Привет, пацаны! Все вы прекрасно знаете, что я уже давно барыжу ключевыми словами. В смысле, давно уже занимаюсь этим на коммерческой основе.
Все те свои услуги, которые я описал , уже давно были мною многократно расширены. Обращаются разные извращенцы, которые придумывают такие задания, что я бы раньше и подумать не мог. Ну и я постепенно матерею за счет того, что они вынуждают меня выполнять их сложные задания
Наверно, все помнят, что я много раз писал про базы пастухова: давным давно я рассказал, что представляет собой этот офигительный софт — , потом рассказал о том, что Максим Пастухова (автор софта) анонсировал выход 180-миллионной русской базы ключевых слов. Это .
Но вот недавно я делал проект для сайта одного солидного человека. Проект был исключительно под Яндекс. Я отпарсил его сайт, нашел ключи, по которым он уже занимает нормальные позиции в выдаче, оценил эти ключи с помощью вордстата, рамблера, Rookee… все, на этом тормозим.
В итоге получается список хороших ключей. Но! Из них получается много неоднозначных ключей. Вот они

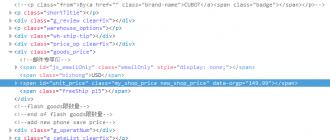
То есть, берем к примеру ключ «радио радио слушать онлайн ». Смотрим частотность по wordstat. Здесь на скриншоте указана точная частотность. То есть, использовался оператор «!слово!слово». И что же видим? Что этот кей имеет частотность 563141 для моего региона, для которого делался анализ.
Меня клиент сразу спрашивает: «Сергей, что за херня? Откуда у несчастного «радио радио слушать онлайн » 563141 показов в месяц?» И прогноз переходов Rookee показывает -1 переход по этому ключику, что означает, что хз, сколько этих переходов будет. То есть, это говорит о том, что их будет 0.
И я потом только допер, что епта, ведь это отличная идея для поста – расписать эту залепу, которая есть в вордстате, тем более, что и Маул недавно про это писал. Только я расскажу про это со своей колокольни, и еще покажу вдобавок, как эта проблема решается.
А что залепа, то залепа. Вот как понять, что это такое на самом деле? Первое, что приходим на ум – пойти в хелп самого Вордстата, да почитать, что они сами об этом пишут. Но нет, единственное, что видим:
И что в итоге? А ничего! Из того что здесь написано, ни фига не понятно, почему мля по запросу «радио радио слушать онлайн » такое большое количество показов.
А на самом деле эта залепа имеет простое объяснение. Открываем свеженькие базы пастухова на 180 млн. кеев, делаем выборку из базы по ключевому слову «радио слушать онлайн»

Думаю, те, кто часто копаются в вордстате, прекрасно понимают, что выдернуть оттуда такие вот ключевые слова — это почти нереально.
Это, кстати, не самые длинные ключевые слова. В базах пастухова я добавил отображение частотности по wordstat.yandex. Смотрите, есть и покруче, вернее, подлиннее ключики

Или вот еще
Понятно, 10-ти словник «интернет радио онлайн слушать бесплатно европа плюс mediaplayer classic » не может иметь частотности, а если и может, то она настолько ничтожная, что не отображается в wordstat. Но дело в том, что вот такие вот многословники и создают эту залепу с ключевыми словами. Смотрите сами

Что здесь видим? Видим, что десятисловник » имеет частоту 5967, что само по себе представляется какой-то утопией.
Так почему же так получается?
Есть одна особенность в вордстате – в нем похер порядок ключевых слов, в связи с чем если не понимаешь всего этого механизма, то можно тупо просаживать баблос, двигая в перспективе ключевые слова, не дающие на выходе трафа.
Все это очень хорошо видно, когда в базах пастухова добавляем колонку со статистикой запросов в Рамблер, в котором порядок слов не похер . Тогда картина становится сразу ясна, и мы видим, для каких запросов есть система, а для каких нет. То есть, какие запросы вводят регулярно, какие действительно можно продвигать, а какие просто создают статистику для таких вот залеп, которые я показал выше. Здесь в базах пастухова особенно зашибенно то, что можно сразу прикинуть частотности Яндекса и Рамблера по отдельно взятому ключевику

