Ce qui suit est une liste alphabétique des opérateurs de recherche. Cette liste comprend les opérateurs qui ne sont pas officiellement pris en charge par Google et non répertoriés dans L'aide en ligne de Google.
Noter: Google peut modifier la manière dont les opérateurs sans papiers fonctionnent ou peuvent les éliminer complètement.
Chaque entrée inclut généralement la syntaxe, les capacités et un exemple. Certains des opérateurs de recherche ne fonctionneront pas comme prévu si vous mettez un espace entre le côlon (:) et le mot de requête ultérieur. Si vous ne vous souciez pas de vérifier quels opérateurs de recherche ne nécessitent aucun espace après le côlon, placez toujours le mot-clé immédiatement à côté du côlon. De nombreux opérateurs de recherche peuvent apparaître n'importe où dans votre requête. Dans nos exemples, nous placons l'opérateur de recherche aussi loin que possible à droite. Nous faisons cela parce que le formulaire de recherche avancé écrit des requêtes de cette manière. En outre, une telle convention rend plus claire quant aux opérateurs associés à quels termes.
Allinancher:
Si vous démarrez votre requête avec Allinancher:, Google restreint les résultats aux pages contenant toutes les conditions de la requête que vous spécifiez dans les liens sur la page. Par example, [ allinancher: Meilleurs musées Sydney ] Ne retournera que des pages dans lesquelles le texte d'ancrage sur les liens vers les pages contient les mots "meilleurs", "Musées" et "Sydney".
Grouper:
Si vous incluez le groupe: Dans votre requête, Google restreindre vos résultats Google Groupes aux articles de groupe de discussion de certains groupes ou sous-parents. Par exemple, [Sleep Group: misc.Kids.Modété] retournera des articles dans le groupe Misc.Kids.Modé que contiennent le mot "Sleep" et [Groupe de veille: Misc.Kids] retournera des articles dans la sous-zone Misc.Kids qui Contenir le mot "sommeil".
ID: Intitle:
La requête Intitle: terme Restreint les résultats aux documents contenant Terme dans le Par exemple, [ plan de la grippe Intitle: aide ] Retournera les documents qui mentionnent le mot "aide" dans leurs titres et mentionnent les mots "grippe" et "tir" n'importe où dans le document (titre ou non).
Noter: Il ne doit y avoir aucun espace entre l'intestin: et le mot suivant.
Mettre Intitle: Devant chaque mot de votre requête est équivalente à mettre Allinterle: à l'avant de votre requête, par exemple [ intitle: Google Intitle: Recherche ] Est le même que [ allinterle: Recherche Google ].
Si vous incluez Inurl: Dans votre requête, Google restreindre les résultats aux documents contenant ce mot dans la. Par exemple, la recherche de pages sur Google Guide dans laquelle l'URL contient le mot "Imprimer". Il trouve des fichiers PDF figurant dans le répertoire ou le dossier nommé "Imprimer" sur le site Web de Google Guide. La requête [ inurl: une alimentation saine ] Retournera des documents qui mentionnent les mots «sains» dans leur URL, et mentionnent le mot «manger» n'importe où dans le document.
Noter: Il ne doit y avoir aucun espace entre l'inurl: et le mot suivant.
Mettre Inurl: En face de chaque mot de votre requête est équivalente à mettre Allinurl: à l'avant de votre requête, par exemple [ inurl: sain inurl: manger ] Est le même que [ allinurl: une alimentation saine ].
En URL, les mots sont souvent gérés ensemble. Ils n'ont pas besoin de courir ensemble lorsque vous utilisez Inurl :.
Le lien de requête: URL Montre des pages qui pointent à cela. Par exemple, pour trouver des pages qui pointent sur la page d'accueil de Google Guide, entrez:
Trouvez des liens vers la page d'accueil directe des propriétaires britanniques non sur son propre site.
Lieu: Connecté:
Vous pouvez également restreindre vos résultats à un site ou à un domaine via le sélecteur de domaines sur la recherche avancée.
Dernière fois nous avons examiné, et cette fois, je vais vous dire comment effacer Pansement manuellement, passant par les fenêtres et programmes.
1. Pour commencer, considérez lorsque les ordures sont stockées dans des systèmes d'exploitation
Sous Windows XP
Nous allons tout supprimer dans les dossiers: Fichiers temporaires Windows:
- C: \\ Documents et paramètres \\ Nom d'utilisateur \\ Paramètres locaux \\ Historique
- C: \\ Windows \\ Temp
- C: \\ Documents et paramètres \\ Nom d'utilisateur \\ Paramètres locaux \\ Temp
- C: \\ Documents et paramètres \\ User par défaut \\ Paramètres locaux \\ Historique
Pour Windows 7 et 8
Fichiers temporaires Windows:
- C: \\ Windows \\ Temp
- C: \\ utilisateurs \\ nom d'utilisateur \\ appdata \\ local \\ temp
- C: \\ utilisateurs \\ tous les utilisateurs \\ temp
- C: \\ utilisateurs \\ tous les utilisateurs \\ temp
- C: \\ utilisateurs \\ par défaut \\ appdata \\ local \\ temp
Navigateurs de cache
Cache Opera:
- C: \\ utilisateurs \\ nom d'utilisateur \\ appdata \\ local \\ opéra \\ opéra \\ cache \\
Cache Mozille:
- C: \\ Utilisateurs \\ Nom d'utilisateur \\ Appdata \\ local \\ Mozilla \\ Firefox \\ profils \\ Dossier \\ cache
Cash Google Chrome (Chrome):
- C: \\ Utilisateurs \\ Nom d'utilisateur \\ Appdata \\ local \\ Bromium \\ Data utilisateur \\ Par défaut \\ cache
- C: \\ Utilisateurs \\ user \\ appdata \\ local \\ Google \\ chrome \\ Data utilisateur \\ Par défaut \\ cache
Ou conduire dans l'adresse Chrome: // version / Et nous voyons le chemin du profil. Il y aura un dossier Cache.
Fichiers Internet temporaires:
- C: \\ Utilisateurs \\ Nom d'utilisateur \\ AppData \\ local \\ Microsoft \\ Windows \\ Fichiers Internet temporaires \\
Documents récents:
- C: \\ utilisateurs \\ nom d'utilisateur \\ appdata \\ itinérance \\ microsoft \\ windows \\ récent \\
Certains dossiers peuvent être cachés des yeux indiscrets. Pour leur montrer que vous avez besoin.
2. Nettoyez le disque des fichiers temporaires et non utilisés en utilisant
Outil de nettoyage de disque standard
1. Allez à "Démarrer" -\u003e "Tous les programmes" -\u003e "Standard" -\u003e "Service" et exécutez le programme "Disque de nettoyage".
2. Sélectionnez un disque de nettoyage:

Le processus de numérisation de disque commencera ...
3. Une fenêtre s'ouvrira avec des informations sur le nombre d'espaces occupés par des fichiers temporaires:

Prenez DAWS devant les sections que vous souhaitez nettoyer et cliquez sur OK.
4. Mais c'est pas tout . Si vous avez installé Windows 7 non sur un disque propre, mais au-dessus du système d'exploitation précédemment installé, vous aurez probablement de tels endroits de dossiers tels que Windows.old ou Windows $. ~ Q.
En outre, il peut être logique de supprimer les points de contrôle de la récupération du système (à l'exception du dernier). Pour effectuer cette opération, répétez les étapes 1 à 3, mais cette fois, cliquez sur "Effacer les fichiers système":

5. Après la procédure décrite au paragraphe 2, vous trouverez la même fenêtre, mais l'onglet "Avancé" apparaîtra en haut. Allez-y.

Dans la section "Système de restauration et Copie Shadow", cliquez sur "Effacer".
3. Fichiers de page.sys et hiberfil.sys.
Les fichiers sont situés à la racine du disque système et occupent beaucoup d'espace.
1. fichier page.sys est fichier podchock système (mémoire virtuelle). Il est impossible de la supprimer (il n'est pas recommandé de le réduire également), mais cela peut être fait et même vous devez vous déplacer vers un autre disque.
Ceci est fait très simplement, ouvrez le «Panneau de commande - System et Security - System», sélectionnez «Paramètres de système avancé» dans la section «Speed», cliquez sur «Paramètres», passez à l'onglet «Avancé» (ou cliquez sur la victoire + R Desserrez et là, tapez SystemPropertsAdvanced) et dans la section "Mémoire virtuelle", cliquez sur Modifier. Là, vous pouvez sélectionner l'emplacement du fichier de pagination et sa taille (je recommande de laisser la taille de la taille de la taille).

