It works like this: for each line of the external dependency, matches are found for all the lines of the internal dependency.
Pseudo-code example:
Nested_loop_join (array outer, array inner) for each row a in outer for each row b in inner if (match_join_condition (a, b)) write_result_in_output (a, b) end if end for end for
Since there is a double iteration, the time complexity is defined as O (N * M).For each of the N lines of external dependency, you need to consider M lines of external dependence. That is, this algorithm requires N + N * M reads from disk. If the internal dependence is small enough, then you can put it in its entirety in memory, and then the disk subsystem will have only M + N readings. So it is recommended to make internal dependence as compact as possible in order to drive it into memory.
From the point of view of time complexity, there is no difference.
You can also replace the internal dependency with an index, this will save input / output operations.
If the internal dependency does not fit into the memory entirely, you can use another algorithm that uses the disk more economically.- Instead of reading both dependencies line by line, they are read by groups of lines (bunch), while one group of each dependency is stored in memory.
- Lines from these groups are compared with each other, and found matches are stored separately.
- Then new groups are loaded into the memory and also compared with each other.
Algorithm Example:
// improved version to reduce the disk I / O. nested_loop_join_v2 (file outer, file inner) for each bunch ba in outer // ba is now in memory for each bunch bb in inner // bb is now in memory for each row a in ba for each row b in bb if (match_join_condition ( a, b)) write_result_in_output (a, b) end if end for end for end for end for end for
In this case, the time complexity remains the same, but the number of disk accesses decreases: (the number of external groups + the number of external groups * the number of internal groups). As the size of the groups increases, the number of disk accesses decreases even more.Note: in this algorithm, a larger amount of data is read with each call, but this does not matter, since the calls are sequential.
- Hash join. This is a more complicated operation, but in many cases its cost is lower.

The algorithm is as follows:
- All elements are read from the internal dependency.
- A hash table is created in memory.
- One by one, all the elements from the external dependency are read.
- A hash is calculated for each element (using the corresponding function from the hash table) so that the corresponding block can be found in the internal dependency.
- Elements from a block are compared with elements from an external dependency.
- The internal dependency contains X blocks.
- The hash function distributes hashes almost equally for both dependencies. That is, all blocks have the same size.
- The cost of finding a correspondence between elements of an external dependency and all elements inside a block is equal to the number of elements inside the block.
(M / X) * (N / X) + hash table creation_ cost (M) + hash function cost * N
And if the hash function creates enough small blocks, then the time complexity will be equal to O (M + N).
There is another hash join method that saves more memory and does not require more I / O:
- Hash tables for both dependencies are calculated.
- Put on the disk.
- And then they are compared behaviorally with each other (one block is loaded into memory, and the second is read line by line).
The merge operation can be divided into two stages:
- (Optional) first, a join is performed by sorting, when both sets of input data are sorted by join keys.
- Then merge is carried out.
The merge sort algorithm has already been discussed above, in this case it justifies itself if it is important for you to save memory.
But it happens that the data sets are already sorted, for example:
- If the table is organized natively.
- If the dependency is an index in the presence of a join condition.
- If combining occurs with an intermediate sorted result.

This operation is very similar to the merge operation in the merge sort procedure. But instead of selecting all the elements of both dependencies, we select only equal elements.
- Two current elements of both dependencies are compared.
- If they are equal, then they are entered in the resulting table, and then the next two elements are compared, one from each dependency.
- If they are not equal, then the comparison is repeated, but instead of the smallest of the two elements, the next element is taken from the same dependence, since the probability of coincidence in this case is higher.
- Steps 1-3 are repeated until the elements of one of the dependencies end.
If both dependencies still need to be sorted, then the time complexity is O (N * Log (N) + M * Log (M)).
This algorithm works well because both dependencies are already sorted, and we don’t have to go back and forth across them. However, some simplification is allowed here: the algorithm does not handle situations when the same data occurs multiple times, that is, when multiple matches occur. In reality, a more complex version of the algorithm is used. For example:
MergeJoin (relation a, relation b) relation output integer a_key: \u003d 0; integer b_key: \u003d 0; while (a! \u003d null and b! \u003d null) if (a< b) a_key++; else if (a > b) b_key ++; else // Join predicate satisfied write_result_in_output (a, b) // We need to be careful when we increase the pointers integer a_key_temp: \u003d a_key; integer b_key_temp: \u003d b_key; if (a! \u003d b) b_key_temp: \u003d b_key + 1; end if if (b! \u003d a) a_key_temp: \u003d a_key + 1; end if if (b \u003d\u003d a && b \u003d\u003d a) a_key_temp: \u003d a_key + 1; b_key_temp: \u003d b_key + 1; end if a_key: \u003d a_key_temp; b_key: \u003d b_key_temp; end if end while
If there was a better way to combine, then all of these varieties would not exist. So the answer to this question depends on a bunch of factors:
- Available memory. If it's not enough, forget about the powerful hash join. At least, about its performance entirely in memory.
- The size of two sets of input data. If you have one table large and the second very small, then joining with nested loops will work the fastest because hash join involves an expensive procedure for creating hashes. If you have two very large tables, then joining using nested loops will consume all processor resources.
- Availability of indices. If you have two B-tree indexes, it is best to use merge union.
- Do I need to sort the result. You might want to use the expensive merge union (with sorting) if you are working with unsorted datasets. Then at the output you will get sorted data that is more convenient to combine with the results of another union. Or because the query indirectly or explicitly involves retrieving data sorted by ORDER BY / GROUP BY / DISTINCT statements.
- Are output dependencies sorted. In this case, it is better to use a merge union.
- What type of dependencies do you use. Equivalence union (table A. column 1 \u003d table B. column 2)? Internal dependencies, external, Cartesian product or self-join? In different situations, some combination methods do not work.
- Data distribution. If the data is rejected by the join condition (for example, you unite people by last name, but namesake names are often found), then in no case can you use a hash join. Otherwise, the hash function will create baskets with very poor internal distribution.
- Do I need to combine into several processes / threads.
4.4.4. Simplified examples
Suppose we need to combine five tables to get a complete picture of some people. Everyone can have:
- Several mobile phone numbers.
- Multiple email addresses.
- Several physical addresses.
- Several bank account numbers.
SELECT * from PERSON, MOBILES, MAILS, ADRESSES, BANK_ACCOUNTS WHERE PERSON.PERSON_ID \u003d MOBILES.PERSON_ID AND PERSON.PERSON_ID \u003d MAILS.PERSON_ID AND PERSON.PERSON_ID \u003d ADRESSES.PERSON_ID AND PERSON_ERSONERSONERSERSONERSERSONERSERSONERSERSONERSERSONERSERSONERSERSONERSERSONONERSERSONONERSERSONONERSERS_PONON_NERSID_PERSON_ERS_ON_ID_ID_ID_ID_ID_ID_ID_LINE_LINE
The optimizer needs to find the best way to process the data. But there are two problems:
- Which way to combine to use? There are three options (hash join, merge join, join using nested loops), with the possibility of using 0, 1 or 2 indexes. Not to mention the fact that indexes can also be different.
- In what order do you need to merge?

