SQL a ajouté des fonctions supplémentaires qui vous permettent de calculer les valeurs de groupe généralisées. Pour appliquer des fonctions agrégées, un groupe préliminaire est supposé. Quelle est l'essence de l'opération de regroupement? Lors du regroupement, toute la pluralité de tuples la relation est divisée en groupes dans lesquels des bandes ayant les mêmes valeurs d'attribut sont collectées dans la liste de regroupement.
Par exemple, regroupé le rapport R1 par la valeur de la colonne de la discipline. Nous obtenons 4 groupes pour lesquels nous pouvons calculer certaines valeurs de groupe, par exemple, le nombre de tuples dans le groupe, la valeur maximale ou minimale de la colonne d'évaluation.
Ceci est fait en utilisant des fonctions agrégées. Les fonctions globales calculent une valeur unique pour l'ensemble de la table de la table. La liste de ces fonctions est présentée dans le tableau 5.7.
Tableau 5.7.Fonctions globales
| R1 | |||||
| Nom et prénom | La discipline | Évaluation | |||
| Groupe 1. | Petrov F. I. | Base de données | |||
| Sidorov K. A. | Base de données | ||||
| Mironov A. V. | Base de données | ||||
| Stepanova K. E. | Base de données | ||||
| Krylova T. S. | Base de données | ||||
| Vladimirov V. A. | Base de données | ||||
| Groupe 2. | Sidorov K. A. | Théorie de l'information | |||
| Stepanova K. E. | Théorie de l'information | ||||
| Krylova T. S. | Théorie de l'information | ||||
| Mironov A. V. | Théorie de l'information | NUL | |||
| Groupe 3. | Trofimov P. A. | Réseaux et télécommunications | |||
| Ivanova E. A. | Réseaux et télécommunications | ||||
| UTKIN N. V. | Réseaux et télécommunications | ||||
| Groupe 4. | Vladimirov V. A. | Anglais | |||
| Trofimov P. A. | Anglais | ||||
| Ivanova E. A. | Anglais | ||||
| Petrov F. I. | Anglais | JE. | |||
Les fonctions globales sont utilisées similaires aux noms de champs dans l'instruction SELECT, mais à une exception près: ils prennent le nom du champ comme un argument. Seuls les champs numériques peuvent être utilisés avec des fonctions SUM et AVG. Avec les fonctions de comptage, max et min, des champs numériques et symboliques peuvent être utilisés. Lorsque vous utilisez avec des champs symboliques, Max et Min les diffuseront dans l'équivalent et le processus de code ASCII dans l'ordre alphabétique. Certains SGDM permettent d'utiliser des agrégats imbriqués, mais il s'agit d'une déviation de la norme ANSI avec toutes les conséquences résultant d'ici.
Par exemple, vous pouvez calculer le nombre d'élèves qui ont cédé des examens pour chaque discipline. Pour ce faire, faites une demande avec un groupe par le champ "Discipline" et dérive le nom de la discipline et le nombre de lignes du groupe sous cette discipline. L'application du symbole * comme argument de la fonction de comptage signifie compter toutes les lignes du groupe.
Sélectionnez R1. Discipline. Sunt (*)
Groupe de la discipline R1
Résultat:
Si nous voulons compter le nombre d'examens remis par une discipline, nous devons alors éliminer les valeurs incertaines de la relation initiale avant le regroupement. Dans ce cas, la demande ressemblera à ceci:
Sélectionnez R1. Discipline. COMPTER (*)
De R1 où R1.
N'est pas une évaluation nulle
Groupe par rl. Discipline
Nous obtenons le résultat:
Dans ce cas, une chaîne avec un étudiant
| Mironov A, V. | Théorie de l'information | NUL | ||
il ne tombera pas dans l'ensemble des tuples avant le regroupement, de sorte que le nombre de tuples dans le groupe de la discipline "La théorie de l'information" sera de 1 moins.
Vous pouvez appliquer des fonctions agrégées et sans une opération pré-groupe, dans ce cas, toute la relation est considérée comme un groupe et pour ce groupe, vous pouvez calculer une valeur au groupe.
En contactant la base de données «Session» à nouveau (Tableaux RL, R2, R2, R2), nous trouverons le nombre d'examens réussi:
Où l'évaluation\u003e 2:
Ceci, bien sûr, diffère de la sélection du champ, car la valeur unique est toujours renvoyée, quel que soit le nombre de lignes dans la table. L'argument des fonctions globales peut être des colonnes de tables séparées. Mais pour calculer, par exemple, le nombre de valeurs différentes d'une certaine colonne du groupe, vous devez appliquer le mot-clé distinct ainsi que le nom de la colonne. Nous calculons le nombre d'estimations différentes obtenues pour chaque discipline:
Sélectionnez RL. Discipline.
Count (distinct R1.Cécry)
Où r1. Zven n'est pas nul
Groupe par rl. Discipline
Résultat:
Vous pouvez activer la valeur du champ de regroupement et plusieurs fonctions globales et dans les conditions de regroupement que vous pouvez utiliser plusieurs champs. Dans le même temps, les groupes sont formés par l'ensemble des champs de regroupement spécifiés. Les opérations avec des fonctions globales peuvent être appliquées à l'unification de l'ensemble des tables source. Par exemple, nous fixerons la question suivante: déterminer pour chaque groupe et chaque discipline le nombre de réussite avec succès l'examen et le score moyen sur la discipline.
Sélectionnez R2.Group. R1. Discipline. Compte (*), AVR (évaluation)
Où rl. Fio \u003d r2.fio et
Rl zven n'est pas nul et
Rl zven\u003e 2.
Groupe par r2.group. Rldiscipline
Résultat:
Nous ne pouvons pas utiliser les fonctions d'agrégat dans la clause WHERE, car les prédicats sont estimés en fonction d'une seule ligne et des fonctions globales sont en termes de groupes de lignes.
L'offre de groupe BA vous permet de déterminer le sous-ensemble de valeurs dans un champ spécial en termes d'un autre champ et d'appliquer la fonction de l'unité à un sous-ensemble. Cela permet de combiner des champs et des fonctions agrégées dans une seule phrase de sélection. Les fonctions globales peuvent être utilisées à la fois pour exprimer la sortie de la chaîne de sélection et dans l'expression des conditions de traitement des groupes formés. Dans ce cas, chaque fonction d'agrégat est calculée pour chaque groupe sélectionné. Les valeurs obtenues lors du calcul des fonctions d'agrégat peuvent être utilisées pour produire les résultats pertinents ou pour la condition de sélection des groupes.
Nous allons construire une demande qui affiche des groupes dans lesquels plus d'une discipline obtenue lors des examens:
Sélectionnez R2.Group
Où rl. Fio \u003d r2.fio et
Rl. Action \u003d 2.
Groupe par r2.group. R1. Discipline
Ayant compté (*)\u003e 1
À l'avenir, comme exemple, nous ne travaillerons pas avec la "session" de la base de données, mais avec la BD "Bank", composée d'un tableau F, qui stocke le ratio F contenant des informations sur les comptes dans les branches de certaines banques:
F \u003d.
Q \u003d (branche, ville);
Étant donné que sur cette base de données peut être plus brillante pour illustrer le travail avec des fonctions agrégées et un regroupement.
Par exemple, supposons que nous souhaitions trouver un équilibre total des comptes dans les branches. Vous pouvez faire une requête séparée pour chacune d'elles en sélectionnant la somme (résidu) de la table pour chaque branche. Le groupe par cependant, leur permettra de les mettre dans une seule équipe:
Sélectionnez une branche, somme
Groupe par branche:
Le groupe en applique des fonctions globales de manière indépendante pour chaque groupe, déterminé par le champ du champ de la branche. Le groupe est constitué de lignes avec la même valeur de champ de champ, et la fonction Somme est appliquée séparément pour chacun de ce groupe, c'est-à-dire que la balance totale des comptes est calculée séparément pour chaque branche. La valeur du champ auquel groupe par est utilisé est, par définition, une seule valeur au groupe de sortie, ainsi que du résultat du fonctionnement de la fonction d'agrégat. Par conséquent, nous pouvons combiner l'unité et le champ dans une requête. Vous pouvez également utiliser le groupe avec plusieurs champs.
Supposons que nous ne voyions que les valeurs totales des soldes sur les comptes dépassant 5 000 $. Pour voir les résidus totaux de plus de 5 000 $, vous devez utiliser l'offre de l'offre. L'offre d'offre détermine les critères utilisés pour supprimer certains groupes de la sortie, tout comme l'offre où l'offre le fait pour des lignes individuelles.
La commande correcte sera la suivante:
Sélectionnez une branche, somme (résidus)
Groupe par branche
Avoir une somme (résidus)\u003e 5000;
Les arguments de la présence d'offre sont soumis aux mêmes règles que dans la clause Select, où groupe par est utilisé. Ils doivent avoir une valeur au groupe de sortie.
La commande suivante sera interdite:
Sélectionnez Branche.sum (résidus)
De f grup par branche
Avoir datainging \u003d 27/12/1999;
Le champ Cycle de données ne peut pas être utilisé pour avoir une offre, car il peut avoir plus d'une valeur au groupe de sortie. Pour éviter une telle situation, la présence d'offre devrait uniquement se référer aux agrégats et aux champs sélectionnés par groupe. Il y a une bonne façon de faire la demande ci-dessus:
Sélectionnez une branche, somme (résidus)
Où datotoberie \u003d "27/12/1999"
Groupe par branche;
La signification de cette demande est la suivante: trouver le montant des résidus de chaque branche des comptes, ouvert le 27 décembre 1999.