4. Supprimer non le logiciel nécessaire du disque
Un bon moyen de faire un espace disque (et d'une performance supplémentaire d'augmentation de bonus), il est supprimé des programmes non utilisés.

Accédez au panneau de commande et sélectionnez "Supprimer des programmes". Une liste dans laquelle vous pouvez sélectionner le programme que vous souhaitez supprimer et cliquez sur "Supprimer".
5. défragmentation
La défragmentation du disque dur effectuée par le programme de défragmenator vous permet d'organiser le contenu des clusters, c'est-à-dire de les déplacer sur le disque afin que les grappes avec le même fichier deviennent séquentiellement et que des clusters vides ont été combinés. Cela conduit Augmenter la vitesse accès aux fichiers, ce qui signifie une augmentation de la vitesse informatique, qui à haut niveau fragmenté Le disque peut être assez perceptible. Le programme de diffusion de disque standard est sur la manière suivante: Démarrer\u003e Tous les programmes\u003e Standard\u003e Défragmentation de disque
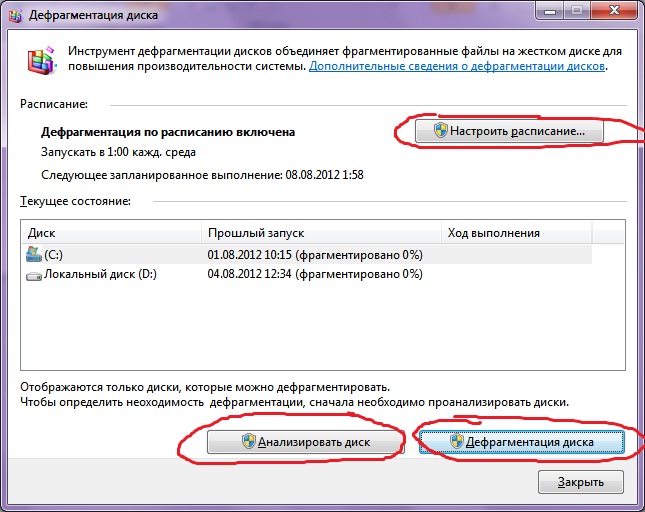
Voici comment on dirait le programme. Dans lequel vous pouvez analyser Le disque où le programme affichera le diagramme fragmenté sur disque et dira que vous devez avoir besoin ou ne pas avoir besoin d'effectuer une défragmentation. Vous pouvez également poser un programme lorsque la défragmentation de disque sera effectuée. Ce programme est intégré à Windows, il existe également des programmes distincts de défragmentation de disque, par exemple, que vous pouvez télécharger ici:

Son interface est également assez simple.

Voici ses avantages par rapport au programme standard:

- Analyse avant défragmentation de disque Analyse du disque de disque avant défragmentation. Une fois l'analyse affiche une boîte de dialogue avec un graphique de pourcentage de fichiers fragmentés et de dossiers dans le disque et la recommandation d'action. L'analyse est recommandée régulièrement et une défragmentation uniquement après la recommandation correspondante du programme de défragmentation de disque. L'analyse de disque est recommandée au moins une fois par semaine. Si le besoin de défragmentation se produit rarement, l'intervalle d'analyse de disque peut être augmenté à un mois.
- Analyse après avoir ajouté un grand nombre de fichiers Après avoir ajouté un grand nombre de fichiers ou de dossiers, les disques peuvent devenir excessivement fragmentés. Dans de tels cas, il est recommandé de les analyser.
- Vérifier la disponibilité d'au moins 15% d'espace disque gratuit Pour une défragmentation complète et correcte à l'aide du programme de défragmentation de disque, le disque doit avoir au moins 15% de l'espace libre. Le programme de défragmentation de disque utilise ce volume comme zone de tri des fragments de fichier. Si le volume est inférieur à 15% de l'espace libre, le programme de défragmentation de disque n'effectuera qu'une défragmentation partielle. Pour libérer une pièce supplémentaire sur le disque, supprimez-les des fichiers inutiles ou de les déplacer sur un autre disque.
- Défragmentation après l'installation de logiciel ou l'installation de Windows Défragmenter les disques après l'installation de logiciel ou après la mise à jour ou la mise à jour des fenêtres d'installation. Après avoir installé le logiciel, les disques sont souvent fragmentés. L'exécution du programme de défragmentation de disque aide à assurer les performances les plus élevées du système de fichiers.
- Gagnez du temps sur la défragmentation de disque Vous pouvez enregistrer un peu de temps requis pour la défragmentation si les fichiers ordures de l'ordinateur à partir de l'ordinateur et excluent également des fichiers système de pageFile.sys et hiberfil.sys, utilisés comme fichiers tampons temporaires et tampon et sont ré-sélectionnés à la début de chaque session Windows..
6. Supprimer inutile du démarrage
7. Nous supprimons tout inutile de
Eh bien, vous n'avez pas besoin sur le bureau que vous pensez par vous-même que vous savez. Et comment peuvent-ils l'utiliser. , procédure très importante, car cela ne l'oublie pas!
Le moteur de recherche Google (www.google.com) fournit de nombreuses options de recherche. Toutes ces caractéristiques constituent un outil de recherche inestimable pour l'utilisateur pour la première fois sur Internet et en même temps encore plus puissants d'armes d'invasion et de destruction entre les mains des personnes souffrant de mauvaises intentions, notamment des pirates, mais aussi des non-ordinateurs. et même des terroristes.
(9475 Vues pour 1 semaine)
Denis Bartankov
Denisnospamixi.ru.
Attention:Cet article n'est pas un guide d'action. Cet article est écrit pour vous, des administrateurs de serveurs Web afin que vous ayez de faux sentiment que vous êtes en sécurité et que vous avez enfin compris la ruse de cette méthode d'obtention d'informations et de prendre la protection de votre site.
introduction
Par exemple, dans 0,14 seconde a trouvé 1670 pages!
2. Nous introduisons une autre chaîne, par exemple:
inurl: "auth_user_file.txt"un peu moins, mais cela suffit déjà à télécharger gratuitement et à sélectionner des mots de passe (avec le même John the Ripper). Ci-dessous, je donnerai un certain nombre d'exemples.
Vous devez donc vous rendre compte que le moteur de recherche Google s'est rendu compte de la plupart des sites Internet et a conservé les informations dans le cache qui leur contient. Cette information mise en cache vous permet d'obtenir des informations sur le site et le contenu du site sans connexion directe sur le site, qui ne creuse que dans les informations stockées à l'intérieur de Google. De plus, si les informations sur le site ne sont plus disponibles, les informations contenues dans le cache peuvent toujours être préservées. Tout ce dont vous avez besoin pour cette méthode: connaître des mots-clés Google. Ce technicien s'appelle Google Hacking.
Pour la première fois, des informations sur Google Hacking sont apparues sur la newsletter Bugtruck pour une autre il y a 3 ans. En 2001, ce sujet a été soulevé par un étudiant français. Voici un lien vers cette lettre http://www.cotse.com/mailing-lists/bugtraq/2001/nov/0129.html. Il contient les premiers exemples de telles demandes:
1) Index of / Admin
2) Index du / mot de passe
3) Index of / Mail
4) Index de / + Banques + Filetype: XLS (pour la France ...)
5) Index of / + passwd
6) Index of / mot de passe.txt
Ce sujet s'est demandé dans la partie de lecture anglaise récemment: après Johnny Long article publié le 7 mai 2004. Pour une étude plus complète de Google Hacking, je vous conseille de saisir le site de cet auteur http://johnny.ihackstuff.com. Dans cet article, je veux juste vous entrer dans l'affaire.
Qui peut être utilisé:
- Les journalistes, les espions et toutes ces personnes qui aiment piquer le nez ne sont pas dans leurs affaires, peuvent l'utiliser pour rechercher un compromis.
- Hackers à la recherche d'objectifs appropriés pour le piratage.
Comment fonctionne Google.
Pour continuer la conversation, je rappelle à certains des mots-clés utilisés dans Google Queries.
Recherche par signe +
Google exclut de la recherche d'unimportants, à son avis, mots. Par exemple, question de mots, de prépositions et d'articles en anglais: par exemple, de, où. En russe, Google semble être important d'être important. Si le mot est exclu de la recherche, Google écrit à ce sujet. Pour que Google ait commencé à rechercher des pages avec ces mots avant qu'ils doivent ajouter un signe + sans espace avant le mot. Par example:
Ace + de base
Recherche par signe -
Si Google trouve un grand nombre de centres, à partir duquel il est nécessaire d'éliminer les pages avec un certain sujet, vous pouvez forcer Google à ne rechercher que des pages sur lesquelles il n'y a pas de mots spécifiques. Pour ce faire, vous devez spécifier ces mots, mettre avant chaque panneau - sans espace avant le mot. Par example:
Pêche - stock
Recherche par signe ~
Il est possible que vous souhaitiez trouver non seulement le mot spécifié, mais aussi ses synonymes. Pour ce faire, spécifiez le symbole ~.
Rechercher une phrase exacte avec des guillemets doubles
Google cherche à chaque page toute la saisie des mots que vous avez écrites dans la ligne de requête, ce qui n'a pas d'importance la position mutuelle des mots, la principale chose est que tous les mots spécifiés sont sur la page en même temps ( Ceci est l'action par défaut). Pour trouver la phrase exacte - il doit être pris entre guillemets. Par example:
"Bookend"
Pour avoir au moins un de ces mots, vous devez spécifier explicitement l'opération logique: ou. Par example:
Sécurité du livre ou protection
De plus, un signe peut être utilisé dans la barre de recherche * pour désigner n'importe quel mot et. Désigner n'importe quel symbole.
Recherche de mots avec des opérateurs supplémentaires
Il existe des opérateurs de recherche spécifiés dans la chaîne de recherche au format:
Opérateur: Search_term
Naps à côté du côlon n'est pas nécessaire. Si vous insérez une lacune après le côlon, vous verrez un message d'erreur et, devant celui-ci, Google les utilisera comme une ligne régulière à la recherche.
Il existe des groupes d'opérateurs de recherche supplémentaires: les langues - indiquez quelle langue vous souhaitez voir le résultat, les résultats de la date - limite des trois derniers mois, entrez-vous - indiquez où le document que vous souhaitez rechercher une ligne : Partout, dans l'en-tête, dans l'URL, les domaines - recherchez sur le site spécifié ou au contraire de l'exclure à partir de la recherche, Secure Search - Sites de blocs contenant le type d'informations spécifié et les supprimez des pages de résultats de recherche.
Dans le même temps, certains opérateurs n'ont pas besoin d'un paramètre supplémentaire, tel qu'une demande " cache: www.google.com."Peut être appelé une chaîne à part entière à la recherche, et certains mots-clés, au contraire, exigent la présence d'un mot à rechercher, par exemple" " site: www.google.com Aide"À la lumière de notre sujet, nous examinerons les opérateurs suivants:
Opérateur |
La description |
Nécessite un paramètre supplémentaire? |
rechercher uniquement sur le site spécifié dans Search_term |
||
recherchez uniquement dans les documents avec SEARCH_TERM Type |
||
trouver des pages contenant recherche_term dans le titre |
||
trouver des pages contenant tous les mots Search_term dans le titre |
||
trouvez des pages contenant le mot Search_term dans votre adresse |
||
trouvez des pages contenant tous les mots Search_term dans votre adresse |
Opérateur placer: Limite uniquement la recherche du site spécifié et vous pouvez spécifier non seulement le nom de domaine, mais également l'adresse IP. Par exemple, entrez:
Opérateur type de fichier: Limite la recherche dans les fichiers d'un certain type. Par example:
À la date de publication de l'article, Google peut rechercher dans 13 formats de fichier différents:
- Format de document Adobe portable (PDF)
- Adobe PostScript (PS)
- Lotus 1-2-3 (WK1, WK2, WK3, WK4, WK5, WKI, WKS, WKU)
- Lotus WordPro (LWP)
- MacWrite (MW)
- Microsoft Excel (XLS)
- Microsoft PowerPoint (PPT)
- Microsoft Word (doc)
- Microsoft travaille (WKS, WPS, WDB)
- Microsoft Ecrire (WRI)
- Format de texte riche (RTF)
- Shockwave Flash (SWF)
- Texte (ANS, TXT)
Opérateur relier: Affiche toutes les pages indiquant la page spécifiée.
Probablement toujours intéressant de voir combien d'endroits sur Internet savent sur vous. Nous essayons:
Opérateur cache: Affiche la version du site dans Google Kesche, car elle a regardé lorsque Google a visité cette page. Nous prenons un site et regardons souvent:
Opérateur intitle: Vous recherchez le mot spécifié dans la page de titre. Opérateur allinterle: C'est une extension - il cherche tous les mots spécifiés dans la page de titre. Comparer:
Intitle: vol de Mars
Intitle: Vol Intitle: à Intitle: Mars
Allinterle: Vol pour Mars
Opérateur Inurl:force Google Affiche toutes les pages contenant la chaîne spécifiée dans l'URL. Opérateur Allinurl: À la recherche de tous les mots de l'URL. Par example:
Allinurl: acid_stat_alerts.php
Cette équipe est particulièrement utile pour ceux qui n'ont pas de reniflement - du moins être en mesure de voir comment cela fonctionne sur le système réel.
Méthodes de piratage avec Google
Nous avons donc découvert qu'à utiliser une combinaison des opérateurs et des mots clés ci-dessus, tout le monde peut prendre une collection des informations nécessaires et rechercher des vulnérabilités. Ces techniques techniques sont souvent appelées google piratage.
Plan du site
Vous pouvez utiliser l'instruction Site: pour afficher tous les liens que Google trouvés sur le site. Généralement des pages créées de manière dynamique par des scripts à l'aide des paramètres ne sont pas indexées. Certains sites utilisent donc des filtres ISAPI afin que les liens ne soient pas sous la forme. /Articule.asp?num\u003d10&dst\u003d5, et avec des barres obliques / Article / ABC / NUM / 10 / DST / 5. Ceci est fait pour que le site soit généralement indexé par les moteurs de recherche.
Essayons:
Site: www.whitehouse.gov blanchehouse
Google pense que chaque page du site contient le mot Whitehouse. Nous utilisons pour obtenir toutes les pages.
Il y a une version simplifiée:
Site: WhiteHouse.gov.
Et quel est le plus agréable camarades avec WhiteHouse.Gov ne savait même pas que nous avons examiné la structure de leur site et avons même examiné les pages cachées que Google s'est téléchargée. Il peut être utilisé pour étudier la structure des sites et afficher le contenu, restant inaperçu à l'heure avant le temps.