Я здесь специально сгруппировал запросы, чтобы было понятно. То есть, в идеале, если продвигать, то брать такие ключи, где будет частота и по Рамблеру и по Яндексу. Но это в идеале.
И все же, как так, что 10-ти словный запрос с повторяющимися словами может иметь частоту 5967?
Я хз если честно, почему в хелпе вордстата не расписали, почему же такое вот может быть. Но суть вот в чем.
Как уже писал выше, в Яндексе вводят множество запросов, среди которых много и десятисловных. И даже больше. Из вордстата эту информацию часто не вытянуть, зато хорошо все эти ключи показывают базы пастухова (примечание — теперь уже закрытый проект). А сама разгадка кроется в том, что дублирующиеся слова не учитываются непосредственно в запросе.
То есть, запрос «!радио!радио!радио!радио!радио!радио!радио!радио!слушать!онлайн », имеющий частоту 5967, на самом деле в точно таком же виде не показывается столько, сколько это отображает вордстат. Здесь учитывается только словосочетание «радио слушать онлайн». То есть, последние три слова. А вместо предыдущих 7 слов «радио» могут употребляться абсолютно разные слова. И все это создает статистику для вот этого десятисловника. Я специально в базах пастухова сделал выборку полученных результатов по «радио слушать онлайн». Там можно сортировать и по длине поисковых запросов, и по количеству слов

И в итоге мы получаем все (или почти все) ключевые слова-десятисловники, которые и делают статистику для нашего «!радио!радио!радио!радио!радио!радио!радио!радио!слушать!онлайн ». Вот они:

И таких десятисловников более чем предостаточно. То есть, еще раз повторяюсь, что вместо слова «радио» может быть любое другое слово, лишь бы оно входило в десятисловник, который содержит словосочетание «радио слушать онлайн».
Ситуация не была бы настолько неоднозначной, если бы вордстат показывал ключевые слова в точно таком же порядке, как они запрашиваются. Но ведь нет. В нашем десятисловнике вместо слова «радио» могут быть любые другие слова, и все они могут меняться местами внутри этого десятисловника, тем самым накручивая его показатель в вордстате.
Вот поэтому и получается, что запрос «радио радио слушать онлайн » на самом деле в точно такой же последовательности и с точно такими же словами, как здесь указано, не имеет частоту 563141 и никогда не имел. А такая цифра получается, потому что вместо первого слова «радио» может быть любое другое, и может оно стоять на любом месте в рамках этого четырехсловника, что и образует в конечном итоге такую большую цифру в 563141. И таких четырехсловников разной интерпретации превеликое множество
Огромная роль в поисковом продвижении сайта отводится грамотности составлении семантического ядра и распределении поисковых запросов по страницам ресурса.
Именно от этого во многом и будет зависеть судьба проекта, по этой причине важно уделять особое внимание подбору ключевых запросов, по которым в дальнейшем планируется в Гугле и Яндексе, я этой теме посветил не одну статью, но думаю, что для начинающих нужно разжевать еще подробней, вот к примеру одна из моих статей — , там я рассказал о подборе ключевых слов и оценке их конкурентности в системе от Google — adwords.google.com и сегодня на блоге , более подробно рассмотрим все это.
Но при всем при этом смотрите, не перестарайтесь с насыщенностью ключевиков на вашем интернет проекте, читай — .
1.1.Частотность поисковых запросов
Популярность ключевого слова можно определить его частотностью. Чем выше частотность, тем выгоднее оказывается по поисковому запросу, так как по нему на ресурс может попасть большее количество посетителей.
Частотность можно определить специальными сервисами статистики поисковых запросов. Такие сервисы содержат информацию о том, как часто пользователи вводят в поисковых системах тот или иной ключ (ключевой запрос).