Comme mentionné précédemment, il ne peut utiliser que des arguments ayant une valeur au groupe de sortie. Pratiquement, les références aux fonctions agrégées sont les plus courantes, mais également les champs sélectionnés à l'aide de groupe par sont également autorisés. Par exemple, nous voulons voir le total des soldes sur les comptes de succursales à Saint-Pétersbourg, Pskov et Uryupinsk:
Sélectionnez Branche.sum (résidus)
Où ffilial \u003d q.filial
Groupe par branche
Avoir une branche dans (Saint-Pétersbourg. "Pskov". "Uryupinsk");
Par conséquent, dans les expressions arithmétiques des prédicats inclus dans la condition d'échantillon d'échantillon, seules les spécifications de colonne spécifiées sous forme de colonnes de regroupement peuvent être utilisées directement dans le groupe par section. Les colonnes restantes ne peuvent être spécifiées que dans la spécification des unités de comptage, de SUM, d'AVG, min et max, qui calculent une certaine valeur d'agrégation pour l'ensemble du groupe de lignes dans ce cas. La situation est similaire aux sous-sollicitations incluses dans les prédicats des conditions d'échantillonnage: si le groupe suivant est utilisé dans la sous-pièce, il ne peut être défini que par référence aux colonnes de regroupement.
Le résultat de la section suivante est une table groupée contenant uniquement les groupes de groupe pour lesquels le résultat du calcul de la condition de recherche est vrai. En particulier, si la section est présente dans une expression de table qui ne contient pas de groupe par groupe, le résultat de son exécution sera soit une table vide, soit le résultat des partitions précédentes de l'expression de table, considérée comme un groupe sans regroupement Colonnes.
Querties SQL investies
Revenons maintenant à la "session" de la base de données et envisagez d'utiliser des demandes investies sur son exemple.
En utilisant SQL, vous pouvez investir des demandes de l'autre. Habituellement, une demande interne génère une valeur vérifiée dans un prédicat de demande externe (dans le lieu ou la clause) la définissant ou non. Avec la sous-compréhension, vous pouvez utiliser des prédicats existants, ce qui rend la vérité si la sortie de sous-travail n'est pas vide.
En combinaison avec d'autres capacités de l'opérateur de sélection, telles que le groupement, la sous-requête est un outil puissant pour obtenir le résultat souhaité. En termes de l'instruction SELECT, il est permis d'appliquer des synonymes pour les noms de table si, lorsque vous formez une demande, nous avons besoin de plusieurs instances de certaines relations. Les synonymes sont définis à l'aide du mot clé comme clé, qui peut être généralement omis. Par conséquent, une partie de peut-elle ressembler à ceci:
De rl en tant que, rl comme dans
De RL A. RL dans:
les deux expressions sont équivalentes et sont considérées comme l'utilisation de l'instruction SELECT à deux instances de la table R1.
Par exemple, nous montrerons comment certaines demandes de la base de données "session" ressemblent à SQL:
- La liste de ceux qui ont passé tous les examens.
Où l'évaluation\u003e 2
Ayant compté (*) \u003d (sélectionnez le nombre (*)
Où r2.group \u003d r3.group et namé complet)
Ici, dans la demande intégrée, le nombre total d'examens est déterminé, qui devrait adopter chaque élève étudiant dans le groupe dans lequel cet étudiant apprend, et ce nombre est comparé au nombre d'examens adoptés par l'étudiant.
- La liste de ceux qui devaient prendre l'examen de la base de données, mais pas encore passés.
Selesfio
Où r2.fpynna \u003d r3.groupe et discipline \u003d "base de données" et n'existe pas
(Sélectionnez FIO de RL où nom complet \u003d A. fio et discipline \u003d "dB")
Les prédicats existent (sous-requête) est vrai lorsque la sous-requête de sous-requête n'est pas vide, c'est-à-dire qu'il contient au moins un tuple, sinon le prédicat existe est faux.
Le prédicat n'existe pas de retour - vrai uniquement lorsque la sous-requête est vide.
Faites attention à la façon dont il n'existe pas d'une demande investie vous permet de faire sans différence de relation. Par exemple, la formulation d'une requête avec le mot "tous" peut être faite comme avec une double négation. Considérons un exemple d'une base qui simule la fourniture de pièces individuelles par des fournisseurs individuels, il est représenté par un SP "fournisseurs" avec le schéma
SP (numéro de support. Numéro de détail) p (Number_tali. Nom)
C'est ainsi que la réponse à la requête est formulée: "Trouvez des fournisseurs qui fournissent tous les détails."
Sélectionnez Numéro distinct de SP SP1 où il n'existe pas
(Numéro SELECT_DETALI
De p où n'existe pas
(Sélectionnez * de SP2
Où sp2.number_number \u003d sp1.number_number_number et
sp2.number_detetali \u003d r. room_detali)):
En fait, nous reformulons cette demande comme suit: "Trouvez des fournisseurs de manière à ce qu'il n'y ait pas de détails qu'ils ne seraient pas fournis." Il convient de noter que cette demande peut être mise en œuvre par le biais de fonctions globales avec une sous-compréhension:
Sélectionnez Number_poster distinct
Groupe par numéro_name
Ayant un cavalin numérique_tali) \u003d
Sélectionnez Count (Détails)
Dans la norme SQL92, les opérateurs de comparaison sont étendus à plusieurs comparaisons en utilisant tous les mots-clés. Cette extension est utilisée lors de la comparaison de la valeur d'une colonne spécifique avec une colonne de données renvoyée par la demande ci-jointe.
Tout mot clé, livré dans n'importe quel prédicat de comparaison, signifie que le prédicat sera vrai si au moins une valeur de la sous-requête Le prédicat de comparaison est vrai. Le mot clé nécessite que le prédicat de comparaison soit vrai par rapport à toutes les lignes de sous-requête.
Par exemple, nous trouvons des étudiants qui ont passé tous les examens pour évaluer le non plus bas que «bon». Nous travaillons avec la même base de données "session", mais ajoutons un autre ratio R4, ce qui caractérise le passage des travaux de laboratoire pendant le semestre:
R 1 \u003d (nom complet, discipline, évaluation);
R 2 \u003d nom complet, groupe);
R 3 \u003d (groupes, discipline)
R 4 \u003d (nom complet, discipline, numéros_lab_rab, score);
Sélectionnez R1.FIO à partir de R1 où 4\u003e \u003d Tout (sélectionnez rl
Où r1.fio \u003d r11.fio)
Considérez un autre exemple:
Choisissez des étudiants qui ont un examen à l'examen ne sont pas moins que d'au moins une estimation sur les travaux de laboratoire sur cette discipline:
Sélectionnez R1.FIO
De R1 où R1. Zven\u003e \u003d Tout (sélectionnez R4. Zven
Où rl. Discipline \u003d r4. Discipline et r1.fio \u003d r4.fio)
SQL externes SQL
La norme SQL2 a élargi le concept d'association conditionnelle. Dans la norme SQL1, seules les conditions spécifiées dans l'instruction SELECT de l'opérateur SELECT ont été utilisées et, dans ce cas, seuls les coordonnés des relations initiales ont été trouvés aux conditions qui en résultent, pour lesquelles ces conditions ont été identifiées et vérité. Cependant, en réalité, il est souvent nécessaire de combiner des tables de manière à ce que toutes les lignes de la première table tombent dans le résultat, et au lieu de ces lignes de la deuxième table, pour lesquelles la condition composée n'est pas remplie, des valeurs incertaines Tomberait dans le résultat. Ou vice versa, toutes les lignes de la table droite (seconde) sont activées et les parties manquantes des rangées de la première table sont complétées par des valeurs incertaines. Ces associations ont été nommées externes par opposition aux associations définies par la norme SQL1, qui a commencé à être appelée interne.
Dans le cas général, la syntaxe de la partie de la partie de la norme SQL2 ressemble à ceci:
De.<список исходных таблиц> |
< выражение естественного объединения > |
< выражение объединения >
< выражение перекрестного объединения > |
< выражение запроса на объединение >
<список исходных таблиц>::= <имя_таблицы_1>
[Nom Synonymes Table_1] [...]
[,<имя_таблицы_п>[ <имя синонима таблицы_n> ] ]
<выражение естественного объединениям:: =
<имя_таблицы_1> Naturel (intérieur | plein | gauche | droite)<имя_таблицы_2>
<выражение перекрестного объединениям: = <имя_таблицы_1> Croix rejoindre.<имя_таблицы_2>
<выражение запроса на объединением:=
<имя_таблицы_1> Union rejoint.<имя_таблицы_2>
<выражение объединениям:= <имя_таблицы_1> (Intérieur |
Complet | À gauche | À droite) rejoindre (à condition)<имя_таблицы_2>
Dans ces définitions interne, intérieure moyenne d'une association interne, à gauche est l'union gauche, c'est-à-dire que le résultat comprend toutes les lignes de tableau 1 et des parties des tuples résultants, pour lesquelles il n'y avait pas de valeurs correspondantes dans le tableau 2, sont complété par les valeurs nulles (incertain). Le mot clé de droite désigne la bonne association externe, et contrairement à l'association de gauche dans ce cas, la relation qui en résulte comprend toutes les lignes de tableau 2 et les pièces manquantes du tableau 1 sont complétées par des valeurs incertaines, le mot clé complet détermine l'association totale externe: la gauche et la droite. Avec une association externe complète, les associations externes à droite et à gauche sont effectuées et la relation qui en résulte inclut toutes les lignes du tableau 1, complétées par des valeurs incertaines et toutes les lignes du tableau 2, également complétées par des valeurs indéfinies.