Based on the described, what are the options?
- Use the brute force approach. Using statistics, calculate the cost of each of the possible plans for fulfilling the request and choose the cheapest one. But there are quite a few options. For each merger order, you can use three different merge methods, for a total of 34 \u003d 81 possible execution plans. In the case of a binary tree, the problem of choosing the union order turns into a permutation problem, and the number of options is (2 * 4)! / (4 + 1)! .. As a result, in this very simplified example, the total number of possible plans for executing the request is 34 * (2 * 4)! / (4 + 1)! \u003d 27,216. If you add to this, when merging uses 0, 1, or 2 B-tree indexes, the number of possible plans rises to 210,000. Have we already mentioned that this is a VERY SIMPLE request?
- Cry and quit. Very tempting, but unproductive, and money is needed.
- Try a few plans and choose the cheapest. Once it’s impossible to calculate the cost of all possible options, you can take an arbitrary test data set and run all kinds of plans on it to evaluate their cost and choose the best one.
- Apply smart rules to reduce the number of possible plans.
There are two types of rules:- "Logical", with which you can exclude useless options. But they are far from always applicable. For example, “when combined using nested loops, the internal dependency should be the smallest set of data.”
- You can not look for the most profitable solution and apply more stringent rules to reduce the number of possible plans. Say, "if the dependency is small, we use join using nested loops, but never merge join or hash join."
So how does a database make a choice?
4.4.5. Dynamic programming, greedy algorithm and heuristic
A relational database uses different approaches, which were mentioned above. And the optimizer’s task is to find the right solution for a limited time. In most cases, the optimizer is not looking for the best, but just a good solution.
Bruteforce might work with small queries. And thanks to ways to eliminate unnecessary calculations, even for medium-sized queries, you can use brute force. This is called dynamic programming.
Its essence is that many execution plans are very similar.