На картинке, представленной выше, видна статистика ключевого выражения “раскрутка сайта”. В подобных случаях может использоваться сервис wordstat.yandex.ru, отображающий, насколько часто пользователи набирали данный запрос в поисковой системе Яндекс .
Вот смотрите подробное видео по работе в wordstat.yandex:
Так как этим сервисом пользуются примерно 55% пользователей интернета, то точную статистику ключа можно определить, прибавив к полученной цифре недостающие 40%.
Кроме того, по частотности ключевые запросы принято делить на три большие группы:
- высокочастотные;
- среднечастотные;
- низкочастотные.
Строгих цифр и рамок в подобных делах нет, всё носит лишь приблизительный характер. Но, как правило, низкочастотными запросами принято считать запросы с показателем менее 1000 запросов/месяц, среднечастотными – 1000-5000, тогда как высокочастотными – более 5000.
Иногда приходится сталкиваться с таким термином, как сверхнизкочастотные запросы, который подразумевает под собой запросы с показателем, не превышающим значение 30-100 запросов в месяц.
Между тем, подобное разделение запросов на группы будет зависеть от тематики самого запроса. К примеру, для запросов коммерческих тем указанные планки будут ниже, тогда как для развлекательных – выше.
Нужно упомянуть и LongTail-запросах, которые содержат в себе огромное количество слов, от чего и пошло название (“длинный хвост”). По такому виду запросов бессмысленно, что обусловлено их низкой частотностью.
Но такие ключи могут привести на площадку 50-80% всех посетителей. Как правило, в подобных случаях сайт продвигаться самостоятельно, не требуя дополнительных затрат и seo-оптимизации, то есть вы написали и оптимизировали статью под один ключевой запрос, а она вышла в топ по тысячи микро частотных (1-10 запросов в месяц) и это называется — LongTail — длинный хвост запросов!!
2.2. Операторы Гугла
В таблице приведены команды поисковой системы Гугл. Ознакомиться с операторами можно по ссылке.
2.3. Подбор ключевых слов
В большинстве случаев поисковые запросы подбираются с помощью сервисов статистики, но существуют и другие методики.
3. Сервисы статистики для подбора поисковых запросов
На сегодняшний день это самый популярный способ получения статистики поисковых запросов. Такие сервисы бесплатны, что и сделало их популярными. Но нужно помнить, что сервис отражает только те данные, которые ему доступны.
- Яндекс Вордстат . Сервис охватывает примерно 55% данных об основных поисковых запросах, что сделало сервис популярным при составлении семантического ядра для сайтов на русском языке. Можно подбирать основные и ассоциативные запросы.
- Гугл. Адвордс . Сервис обрабатывает примерно 30% поисковых запросов. Сегодня это второй по популярности сервис статистики. Функционал аналогичен сервису от Яндекс.
- Рамблер.Адстат. Сервис занимает третье место, но его результат всего лишь 5%. Редко используется вебмастерами.
3.1. Поиск перспективных запросов
Перечисленные сервисы являются не единственными, поэтому иногда можно воспользоваться и более оригинальными способами.
3.2. Анализ LiveInternet
Это сервис знаменитейшего счётчика, содержащий в себе огромнейшую статистику поисковых запросов, которую можно свободно проанализировать. Кроме того, в таком случае можно точнее спрогнозировать потенциальный успех площадки, чем с помощью сервисов, перечисленных выше.
Первый способ
Для начала следует зайти в статистику по ссылке , после чего выбрать интересующую рубрику, список которых находится с левой стороны:

Теперь можно начинать -конкурентов, позаимствовав для себя поисковые запросы. Выбирать рекомендуется сайты, находящиеся за 10 страницей сервиса.
Обращаем внимание на цвет иконок. По цвету нужно выбирать светлые сайты, так как темные, это сайты с закрытой статистикой и они бесполезны для нас.