Le mot clé externe signifie externe, mais si les mots-clés pleins, à gauche, à droite sont spécifiés, l'association est toujours considérée comme externe.
Considérons des exemples d'exécution d'associations externes. Référoir la "session" de la base de données. Créez une attitude dans laquelle toutes les estimations reçues par tous les étudiants de tous les examens qu'ils ont dû passer. Si l'étudiant n'a pas abandonné cet examen, alors au lieu de l'évaluation, elle restera indéfiniment. Pour ce faire, effectuez une association interne naturelle de manière séquentielle des tables R2 et R3 par l'attribut de groupe et la relation qui en résulte avec l'association naturelle externe gauche avec la table R1 à l'aide des colonnes et de la discipline de noms. Dans ce cas, la norme est autorisée à utiliser une structure d'empileur, car le résultat de la combinaison peut être l'un des arguments en termes d'opérateur Select.
Sélectionnez RL. FIO, R1. Discipline. Interdiction de RL
De (R2 Natural Inner Joindre R3), rejoignez RL en utilisant (nom complet. Discipline)
Résultat:
| Nom et prénom | La discipline | Évaluation | ||
| Petrov F. I. | Base de données | |||
| Sidorov K. A. | Base de données | 4 | ||
| Mironov L. V. | Base de données | |||
| Stepanova K. E. | Base de données | |||
| Krylova T. S. | Base de données | |||
| Vladimirov V. A. | Base de données | |||
| Petrov F. I. | Théorie de l'information | NUL | ||
| Sidorov K. A. | Théorie de l'information | |||
| Mironov A. V. | Théorie de l'information | NUL | ||
| Stepanova K. E. | Théorie de l'information | |||
| Krylova T. S. | Théorie de l'information | |||
| Vladimirov V. A. | Théorie de l'information | NUL | ||
| Petrov F. I. | Anglais | |||
| Sidorov K. A. | Anglais | NUL | ||
| Mironov A. V. | Anglais | NUL | ||
| Stepanova K. E. | Anglais | NUL | ||
| Krylova T. S. | Anglais | NUL | ||
| Vladimirov V. A. | Anglais | |||
| Trofimov P. A. | Réseaux et télécommunications | |||
| Ivanova E. A. | Réseaux et télécommunications | |||
Considérez un autre exemple, pour cela, prenez la base de données «Bibliothèque». Il se compose de trois relations, les noms des attributs ici sont diagnostiqués avec des lettres latines, nécessaires dans la plupart des SGBD commerciaux.
Livres (ISBN, TITL. AUTOR. COATOR. ANNEJZD, PAGES)
Lecteur (Num_Reader. Nom_reader, Adresse. Hoom_phone. Work_Phone. Naissance_day)
EXEMPLARE (INV, ISBN, YES_NO. NUM_READER. DATE_IN. DATE_DUT)
Ici, la table des livres décrit tous les livres présents dans la bibliothèque, il dispose des attributs suivants:
- Isbn est un livre unique en chiffre;
- TITL - Nom du livre;
- Autor - Nom de famille de l'auteur;
- Coautor - Co-auteur de famille;
- Yeary - Année de publication;
- Pages - Nombre de pages.
Le lecteur de table stocke des informations sur tous les lecteurs de bibliothèque et contient les attributs suivants:
- Num_Reader est un numéro de billet d'un lecteur unique;
- Name_reader - nom de famille et initiales du lecteur;
- Adresse - Adresse du lecteur;
- Hoom_phone - numéro de la maison;
- Work_phone - numéro de téléphone de fonctionnement;
- Naissance - Date du lecteur.
La table Exemplare contient des informations sur l'état actuel de toutes les instances de tous les livres. Il comprend les colonnes suivantes:
- Inv - un numéro d'inventaire unique de la copie du livre;
- ISBN - un livre de livre qui détermine qui le livre est et fait référence aux informations de la première table;
- Yes_no - un signe de présence ou d'absence d'une instance donnée dans la bibliothèque;
- NUM_READER - Numéro de lecteur, si le livre est délivré au lecteur et que NULL autrement;
- DATE_IN - Si le livre du lecteur est, c'est la date à laquelle il est délivré au lecteur; Une date_out - date lorsque le lecteur doit renvoyer le livre à la bibliothèque.
Déterminer la liste des livres de chaque lecteur; Si le lecteur n'a pas de livres, le numéro de la copie du livre est NULL. Pour effectuer cette recherche, nous devons utiliser l'association externe gauche, c'est-à-dire que nous prenons toutes les lignes de la table de lecteur et connectez-vous avec des chaînes de la table Exemplare s'il n'y a pas de chaînes avec le numéro de ticket du lecteur correspondant dans la deuxième table ont un Valeur indéfinie de NULL:
Sélectionnez Reader.Name_Reader, Exemplare.inv
De Reader Droite Rejoignez Exemplare sur Reader.Num_Reader \u003d Exemplare.num_reader
Le fonctionnement de l'association externe, comme nous l'avons déjà mentionné, peut être utilisé pour former des sources de la clause de la clause, ce qui sera donc permis, par exemple, le texte de requête suivant:
De (livres à gauche rejoindre Exemplare)
Joindre gauche (Reader Natural Rejoignez Exemplare)
Dans le même temps, pour des livres, aucune copie ne se trouve pas sur les mains des lecteurs, les valeurs du billet du lecteur et la date de la prise et du retour du livre seront incertaines.
La combinaison croisée dans l'interprétation de la norme SQL2 correspond au fonctionnement d'un travail décartitien prolongé, c'est-à-dire les opérations de connexion de deux tables, dans lesquelles chaque ligne de la première table est connectée à chaque rangée de la deuxième table.
Opération demande d'association PAÉquivalent à l'opération d'association théorique et multiple dans l'algèbre. Dans le même temps, l'exigence d'équivalence des taux de relations initiales est préservée. La demande de l'Union est effectuée conformément au schéma suivant:
Sélectionnez - Requête
Union Select - Demande
Union Select - Demande
Toutes les demandes participant à l'opération de l'Union ne doivent pas contenir des expressions, c'est-à-dire les champs calculés.
Par exemple, vous devez retirer une liste de lecteurs qui gardent le livre "idiot" ou le livre "crime et punition". Enveloppe d'enveloppe:
Sélectionnez Reader. Name_reader.
De lecteur, exemplare.books
Books.title \u003d "(! Lang: idiot"!}
Sélectionnez Reader.Name_reader.
De lecteur, exemplre, livres
Où exemplare.num_reader \u003d lave.num_reader et
Exemplre.isbn \u003d books.isbn et
Livres.title \u003d "(! Lang: Crime"!}
Par défaut, lorsque vous remplissez la demande de combinaison de duplicats, les tuples sont toujours exclus. Par conséquent, s'il y a des lecteurs qui ont les deux livres entre leurs mains, ils ne tomberont toujours dans la liste des résultats obtenus une fois.
La demande de l'Union peut combiner un nombre quelconque de demandes source.
Donc, à la demande précédente, vous pouvez ajouter davantage de lecteurs qui gardent le livre "Castle" sur les mains:
Sélectionnez Reader. Name_reader.
De lecteur. Exemplare, livres.
Où exemplare.num_reader \u003d lave.num_reader et.
Exemplre.isbn \u003d books.isbn et
Books.title \u003d "(! Lang: Castle"!}
Si vous devez enregistrer toutes les lignes de la relation source, vous devez utiliser tous les mots-clés de l'opération de combinaison. En cas d'économie de doublons des tuples, le schéma d'exécution d'une demande de combinaison ressemblera à ceci:
Sélectionnez - Requête
Sélectionnez - Requête
Sélectionnez - Requête
Cependant, le même résultat peut être obtenu en modifiant simplement la phrase de la première partie de la demande source, reliant les conditions locales avec une opération logique ou à l'exclusion des doublons des tuples.
Sélectionnez Lecteur distinct.Name_reader.
De lecteur. Exemplare.Books.
Où exemplare.num_reader \u003d lave.num_reader et
Exemplre.isbn \u003d books.isbn et
Books.title \u003d "(! Lang: idiot" OR!}
Books.title \u003d "(! Lang: crime et punition" OR!}
Books.title \u003d "(! Lang: Castle"!}
Aucune des demandes initiales de l'opération syndicale ne devrait contenir les propositions de commande par ordre de commande par cependant, le résultat de la combinaison peut être commandé, pour cela, la commande par la proposition des colonnes de commande est écrite après le texte de la dernière source. Sélectionnez Demande.