In this illustration, all four plans use the A JOIN B subtree. Instead of calculating its cost for each plan, we can only calculate it once and then use this data as much as needed. In other words, with the help of memoization we solve the problem of overlap, that is, we avoid unnecessary calculations.
Thanks to this approach, instead of time complexity (2 * N)! / (N + 1)! we get “only” 3 N. In relation to the previous example with four associations, this means a decrease in the number of options from 336 to 81. If we take a query with 8 associations (a small query), then the complexity will decrease from 57 657 600 to 6 561.
If you are already familiar with dynamic programming or algorithmization, you can play around with this algorithm:
Procedure findbestplan (S) if (bestplan [S]. Cost infinite) return bestplan [S] // else bestplan [S] has not been computed earlier, compute it now if (S contains only 1 relation) set bestplan [S]. plan and bestplan [S]. cost based on the best way of accessing S / * Using selections on S and indices on S * / else for each non-empty subset S1 of S such that S1! \u003d S P1 \u003d findbestplan (S1) P2 \u003d findbestplan (S - S1) A \u003d best algorithm for joining results of P1 and P2 cost \u003d P1.cost + P2.cost + cost of A if cost< bestplan[S].cost
bestplan[S].cost = cost
bestplan[S].plan = “execute P1.plan; execute P2.plan;
join results of P1 and P2 using A”
return bestplan[S]
Dynamic programming can also be used for larger queries, but additional rules (heuristics) will have to be introduced to reduce the number of possible plans: 
Greedy
But if the request is very large, or if we need to get a response extremely quickly, another class of algorithms is used - greedy algorithms.
In this case, the query execution plan is built step by step using a certain rule (heuristic). Thanks to him, the greedy algorithm is looking for the best solution for each stage individually. The plan begins with a JOIN statement, and then at each stage a new JOIN is added in accordance with the rule.
Consider a simple example. Take a query with 4 joins of 5 tables (A, B, C, D, and E). We simplify the problem somewhat and imagine that the only option is to combine using nested algorithms. We will use the rule "apply the least cost combination".
- We start with one of the tables, for example, A.
- We calculate the cost of each association with A (it will be both in the role of external and internal dependence).
- We find that the cheapest is A JOIN B.
- Then we calculate the cost of each association with the result A JOIN B (we also consider it in two roles).
- We find that (A JOIN B) JOIN C. will be most profitable.
- Again, we evaluate the options.
- At the end, we get the following plan for executing the request: (((A JOIN B) JOIN C) JOIN D) JOIN E) /
This algorithm is called the “nearest neighbor algorithm”.
We will not go into details, but with good modeling of the complexity of sorting N * log (N) this problem can be. The time complexity of the algorithm is O (N * log (N)) instead of O (3 N) for the full version with dynamic programming. If you have a large query with 20 associations, then this will be 26 against 3,486,784,401. A big difference, right?
But there is a nuance. We assume that if we find the best way to combine the two tables, we will get the lowest cost when combining the result of previous joins with the following tables. However, even if A JOIN B is the cheapest option, then (A JOIN C) JOIN B may have a lower cost than (A JOIN B) JOIN C.
So if you desperately need to find the cheapest plan of all time, you can be advised to repeatedly run greedy algorithms using different rules.
Other algorithms
If you are already fed up with all of these algorithms, you can skip this chapter. It is not required for the assimilation of all other material.
Many researchers are concerned with finding the best plan for fulfilling a request. Often they try to find solutions for specific tasks and patterns. For example, for star-shaped joins, parallel query execution, etc.
We are looking for options for replacing dynamic programming to execute large queries. The same greedy algorithms are a subset of heuristic algorithms. They act in accordance with the rule, remember the result of one stage and use it to find the best option for the next stage. And algorithms that do not always use the solution found for the previous stage are called heuristic.
An example is genetic algorithms:
- Each decision is a plan for the full execution of the request.
- Instead of one solution (plan), the algorithm at each stage generates X decisions.
- First, X plans are created, this is done randomly.
- Of these, only those plans are preserved whose value satisfies a certain criterion.
- Then these plans are mixed to create X new plans.
- Some of the new plans are modified randomly.
- The previous three steps are repeated Y times.
- From the plans of the last cycle, we get the best.
By the way, genetic algorithms are integrated into PostgreSQL.
The database also uses heuristic algorithms such as Simulated Annealing, Iterative Improvement, and Two-Phase Optimization. But it’s not the fact that they are used in corporate systems, perhaps their destiny is research products.
4.4.6. True optimizers
Also an optional chapter, you can skip.
Let's move away from theorizing and consider real examples. For example, how the SQLite optimizer works. This is a “lightweight” database that uses simple optimization based on a greedy algorithm with additional rules:
- SQLite never changes the order of tables in a CROSS JOIN operation.
- Used union using nested loops.
- External associations are always evaluated in the order in which they were carried out.
- Up to version 3.8.0, the greedy Nearest Neighor algorithm is used to find the best plan for executing a request. And from version 3.8.0, “N nearest neighbors” (N3, N Nearest Neighbors) are used.
- Greedy Algorithms:
- 0 - minimum optimization. It uses index scanning, combining using nested loops, and eliminating the overwrite of some queries.
- 1 - low optimization
- 2 - full optimization
- Dynamic programming:
- 3 - average optimization and rough approximation
- 5 - full optimization, all heuristic techniques are used
- 7 - the same, but without heuristic
- 9 - maximum optimization at any cost, without regard to the efforts expended. All possible ways of combining, including Cartesian products, are evaluated.
- Collection of all possible statistics, including frequency distributions and quantiles.
- Application of all rules for rewriting queries, including creating a tabular route for materialized queries). The exception is rules requiring intensive computations, applied for a very limited number of cases.
- When enumerating union options using dynamic programming:
- Limited use of compound internal dependency.
- For star-shaped circuits with conversion tables, Cartesian products are used to a limited extent.
- A wide range of access methods is considered, including prefetching the list (more on that below), a special operation with AND indices, and compiling a tabular route for materialized queries.
Other conditions (GROUP BY, DISTINCT, etc.) are processed by simple rules.
4.4.7. Query Plan Cache
Because planning takes time, most databases store the plan in the query plan cache. This helps to avoid unnecessary calculations of the same steps. The database should know exactly when it needs to update outdated plans. For this, a certain threshold is set, and if the changes in the statistics exceed it, then the plan related to this table is deleted from the cache.
Query Executor
At this stage, our plan is already optimized. It is recompiled into executable code and, if there are enough resources, is executed. The operators contained in the plan (JOIN, SORT BY, etc.) can be processed both sequentially and in parallel, the decision is made by the executor. It interacts with the data manager to receive and record data.5. Data Manager