Теперь остается найти те сайты, чья статистика полностью открыта, нас больше всего интересует «по поисковым фразам»:

Второй способ
В этом случае нужно проанализировать ТОП поисковых систем. Для начала вводится интересующий ключ в поисковую строку, после чего анализируются сайты в ТОПе.
3.3. Анализ MegaIndex
MegaIndex — это машина автоматического продвижения, которая благодаря наличию огромного и бесплатного функционала позволяет находить интересные поисковые запросы.
В рамках данной статьи не буду об этом рассказывать, так как уже многое сказал в статье — , там есть подробное видео от самой компании Мегаиндекс.
4. Анализ и отсев ключевых запросов
Собранные запросы следует тщательно проанализировать, удалив “запросы-пустышки”, ВЧ и неэффективные словосочетания.
Или перед запуском необходимо составить семантическое ядро. Звучит страшно, но на самом деле это просто запросы, по которым пользователи будут искать ваши услуги или товары в поисковых системах. Если вы правильно подберете ключевые запросы, ваш сайт быстро поднимется в выдаче Яндекс и Google и приведет вам клиентов. Чтобы понять, в каком направлении двигаться, подумайте, как бы вы сами искали свои товары, по каким фразам. Можно выписать 3-5 основных тематик и от них отталкиваться. Но, чтобы не ломать голову и не придумывать велосипед, создали помощника – Яндекс Вордстат .
Wordstat (Вордстат) показывает статистику запросов пользователей. Сервис выдает все словосочетания с введенным ключом и количество пользователей, которые искали этот ключевой запрос. В этой статье я подробно расскажу о сервисе и о том, какие нюансы стоит учесть, работая с ним.
Yandex Wordstat спешит на помощь
Чтобы посмотреть статистику интересующего запроса, нужно вписать его в строку поиска, нажать «Подобрать» и сервис выдаст результат. Ниже схематично представлены основные блоки функционала сервиса.
- Поисковая фраза.
- Последнее обновление.
- Общее число показов в месяц.
- Число показов, по определенной фразе.
- Похожие запросы.
Вы можете искать фразы по:
- словам;
- регионам;
- истории запросов (по месяцам, неделям и т.д.).
Сервис показывает результат не только по введенному запросу, но и похожие фразы, которые искали пользователи.
Основные операторы
Чтобы понять принцип работы, введем запрос «Итальянская пицца»:

Сервис выдал нам результат, что данный запрос вводили 16 654 раза за месяц. Но так ли это на самом деле? Нет. Нужно иметь в виду, что пользователи могли искать запрос в различных вариациях, например «купить итальянскую пиццу» или «приготовить итальянскую пиццу». Некоторые запросы явно не стоит учитывать. И чтобы увидеть более правдивую картину, в сервисе есть базовые операторы.
1. Кавычки: “Слово”. Этот оператор, позволяет увидеть точное количество показов данного запроса, но по всем возможным окончаниям и порядку слов.

Теперь вместо цифры 16 654, мы видим 1152 показа в месяц. Это уже более правдоподобная цифра.
2. Восклицательный знак: !. Позволяет просмотреть количество показов по запросу с учетом окончания.

Мы поменяли окончание у запроса, и видим, что всего 225 раз пользователи искали эту фразу и именно с этим окончанием.
Вспомогательные операторы
В сервисе существуют дополнительные операторы, которые открывают больше возможностей при анализе и подборе запросов.
1. Оператор «ИЛИ».
Помогает объединять запросы, сравнивать несколько фраз.
Обозначается
(|).

На рисунке, справа, мы видим сколько запросов каждой фразы было сделано за месяц.
2. Оператор «Квадратные скобки». Фиксирует порядок слов, при этом учитываются все словоформы и стоп-слова. Обозначается .

3. Оператор «Плюс». Ищет сам запрос плюс дополнительное слово. Обозначается символом +.

4. Оператор «Минус». Выдает результат без слова, которое идет со знаком -. Обозначается символом -.

С помощью этого оператора, мы убрали все запросы, содержащие слово додо (додо, это марка пиццы).
5. Оператор «Группировка». Используется, когда требуется сгруппировать несколько операторов. Обозначается ().