La valeur de l'estimation de la colonne.| Une fonction | Résultat |
|---|---|
| Compter | Nombre de lignes ou de valeurs de champ non vides qui ont choisi la demande |
| SOMME. | La somme de toutes les valeurs sélectionnées de ce champ |
| Avg. | La valeur moyenne parentale de toutes les valeurs sélectionnées de ce champ. |
| Min. | La plus petite de toutes les valeurs sélectionnées de ce champ. |
| Max | La plus grande de toutes les valeurs sélectionnées de ce champ. |
| R1 | |||
|---|---|---|---|
| Nom et prénom | La discipline | Évaluation | |
| Groupe 1. | Petrov F. I. | Base de données | 5 |
| Sidorov K. A. | Base de données | 4 | |
| Mironov A. V. | Base de données | 2 | |
| Stepanova K. E. | Base de données | 2 | |
| Krylova T. S. | Base de données | 5 | |
| Vladimirov V. A. | Base de données | 5 | |
| Groupe 2. | Sidorov K. A. | Théorie de l'information | 4 |
| Stepanova K. E. | Théorie de l'information | 2 | |
| Krylova T. S. | Théorie de l'information | 5 | |
| Mironov A. V. | Théorie de l'information | NUL | |
| Groupe 3. | Trofimov P. A. | Réseaux et télécommunications | 4 |
| Ivanova E. A. | Réseaux et télécommunications | 5 | |
| UTKIN N. V. | Réseaux et télécommunications | 5 | |
| Groupe 4. | Vladimirov V. A. | Anglais | 4 |
| Trofimov P. A. | Anglais | 5 | |
| Ivanova E. A. | Anglais | 3 | |
| Petrov F. I. | Anglais | 5 | |
Fonctions globales Utilisé de la même manière par des noms de champs dans l'instruction SELECT, mais à une exception près: ils prennent le nom du champ comme argument. Seuls les champs numériques peuvent être utilisés avec des fonctions SUM et AVG. Avec les fonctions de comptage, max et min, des champs numériques et symboliques peuvent être utilisés. Lorsqu'ils sont utilisés avec des champs de caractères max et min, les diffuseront dans l'équivalent et le processus de code ASCII dans l'ordre alphabétique. Certains SGDM permettent d'utiliser des agrégats imbriqués, mais il s'agit d'une déviation de la norme ANSI avec toutes les conséquences résultant d'ici.
Par exemple, vous pouvez calculer le nombre d'élèves qui ont cédé des examens pour chaque discipline. Pour ce faire, vous devez faire une demande avec un groupe de «discipline» sur le terrain et à tirer le nom de la discipline et le nombre de lignes du groupe sous cette discipline. L'application du symbole * comme argument de la fonction de comptage signifie compter toutes les lignes du groupe.
Sélectionnez R1.DisciPline, Count (*) du groupe R1 par R1.Discipline
Résultat:
Si nous voulons compter le nombre d'examens remis par une discipline, nous devons alors éliminer les valeurs incertaines de la relation initiale avant le regroupement. Dans ce cas, la demande ressemblera à ceci:
Nous obtenons le résultat:
Dans ce cas, une chaîne avec un étudiant
| Mironov A. V. | Théorie de l'information | NUL |
|---|
ne tombera pas dans l'ensemble des tuples avant le groupement, donc le nombre de tuples dans le groupe de la discipline " Théorie de l'information"Sera 1 moins.
Peut être appliqué fonctions globales Sans aucune opération de regroupement préliminaire, dans ce cas, toute la relation est considérée comme un groupe et que ce groupe peut être calculé sur le groupe.
En contactant la "session" de la base de données (Tables R1, R2, R3), nous trouverons le nombre d'examens réussi:
Ceci, bien sûr, diffère de la sélection du champ, car la valeur unique est toujours renvoyée, quel que soit le nombre de lignes dans la table. Argument fonctions globales Il peut y avoir des colonnes de tables séparées. Mais pour calculer, par exemple, le nombre de valeurs différentes d'une certaine colonne du groupe, vous devez appliquer le mot-clé distinct ainsi que le nom de la colonne. Nous calculons le nombre d'estimations différentes obtenues pour chaque discipline:
Résultat:
Dans le résultat, vous pouvez activer la valeur du champ de regroupement et plusieurs. fonctions globalesQuelques champs peuvent être utilisés dans les conditions de regroupement. Dans le même temps, les groupes sont formés par l'ensemble des champs de regroupement spécifiés. Les opérations avec des fonctions globales peuvent être appliquées à l'unification de l'ensemble des tables source. Par exemple, nous fixerons la question suivante: déterminer pour chaque groupe et chaque discipline le nombre de réussite avec succès l'examen et le score moyen sur la discipline.
Résultat:
Nous ne pouvons pas utiliser fonctions globales Dans l'offre, car les prédicats sont estimés aux termes d'une seule ligne, et fonctions globales - en termes de groupes de lignes.
L'offre de groupe BA vous permet de déterminer le sous-ensemble de valeurs dans un champ spécial en termes d'un autre champ et d'appliquer la fonction de l'unité à un sous-ensemble. Cela permet de combiner des champs et fonctions globales Dans une seule phrase, sélectionnez. Fonctions globales Ils peuvent être utilisés à la fois dans l'expression de la sortie de la chaîne de sélection et dans l'expression des conditions de traitement formées des groupes ayant. Dans ce cas, chaque fonction d'agrégat est calculée pour chaque groupe sélectionné. Valeurs obtenues lors du calcul fonctions globalesPeut être utilisé pour produire des résultats pertinents ou pour la condition de la sélection des groupes.
Nous allons construire une demande qui affiche des groupes dans lesquels plus d'une discipline obtenue lors des examens:
À l'avenir, comme exemple, nous ne travaillerons pas avec la "session" de la base de données, mais avec la BD "Bank", composée d'un tableau F, qui stocke le ratio F contenant des informations sur les comptes dans les branches de certaines banques:
F \u003d (N, Nom complet, Branche, DatabOut, Databroat, Balance); Q \u003d (branche, ville);
Étant donné que sur cette base de données peut être plus brillante pour illustrer le travail avec des fonctions agrégées et un regroupement.
Par exemple, supposons que nous souhaitions trouver un équilibre total des comptes dans les branches. Vous pouvez faire une requête séparée pour chacune d'elles en sélectionnant la somme (résidu) de la table pour chaque branche. Le groupe par cependant, leur permettra de les mettre dans une seule équipe:
Sélectionnez la branche, la somme (résidus) de F grup par branche;
Groupe par usage fonctions globales Indépendamment de chaque groupe, déterminé par la valeur de champ de la branche. Le groupe est constitué de lignes avec la même valeur de champ de champ, et
introduction
SQL (langue de requête structurée) - Langage de requêtes structurées - demandes de langage standard de travail avec des bases de données relationnelles.
La première langue internationale SQL SQL a été adoptée en 1989 (ci-après, nous l'appelerons SQL / 89 ou SQL1). Parfois, SQL1 StandPRPR1 s'appelle également la norme ANSI / ISO et la majorité écrasante des SGBD disponibles sur le marché appuient pleinement cette norme.
À la fin de 1992, une nouvelle langue SQL standard internationale a été adoptée (qui s'appellera SQL / 92 ou SQL2). Et ce n'est pas dépourvu de défauts, mais en même temps, il est significativement plus précis et plein que SQL / 89. Actuellement, la plupart des fabricants de DBMS apportent des modifications à leurs produits afin qu'ils soient plus satisfaits par la norme SQL2.
La dernière norme dans la langue SQL a été publiée en 1996. Elle s'appelle SQL3.
SQL ne peut pas être entièrement attribué aux langages de programmation traditionnels: il ne contient pas d'opérateurs de gestion de programme traditionnels, de type description des opérateurs de type et bien plus encore, il ne contient que un ensemble d'opérateurs d'accès à des données standard stockés dans la base de données. Les instructions SQL sont intégrées au langage de la programmation de base, qui peut être n'importe quel type de langue standard C ++, PL, COBOL, etc. De plus, les instructions SQL peuvent être effectuées directement en mode interactif.
1. Structure SQL.
SQL contient les sections suivantes:
1. Opérateurs de définition de données DDL (langage de définition de données).
| Opérateur | Sens | Acte |
| Créer une table | Créer une table | Crée une nouvelle table dans la base de données |
| Table de goutte | Supprimer la table | Supprime la table de la base de données |
| Modifier table | Tableau de changement | Change la structure de la table existante |
| Créer une vue. | Créer une vue | Crée une table virtuelle, c'est-à-dire Une table qui n'existe pas réellement, mais simulée à l'aide de cet opérateur. |
| Altérer la vue. | Change de vue | Change la structure ou le contenu de la table virtuelle |
| Vue de goutte. | Enlever la vue | Supprime une description de la table virtuelle. Il n'est pas nécessaire de retirer la table elle-même, car Elle n'existe vraiment pas. |
| Créer index | Créer un message | Crée une structure physique spéciale appelée index qui fournit une accélération de l'accès aux données |
| Index | Supprimer le message | Supprime la structure créée |
| Créer synonyme. | Créer synonyme | |
| Drop Synonyme. | Supprimer Synonyme | |
2. Opérateurs de manipulation de manipulation de données Langue (DML)
3. Demandes de requête Queres Langue Langue (DQL)
4. Outils de gestion des transactions (DCL)
5. Outils d'administration de données (DDL)
Logiciel SQL
2. Types de données
Les types de données suivants sont pris en charge dans SQL / 89: caractère, numérique, décimal, entier, smallint, flotteur, réel, double prévision. Ces types de données sont classés sur des types de caractères, des nombres précis et des nombres approximatifs.
Les types de données suivants sont ajoutés dans la norme SQL92:
Varchar (n) - caractères de longueur variable
NCHAR (N) - Serrures de caractères de longueur constante localisée
NCHAR variable (n) - Serrures de caractères de longueur variable localisée
Bit (N) - Bits de string de longueur constante
Bit variant (n) - chaîne de bits de longueur variable
Date de calendrier Date
Horodatage (précision) date et heure
Intervalle d'intervalle temporaire
3. Sélectionnez Opérateur de sélection
Sélectionner est le seul opérateur de recherche qui remplace toutes les opérations d'algèbre relationnelle.
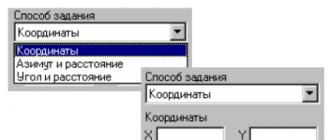
Sélectionnez le diagramme de syntaxe de l'opérateur est affiché à la Fig.1.