Afficher la liste des fichiers dans les répertoires
Les serveurs Web peuvent afficher des listes de répertoires de serveur au lieu de pages HTML ordinaires. Ceci est généralement fait pour que les utilisateurs choisissent et téléchargent certains fichiers. Toutefois, dans de nombreux cas, les administrateurs n'ont aucun but de montrer le contenu du répertoire. Cela se pose en raison de la configuration incorrecte du serveur ou de l'absence de la page principale du répertoire. En conséquence, le pirate informatique semble avoir une chance de trouver quelque chose d'intéressant dans le répertoire et de tirer parti de cela à ses fins. Pour trouver toutes ces pages, il suffit de noter qu'ils contiennent tous dans leurs mots de titre: index de. Mais puisque les mots indiquent de contenir non seulement de telles pages, vous devez clarifier la demande et prendre en compte les mots-clés sur la page elle-même. Nous répondrons donc aux demandes du formulaire:
intitle: index.of
Intitle: index de nom de nom
Étant donné que les listes de répertoires sont délibérément, vous trouverez peut-être difficile de trouver des listes supprimées par erreur dès la première fois. Mais au moins vous pouvez déjà utiliser les annonces pour déterminer la version du serveur Web, comme décrit ci-dessous.
Obtenir une version du serveur Web.
La connaissance de la version du serveur Web est toujours utile avant toute attirement du pirate informatique. Encore une fois, grâce à Google, vous pouvez obtenir ces informations sans vous connecter au serveur. Si vous examinez soigneusement la liste du répertoire, vous pouvez voir que le nom du serveur s'affiche et sa version.
Apache1.3.29 - Server ProxAad à TRF296.FREE.fre.fr Port 80
Un administrateur expérimenté peut remplacer cette information, mais, en règle générale, cela correspond à la vérité. Donc, pour obtenir ces informations pour envoyer une demande:
Intitle: index.oferver.at
Pour obtenir des informations sur un serveur spécifique, nous spécifions la requête:
Intitle: Index.of Server.at Site: ibm.com
Ou, au contraire, nous recherchons un serveur travaillant sur une version de serveur spécifique:
Intitle: index.of apache / 2.0.40 serveur à
Cette technique peut être utilisée par un pirate informatique pour trouver la victime. S'il a, par exemple, il existe une exploitement pour une version spécifique du serveur Web, elle peut le trouver et essayer l'exploitation existante.
Vous pouvez également obtenir une version du serveur en affichant les pages installées par défaut lors de l'installation de la dernière version du serveur Web. Par exemple, pour voir la page de test Apache 1.2.6 suffit à composer
Intitle: test.page.por.pour.apache-la-chaussée!
De plus, certains systèmes d'exploitation lors de l'installation immédiate et exécutent un serveur Web. Dans le même temps, certains utilisateurs ne le soupçonnent même pas. Naturellement, si vous voyez que quelqu'un n'a pas supprimé la page par défaut, il est logique de supposer que l'ordinateur ne subit pas de configuration du tout et probablement vulnérable aux attaques.
Essayez de trouver les pages IIS 5.0
allIntiTle: Bienvenue sur les services Internet Windows 2000
Dans le cas de l'IIS, vous pouvez définir non seulement la version du serveur, mais également la version de Windows et Service Pack.
Une autre façon de déterminer la version du serveur Web est de rechercher des manuels (pages de conseil) et des exemples pouvant être installés sur le site Web par défaut. Les pirates informatiques ont trouvé de nombreuses façons d'utiliser ces composants pour obtenir un accès privilégié au site. C'est pourquoi vous devez supprimer ces composants sur le site de bataille. Sans parler du fait que, par la présence de ces composants, vous pouvez obtenir des informations sur le type de serveur et sa version. Par exemple, nous trouverons un guide pour Apache:
INURL: Modules manuels Apache Directives
Utilisez Google comme scanner CGI.
Scanner CGI ou Scanner Web - Utilitaire de recherche de scripts et de programmes vulnérables sur le serveur de sacrifice. Ces services publics devraient savoir quoi rechercher, car ils ont toute une liste de fichiers vulnérables, par exemple:
/cgi-bin/cgiemail/uargg.txt
/random_banner/index.cgi.
/random_banner/index.cgi.
/cgi-bin/mailview.cgi.
/cgi-bin/maillist.cgi.
/cgi-bin/userreg.cgi.
/Iissamples/issamples/sqlqhit.asp.
/SitesServer/Admin/findvServer.asp.
/sscrips/cphost.dll
/cgi-bin/finger.cgi.
Nous pouvons trouver chacun de ces fichiers à l'aide de Google à l'aide d'un nom de fichier supplémentaire dans la chaîne de recherche de l'index Word de ou inurl: nous pouvons trouver des sites avec des scripts vulnérables, par exemple:
Allinurl: /Random_banner/index.cgi.
Profitant de connaissances supplémentaires, le pirate informatique peut utiliser la vulnérabilité de script et avec cette vulnérabilité pour forcer le script à émettre n'importe quel fichier stocké sur le serveur. Par exemple, le fichier de mot de passe.
Comment vous protéger du piratage via Google.
1. Ne postez pas de données importantes sur le serveur Web.
Même si vous avez posté les données temporairement, vous pouvez l'oublier ou que quelqu'un aura le temps de trouver et de récupérer ces données pendant que vous ne les effacez pas. Ne le faites pas. Il existe de nombreuses autres façons de transférer des données qui les protègent du vol.
2. Vérifiez votre site.
Utilisez les méthodes décrites pour étudier votre site. Vérifiez votre site périodiquement avec de nouvelles méthodes qui apparaissent sur le site http://johnny.ihackstuff.com. N'oubliez pas que si vous souhaitez automatiser vos actions, vous devez obtenir une résolution spéciale de Google. Si vous lisez attentivement http://www.google.com/terms_of_service.html. Vous verrez la phrase: vous ne pouvez pas envoyer de requêtes automatiques de tout type au système de Google sans autorisation expresse à l'avance de Google.
3. Vous n'avez peut-être pas besoin de Google pour indexer votre site Web ou une partie de celui-ci.
Google vous permet de supprimer un lien vers votre site ou une partie de sa base, ainsi que de supprimer les pages de cache. De plus, vous pouvez interdire la recherche d'images sur votre site, elle est décrite à afficher des fragments de pages courts montrés dans les résultats de la recherche. http://www.google.com/remove.html. . Pour ce faire, vous devez confirmer que vous voulez vraiment propriétaire de ce site ou insérer les balises ou
4. Utilisez robots.txt
Il est connu que les moteurs de recherche examinent le fichier robots.txt qui se trouvent dans la racine du site et n'exposent pas ces pièces marquées d'un mot Refuser.. Vous pouvez en tirer parti pour qu'une partie du site n'est pas indexée. Par exemple, de sorte que l'ensemble du site n'est pas indexé, créez un fichier robots.txt contenant deux lignes:
Agent utilisateur: *
Interdit: /
Qu'est-ce qui arrive
Pour vous avec vous avec du miel, je ne semble pas dire que je dirai qu'il existe des sites qui suivent les personnes qui, à l'aide des méthodes ci-dessus, recherchent des trous dans les scripts et les serveurs Web. Un exemple d'une telle page est
Application.
Un peu doux. Essayez quelque chose de la liste suivante:
1. #MYSQL Dump FileType: SQL - Recherche de la base de données Dumps MySQL
2. Rapport de synthèse de la vulnérabilité de l'hôte - vous montrera quelles vulnérabilités ont trouvé d'autres personnes
3. phpmyadmin en cours d'exécution sur Inurl: Main.PHP - Il fera un contrôle via le panneau PHPMYADMIN
4. Pas pour la distribution confidentielle
5. Demander des détails Variables de serveur d'arborescence de contrôle
6. Courir en mode enfant
7. Ce rapport a été généré par Weblog
8. Intitle: index.of cgiirc.config
9. Filetype: Conf inurl: Pare-feu -IuTle: CVS - Qui peut avoir besoin d'un fichier de configuration de pare-feu? :)
10. Intitle: index.of finances.xls - MDA ....
11. Intitle: Index de DBConvert.exe Chats - Chat Journaux ICQ
12. Intext: Analyse du trafic Oetiker Tobias
13. Intitle: Statistiques d'utilisation pour générés par Webalizer
14. Intitle: Statistiques des statistiques Web avancées
15. Intitle: Index.of ws_ftp.ini - WS FTP config
16. INURL: ipsec.Secrets détient des secrets partagés - clé secrète - bonne trouvaille
17. INURL: Main.PHP Bienvenue à phpmyadmin
18. INURL: Informations sur le serveur Apache Server-Info Apache
19. Site: EDU Admin Classes
20. ORA-00921: extrémité inattendue de la commande SQL - Obtenez le chemin
21. Intitle: index.of trillian.ini
22. Intitle: Index de PWD.DB
23. Intitle: Index.of Personnes.lst
24. Intitle: Index.of Master.Passwd
25. Inurl: Passlist.txt
26. Intitle: index de .mysql_history
27. Intitle: Index of Intext: Globals.inc
28. Intitle: Index.of Administrators.PWD
29. Intitle: Index.of etc Shadow
30. Intitle: Index.of Secring.pgp
31. INURL: CONFIG.PHP DBUNAME DBPASS
32. Inurl: Effectuer des fichiers filetype: INI
Le centre éducatif "Informzashchita" http://www.itsecurity.ru est un centre spécialisé de premier plan dans le domaine de la formation en sécurité de l'information (licence du Comité de l'éducation de Moscou n ° 015470, accréditation de l'État n ° 004251). Le seul centre de formation agréé pour les systèmes de sécurité Internet et ClearSwift en Russie et dans les pays de la CEI. Centre de formation autorisé Microsoft (Sécurité de spécialisation). Les programmes de formation sont convenus avec le personnel de l'État de la Russie, de la FSB (FAPSI). Certificats de formation et de documents d'état sur la formation avancée.
La touche programmable est un service unique pour les acheteurs, les développeurs, les concessionnaires et les partenaires affiliés. En outre, c'est l'un des meilleurs magasins en ligne en Russie, l'Ukraine, le Kazakhstan, qui propose aux acheteurs une large gamme, de nombreux modes de paiement, de traitement de commande opérationnel (fréquent instantané), suivant le processus d'exécution de la commande dans une section personnelle, Divers réductions du magasin et des fabricants par.
La langue de requête est un langage de programmation créé artificiellement utilisé pour apporter des demandes dans des bases de données et des systèmes d'information.
En général, ces méthodes de requête peuvent être classées selon qu'ils servent à une base de données ou à rechercher des informations. La différence est que les demandes de services similaires sont faites pour recevoir des réponses réelles aux questions soulevées, tandis que le moteur de recherche tente de trouver des documents contenant des informations relatives au domaine d'intérêt.
Base de données
Les langues des demandes de base de données incluent les exemples suivants:
- QL - orienté objet, appartient au successeur de Datalog.
- Contextual (CQL) est une langue de vue de la langue formelle pour les moteurs d'information et de recherche (tels que les indices Web ou les répertoires bibliographiques).
- CQLF (Codyasyle) - Pour les bases de données de type CODASYL.
- Langue de requête orientée conceptuelle (COQL) - Utilisée dans les modèles appropriés (COM). Il repose sur les principes de la modélisation des données et utilise des opérations telles que la projection et la projection d'analyse multidimensionnelle, d'opérations analytiques et de conclusions.
- DMX - utilisé pour modéliser
- Datalog est une langue de requête à des bases de données déductives.
- Gellish Français est une langue pouvant être utilisée pour des requêtes dans des bases de données gellish anglaises et vous permet de mener des dialogues (requêtes et réponses) et sert également à la modélisation d'informations.
- HTSQL - traduit les demandes HTTP à SQL.
- Isbl - utilisé pour PRTV (l'un des premiers systèmes de gestion de la base de données relationnels).
- LDAP est un protocole de requêtes et de services d'annuaire travaillant sur le protocole TCP / IP.
- MDX est nécessaire pour les bases de données OLAP.