The query manager executes the query and needs data from tables and indexes. He requests them from the data manager, but there are two difficulties:
- Relational databases use a transactional model. It is impossible to get any desired data at a particular time, because at that time they can be used / modified by someone.
- Data extraction is the slowest operation in the database. Therefore, the data manager needs to be able to predict its work in order to fill the memory buffer in a timely manner.
5.1. Cache manager
As has been said more than once, the most bottleneck in the database is the disk subsystem. Therefore, a cache manager is used to increase performance.
Instead of receiving data directly from the file system, the requestor requests it from the cache manager. He uses the buffer pool contained in the memory, which allows to drastically increase the database performance. In figures, this is difficult to evaluate, since a lot depends on what you need:
- Serial access (full scan) or random access (access by line ID).
- Read or write.
However, here we are faced with another problem. The cache manager needs to put the data in memory BEFORE the query executor needs it. Otherwise, he will have to wait for them to be received from the slow disk.
5.1.1. Anticipation
The requestor knows what data he will need, since he knows the whole plan, what data is contained on the disk and statistics.
When the executor processes the first batch of data, he asks the cache manager to preload the next batch. And when he proceeds to its processing, he asks the DC to load the third and confirms that the first portion can be deleted from the cache.
The cache manager stores this data in the buffer pool. He also adds to them the service information (trigger, latch) to know whether they are still needed in the buffer.
Sometimes the contractor does not know what data he will need, or some databases do not have such functionality. Then, speculative prefetching is used (for example, if the contractor requests data 1, 3, 5, then it will probably request 7, 9, 11 in the future) or sequential prefetching (in this case, the DC simply loads the next a chunk of data.
Do not forget that the buffer is limited by the amount of available memory. That is, to load some data we have to periodically delete others. Filling and flushing the cache consumes part of the resources of the disk subsystem and network. If you have a frequently executed query, it would be counterproductive to load and clear the data it uses every time. To solve this problem, modern databases use a buffer replacement strategy.
5.1.2. Buffer Replacement Strategies
Most databases (at least SQL Server, MySQL, Oracle, and DB2) use the LRU (Least Recently Used) algorithm for this. It is designed to maintain in the cache those data that were recently used, which means that it is likely that they may be needed again.

To facilitate understanding of the algorithm, we assume that the data in the buffer is not blocked by triggers (latch), and therefore can be deleted. In our example, the buffer can store three pieces of data:
- The cache manager uses data 1 and puts it in an empty buffer.
- Then it uses the data 4 and also sends them to the buffer.
- The same thing is done with data 3.
- Next, data is taken 9. But the buffer is already full. Therefore, data 1 is deleted from it, since it has not been used for the longest. After that, data 9 is placed in the buffer.
- The cache manager uses the data 4 again. It is already in the buffer, so it is marked as the last used.
- Data 1 is again in demand. In order to put it into the buffer, data 3 is deleted from it, as if it were not used the longest.
Algorithm Improvements
To prevent this from happening, some databases use special rules. According to Oracle documentation:
“For very large tables, direct access is usually used, that is, data blocks are read directly to avoid cache buffer overflows. For medium-sized tables, both direct access and reading from the cache can be used. If the system decides to use the cache, the database places data blocks at the end of the LRU list to prevent buffer clearing. ”
An improved version of LRU - LRU-K is also used. SQL Server uses LRU-K with K \u003d 2. The essence of this algorithm is that when evaluating a situation, it takes into account more information about past operations, and not only remembers the last data used. The letter K in the name means that the algorithm takes into account which data was used the last K times. They are assigned a certain weight. When new data is loaded into the cache, the old, but often used data is not deleted, because its weight is higher. Of course, if the data is no longer used, it will still be deleted. And the longer the data remains unclaimed, the more its weight decreases over time.
Calculation of the weight is quite expensive, therefore, in SQL Server, LRU-K is used with K equal to only 2. With a slight increase in K, the efficiency of the algorithm improves. You can get to know him better thanks.
Other algorithms
Of course, LRU-K is not the only solution. There are also 2Q and CLOCK (both similar to LRU-K), MRU (Most Recently Used, which uses LRU logic, but another rule is applied, LRFU (Least Recently and Frequently Used), etc. In some databases, you can choose which algorithm will be used.
5.1.3. Write buffer
We talked only about the read buffer, but DBs also use write buffers, which accumulate data and flush portions to the disk instead of sequential writes. This saves I / O.
Remember that buffers store pages (indivisible data units), not series from tables. A page in the buffer pool is called dirty if it is modified but not written to disk. There are many different algorithms by which you select the recording time of dirty pages. But this is largely due to the concept of transactions.
5.2. Transaction manager
His responsibilities include tracking so that each request is executed using his own transaction. But before we talk about the dispatcher, let's clarify the concept of ACID transactions.5.2.1. “Under the acid” (pun, if anyone doesn’t understand)
An ACID transaction (Atomicity, Isolation, Durability, Consistency) is an elementary operation, a unit of work that satisfies 4 conditions:
- Atomicity There is nothing less than a transaction, no smaller operation. Even if the transaction lasts 10 hours. In case of unsuccessful transaction, the system returns to the “before” state, that is, the transaction is rolled back.
- Isolation. If two transactions A and B are executed at the same time, their result should not depend on whether one of them completed before, during or after the execution of the other.
- Reliability (Durability). When the transaction is commited, that is, successfully completed, the data used by it remains in the database regardless of possible incidents (errors, crashes).
- Consistency (Consistency). Only valid data is written to the database (in terms of relational and functional relationships). Consistency depends on atomicity and isolation.