Ici, le tout mot clé signifie que l'ensemble des lignes résultantes inclut toutes les lignes satisfaisant à la demande d'attribution. Le mot clé distinct signifie que seules différentes lignes sont incluses dans le jeu de résultats, c'est-à-dire Duplicats Les résultats des lignes ne sont pas inclus dans l'ensemble. S'il n'y a pas de mot clé, cette situation est interprétée comme la présence d'un mot clé tout.
Le symbole * signifie que le jeu de résultats inclut toutes les colonnes des tables de requête source.
Une partie de la liste des relations source (tables) de la requête.
En termes d'où, les conditions de sélection du résultat du résultat ou de la condition reliant les utilles des tables source sont définies.
En partie, dans la liste des champs de regroupement est défini.
En termes d'avoir, les prédicats sont définis dans les conditions imposées à chaque groupe.
En termes d'ordre par, une liste des champs résultants est définie.
Les prédicats suivants peuvent être utilisés pour exprimer des conditions pour la partie où:
· Préciser la comparaison avec l'échantillon comme et pas comme
· Existe et n'existe pas de prédicat.
· Prédicatifs de comparaison { =, <>, >,<,>=,<=,}. Le diagramme syntaxique des prédicats de comparaison est présenté à la Fig. 2
In - inclut dans l'ensemble / non inclus dans l'ensemble.
Dans ou non dans le prédicat peut également être utilisé pour comparer l'expression expression en cours de vérification, dans ce cas, le diagramme syntaxique est représenté sur la Fig. cinq.
Dans le prédicat en est vrai lorsque la valeur de l'attribut spécifié dans l'expression vérifiée pour le cortex actuel coïncide avec au moins une des nombreuses valeurs obtenues à la suite de la mise en œuvre de la sous-requête appropriée ou des valeurs contenues dans la liste. Et retour, le prédicat non intégré n'est vrai que lorsque la valeur d'un attribut spécifié dans le cortex actuel ne coïncide avec aucune des nombreuses valeurs définies par la sous-requête intégrée ou une liste de valeurs donnée.
Prédicat comme - comprend (comme)
Le modèle peut contenir un symbole souligné pour désigner un seul symbole;
% Symbole pourcentage - pour faire référence à une séquence arbitraire de caractères.
Le prédicat similaire est vrai lorsque la valeur d'attribut spécifiée par le nom de la colonne dans la taverne actuelle inclut le fichier spécifié.<шаблон>.
Pré-comme présenté - Truents lorsque la valeur d'attribut dans le cortex actuel n'inclut pas la valeur spécifiée<шаблон>.
· Prédicat null - inconnu, incertain
Le diagramme syntaxique du prédicat est présenté à la Fig. 7.
Dans les termes de recherche, tous les prédicats précédents peuvent être utilisés.
Après avoir reporté la connaissance avec le regroupement, envisagez de détailler les trois premières lignes de l'opérateur Select:
SÉLECTIONNER - Un mot clé qui signale le SGBD que cette commande est une demande. Toutes les demandes commencent avec ce mot avec l'espace suivant. Derrière lui peut suivre la méthode d'échantillon - avec la suppression des doublons ( Distinct.), ou sans retrait ( Tout.La valeur par défaut est implicite). Suit ensuite la liste des colonnes répertoriées via la virgule, qui sont sélectionnées par la requête des tables ou du caractère ' * 'Sélectionner la ligne entière. Toute colonnes non répertoriées ici ne sera pas incluse dans le jeu de données résultant. Bien entendu, cela ne signifie pas qu'ils seront supprimés ou que leurs informations seront effacées des tableaux, car la demande n'affecte pas les informations contenues dans les tableaux - elle ne montre que les données.
De. - un mot-clé qui doit être présenté dans chaque demande. Une fois que le mot clé de l'A partir suit un ou plusieurs espaces, puis la liste des tables source utilisées dans la requête. Les noms de tableaux sont séparés des autres virgules. Les tables peuvent être affectées à des noms-pseudonymes, utiles pour effectuer une opération de connexion de table avec elle-même ou pour accéder au sous-match à l'enregistrement actuel d'une demande externe (sous-requêtes imbriquées ne sont pas considérées ici). Les alias sont un nom de table temporaire utilisé uniquement dans cette requête et n'est pas appliqué. Le pseudonyme est séparé du nom principal de la table au moins un espace. Le diagramme de syntaxe de la partie de la partie est présenté à la Fig. neuf.
Toutes les parties suivantes de l'instruction SELECT sont facultatives.
· Où - Le mot clé suivi d'une condition de prédicat qui définit les enregistrements qui tomberont dans l'ensemble de recrutement résultant.
Considérez la relation entre la base de données qui simule la livraison de la session dans certains établissements d'enseignement. Laisser comprendre trois relations ,, Nous supposons qu'ils sont représentés par des tables R1, R2 et R3, respectivement.
R1 \u003d (nom complet, discipline, évaluation)
R2 \u003d nom complet, groupe)
R3 \u003d (groupe, discipline)
Nous donnons plusieurs exemples d'utilisation de l'instruction SELECT.
· Liste de tous les groupes (sans répétition), où les examens devraient passer
Sélectionnez Distinct. Groupes
De r3.
· Liste des étudiants qui ont passé l'examen de base de données sur "Excellent"
Sélectionnez Nom complet
De r1.
Où. La discipline \u003d "BD" et Évaluation = 5
· Une liste de tous les étudiants qui doivent prendre quelque chose, ainsi que le nom de la discipline.
SÉLECTIONNER Nom complet, discipline
De r2, r3
Où. R1.group = R2.group
Ici, une partie de l'endroit où définit les conditions de connexion des relations R1 et R2. En l'absence de conditions de connexion dans la partie où la partie, le résultat sera équivalent à un travail décharicain élargi et, dans ce cas, chaque élève serait attribué à toutes les disciplines du ratio R2, et non celles qui devraient passer à son groupe.
· Liste des rampes ayant plusieurs corps
SÉLECTIONNER Nom et prénom
De. R1 A, R1 B
Où. a.fio \u003d b.fio Et.
A.Discipline <> b. Discipline Et.
A. Zvenka<= 2
Et. b. Zotsenka.<= 2
Ici, nous avons utilisé des aliases pour nommer la relation R1 A et B, car pour enregistrer les conditions de recherche, nous devons travailler immédiatement avec deux cas de cette relation.
De ces exemples, il est clair que la logique du choix de l'opérateur de sélection (Projection de la sélection de produits cartésiens) ne coïncide pas avec la procédure de la description des données (première liste des champs de la projection, puis de la Liste des tables pour le travail décartitien, puis la condition composée). Le fait est que SQL a été initialement développé pour être utilisé par l'utilisateur final, et il a été cherché à apporter la langue naturelle et non à l'algorithmique de la langue. Bien sûr, l'anglais est choisi comme langue internationale, largement utilisée dans la technologie informatique et la programmation. Pour cette raison, SQL au début provoque une confusion et une irritation des débutants pour étudier les programmeurs professionnels qui sont habitués à parler avec précision sur la voiture sur les langues algorithmiques.
La présence de valeurs nuls incertaines augmente la flexibilité des informations de traitement stockées dans la base de données. Dans nos exemples, nous pouvons assumer la situation lorsque l'étudiant est arrivé à l'examen, mais ne l'a pas transmis pour une raison quelconque, dans ce cas, l'évaluation de certaines disciplines de cet élève a une valeur indéfinie. Dans cette situation, vous pouvez poser la question suivante: "Trouvez des étudiants qui sont venus à l'examen, mais ne l'ont pas donné au nom de la discipline." L'instruction SELECT ressemblera à ceci:
SÉLECTIONNER Nom complet, discipline
Où. ÉvaluationEst null
Immédiatement, je veux faire une réservation que tous les exemples indiqués précédemment sont conditionnels. Pourquoi? Ne travaillent-ils pas dans de vraies bases de données? Sont-ils faux? Ici, tout est correct, à l'exception des noms d'attribut ou des colonnes de table. La plupart des DBMS (systèmes de gestion de la base de données) ne sont pas autorisés à appeler des colonnes dans les langues nationales, ces objets de base de données et les objets linguistiques sont nécessaires pour qu'elles soient appelées par les règles des identificateurs nommant dans cette langue. Le plus souvent, le nom d'attribut peut être une séquence de lettres de l'alphabet et des chiffres latins, en commençant par une lettre qui ne contient pas de caractères spéciaux (par exemple, espaces, points, virgules, pourcentage de% et autres caractères spéciaux) et ayant quelques limitations de longueur. Dans différents SGBM, ces restrictions sont différentes, par exemple dans MS SQL Server 2000 - la longueur du nom d'attribut peut atteindre 128 caractères. Les noms d'attributs longs sont gênants pour écrire une demande, mais les noms très courts d'un alésage ne permettent pas de garder le sens sémantique de la colonne de table, de sorte qu'ils choisissent de compromis et se réfèrent à la méchanceté, mais il est pratique, de sorte qu'il soit Pas nécessaire de regarder une description complète de la base de données lors de la rédaction de chaque demande. De plus, les noms des attributs, ainsi que les noms d'autres objets, ne doivent pas coïncider avec les mots-clés de la langue SQL - I.E. Ces mots inclus dans les opérateurs de la langue.
Par conséquent, en termes d'exactitude, nous devrions fournir un schéma de base de données "session" sous la forme de
R1 \u003d (Name ST_Name, discipline, marque)
R2 \u003d (st_name, n_group)
R3 \u003d (n_group, discipline)
Et le changement de manière appropriée toutes les demandes.