Дополнительные возможности
В начале статьи я упоминала, что в Wordstat есть возможность искать и анализировать запросы по словам, по регионам и по истории. Начнем с истории запроса.
История запроса
Скоро Новый год и вы уже задумываетесь, когда же начинать оповещать своих подписчиков о новогодних акциях и распродажах. Чтобы отследить, когда люди начинают интересоваться данной темой, перейдем во вкладку «История запросов» и посмотрим сезонные колебания запроса «Новый год».

Если смотреть на график, то видно, что пик приходится на декабрь (12 месяц). Но начинают интересоваться уже в конце октября.
Количество запросов в заданном регионе
В этой вкладке можно посмотреть количество показов запроса в регионе или городе. Также можно оценить популярность в процентах. Чем выше процент, тем выше интерес.

В режиме«Карта» можно увидеть количество запросов и их популярность по странам на карте мира.

Сбор (парсинг) запросов заданной длины
Иногда возникает необходимость искать запросы заданной длины (из 2, 3, 4 слов и так далее) с вхождением ключевого слова.
К примеру, мы хотим найти фразу с ключевым словом «пицца» и длиной в 4 слова:

Запросы длиной от 2 до 7 слов позволяют существенно увеличить охват аудитории.
В статье были рассмотрены основные функциональные возможности сервиса WordStat. Теперь вам остается лишь правильно применить полученные знания на практике. Обязательно используйте данный инструмент в работе, если вам важно качественно , запускать эффективную и .
Очень важно убедиться, что запросы, по которым вы собрались продвигаться, вообще кто-то ищет. Если вы наберете «семантическое ядро», где все ключи будут с нулевой частотностью — то ваш сайт и будет нулём. Поэтому давайте не будем вола нагибать, а приступим.
Что такое частота ключевого слова
Очевидно, что различные запросы имеют разную популярность среди пользователей поисковых систем. Число ввода конкретного запроса в поисковик берется за один месяц. Таким образом, частота ключевых слов — это количество вводов запросов за месяц.
Вполне возможно, что даже тут есть запросы-пустышки
Для продвижения вашего сайта необходимо создавать оригинальный контент. Например, если вы пишете статьи, уникальность вашего текста должна быть, как правило, выше 90%. В теории, уникальный контент приносит высокий показатель посещаемости, состоящий в большей мере из переходов с Яндекса и Гугла. Однако в реальных условиях ранжирования написать уникальную статью — только половина успеха.
Поисковые системы обращают внимание не только на уникальность текста, но и на содержания в нем ключевых запросов, соответствующих тематике статьи или любого другого текстового контента. Правильное распределение ключевых слов в статье называют текстовой оптимизацией. Уникальная, но не оптимизированная статья, содержащие неопределенные запросы, может и вовсе не привлечь на сайт посетителей. Такая ситуация будет означать зря потраченные время и ресурсы на создание контента.
Для оптимизаторов, частотность это критерий по выбору того или иного запроса для его использования в тексте. В зависимости от частотности, на высокочастотные (ВЧ), среднечастотные (СЧ) и низкочастотные (НЧ) запросы. При оптимизации статьи, в первую очередь, обращают внимание на ВЧ и СЧ запросы. Однако с каждым годом продвижение новых сайтов становится все затруднительным, а оптимизация все тоньше. Сейчас считается, что использование НЧ ключей также может принести некоторый объем трафика.
Как проверить частотность запроса
Частотность ключевых слов можно узнать с помощью соответствующих сервисов поисковых систем, а также специальных программ по составлению семантического ядра. Поисковики предоставляют свои сервисы с расчетом подбора запросов для контекстной рекламы.
Wordstat (Яндекс)
Wordstat — cервис Яндекса по определению статистики ключевых запросов. Вордстат использует большинство оптимизаторов не только в целях составления коммерческих запросов под рекламу, но и для добычи ключевых слов в рамках обычной текстовой оптимизации. У Вордстата выделяют три вида частотностей:
- Частотность WS — базовая частотность запроса в Вордстате.
- Частотность «» WS — частотность по точному вводу запроса. Например, статистика по запросу [«автомобиль»] будет соответствовать запросу [автомобиль] без добавлений других слов.
- Частотность «!» WS — частотность по точному вводу каждого слова в запросе, исключая склонения и т.п. Запрос [!китайский] означает, что будет выдана статистика по слову [китайский] без возможных склонений (китайская, китайское).
По запросу [автомобиль] текущая частотность превышает десять миллионов показов. Однако базовый показатель предполагает добавление всевозможных слов к ключевому слову, по которым будет ранжироваться статья.