Moteurs de recherche
La langue de la recherche de recherche est à son tour visée à trouver des données dans les moteurs de recherche. Il est caractérisé par le fait que les demandes fréquemment contiennent du texte régulier ou un hypertexte avec une syntaxe supplémentaire (par exemple, "et" / "ou"). Il diffère de manière significative des langues similaires standard, qui sont régies par des règles strictes de syntaxe de règles ou contiennent des paramètres de position.
Comment les requêtes de recherche sont-elles classées?
Il existe trois grandes catégories qui couvrent la plupart des requêtes de recherche: informations, navigation et transaction. Bien que cette classification n'ait pas été fixée théoriquement, elle est confirmée empiriquement par la présence de moteurs de recherche réels.
Les demandes d'informations sont celles qui couvrent de nombreux sujets (par exemple, toute ville ou modèle de camions particuliers), pour lesquels des milliers de résultats pertinents peuvent être obtenus.
Navigation - Ce sont des demandes qui recherchent un site ou une page Web à un sujet spécifique (par exemple, YouTube).

Transactional - reflète l'intention de l'utilisateur d'effectuer une action spécifique, par exemple, de faire l'achat d'une voiture ou de réserver un billet.
Les moteurs de recherche supportent souvent le quatrième type de requête utilisée beaucoup moins fréquemment. Ce sont les demandes de connexion contenant un rapport sur la connexion d'un graphique Web indexé (nombre de références à une URL spécifique ou combien de pages sont indexées d'un domaine spécifique).
Comment est la recherche d'informations?
Fonctionnalités intéressantes liées à la recherche sur le Web:
La longueur moyenne de la requête de recherche était de 2,4 mots.
- Environ la moitié des utilisateurs ont guidé une demande et un peu moins d'un tiers des utilisateurs ont fait trois demandes uniques ou plus uniques.
- Près de la moitié des utilisateurs ont parcouru uniquement la première ou deux pages des résultats obtenus.
- Moins de 5% des utilisateurs utilisent des capacités de recherche avancées (par exemple, en choisissant des catégories spécifiques ou une recherche de recherche).
Caractéristiques de l'action personnalisée
L'étude a également montré que 19% des demandes contenaient un terme géographique (par exemple, noms, codes postaux, objets géographiques, etc.). Il convient également de noter qu'en plus des requêtes courtes (c'est-à-dire avec plusieurs conditions) et des régimes prévisibles pour lesquels les utilisateurs ont changé de phrases de recherche.

Il a également été constaté que 33% des demandes d'un utilisateur sont répétées et dans 87% des cas, l'utilisateur clique sur le même résultat. Cela suggère que de nombreux utilisateurs utilisent des demandes répétées pour réviser ou retrouver des informations.
Distributions de fréquence des demandes
En outre, des experts ont été confirmés que les distributions de fréquence des demandes correspondent à la loi sur la puissance. C'est-à-dire qu'une petite partie des mots-clés est observée dans la liste la plus importante de requêtes (par exemple, plus de 100 millions), et elles sont le plus souvent utilisées. Les autres phrases dans le cadre des mêmes sujets sont appliquées moins souvent et plus individuellement. Ce phénomène a reçu le nom du principe de Pareto (ou "Règle 80-20") et a permis aux moteurs de recherche d'utiliser de telles méthodes d'optimisation telles que l'indexation ou la séparation de la base de données, de la mise en cache et de la charge proactive, et a également permis d'améliorer la langue de la requête du moteur de recherche.
Ces dernières années, il a été révélé que la durée moyenne des demandes augmente régulièrement au fil du temps. Donc, la requête moyenne en anglais est devenue plus longue. À cet égard, Google a mis en place une mise à jour appelée «Hummingbird» (en août 2013), qui est capable de traiter de longues phrases de recherche avec une langue de demande «de conversationationnel» non programmable (comme "où le café le plus proche?").

Pour des demandes plus longues, leur traitement est utilisé - ils sont divisés en phrases formulées par la langue standard et les réponses sont émises séparément à différentes parties.
Demandes structurées
Moteurs de recherche que la prise en charge et la syntaxe utilisent des langues de demande plus avancées. Un utilisateur qui recherche des documents couvrant plusieurs ou faces peut décrire chacune d'elles par la caractéristique logique du mot. Essentiellement, la langue logique des demandes est une combinaison de certaines phrases et marques de ponctuation.
Qu'est-ce qu'une recherche élargie?
La langue de "Yandex" et "Google" est capable d'effectuer une recherche plus stricte de direction soumise à certaines conditions. La recherche avancée peut rechercher une partie du nom de page ou du préfixe d'en-tête, ainsi que dans certaines catégories et la liste des noms. Il peut également limiter la recherche de pages contenant certains mots dans le titre ou situé dans certains groupes thématiques. Avec l'utilisation correcte du langage de requête, elle peut gérer les paramètres de la commande plus complexes que les résultats de la surface de la plupart des moteurs de recherche, y compris sur l'utilisateur spécifié avec les mots avec des notes variables et une orthographe similaire. Lors de la présentation des résultats de la recherche étendue, la référence sera affichée sur les partitions de page correspondantes.