Application des fonctions agrégées et des demandes investies dans l'opérateur de sélection
Les demandes peuvent calculer la valeur de groupe généralisée des champs, comme la valeur d'un champ. Ceci est fait en utilisant des fonctions agrégées. Les fonctions globales produisent une valeur unique pour toute la table de la table. Liste de ces fonctionnalités:
Les fonctions globales sont utilisées similaires aux noms de champs dans l'instruction SELECT, mais à une exception près: ils prennent le nom du champ comme un argument. Seuls les champs numériques peuvent être utilisés avec des fonctions SUM et AVG. Avec le nombre, les fonctions max et MIN peuvent être utilisés à la fois des champs numériques et symboliques. Lorsqu'il est utilisé avec des champs symboliques, MAX et MI les diffusera dans l'équivalent ASCII et le processus dans l'ordre alphabétique. Certains SGDM permettent d'utiliser des agrégats imbriqués, mais il s'agit d'une déviation de la norme ANSI avec toutes les conséquences résultant d'ici.
En contactant la "session" de la base de données (Tables R1, R2, R3), nous trouverons le nombre d'examens réussi:
Sélectionnez Compte (*)
De r1.
Où mark\u003e 2;
Ceci, bien sûr, diffère de la sélection du champ, car la valeur unique est toujours renvoyée, quel que soit le nombre de lignes dans la table. Pour cette raison, les fonctions et les champs d'agrégats ne peuvent pas être sélectionnés simultanément si le groupe par une offre spéciale n'est pas utilisé.
Le groupe par offre vous permet de déterminer le sous-ensemble des valeurs qui s'appelle en outre du groupe et d'appliquer la fonction de l'unité à ce groupe. Le groupe est formé à partir de toutes les lignes pour lesquelles les valeurs des champs de regroupement spécifiés dans le groupe par suggestion ont la même valeur. Cela permet de combiner des champs et des fonctions agrégées dans une seule phrase de sélection. Le diagramme syntaxique de l'utilisation des fonctions globales est illustré à la Fig. 10 Les fonctions d'agrégat peuvent être utilisées comme dans l'expression de la sortie de la chaîne. SÉLECTIONNERet dans l'expression de la condition de traitement des groupes formés Ayant. Dans ce cas, chaque fonction d'agrégat est calculée pour chaque groupe sélectionné. Les valeurs obtenues lors du calcul des fonctions d'agrégat peuvent être utilisées pour produire les résultats pertinents ou pour la condition de sélection des groupes.
Lorsque vous utilisez des fonctions agrégées, il est nécessaire de rappeler que seules les valeurs des champs de regroupement peuvent être présentes dans l'ensemble résultant et les valeurs des fonctions globales peuvent être présentes. Il n'est pas autorisé à grouper en une seule valeurs, mais à générer d'autres valeurs. Ce sera une erreur syntaxique.
Par exemple, une telle demande sera toujours erronée:
SÉLECTIONNER UN.
Groupe de B.
En effet, voyez-le. Que voulons-nous trouver? Nous essayons de retirer une certaine valeur de la colonne MAIS de la table T. et en même temps effectuer un regroupement sur une autre colonne, une colonne DANS.Nous effectuons un groupe - cela signifie que nous collectons toutes les lignes avec les mêmes valeurs de colonne dans un groupe et sur, puis il n'est pas clair, nous dérivons la valeur de la colonne A, mais dans le même groupe, il peut y avoir De nombreuses valeurs, différentes valeurs de la colonne A. Donc, quelle valeur nous affichons? Ce n'est pas clair pour nous ni un ordinateur. C'est pourquoi il refuse d'exécuter cette demande et déclare que nous avons une erreur de syntaxe.
Revenons à notre base de données "Session", mais ajoutons-la à plusieurs autres attributs. Premièrement, parmi les élèves, il peut y avoir des nabligés, nous utiliserons donc le carnet de test de l'étudiant pour identifier l'élève, qui identifie toujours l'élève. Et deuxièmement, supposons que l'étudiant puisse faire plusieurs tentatives de réussir l'examen sur la même discipline et nous introduisons la date de la prochaine tentative de réussite de l'examen par rapport à R1. Et enfin, la troisième addition, nous supposons que nous avons beaucoup de groupes dans diverses spécialités de notre université, puis le diagramme de notre base de données sera le suivant.
Sessia (n_zach, discipline, marque, Data_ex)
Exemple 21.. Obtenez le nombre total de fournisseurs (mot-clé Compter ):
Sélectionnez Count (*) comme n
En conséquence, nous obtenons une table avec une colonne et une ligne contenant le nombre de lignes du tableau P:
Utilisation de fonctions agrégées avec des groupements
Exemple 23. . Pour chaque détail pour obtenir la quantité totale fournie (mot-clé Par groupe. …):
Somme (pd.volume) comme SM
Groupe par pd.dnum;
Cette demande sera effectuée comme suit. Premièrement, les lignes de la table source seront regroupées de manière à ce que les rangées avec les mêmes valeurs de DNUM tombent dans chaque groupe. Ensuite, au sein de chaque groupe, le champ de volume sera résumé. Dans chaque groupe, une ligne sera activée à la table résultante:
Commenter. Dans la liste des champs sélectionnés, l'opérateur Select contenant le groupe par section peut être inclus. seulfonctions et champs agrégés qui sont dans la condition de regroupement. La demande suivante affichera une erreur syntaxique:
Somme (pd.volume) comme SM
Groupe par pd.dnum;
La cause de l'erreur est que le champ Pnum est inclus dans la liste des champs sélectionnés. excludans le groupe par section. Et en effet, dans chaque groupe de lignes résultant peut inclure plusieurs rangées avec diversvaleurs de champ pnum. De chaque groupe de chaînes sera formé à une seule ligne. Dans le même temps, il n'y a pas de réponse sans ambiguïté à la question de savoir comment choisir pour le champ Pnum dans la dernière ligne.
Commenter. Certains dialectes SQL ne le considèrent pas pour une erreur. La requête sera exécutée, mais de prédire quelles valeurs seront entrées dans le champ Pnum dans la table d'esquissage, il est impossible.
Exemple 24. . Obtenez des numéros de pièce, dont le nombre total fourni est supérieur à 400 (mot-clé Ayant …):
Commenter. La condition selon laquelle la quantité totale fournie doit être supérieure à 400 ne peut pas être formulée dans la section où la section, car Dans cette section, il est impossible d'utiliser des fonctions agrégées. Les conditions utilisant des fonctions agrégées doivent être affichées dans une section spéciale ayant:
Somme (pd.volume) comme SM
Groupe par pd.dnum.
Avoir une somme (pd.volume)\u003e 400;
En conséquence, nous obtenons le tableau suivant:
Commenter. Dans une requête, vous pouvez rencontrer les deux paramètres de la sélection des lignes de la section où la section et les conditions de sélection dans la section ayant une section. Les paramètres de sélection des groupes ne peuvent pas être transférés de la section ayant une section dans la section où la section. De même, les conditions de sélection des lignes ne peuvent pas être transférées de la section où la section en présentant une section, à l'exception des conditions, y compris les champs du groupe par groupe de regroupement.
Utiliser des sous-requêtes
Un outil très pratique qui vous permet de formuler des requêtes est plus compréhensible, est la capacité d'utiliser des sous-requêtes investies dans la demande principale.
Exemple 25. . Obtenez une liste de fournisseurs dont le statut est inférieur au statut maximum dans la table des fournisseurs (comparaison de comparaison):
Où p.statys.<
(Sélectionnez max (p.status)
Commenter. Parce que Le champ P.Status est comparé au résultat de sous-rattage, les sous-sols doivent être formulés pour renvoyer la table constituée. exactement d'une ligne et d'une colonne.
Commenter
Effectuer une fois quesous-requête imbriquée et obtenez la valeur maximale de statut.
Numérisez la table des fournisseurs, chaque fois comparant la valeur de l'état du fournisseur à la suite de sous-requêtes et sélectionnez uniquement les lignes dans lesquelles le statut est inférieur au maximum.
Exemple 26. . Utilisation du prédicat DANS.
(Sélectionnez PD.PNUM distinct
Où pd.dnum \u003d 2);
Commenter. Dans ce cas, le sous-match peut renvoyer une table contenant plusieurs lignes.
Commenter. Le résultat de la requête sera équivalent au résultat de la séquence d'actions suivante:
Effectuer une fois quesous-requête imbriquée et obtenir une liste de fournisseurs fournisseurs fournissant la pièce numéro 2.
Scannez la table des fournisseurs P, après avoir vérifié à chaque fois que le numéro de fournisseur est contenu à la suite de la sous-requête.
Exemple 27. . Utilisation du prédicat EXISTER . Obtenez une liste de fournisseurs fournis le détail numéro 2:
Pd.pnum \u003d p.pnum et
Commenter. Le résultat de la requête sera équivalent au résultat de la séquence d'actions suivante:
Table de numérisation Fournisseurs P, chaque fois effectuant une sous-requêteavec la nouvelle valeur du numéro de fournisseur extraite de la table P..
En conséquence de la requête, seules les lignes de la table des fournisseurs pour laquelle la sous-requête imbriquée renvoya un ensemble de lignes non vide est renvoyée.
Commenter. Contrairement aux deux exemples précédents, la sous-requête contient le paramètre (lien externe) transmis à partir de la requête principale - le numéro de fournisseur P.Pnum. Ces sous-tiens sont appelés corrélé (corrélé. ). La liaison externe peut prendre différentes valeurs pour chaque chaîne de candidature mesurée à l'aide d'un sous-traitant. La sous-requête doit donc être recueillie à nouveau pour chaque ligne sélectionnée dans la demande principale. De tels sous-parents sont caractéristiques du prédicat existent, mais peuvent être utilisés dans d'autres sous-risers.