Если заключить запрос в кавычки, то статистика сократится с десяти миллионов до 28 тысяч. Для оптимизатора может оказаться полезной правая колонка с похожими запросами, которые дополняют семантический сбор.

Вкладка «По словам» означает, что статистика приводится по общей сумме показов введенного запроса. На вкладке «по регионам» отображается статистика показов в разных регионах страны. А на «Истории запросов» можно отследить по графике изменение частотности запроса в течении месяца или недели, а также статистику по по запросам через ПК или мобильные устройства.
Сервис Google AdWords сам по себе более заточен под контекстную рекламу, нежели Вордстат. В разделе «Инструменты» можно подобрать необходимые ключи под нужный запрос. В колонке «Таргетинг» задается нужный регион показов и язык. Также можно указывать минус-слова.

В отличии от Вордстата, где указывается статистика за месяц, в AdWords можно выбирать месячный диапазон показов в колонке «Диапазон дат». Недостатком является усредненный число результатов. Сама статистика разделена на два блока:
- Ключевые слова — аналог частотности «» Вордстата;
- Ключевые слова (по релевантности) — аналог базовой частотности и похожих запросов WS.

Плюсами являются присутствие уровня конкурентности, а также возможность скачать подобранные слова в CSV-файл или на Гугл Диск.
Помимо AdWords, Гугл имеет еще один инструмент по анализу запросов под названием Google Trends . Данный сервис оценивает популярность введенного запроса на определенный период времени и представляет статистику в виде графика. Можно сравнивать несколько ключевых запросов между собой. Также отображается статистика по регионам.

Для графика используются не точные числа, а относительные, основанные в том числе на релевантных запросах.
Mail.ru
Mail.ru также имеет в сервисе для вебмастеров инструмент по статистике поисковых запросов. Помимо общих показов, в таблице представлены распределение запросов по полу и возрасту пользователей.

Не секрет, что Mail сотрудничает с Яндексом, так как поисковик размещает рекламу Яндекса.
Rambler
Rambler с каждым годом теряет свою популярность, однако их Wordstat может оказаться весьма полезным. Дело в том, что статистика запросов в Яндексе и Гугле не всегда может отображать реальное положение вещей. Многие компании могут вводить «в холостую» коммерческие запросы в целях слежки за конкурентами, т.е. для анализа ТОПа, тайтлов и т.д.

По причине низкой популярности Рамблера, статистика их Вордстата обладает меньшей заспамленностью и может внести некоторую ясность для оптимизаторов. В общем, в качестве дополнительного инструмента вполне сгодится.
Как проверить массово частотность запросов
Большинство оптимизаторов выбирают для сбора и анализа семантического ядра такие программы, как Key Collector или Slovoeb. Также существуют онлайн-сервисы по определению частотностей.
Key Collector
Получить необходимые ключи для семантического ядра и массово проверить их частотность можно при помощи десктопной программы Key Collector . Открываем Вордстат, в поле заносим основные ключи с новой строки по вашей тематике и нажимаем «Начать сбор».

В настройках можно задавать требуемый регион для сбора, а также стоп-слова. После того как ключи соберутся, определяем частотности через Директ.

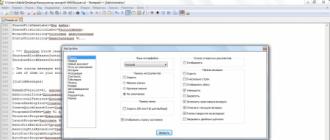
В итоге у вас будет таблица с ключами и частотой показов. Сразу удаляем все ключи, у которых точная частотность «!» равна нулю. Для этого делаем фильтрацию в колонке «Частотность!». Кликаем на синюю иконку. Появится окно с фильтром. Выбираем «больше или равно» > «1» и жмем «Применить».