En outre, il s'agit également de la recherche de toutes les pages contenant une phrase spécifique, avec une requête standard, les moteurs de recherche ne peuvent pas arrêter sur une page de la discussion. Dans de nombreux cas, la langue de requête peut conduire à n'importe quelle page située dans NOINDEX TAGS.
Dans certains cas, la demande correctement formée vous permet de trouver des informations contenant un certain nombre de caractères spéciaux et de lettres d'autres alphabets (hiéroglyphes chinois par exemple).
Comment les symboles de langue de requête sont-ils lus?
Les registres supérieurs et inférieurs, ainsi que certains (graphiques et accents) ne sont pas pris en compte à la recherche. Par exemple, la recherche du mot-clé Citroen ne trouvera pas les pages contenant le mot "citroly". Mais certaines ligatures correspondent à des lettres individuelles. Par exemple, une recherche de "Aeroscrobing" trouvera facilement des pages contenant "Ereskebing" (AE \u003d æ).
Beaucoup de caractères numériques pas alphabétiquement sont constamment ignorés. Par exemple, il est impossible de trouver des informations sur demande contenant une chaîne | L | (La lettre entre deux rayures verticales), malgré le fait que ce symbole est utilisé dans certains modèles de conversion. Les résultats n'auront que des données de LT. Certains caractères et expressions sont traités de différentes manières: la demande "Crédit (Finance)" affichera des articles avec les mots "Crédit" et "Finance", Ignorer les crochets, même s'il existe un article avec le nom exact "Crédit (Finance) ".

Il existe de nombreuses fonctionnalités pouvant être utilisées à l'aide de la langue de requête.
Syntaxe
Les demandes "Yandex" et "Google" peuvent utiliser des marques de ponctuation pour clarifier la recherche. Par exemple, des crochets peuvent être apportés - (((recherche)). La phrase conclue en eux sera exposée à l'ensemble, inchangée.
La phrase vous permet de choisir l'objet de recherche. Par exemple, le mot entre guillemets sera reconnu comme utilisé dans un sens figuratif ou comme un caractère fictif, sans citations - comme des informations plus documentaires.
En outre, tous les principaux moteurs de recherche prennent en charge le symbole "-" pour logique "non", ainsi que / ou. Exception - termes qui ne peuvent pas être séparés à l'aide de préfixes ou de préfixes de Dash.
La conformité inexacte de la phrase de recherche est marquée de ~. Par exemple, si vous ne vous souvenez pas de la formulation exacte du terme ou du nom, vous pouvez le spécifier dans la barre de recherche avec le symbole spécifié et vous pouvez obtenir des résultats ayant la similitude maximale.
Paramètres de recherche spécialisée
Il existe également des paramètres de recherche tels que Intitule et Incategory. Ce sont des filtres affichés à travers un côlon, sous la forme de "filtre: chaîne de requête". La chaîne de requête peut contenir un terme ou une phrase souhaité, une pièce ou le nom complet de la page.
La fonctionnalité "Intitle: demande" donne la priorité dans les résultats de recherche par nom, mais affiche également les résultats habituels du contenu du titre. Plusieurs de ces filtres peuvent être utilisés simultanément. Comment utiliser cette opportunité?
Demande de "Intitle: nom de l'aéroport" émettra tous les articles contenant le nom du titre de l'aéroport. Si vous le formez comme «Intitle Parking: Nom de l'aéroport», vous recevrez des articles avec le nom de l'aéroport dans le titre et vous référez au parking dans le texte.
Recherche par filtre "Incategory: catégorie" fonctionne sur le principe des articles d'émission initiaux appartenant à un groupe ou à une liste de pages spécifiques. Par exemple, la requête de recherche par le type "Temples Incategory: Historique" émettra des résultats sur l'historique des temples. Cette fonctionnalité peut également être utilisée comme étendue en définissant divers paramètres.
L'obtention de données privées ne signifie pas toujours le piratage - parfois, ils sont publiés dans un accès général. La connaissance des paramètres de Google et une petite fusion feront beaucoup d'intérêt - des numéros de carte de crédit aux documents du FBI.
Avertissement
Toutes les informations sont fournies uniquement à des fins d'information. Ni les éditeurs ni l'auteur ne sont responsables de tout préjudice éventuel causé par le matériel de cet article.Aujourd'hui, il est connecté à Internet aujourd'hui, un peu soin de restreindre l'accès. Par conséquent, de nombreuses données privées deviennent des moteurs de recherche minière. Les robots- "araignées" ne sont plus limités aux pages Web et indexe tout le contenu disponible sur le réseau et sont constamment ajoutés à leurs bases de données non destinées à divulguer des informations. Vous savez juste ces secrets - il vous suffit de savoir comment vous poser des questions sur eux.
Nous recherchons des fichiers
Dans les mains habiles, Google trouvera rapidement tout ce qui se situe mal sur le réseau - par exemple, des informations personnelles et des fichiers de service. Ils se cachent souvent comme la clé sous le tapis: il n'y a pas de restrictions d'accès, les données sont simplement menées sur les backyards du site où les liens ne conduisent pas. L'interface Web Google standard fournit uniquement les paramètres de base de la recherche prolongée, mais même ils suffiront.
Limitez la recherche de fichiers d'un type spécifique dans Google en utilisant deux opérateurs: FileType et Ext. Le premier définit le format que le moteur de recherche a défini l'en-tête du fichier, la seconde est l'extension de fichier, quel que soit son contenu interne. Lors de la recherche dans les deux cas, vous n'avez besoin que de spécifier l'extension. Initialement, l'instruction EXT était pratique à utiliser dans des cas où les fonctions spécifiques du format de fichier étaient absentes (par exemple, pour rechercher des fichiers de configuration INI et CFG, à l'intérieur de ce que tout peut être). Maintenant, Google Algorithmes a changé et il n'y a aucune différence visible entre les opérateurs - les résultats dans la plupart des cas sont les mêmes.

Filtre émetteur
Par défaut, les mots et généralement des caractères Google entrés sont recherchés pour tous les fichiers sur les pages indexées. Vous pouvez limiter la zone de recherche sur le domaine de niveau supérieur, un site spécifique ou à l'emplacement de la séquence souhaitée dans les fichiers eux-mêmes. Pour les deux premières options, l'instruction Site est utilisée, après quoi le nom de domaine ou le site sélectionné est entré. Dans le troisième cas, tout un ensemble d'opérateurs vous permet de rechercher des informations dans des champs de bureau et des métadonnées. Par exemple, Allinurl supprimera les liens spécifiés dans le corps, Allinancher - dans le texte équipé de la balise , AllInterle - Dans les titres des pages, Allintext - dans le corps des pages.
Pour chaque opérateur, il existe une version légère avec un nom plus court (sans une console toutes. La différence est que Allinurl supprimera des liens avec tous les mots et Inurl ne se porte qu'avec le premier. La seconde et les mots suivants de la requête peuvent survenir sur des pages Web n'importe où. L'opérateur INURL a également des différences d'un autre sens similaire. Le premier vous permet également de trouver une séquence de caractères dans la référence au document souhaité (par exemple, / cgi-bac /), qui est largement utilisé pour rechercher des composants avec des vulnérabilités connues.
Essayons dans la pratique. Nous prenons le filtre Allintext et faites de sorte que la demande donne la liste des chiffres et des codes de vérification des cartes de crédit, dont la validité n'expirera que dans deux ans (ou lorsque leurs propriétaires se lassent d'alimenter toutes d'une rangée).
Allintext: Numéro de carte Date d'expiration / 2017 CVV 
Lorsque vous lisez dans les nouvelles que le jeune pirate informatique «a piraté les serveurs» de Pentagone ou de la NASA, fixant les informations secrètes, puis dans la plupart des cas, il s'agit d'une telle technique élémentaire pour utiliser Google. Supposons que nous soyons intéressés par la liste des employés de la NASA et leurs coordonnées. Une telle liste est sûrement sous forme électronique. Pour plus de commodité ou en écrasant, il peut se situer sur le site lui-même. Il est logique que dans ce cas, il ne sera pas des liens, car il est destiné à une utilisation interne. Quels mots peuvent être dans un tel fichier? Au moins - le champ "Adresse". Vérifiez que toutes ces hypothèses sont plus faciles que simples.