During the execution of a transaction, you can execute various SQL queries for reading, creating, updating, and deleting data. Problems begin when two transactions use the same data. A classic example is the transfer of money from account A to account B. Let's say we have two transactions:
- T1 takes $ 100 from account A and sends them to account B.
- T2 takes $ 50 from account A and also sends them to account B.
- Atomicity allows you to be sure that no matter what happens during T1 (server crash, network failure), it cannot happen that $ 100 will be debited from A, but will not come to B (otherwise, they speak of an “inconsistent state”).
- Isolation says that even if T1 and T2 are carried out simultaneously, as a result $ 100 will be debited from A and the same amount will go to B. In all other cases, they again talk about an inconsistent state.
- Reliability allows you not to worry about the fact that T1 will disappear if the base falls immediately after the T1 commit.
- Consistency prevents the possibility of creating money or its destruction in the system.
Many databases do not provide complete isolation by default, as this leads to huge performance overheads. SQL uses 4 isolation levels:
- Serializable transactions. The highest level of isolation. Used by default in SQLite. Each transaction is executed in its own, completely isolated environment.
- Repeatable read Used by default in MySQL. Each transaction has its own environment, except for one situation: if the transaction adds new data and succeeds, they will be visible to other transactions that are still in progress. But if the transaction modifies data and succeeds, these changes will not be visible to transactions that are still in progress. That is, for new data, the principle of isolation is violated.
For example, transaction A executes
SELECT count (1) from TABLE_X
Then transaction B adds to table X and commits the new data. And if after that transaction A again executes count (1), then the result will be different.This is called phantom reading.
- Read Committed Data. Used by default in Oracle, PostgreSQL, and SQL Server. This is the same as repeated reading, but with an additional violation of isolation. Suppose transaction A reads data; they are then modified or deleted by transaction B, which commits these actions. If A again considers this data, then she will see the changes (or the fact of deletion) made by B.
This is called non-repeatable read.
- Read uncommited data. The lowest level of isolation. A new violation of isolation is added to reading captured data. Suppose transaction A reads data; then they are modified by transaction B (changes are not committed, B is still being executed). If A reads the data again, then he will see the changes made. If B is pumped back, then upon repeated reading, A will not see the changes, as if nothing had happened.
This is called dirty reading.
Most databases add their own isolation levels (for example, based on snapshots, as in PostgreSQL, Oracle and SQL Server). Also, in many databases, all four of the above levels are not implemented, especially reading uncommitted data.
The user or developer can immediately override the default isolation level after establishing a connection. To do this, just add a very simple line of code.
5.2.2. Concurrency management
The main thing for which we need isolation, consistency and atomicity is the ability to perform write operations on the same data (add, update and delete).
If all transactions will only read data, then they will be able to work simultaneously, without affecting other transactions.
If at least one transaction changes the data read by other transactions, then the database needs to find a way to hide these changes from them. You also need to make sure that the changes made will not be deleted by other transactions that do not see the changed data.
This is called concurrency management.
The easiest way is to simply execute transactions one at a time. But this approach is usually inefficient (only one core of one processor is involved), and besides, the ability to scale is lost.
The ideal way to solve the problem is as follows (each time a transaction is created or canceled):
- Monitor all operations of each transaction.
- If two or more transactions conflict due to reading / changing the same data, then change the sequence of operations within the parties to the conflict in order to minimize the number of reasons.
- Perform conflicting parts of transactions in a specific order. Non-conflicting transactions at this time are performed in parallel.
- Keep in mind that transactions can be canceled.
5.2.3. Lock manager
To solve the above problem, many databases use locks and / or versioned data.
If transactions need some data, then it blocks them. If they also needed another transaction, then it will have to wait until the first transaction releases the lock.
This is called an exclusive lock.
But it’s too wasteful to use exclusive locks in cases where transactions only need to read data. Why bother reading data? In such cases, shared locks are used. If transactions need to read data, they apply a joint lock to them and reads. This does not prevent other transactions from using joint locks and reading data. If any of them needs to change the data, then she will have to wait until all joint locks are released. Only then can she apply an exclusive lock. And then all other transactions will have to wait for its withdrawal in order to read this data.

A lock manager is a process that applies and removes locks. They are stored in a hash table (the keys are locked data). The dispatcher knows for all data which transactions have applied locks or are waiting for them to be removed.
Deadlock
Using locks can lead to a situation where two transactions endlessly wait for locks to be released:

Here, transaction A has exclusively locked data 1 and is waiting for the release of data 2. At the same time, transaction B has exclusively locked data 2 and is waiting for the release of data 1.
With a mutual lock, the dispatcher chooses which transaction to cancel (roll back). And the decision to make is not so simple:
- Would it be better to kill a transaction that changed the last data set (which means rollback would be the least painful)?
- Would it be better to kill the youngest transaction, as users of other transactions have waited longer?
- Would it be better to kill a transaction that takes less time to complete?
- How many other transactions will rollback affect?
Imagine the hash table in the form of a diagram, as in the illustration above. If there is a cyclic connection in the diagram, the deadlock is confirmed. But since checking for the presence of cycles is quite expensive (because the diagram on which all the locks are displayed will be very large), a simpler approach is often used: the use of timeouts. If the lock is not released within a certain time, then the transaction has entered a state of mutual lock.
Before imposing a lock, the dispatcher can also check if this will lead to a deadlock. But in order to unequivocally answer this, one also has to spend money on calculations. Therefore, such pre-checks are often presented as a set of basic rules.
Biphasic blocking
The easiest way to ensure complete isolation is when the lock is applied at the beginning and is removed at the end of the transaction. This means that transactions have to wait until all locks are released before starting, and the locks used by it are released only at the end. This approach can be applied, but then a lot of time is wasted on all these expectations of unlocking.
DB2 and SQL Server use a two-phase locking protocol, in which a transaction is divided into two phases:
- Phase of rise (growing phase)when a transaction can only apply locks but not release them.
- Shrinking phasewhen a transaction can only release locks (from data that has already been processed and will not be processed again), but not apply new ones.