Для получения большего списка ключей можно собрать поисковые подсказки с Яндекса. Делаем новую группу (окно справа).
Также убедитесь, что включена галка «Собирать только ТОП подсказок без перебора…». Теперь кликаем на созданную группу – откроется новая пустая вкладка. Жмем иконку сбора поисковых подсказок.
После сбора фраз делаем то же самое, что и при парсинге Вордстата: снимаем частотности, убираем неподходящие по смыслу фразы и фразы, где частотность «!» равна нулю.
Аналогично с помощью Key Collector можно собрать ключи и частотности с Гугла.
Rush Analytics
Сервис Rush Analytics является онлайн-альтернативой Key Collector. Плюсом инструмента по сбору ключей является отсутствие необходимости использовать прокси, антикапчу и т.п.
Для сбора частотности с Вордстата, необходимо перейти на вкладку «Сбор частотности» и поставить галочку напротив !ключевое слово , то есть точной частотности. Далее заносим ключевые слова. После того, как сервис посчитает затраты, нажимаем «Создать новый проект».
Результаты можно сохранить в Excel-файл.
Прежде чем начать работы над созданием нового интернет проекта, опытные вебмастера оценивают его перспективы – есть ли смысл вкладывать время и средства? Может случиться так, что масштабное начинание закончится провалом из-за того, что ниша абсолютно не востребована.
Знание самых популярных запросов в Яндексе или других поисковых системах, под которые вы продвигаетесь, поможет с самого начала выбрать нишу с большой целевой аудиторией.
- популярность темы в сети;
- платежеспособность аудитории.
В первую очередь смотрят на популярность, так как хороший трафик можно монетизировать в любом случае, например, добавлением сайта в рекламную сеть Яндекса (РСЯ) или в Google Adsense.
Популярность темы = много запросов в поиске = высокочастотные ключевые слова
Значит, надо узнать частотность интересующих нас слов и словосочетаний.
Как узнать частотность конкретных запросов
Если у вас уже есть определенные наметки по будущей тематике сайта, то достаточно набросать предварительный список наиболее популярных в этой теме запросов и «пробить» их частотность через сервис – wordstat.yandex.ru .
Например, пришла в голову идея сделать сайт по разведению оленей, можно посмотреть, сколько людей ищут «как разводить оленей».
Популярность запроса в поисковой системе Яндекс будет выражена конкретными цифрами, а дальше вы уже сами оценивайте, как это впишется в ваш бизнес план.


Видим, что тема про оленей не особо востребована, может быть, стоит для сайта подобрать какие-то более популярные запросы и вкладываться в них.
Максимум, что мы можем извлечь из этого сервиса – это посмотреть популярность сложных ключевых запросов (состоящих из 2 и более слов) с обязательным вхождением одного из них.
Например, ищем, что чаще всего хотят купить люди. Их запросы должны выглядеть так – «купить …» (вместо троеточия слово). В поле вордстата вводим «купить» и в списке предложенных вариантов мы увидим все самые популярные запросы купить в Яндексе. Подборка ключей для магазина авто шин может начинаться с общего запроса «купить шины»:


По списку уже видно чего и сколько ищут. Из общего запроса можно выделить множество групп более узкой специализации. Каждую из этих групп можно потом рассмотреть индивидуально по той же схеме и вычленить запросы из 4-5 слов. Для интернет магазина все закончится на самых узких запросах – карточках товаров.
Аналогично можно искать слова «смотреть», «скачать» и т.д. Если нужная вам тематика имеет подобные объединяющие слова, то вам повезло. Сложнее, когда все запросы в теме не похожи друг на друга. Как их выудить я расскажу дальше.
Где взять ВСЕ поисковые запросы
Вы уже поняли, что сервис wordstat не покажет нам всю статистику по интернету и не «спалит» наиболее востребованные запросы, он лишь подскажет частотность того, что мы спросили.
Некоторые вебмастера рекомендуют пользоваться для поиска сервисом Google trends, которые показывает популярные в сети темы на данный момент, но это малоэффективно, так как там сплошные новости шоу-бизнеса, кино и прочей чепухи – никакой реальной подсказки для перспективного сайта не будет.
Есть реальный способ получить полную выборку всех ключевых запросов, которые обрабатывали поисковые системы, но это удовольствие не бесплатно – называется Базы Пастухова (сайт pastukhov.com ).
Для удовлетворения любопытства по самым-самым популярным ключам у Пастухова выложено несколько десятков ключей из ТОПа прямо на сайте в таком виде,