Commenter. Il peut sembler que des requêtes contenant les sous-actionnaires corrélées seront effectuées plus lentement que les requêtes avec des sous-requêtes non corrosives. En fait, ce n'est pas le cas, parce que Comment l'utilisateur a formulé la demande, ne détermine pasComment cette demande sera effectuée. La langue SQL n'est pas non traitée, mais déclarative. Cela signifie que l'utilisateur qui formule la demande décrit simplement que devrait être le résultat de la demandeet comment ce résultat sera obtenu - le DBMS lui-même en est responsable.
Exemple 28. . Utilisation du prédicat N'existe pas . Obtenez une liste de fournisseurs qui ne fournissent pas la pièce numéro 2:
Pd.pnum \u003d p.pnum et
Commenter. Comme dans l'exemple précédent, une sous-requête corrélée est utilisée ici. La différence est que dans la demande principale, ces lignes de la table des fournisseurs seront sélectionnées, pour lesquelles la sous-requête imbriquée ne se verra pas attribuer une seule ligne.
Exemple 29. . Obtenez les noms des fournisseurs fournissant tous les détails:
Sélectionnez Distinct PName.
Pd.dnum \u003d d.dnum et
Pd.pnum \u003d p.pnum));
Commenter. Cette demande contient deux sous-candidats imbriquées et implémente une opération relationnelle. relations de division.
La sous-requête la plus interne est paramétrée par deux paramètres (d.dnum, p.pnum) et a la signification suivante: Pour sélectionner toutes les lignes contenant des données de livraison du fournisseur avec le numéro Dnum Numéro Pnum. La négance n'existe pas suggère que ce fournisseur ne fournit pas cet article. La sous-requête externe à celle-ci, qui est le paramètre p.pnum imbriqué et paramétré, il est logique: de sélectionner une liste de pièces qui ne sont pas fournies par PNUM. Nedance n'existe pas indiquant que pour un fournisseur avec le numéro de Pnum, il ne devrait pas y avoir de détails qui ne seraient pas livrés par ce fournisseur. Cela signifie exactement que seuls les fournisseurs fournissant toutes les pièces sont sélectionnés dans la requête externe.
Important! Si le paramètre de fonction a un type de chaîne et indique que le nom du champ contenant des espaces, un tel nom de champ doit être enfermé entre crochets.
Par exemple: "[Nombre de chiffre d'affaires]."
1. montant (total) - Calcule la quantité de valeurs des expressions transférées comme un argument pour tous les enregistrements détaillés. En tant que paramètre, vous pouvez transmettre un tableau. Dans ce cas, la fonction sera appliquée au contenu de la matrice.
Exemple:
Montant (vente. Résumé)
2. Nombre (compte) - Calcule le nombre de valeurs autres que NULL. En tant que paramètre, vous pouvez transmettre un tableau. Dans ce cas, la fonction sera appliquée au contenu de la matrice.
Syntaxe:
Numéro (paramètre [différent])
En spécifiant différentes valeurs, le paramètre de quantité doit être spécifié différent (distinct).
Exemple:
Quantité (vente. Contrecount)
Quantité (diverses ventes. Agent de contrôle)
3. Maximum (maximum)
- Obtient la valeur maximale. En tant que paramètre, vous pouvez transmettre un tableau. Dans ce cas, la fonction sera appliquée au contenu de la matrice.
Exemple:
Maximum (résidus. Nalité)
4. Minimum (minimum) - Obtient la valeur minimale. En tant que paramètre, vous pouvez transmettre un tableau. Dans ce cas, la fonction sera appliquée au contenu de la matrice.
Exemple:
Minimum (résidu. Nalité)
5. moyenne (moyenne) - Obtient la valeur moyenne des valeurs autres que NULL. En tant que paramètre, vous pouvez transmettre un tableau. Dans ce cas, la fonction sera appliquée au contenu de la matrice.
Exemple:
Moyenne (résidus. Nalité)
6. Array (tableau) - génère une valeur contenant une valeur de paramètre pour chaque enregistrement détaillé.
Syntaxe:
Array ([différentes] expression)
Vous pouvez utiliser la table des valeurs comme paramètre. Dans ce cas, le résultat de la fonction de la fonction sera un tableau contenant les valeurs de la première colonne de la table des valeurs transmises sous forme de paramètre. Si l'expression contient une fonction de tableau, on pense que cette expression est agrégée. Si un mot clé différent est spécifié, le tableau résultant ne contiendra pas de valeurs en double.
Exemple:
Array (contrepartie)
7. Tivraison (Vastable) - génère une table de valeurs contenant autant de colonnes que les paramètres de la fonction. Des enregistrements détaillés sont obtenus à partir d'ensembles de données nécessaires pour obtenir tous les champs impliqués dans les expressions de paramètres de la fonction.
Syntaxe:
Applications ([diverses] express1 [comme namecolonki1] [, expression2 [comme Namecolonka2], ...]
Si les paramètres de fonction sont les paramètres de champ résiduels, les valeurs seront données pour des enregistrements pour des combinaisons de mesure uniques à partir d'autres périodes. Dans ce cas, les valeurs ne sont obtenues que pour les résidus de champs, les mesures, les comptes, les périodes de périodes et leurs détails. Les valeurs des autres champs des enregistrements d'autres périodes sont considérées comme égales à NULL. Si l'expression contient la fonction de la table, on pense que cette expression est agrégée. Si un mot clé différent est spécifié, alors dans la table de valeurs des valeurs, il n'y aura pas de lignes contenant les mêmes données. Après chaque paramètre, un mot clé optionnel peut être situé comme un nom qui sera attribué à la colonne Table de valeurs.
Exemple:
Évaluations (diverses nomenclatures, caractéristiques des caractéristiques comme caractéristique)
8. Réduire (groupby) - Conçu pour supprimer des doublons de la matrice.
Syntaxe:
Réduire (Expression, Slottle)
Paramètres :
- Expression - une expression de la matrice de type ou de l'apposition, les valeurs des éléments dont vous avez besoin pour s'effondrer;
- Numérique - (si l'expression a le type de table) de type ligne. Numéros ou noms (sur les virgules) Valeurs de table de colonnes, parmi lesquelles vous devez rechercher des doublons. Par défaut - Toutes les enceintes.
Effondrement (signes de table (chiffres, adresse), "numéro");
9. GetPart) - Obtient une table de valeurs contenant certaines colonnes de la table source des valeurs.
Syntaxe:
Se familiariser (expression, escale)
Paramètres :
- Expression - Tapis de type. La table des valeurs à partir de laquelle vous devez recevoir des colonnes;
- Numérique - Tapez la chaîne. Numéros ou noms (sur des virgules) de la table des valeurs à obtenir.
Exemple:
Arriver à obtenir (effondrement (panneaux de table (numéros, adresse), "numéro"), "numéro");
10. Trier (ordre) - Conçu pour rationaliser les éléments de réseau et la table de valeurs.
Syntaxe:
Trier (expression, escale)
Paramètres :
- Expression - panneaux de tableau ou de table à partir desquels vous devez recevoir des colonnes;
- Numérique - (si l'expression a le type de table) des nombres ou des noms (via une virgule) des colonnes de table de valeurs pour lesquelles vous devez rationaliser. Il peut contenir la direction de la commande et la nécessité d'une commande automatique: décroissant / révision + automobile.
Exemple:
Streamline (panneaux de table (numéro de téléphone, adresse, DataSvonka), "Datazvonka décroissant");
11. Connecteurs (joints) - Conçu pour combiner des chaînes en une seule ligne.
Syntaxe:
Connecteurs (valeur, éléments de séparateur, séparateurs)
Paramètres :
- Valeur - expressions qui doivent être fusionnées en une seule ligne. Si un tableau est, les éléments du tableau seront combinés dans la chaîne. S'il y a une table, toutes les colonnes et les lignes de la table seront combinées dans la chaîne;
- Éléments de séparateur - une chaîne contenant le texte que vous souhaitez utiliser comme séparateur entre les éléments du tableau et les lignes des valeurs des valeurs. Par défaut, le symbole de la traduction de ligne;
- Dividocolonok - une chaîne contenant le texte que vous souhaitez utiliser comme séparateur entre les haut-parleurs de la table des valeurs. Défaut "; ".
Connecteurs (paramètres de table (numéro de téléphone, adresse));
12. PRODUCTION DE GROUPE (GROUPE PRODUCTIONS) - Renvoie l'objet de ces produits dérivés. Dans l'objet à la propriété, les données sont placées sous la forme des valeurs des valeurs des groupements pour chaque expression spécifiée dans le paramètre de fonction d'expression. Dans le cas de l'utilisation d'un groupe hiérarchique, chaque niveau de hiérarchie est traité séparément. Les valeurs pour les enregistrements hiérarchiques sont également placées dans des données. Dans l'objet, l'objet de l'objet est placé une chaîne des valeurs des valeurs pour lesquelles la fonction est actuellement calculée.
Syntaxe:
Traitement de groupe (expressions, expressions, noms)
Paramètres :
- Expressions. Expressions qui doivent être calculées. La chaîne dans laquelle les expressions qui doivent être calculées sont répertoriées par la virgule. Après chaque expression, la présence d'un mot-clé optionnel est possible comme et le nom de la colonne de la table des valeurs résultante. Chaque expression forme une colonne d'une table de valeurs de la propriété des données de l'objet des données de la compensation.