Before transaction A, X \u003d 1 and Y \u003d 1. It processes the data Y \u003d 1, which was changed by transaction B after the start of transaction A. Due to the principle of isolation, transaction A must process Y \u003d 2.
Goals to be achieved with these two simple rules:
- Release locks that are no longer needed to reduce the latency of other transactions.
- To prevent cases when a transaction receives data modified by a previously launched transaction. Such data does not match the requested.
Of course, real databases use more complex systems, more types of locks and with greater granularity (blocking rows, pages, partitions, tables, table spaces), but the essence is the same.
Data versioning
Another way to solve the transaction conflict problem is to use data versioning.
- All transactions can modify the same data at the same time.
- Each transaction works with its own copy (version) of data.
- If two transactions change the same data, then only one of the modifications is accepted, the other will be rejected, and the transaction that made it will be rolled back (and maybe restarted).
- Reading transactions do not block writing, and vice versa.
- The slow lock manager has no effect.
Both approaches - locking and versioning - have pros and cons, a lot depends on the situation in which they are used (more reads or more records). You can study a very good presentation on the implementation of multi-version concurrency management in PostgreSQL.
Some databases (DB2 prior to version 9.7, SQL Server) use only locks. Others, like PostgreSQL, MySQL, and Oracle, use combined approaches.
Note: versioning has an interesting effect on indexes. Sometimes duplicates appear in a unique index, the index may contain more records than rows in the table, etc.
If part of the data is read at one level of isolation, and then it increases, then the number of locks increases, which means that more time is spent waiting for transactions. Therefore, most databases do not use the maximum isolation level by default.
As usual, for more information, refer to the documentation: MySQL, PostgreSQL, Oracle.
5.2.4. Log manager
As we already know, for the sake of increasing productivity, the database stores part of the data in buffer memory. But if the server crashes during a transaction commit, then the data in memory will be lost. And this violates the principle of transaction reliability.
Of course, you can write everything to disk, but if you fall, you will be left with incomplete data, and this is a violation of the principle of atomicity.
Any changes recorded by the transaction must be rolled back or completed.
This is done in two ways:
- Shadow copies / pages. Each transaction creates its own copy of the database (or part of it), and works with this copy. In case of an error, the copy is deleted. If everything went well, then the database instantly switches to the data from the copy with a single trick at the file system level, and then deletes the "old" data.
- Transaction log This is a special repository. Before each write to disk, the database writes information to the transaction log. So in the event of a failure, the database will know how to delete or complete an incomplete transaction.
In large databases with many transactions, shadow copies / pages take up an incredibly large amount of space in the disk subsystem. Therefore, in modern databases, a transaction log is used. It must be located in a fault-proof repository.
Most products (in particular, Oracle, SQL Server, DB2, PostgreSQL, MySQL, and SQLite) work with the transaction log via the WAL (Write-Ahead Logging) protocol. This protocol contains three rules:
- Each modification in the database must be accompanied by a record in the log, and it must be made BEFORE the data is written to disk.
- Log entries should be arranged in accordance with the sequence of relevant events.
- When a transaction is committed, a record of this should be logged BEFORE the transaction is successfully completed.

These rules are monitored by the log manager. Logically, it is located between the cache manager and the data access manager. The log manager registers every operation performed by transactions until it is written to disk. It seems right?
WRONG! After everything that you and I went through in this article, it's time to remember that everything related to the database is subject to the curse of the “database effect”. Seriously, the problem is that you need to find a way to write to the log, while maintaining good performance. After all, if the transaction log is slow, then it slows down all other processes.
Aries
In 1992, IBM researchers created an extended version of WAL called ARIES. In one form or another, ARIES is used by most modern databases. If you want to study this protocol more deeply, you can study the corresponding work.
So ARIES stands for Algorithms for Recovery and Isolation Exploiting Semantics. This technology has two tasks:
- Provide good logging performance.
- Provide fast and reliable recovery.
- User canceled it.
- Server or network error.
- The transaction violated the integrity of the database. For example, you applied a UNIQUE clause to a column, and the transaction added a duplicate.
- The presence of mutual locks.
How is this possible? To answer this, you first need to figure out what information is stored in the log.
Logs
Each operation (add / delete / change) during the execution of the transaction leads to the appearance of a log entry. The entry contains:
- LSN (Log Sequence Number). This is a unique number whose value is determined in chronological order. That is, if operation A occurred before operation B, the LSN for A will be less than the LSN for B. In reality, the method of generating the LSN is more complicated, since it is also associated with the method of storing the log.
- TransID The identifier of the transaction that performed the transaction.
- PageID. The disk space where the changed data is located.
- PrevLSN. Link to the previous log entry created by the same transaction.
- Undo. The way to roll back the operation.
For example, if an update operation was performed, then the previous value / state of the changed element (physical UNDO) or the inverse operation that allows you to return to the previous state (logical UNDO) is written to UNDO. ARIES uses only the logical, it is very difficult to work with the physical.
- REDO. The way to repeat the operation.
As far as I know, UNDO is not used only in PostgreSQL. Instead, a garbage collector is used to clean up older versions of data. This is due to the implementation of data versioning in this DBMS.
To make it easier for you to imagine the composition of the entry in the log, here is a visual simplified example in which the query UPDATE FROM PERSON SET AGE \u003d 18; is executed. Let it be executed in transaction number 18:

Each log has a unique LSN. Linked logs refer to the same transaction, and they are linked in chronological order (the last log of the list refers to the last operation).
Log buffer
To prevent the log entry from becoming a system bottleneck, the log buffer is used.