но для работы это не прокатит (сплошные скачать, смотреть, игры, фильмы, песни), а за полную версию просят от 200 до 600 долларов в зависимости от разных акций.
Если вы делаете постоянно и много сайтов, то база может пригодиться, но есть вариант узнать популярные ключевые слова подешевле, точнее, бесплатно.
LiveInternet – самые популярные запросы БЕСПЛАТНО
Воспользуемся для этого сервисом статистики Liveinternet. К сожалению, использование данных этого сервиса не даст на 100% совпадения с данными поисковых систем Яндекс или Гугл, так как не все сайты интернета используют счетчики посещаемости от ЛайвИнтернет и не все кто используют делают свою статистику открытой, но выборка там очень большая, поэтому, для реальной работы более чем достаточна. В конце концов, нам же нужен список, а точные цифры потом по Wordstat пробьем.
Полезная штука в Liveinternet – есть возможность сразу делать сортировку по категориям – копать поисковые запросы не по всему интернету, а в конкретной теме (хотя, можно и по всему интернету тоже).
Открываем сайт – liveinternet.ru
Если нам нужны данные по поисковым запросам общим по сети, то переходим сразу в рейтинг сайтов, если нужные ключевые фразы по определенной тематике, то выбираем одну из рубрик.


Для примера я выбрал группу компьютеры. Теперь нам нужна статистика группы – это такая ссылка с пиктограммой графика сверху списка сайтов в рейтинге. Обратите внимание, что мы можем уточнить страну и регион – для сайтов, которые имеют привязку к территории, нужны запросы популярные в заданной местности.

В статистике мы увидим общие цифры посещаемости и много чего еще, но интересует нас левый столбец меню и, конкретно, пункт «По поисковым фразам».


Существенная доля запросов тут спрятана под кодовым названием «Другие», но пусть вас это не смущает, наиболее популярные открыты.
Чтобы выборку сделать максимально удобной в настройках итоговой таблицы выберите «По месяцам» и «Суммарные». Снизу можно настроить определенное число строк, одновременно выводимое на страницу (от 10 до 100).


Таким образом, мы получаем список наиболее популярных запросов в заданной категории. Не стоит удивляться, если среди запросов будут проскакивать не тематические – это происходит от того, что выборка идет не по реальным категориям запросов, а по сайтам, которые есть в рейтинге Liveinternet. И часто бывает так, что сайт ошибочно помещен не в ту категорию и его запросы учтены. Случается и так, что сайт тематический, но на нем есть страница с текстом другой тематики, которая дает ощутимый поисковый трафик, не относящийся к заданной категории.
Так что, самые популярные слова и словосочетания нужные вам надо будет отобрать руками.
Теперь мы можем расширить нашу выборку для подбора конкретных ключевых фраз под написание статей для своего сайта. Для этого берем список слов выписанных из Лайвинтернета и возвращаемся к любимому Яндекс Wordstat. Поочередно внося слова, мы получим более узкие значения популярных запросов, но, главное, в правой колонке мы найдем схожие по теме запросы, расширяющие нашу первоначальную выборку.


Вот такая методика бесплатного получения самых популярных запросов в поисковых системах без покупки всяких там баз Пастухова и прочих списков.
Полезные статьи:

 Как заработать деньги в интернете новичку – 23…
Как заработать деньги в интернете новичку – 23…

 Что такое блог, как его создать, раскрутить и как…
Что такое блог, как его создать, раскрутить и как…
 Wordstat.yandex.ru (Яндекс Вордстат) – как правильно…
Wordstat.yandex.ru (Яндекс Вордстат) – как правильно…