INURL: NASA.GOV FileTipe: XLSX "Adresse"

Nous utilisons la bureaucratie
Des trouvailles similaires sont une bonne petite chose. La véritable capture solide offre une connaissance plus détaillée des opérateurs de Google pour les webmasters, le réseau lui-même et les caractéristiques de la structure de la personne souhaitée. Connaissant les détails, vous pouvez facilement filtrer l'émission et clarifier les propriétés des fichiers souhaités afin que dans le reste pour obtenir des données vraiment précieuses. C'est drôle que la bureaucratie entre à la rescousse. Cela crée une formulation typique, pour laquelle il est pratique de rechercher des informations secrètes penchées par hasard.
Par exemple, une déclaration de distribution est obligatoire dans le bureau du département américain de la Défense signifie des restrictions normalisées sur la distribution des documents. Littéra une communiquée publique marquée, dans laquelle il n'y a rien de secret; B - Destiné à un usage interne, c est strictement confidentiel et ainsi de suite à F. Séparaimal, il vaut la peine de la lettre X, qui marque des informations particulièrement précieuses représentant le mystère d'État du plus haut niveau. Que ces documents recherchent ceux qui devraient être effectués sur la dette du service et nous nous limitons aux dossiers de C. conformément à la directive DODI 5230.24, ce marquage est attribué à des documents contenant une description des technologies critiques qui relèvent d'exportation contrôler. Vous pouvez détecter des informations si soigneusement protégées sur des sites dans le domaine de niveau supérieur.Mil attribué à l'armée américaine.
"Déclaration de distribution C" Inurl: Navy.mil 
Il est très pratique que seuls les sites Web de la US Mo et de ses organisations contractuels sont collectés dans le domaine de domaine.Mil. La recherche d'une restriction de domaine est extrêmement propre et les titres - se distinguent par eux-mêmes. La recherche de cette façon, les secrets russes sont presque inutiles: le chaos règne à domaines.ru et les noms de nombreux systèmes d'armes semblent botaniques (PP "Kiparis", ACS "Acacia") ou du tout fabuleux (TOS "Buratino").

Examinant soigneusement tout document du site dans le domaine.Mil, d'autres marqueurs peuvent être vus pour affiner la recherche. Par exemple, la référence aux restrictions d'exportation "SEC 2751", qui est également pratique pour rechercher des informations techniques intéressantes. De temps en temps, il est pris à partir de sites officiels, où elle était éclairée, alors si la recherche d'extradition ne parvient pas à procéder à un lien intéressant, utilisez le site Google Cash (Opereul de cache) ou sur le site d'archive Internet.
Nous grimpons dans les nuages
Outre les documents déclassifiés accidentellement des départements gouvernementaux, à Kesche Google, se sont parfois référencés de liens vers des fichiers personnels de Dropbox et d'autres services de stockage qui créent des références «privées» à des données publiées publiquement. Avec des services alternatifs et faits maison encore pire. Par exemple, la requête suivante trouve les données de tous les clients Verizon, dans lesquels le serveur FTP est installé sur le routeur.
Allinurl: FTP: // verizon.net
Ces personnes intelligentes ont maintenant trouvé plus de quarante mille et au printemps 2015, ils étaient plus d'ordre de grandeur. Au lieu de verizon.net, vous pouvez remplacer le nom de tout fournisseur célèbre et ce qu'il sera connu, plus il ya une prise. Grâce au serveur FTP intégré, les fichiers sont visibles sur le lecteur externe connecté au routeur. Habituellement, il s'agit de NAS pour un travail à distance, un nuage personnel ou une chaise à bascule de pyring. Tous les contenus de ce support sont indexés par Google et d'autres moteurs de recherche. Vous pouvez donc accéder aux fichiers stockés sur des disques externes par lien direct.

Nous espions les configs
Avant les nuages \u200b\u200baux nuages, de simples serveurs FTP dans lesquels il y avait aussi suffisamment de vulnérabilités a également raconté les nuages \u200b\u200bcomme stockages à distance. Beaucoup d'entre eux sont pertinents jusqu'à présent. Par exemple, les données de configuration de programme professionnelles populaires WS_FTP, les comptes d'utilisateurs et les mots de passe sont stockés dans le fichier WS_FTP.INI. Il est facile à trouver et à lire, car tous les enregistrements sont stockés dans un format de texte et les mots de passe sont cryptés par le triple des algorithme après l'obfuscation minimale. Dans la plupart des versions, il suffit de jeter le premier octet.

Decripher De tels mots de passe sont faciles à utiliser le service utilitaire de mot de passe WS_FTP ou un service Web gratuit.

En parlant de piratage d'un site arbitraire, impliquent généralement un mot de passe des journaux et des sauvegardes des fichiers de configuration CMS ou des applications de commerce électronique. Si vous connaissez leur structure typique, vous pouvez facilement spécifier des mots-clés. Les rangées comme celles rencontrées dans WS_FTP.INI sont extrêmement courantes. Par exemple, dans Drupal et PrestaShop, il existe un identifiant utilisateur (UID) et le mot de passe correspondant (PWD), et toutes les informations contenues dans des fichiers avec une extension sont stockées .inc. Recherchez-les comme suit:
"pwd \u003d" "uid \u003d" ext: inc
Révéler des mots de passe de la DBMS
Dans les fichiers de configuration des serveurs SQL, les noms et les adresses électroniques des utilisateurs sont stockés sur un formulaire ouvert, et au lieu de mots de passe sont enregistrés par leur hachage MD5. Pour les déchiffrer, à proprement parler, il est impossible, cependant, vous pouvez trouver la conformité parmi un mot de passe de hachage de Steam bien connu.

Il y a toujours des bases de données qui n'utilisent même pas de hachage de mot de passe. Les fichiers de configuration de l'un d'eux peuvent être simplement consultés dans le navigateur.
Intext: db_password FileType: env

Avec l'apparence sur les serveurs Windows, le lieu de fichiers de configuration occupait partiellement le registre. La recherche par ses branches peut être exactement de la même manière que l'utilisation de Reg comme type de fichier. Par exemple, comme ceci:
Filetype: Reg HKEY_CURRENT_USER "Mot de passe" \u003d
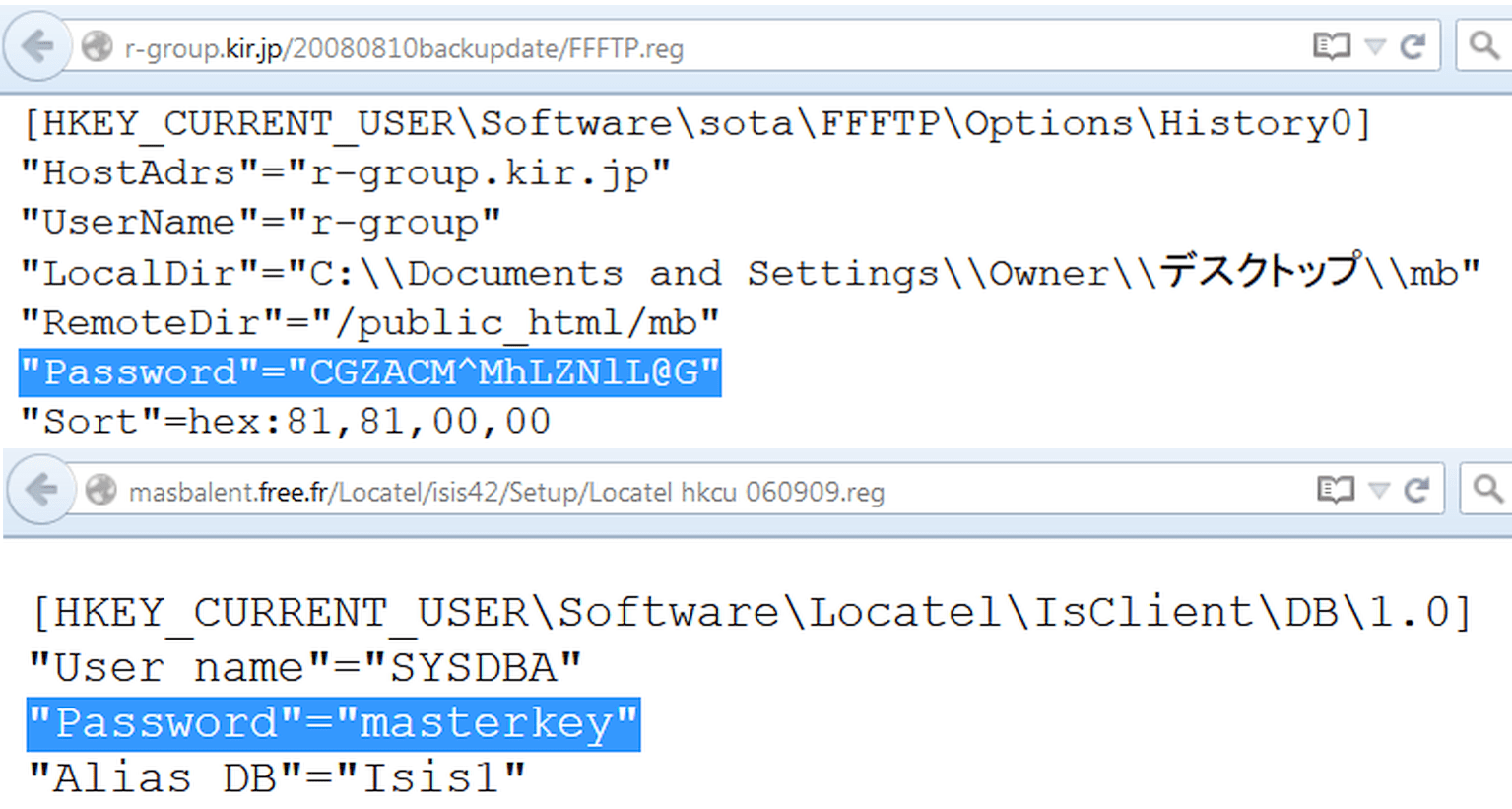
N'oubliez pas de l'évidence
Parfois, vous pouvez accéder aux informations fermées à l'aide d'une ouverture accidentelle et dans le champ de vision des données Google. L'option parfaite consiste à trouver une liste de mots de passe dans n'importe quel format commun. Stockez les informations de compte dans un fichier texte, le document Word ou l'E-Table Excel ne peuvent que désespérer des personnes, mais juste leur suffisamment.
FileType: XLS Inurl: Mot de passe