When the requestor requests the modified data:
- The cache manager stores them in a buffer.
- The log manager stores the corresponding log in its own buffer.
- The requestor determines whether the operation is completed and, accordingly, whether the changed data can be requested.
- The log manager saves the necessary information in the transaction log. The moment of making this entry is set by the algorithm.
- The cache manager writes the changes to disk. The moment of recording is also set by the algorithm.
STEAL and FORCE Policies
To increase productivity, step 5 must be done after the commit, because in the event of a failure it is still possible to restore the transaction using REDO. This is called a NO-FORCE policy.
But the database can choose the FORCE policy to reduce the load during recovery. Then step number 5 is performed before the commit.
The database also selects whether to write data to the disk step by step (STEAL policy) or, if the buffer manager should wait for a commit, write everything all at once (NO-STEAL). The choice depends on what you need: fast recording with a long recovery or fast recovery?
How the policies mentioned affect the recovery process:
- STEAL / NO-FORCE needs UNDO and REDO. Performance is the highest, but more complex structure of logs and recovery processes (like ARES). This combination of policies is used by most databases.
- For STEAL / FORCE, only UNDO is needed.
- For NO-STEAL / NO-FORCE - only REDO.
- For NO-STEAL / FORCE nothing is needed at all. Performance in this case is the lowest, and a huge amount of memory is required.
So, how can we use our wonderful logs? Suppose a new employee has destroyed the database (rule # 1: the newbie is always to blame!). You restart it and the recovery process begins.
ARIES restores in three steps:
- Analysis. The entire transaction log is read so that you can restore the chronology of events that occurred during the fall of the database. This helps determine which transaction needs to be rolled back. All transactions are rolled back without an order to commit. The system also decides which data should be written to disk during the crash.
- Replay. REDO is used to update the database to the state before the crash. Its logs are processed in chronological order. For each log, the LSN of the page on the disk containing the data that needs to be changed is read.
If LSN (disk_page)\u003e \u003d LSN (log_log), then the data has already been written to disk before the failure. But the value was overwritten by the operation that was performed after writing to the log and before the failure. So nothing has been done, actually.
If LSN (drive_page)
Repeat is even performed for transactions that will be rolled back, because it simplifies the recovery process. But modern databases probably do not.
- Cancel At this stage, all transactions that were not completed at the time of the failure are rolled back. The process begins with the last logs of each transaction and processes UNDO in reverse chronological order using PrevLSN.
If the transaction is canceled "manually" either by the lock manager or due to a network failure, then the analysis step is not needed. Indeed, the information for REDO and UNDO is contained in two tables located in memory:
- In the transaction table (the status of all current transactions is stored here).
- The table of dirty pages (here contains information about what data you need to write to disk).
The analysis stage is needed just to restore both tables using information from the transaction log. To accelerate this step, ARIES uses breakpoints. The contents of both tables are written to the disk from time to time, as well as the last at the time of LSN recording. So during recovery, only the logs following that LSN are analyzed.
6. Conclusion
As an additional overview on databases, you can recommend the article Architecture of a Database System. This is a good introduction to a topic written in a fairly understandable language.If you carefully read all of the above material, then you probably got an idea of \u200b\u200bhow great the capabilities of the databases are. However, this article does not address other important issues:
- How to manage clustered databases and global transactions.
- How to get a snapshot if the database is working.
- How to effectively store and compress data.
- How to manage memory.
So, if someone asks you how the databases work, then instead of spitting and leaving, you can answer:

Tags: Add Tags
2. The principles of the relational model
The principles of the relational database model, relation, table, result set, tuple, power, attribute, dimension, header, body, domain
The relational model was developed in the late 1960s by EF Koddom (an IBM employee) and published in 1970. It defines the way data is presented (data structure), data protection methods (data integrity), and operations that can be performed with data (data manipulation).
The relational model is not the only one that can be used when working with data. There is also a hierarchical model, a network model, a star-shaped model, etc. However, the relational model turned out to be the most convenient and therefore is now used most widely.
The basic principles of relational databases can be formulated as follows:
· All data at a conceptual level is presented in the form of an ordered organization, defined in the form of rows and columns and called a relation. The more common synonym for the word “relation” is a table (or “record set”, or a result set - result set. This is what the term “relational databases” comes from, and not from relations between tables;
· All values \u200b\u200bare scalars. This means that for any row and column of any relation, there is one and only one value;
· All operations are performed on the whole relation and the result of these operations is also the whole relation. This principle is called closure. Therefore, the results of one operation (for example, a query) can be used as input to perform another operation (subquery).
Now - about formal terminology:
· the attitude (relation) - this is the whole structure, a set of records (in the usual sense - a table).
· motorcade is every row containing data. A more common but less formal term is recording.
· power - the number of tuples in relation (in other words, the number of records);
· attribute - this is a column in relation;
· dimension - this is the number of attributes in relation (in this case - 3);
· Each relationship can be divided into two parts - heading and body. In simple language, the relationship header is a list of columns, and the body is the records themselves (tuples).
· In our example, the name of each column (attribute) consists of two words separated by a colon. According to formal definitions, the first part is attribute name (column name), and the second part is domain (the kind of data that the data column represents). The concepts of "domain" and "data type" are not equivalent to each other. In practice, the domain is usually omitted.
· The relationship body consists of an unordered set of tuples (its number can be any - from 0 to infinitely large).
Melnikova 620000 Russia, Sverdlovsk region, Yekaterinburg. +7 953 039 559 1 [email protected]site