- Expressions. Expressions qui doivent être calculées pour des enregistrements hiérarchiques. De même, le paramètre d'expression avec la différence est que le paramètre de l'expression est utilisé pour les enregistrements hiérarchiques. Si le paramètre n'est pas spécifié, les expressions spécifiées dans le paramètre d'expression sont utilisées pour calculer des valeurs pour des enregistrements hiérarchiques.
- Nom. Le nom du groupe dans lequel vous devez calculer le groupe de traitement. Ligne. Si non spécifié, le calcul se produit dans le groupe actuel. Si le calcul va dans la table et que le paramètre contient une chaîne vide ou non spécifiée, la valeur est calculée pour les chaînes de regroupement. La disposition de la mise en page lors de la génération de la disposition de la disposition de données remplace ce nom dans le nom du groupe dans la disposition résultante. Si le regroupement n'est pas disponible, la fonction sera remplacée par NULL.
Syntaxe:
Chacun (expression)
Paramètre:
- Expression - Tapez buleveo.
Toutes les personnes()
14. Tout (n'importe quel) - Si au moins un enregistrement a le sens de la vérité, alors le résultat de la vérité, sinon un mensonge
Syntaxe:
Quiconque (expression)
Paramètre:
- Expression - Tapez buleveo.
Quelconque()
15. StandardLonenev_Pop (STDDEV_POP) - Calcule l'écart type de l'agrégat. La formule est calculée par la formule: SQRT (Dispersion Indica (X)).
Syntaxe:
Technologie StandardLoneneeneration (expression)
Paramètre:
- Expression - Numéro de type.
Exemple:
| X. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y. | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Résultat: 805.694444
16. StandardLonions Creatures (STDDEV_SAMP) - Calcule l'écart type typique cumulatif. Il est calculé par la formule: SQRT (dispersion / x)).
Syntaxe:
StandardLonions créatures (expression)
Paramètre:
- Expression - Numéro de type.
Exemple:
| X. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y. | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Résultat: 28.3847573
17. Voitures de dispersion (Var_Samp) - Calcule la différence typique entre le nombre de nombres sans prendre en compte les valeurs nulles dans cet ensemble. Il est calculé par la formule: (somme (x ^ 2) - la somme (x) ^ 2 / nombre (x)) / (nombre (x) - 1). Si la quantité (x) \u003d 1, alors null est renvoyé.
Syntaxe:
Voitures de dispersion (expression)
Paramètre:
- Expression - Numéro de type.
Sélectionnez le capteur de dispersion (Y) de la table
Résultat: 716.17284.
19. Réceptacle de covariance (Covar_pop) - Calcule la covariance d'un certain nombre de paires numériques. Il est calculé par la formule: (somme (Y * x) - somme (x) * somme (y) / n) / n, où n nombre de paires (y, x) dans lequel ni x sont nuls.
Syntaxe:
Récipient de covariance (Y, X)
Paramètres :
- Y. - Numéro de type;
- X. - Numéro de type.
| X. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y. | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Résultat: 59.4444444
20. Covariance (Covar_Samp) - Calcule la différence typique entre le nombre de nombres sans prendre en compte les valeurs nulles dans cet ensemble. La formule est calculée par la formule: (somme (y * x) - somme (Y) * somme (x) / n) / (n-1), où n nombre de paires (y, x) dans lequel ni x sont NUL.
Syntaxe:
Covarianesebors (Y, X)
Paramètres :
- Y. - Numéro de type;
- X. - Numéro de type.
| X. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y. | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Résultat: 66.875
21. Corrélation (Corl) - Calcule le coefficient de corrélation d'un certain nombre de paires numériques. La formule est calculée par la formule: réceptacle de covariance (Y, X) / (alternatenèse standard (Y) * rayonnement plan-plan standard (X)). Il n'y a pas de paires dans laquelle Y ou X est égal à NULL.
Syntaxe:
Corrélation (Y, X)
Paramètres :
- Y. - Numéro de type;
- X. - Numéro de type.
| X. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y. | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Résultat: 0.860296149.
22. RegritessionNaclon (Regr_slope) - Calcule la pente de la ligne. La formule est calculée par la formule: Indication de covariance (Y, X) / Dispersionagengengegengegenge (X). Calculé sans enregistrements contenant null.
Syntaxe:
Regrestallon (Y, X)
Paramètres :
- Y. - Numéro de type;
- X. - Numéro de type.
| X. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y. | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Résultat: 8.91666667
23. Régressage: Regr_Intercept - Calcule le point Y de traversant la ligne de régression. La formule est calculée par la formule: la moyenne (y) est la régression de clone (y, x) * moyenne (x). Calculé sans enregistrements contenant null.
Syntaxe:
Régresser la remise (y, x)
Paramètres :
- Y. - Numéro de type;
- X. - Numéro de type.
Choisissez une capacité de régression (Y, X) de la table
Résultat: 9
25. RégressionR2 (REGR_R2) - Calcule le coefficient de détermination. Calculé sans enregistrements contenant null.
Syntaxe:
RegressionR2 (Y, X)
Paramètres :
- Y. - Numéro de type;
- X. - Numéro de type.
- Null - si la dispersion de la distinction est (x) \u003d 0;
- 1 - Si le moyen de dispersion du recyclage (Y) \u003d 0 et de la dispersion indica (x)<>0;
- POW (corrélation (y, x), 2) - si les dispersionageneeneels (Y)\u003e 0 et distinction indica (x)<>0.
| X. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y. | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Résultat: 0.740109464.
26. Régression moyenne (REGR_AVGX) - Calcule le nombre moyen x après l'exception des paires x et y, où ou x ou y sont vides. La moyenne (x) est calculée sans prendre en compte les paires contenant null.
Syntaxe:
Régression moyenne (Y, X)
Paramètres :
- Y. - Numéro de type;
- X. - Numéro de type.
| X. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y. | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Résultat: 5.
27. Moyenne régressée (REGR_AVGY) - Calcule le nombre moyen Y après l'exception des paires x et y, où ou x ou y sont vides. La moyenne (y) est calculée sans prendre en compte les paires contenant null.
Syntaxe:
Moyenne régressée (y, x)
Paramètres :
- Y. - Numéro de type;
- X. - Numéro de type.
| X. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y. | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Résultat: 24.2222222.
28. REGRESSIONSXX (REGR_SXX) - Il est calculé par la formule: capacité de régression (y, x) * dispersion de la dispersion (x). Calculé sans enregistrements contenant null.
Syntaxe:
Régressionsxx (y, x)
Paramètres :
- Y. - Numéro de type;
- X. - Numéro de type.
Exemple:
Sélectionnez Regressionsyyyy (Y, X) de la table
Résultat: 6445.5556
30. régressionsxy (REGR_SXY) - Il est calculé par la formule: Régression (y, x) * réceptacle de covariance (Y, X). Calculé sans enregistrements contenant null.
Syntaxe:
Régressionsxy (y, x)
Paramètres :
- Y. - Numéro de type;
- X. - Numéro de type.
| X. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y. | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Résultat: 535.
31. Pravoder (rang)
Syntaxe:
Podkovpioevik (commande, décoiteurfoots, nom de marque)
Paramètres :
- Ordre - Tapez la chaîne. Contient des expressions dans la séquence dont les entrées de groupe sont nécessaires séparées par des virgules. La direction de la rationalisation est contrôlée au moyen du mot, décroissant. Après le champ, vous pouvez également spécifier l'ordre automatique de la ligne, ce qui signifie que lors de la commande de liens, vous devez utiliser les champs d'arrangement définis pour l'objet auquel le lien. Si la séquence n'est pas spécifiée, la valeur est calculée dans la séquence de regroupement;
- Décoïde - Tapez la chaîne. Contient des expressions de commande pour les enregistrements hiérarchiques;
- Nom - Tapez la chaîne. Le nom du groupe dans lequel vous devez calculer le groupe de traitement. Si non spécifié, le calcul se produit dans le groupe actuel. Si le calcul va dans la table et que le paramètre contient une chaîne vide ou non spécifiée, la valeur est calculée pour les chaînes de regroupement. La disposition de la mise en page lors de la génération de la disposition de la disposition de données remplace ce nom dans le nom du groupe dans la disposition résultante. Si le regroupement n'est pas disponible, la fonction sera remplacée par NULL.
Exemple:
Messager ("[Nombre de chiffre d'affaires]")
32. classificationAbc (classificationabc)
Syntaxe:
ClassificationAcc (valeur, groupes de quantité, groupes intestinaux, groupe de noms)
Paramètres :
- Valeur - Tapez la chaîne. Pour lequel vous devez calculer la classification. La chaîne dans laquelle l'expression est indiquée;
- Correspondre - Numéro de type. Définit le nombre de groupes à cassé;
- Groupe d'intérêts - Tapez la chaîne. Tant de nombreux groupes ont besoin de diviser moins 1. à travers la virgule. Si non spécifié, alors automatiquement;
- Nom - Tapez la chaîne. Le nom du groupe dans lequel vous devez calculer le groupe de traitement. Si non spécifié, le calcul se produit dans le groupe actuel. Si le calcul va dans la table et que le paramètre contient une chaîne vide ou non spécifiée, la valeur est calculée pour les chaînes de regroupement. La disposition de la mise en page lors de la génération de la disposition de la disposition de données remplace ce nom dans le nom du groupe dans la disposition résultante. Si le regroupement n'est pas disponible, la fonction sera remplacée par NULL.
Exemple:
Classificationabc ("montant (Vavypribil)", 3, "60, 90")