D'une part, il y a beaucoup de moyens pour prévenir de tels incidents. Vous devez spécifier des droits d'accès adéquats à HtactCess, PatT CMS, n'utilisez pas de scripts de gauche et de fermer d'autres trous. Il existe également un fichier avec une liste d'exceptions de robots.txt, interdisant les moteurs de recherche à indexer les fichiers et les répertoires spécifiés. D'autre part, si la structure de robots.txt sur certains serveurs diffère de la norme, il devient immédiatement clair qu'ils essaient de se cacher dessus.

La liste des répertoires et des fichiers sur n'importe quel site est précédé de l'indice d'inscription standard de. Comme il doit se réunir dans le titre à des fins de service, il est logique de limiter sa recherche par l'opérateur de l'intestation. Les choses intéressantes sont dans les répertoires / admin /, / personnel /, / etc / et même / secret /.

Suivez les mises à jour
La pertinence est très importante ici: les anciennes vulnérabilités se ferment très lentement, mais Google et son île de recherche changent constamment. Il y a une différence entre le "deuxième deuxième" filtre (& tbs \u003d qdr: s à la fin de la demande) et "temps réel" (& tbs \u003d qdr: 1).
L'intervalle de temps de la date de la dernière mise à jour du fichier dans Google est également indiqué implicitement. Grâce à l'interface Web graphique, vous pouvez choisir l'une des périodes standard (heure, jour, semaine, etc.) ou définir la plage de date, mais cette méthode ne convient pas à l'automatisation.
Selon l'apparence de la barre d'adresse, vous ne pouvez deviner que la méthode pour limiter la sortie des résultats à l'aide de & TBS \u003d QDR :. La lettre Y après avoir défini la limite d'un an (& TBS \u003d QDR: Y), m montre les résultats au cours du dernier mois, W - pour la semaine, D - Au cours de la dernière journée, H - pour la dernière heure, n - par minute, et s - pour me donner une seconde. Les résultats les plus frais qui viennent de devenir célèbres Google utilisent le filtre & TBS \u003d QDR: 1.
Si vous souhaitez écrire un script ruse, il sera utile de savoir que la plage de dates est définie dans Google au format Julian via la déclaration Daterange. Par exemple, vous trouverez ici une liste de documents PDF avec le mot confidentiel, téléchargé du 1er janvier au 1er juillet 2015.
Filetype confidentiel: pdf daterange: 2457024-2457205
La gamme est indiquée dans le format des dates de Julian sans prendre en compte la partie fractionnée. Traduisez-les manuellement du calendrier grégorien est gênant. Il est plus facile d'utiliser le convertisseur Dates.
Cibler et filtrer à nouveau
En plus de spécifier des opérateurs supplémentaires dans la requête de recherche, vous pouvez envoyer directement dans le corps de la liaison. Par exemple, clarifier le type de fichier: PDF correspond à la conception as_fileType \u003d pdf. Ainsi, il est commode de définir les clarifications. Supposons que l'émission de résultats uniquement de la République du Honduras est donnée en ajoutant Cr \u003d Countryhn à l'URL de recherche et uniquement à partir de la ville de Bobruisk - GCS \u003d Bobruisk. Dans la section Développeur, vous pouvez trouver une liste complète.
Les moyens d'automatisation de Google sont conçus pour faciliter la vie, mais ajoutent souvent des problèmes. Par exemple, par IP de l'utilisateur via WHOIS est déterminé par sa ville. Sur la base de ces informations sur Google, la charge entre serveurs est non seulement équilibrée, mais modifie également les résultats des résultats de la recherche. Selon la région, avec la même requête, différents résultats tomberont sur la première page et certains d'entre eux peuvent être du tout cachés. Sentant un cosmopolite et rechercher des informations de n'importe quel pays aidera son code de deux lettres après la directive GL \u003d pays. Par exemple, le code des Pays-Bas - NL et le Vatican et la Corée du Nord sur Google ne sont pas autorisés.
Souvent, la recherche d'émission s'avère être dérobée même après avoir utilisé plusieurs filtres avancés. Dans ce cas, il est facile de clarifier la demande en ajoutant quelques exceptions près (avant que chacune d'entre elles ne soit un signe moins). Par exemple, selon les noms personnels, bancaires, noms et tutoriels sont souvent utilisés. Par conséquent, plus de résultats de recherche pure ne montreront pas d'exemple clore d'une demande, mais un raffiné:
Intitle: "Index of / Personal /" -Names -Tutorial -Banking
Un exemple est enfin
Le pirate sophistiqué est caractérisé en s'assurant de tout ce qui est nécessaire. Par exemple, VPN est une chose commode, mais coûte ou temporaire et des limitations. Préparez un abonnement pour vous-même un trop cher. Il est bon qu'il existe des abonnements de groupe et avec l'aide de Google, il est facile de faire partie de certains groupes. Pour ce faire, il suffit de trouver le fichier de configuration Cisco VPN, qui possède une extension PCF assez non standard et un chemin reconnaissable: Fichiers de programme \\ Cisco Systems \\ VPN Client \\ Profils. Une demande et vous entrez, par exemple, dans une équipe amicale de l'Université de Bonn.
Filetype: PCF VPN ou groupe

Info
Google trouve des fichiers de configuration avec des mots de passe, mais nombre d'entre eux sont écrits sous une forme cryptée ou remplacés par le hachage. Si vous voyez les rangées de longueur fixe, le service de décryptage recherche immédiatement.Les mots de passe sont stockés sous une forme cryptée, mais Maurice Massar a déjà écrit un programme pour leur déchiffrement et la fournit gratuitement via Thecampusgeeks.com.
Avec Google, des centaines de types d'attaques et de tests de pénétration sont effectués. De nombreuses options affectent les programmes populaires, les principaux formats de base de données, de nombreuses vulnérabilités de PHP, des nuages, etc. Si vous vous assurez que vous recherchez, cela simplifiera grandement l'obtention des informations nécessaires (en particulier celle qui n'a pas prévu de faire la propriété universelle). Not Shodan alimente des idées intéressantes, mais chaque base de ressources réseau indexées!