Relational database - This is related information presented in the form of two-dimensional tables. Imagine an address book. It contains many lines, each of which corresponds to a given individual. For each of them, it presents some independent data, for example, name, phone number, address. Imagine this address book in the form of a table containing rows and columns. Each row (also called a record) corresponds to a specific individual, each column contains values \u200b\u200bof the corresponding data type: name, phone number and address, presented in each row. The address book may look like this:
What we got is the basis of the relational database, defined at the beginning of our discussion of a two-dimensional (row and column) information table. However, a relational database rarely consists of a single table that is too small compared to the database. When you create multiple tables with related information, you can perform more complex and powerful data operations. The power of the database lies, rather, in the relationships that you construct between the pieces of information than in the pieces themselves.
Let's use the example of an address book to discuss a database that can really be used in business life. Suppose the individuals in the first table are hospital patients. Additional information about them can be stored in another table. The columns of the second table can be named this way: Patient (Patient), Doctor (Doctor), Insurer (Insurance), Balance (Balance).
You can perform many powerful functions when extracting information from these tables in accordance with specified criteria, especially if the criterion includes related pieces of information from different tables.
Suppose Dr. Halben wishes to receive the telephone numbers of all his Patients. In order to extract this information, he must link the table with the phone numbers of the patients (address book) with the table identifying his patients. In this simple example, he can mentally perform this operation and find out the phone numbers of his patients Grillet and Brock, but in reality these tables can very well be larger and much more complicated.
Programs that process relational databases were created to work with large and complex sets of data that are the most common in the business life of society. Even if the hospital database contains tens or thousands of names (as is likely to be the case in real life), a single SQL command will provide Dr. Halben with the necessary information almost instantly.
The order of the lines is arbitrary.
To provide maximum flexibility when working with data, table rows are, by definition, not ordered in any way. This aspect distinguishes the database from the address book. Lines in the address book are usually sorted alphabetically. One of the powerful tools provided by relational database systems is that users can organize information as they wish.
Consider the second table. The information contained in it is sometimes convenient to consider ordered by name, sometimes in ascending or descending balance (Balance), and sometimes grouped by doctor. An impressive array of possible row orders would prevent the user from being flexible with the data, so the rows are assumed to be disordered. It is for this reason that you cannot simply say: "I am interested in the fifth row of the table." Regardless of the order in which data is included or some other criterion, this fifth row does not exist by definition. So, table rows are supposed to be arranged in random order.
Row Identification (Primary Key)
For this and a number of other reasons, you must have a table column that uniquely identifies each row. Usually this column contains a number, for example, assigned to each patient. Of course, you can use the name of the patient to identify the strings, but it may happen that there are several patients named Mary Smith. In such a case, there is no easy way to distinguish between them. It is for this reason that numbers are commonly used. Such a unique column (or group of them), used to identify each row and ensure that all rows are distinguishable, is called the primary key of the table.
Table primary key - The vital concept of database structure. It is the heart of a data system: in order to find a particular row in a table, specify the value of its primary key. In addition, it ensures data integrity. If the primary key is properly used and maintained, you will be firmly convinced that not a single row of the table is empty and that each of them is different from the rest.
Columns are numbered and numbered.
Unlike rows, table columns (also called fields) are ordered and named. Therefore, in our table corresponding to the address book, we can refer to the “Address” column as “column number three.” Naturally, this means that each the column of this table must have a name that is different from other names so that there is no confusion. It is best when the names determine the contents of the field. In this book we will use the abbreviation for naming columns in simple tables, for example: cname - for the name of the buyer (customer name), odate - for the date of receipt (order date). Suppose also that the table contains a single digital column used as the primary key.
Tables 1.1, 1. 2, 1.3 form a relational database that is small enough to understand its meaning, but also complex enough to illustrate important concepts and practical conclusions related to the use of SQL using its example.
You may notice that the first column in each table contains numbers that do not repeat from row to row within the table. As you probably guessed, these are the primary keys of the table. Some of these numbers also appear in columns of other tables (there is nothing reprehensible in this), which indicates a relationship between rows using a particular primary key value and the row in which this value is applied directly in the primary key.
For example, the snum field in the Customers table determines which seller (salespeople) is serving a particular customer. The snum field number establishes a link to the Salespeople table, which provides information about this salespeople. Obviously, the seller who serves this buyer exists, i.e. the value of the snum field in the Customers table is also present in the Salespeople table. In this case, we say that the system is in a state of referential integrity.
The tables themselves are intended to describe real situations in business life when you can use SQL to conduct business related to sellers, their customers and orders. Let's fix the state of these three tables at some point in time and clarify the purpose of each of the fields in the table.
Here is an explanation of the columns in table 1.1:
Table 1.2 contains the following columns:
And finally, the columns of table 1.3.